利用Plotly绘制各类图表
Plotly部分
Plotly的安装
Plotly比较新,没有包含在anaconda环境中,需要单独安装。
Pycharm或者anaconda找到Plotly点击install安装即可。
可以在终端输入:pip3 install plotly
可以在命令行输入:pip install plotly
可以在anaconda环境中安装:conda install plotly
如果下载速度慢可以使用清华源:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple plotly
检查是否安装成功
import plotly
from plotly import __version__
print(__version__)
这里显示版本即表示安装成功,我用的是4.14.3版本。
利用Plotly绘制第一张图
使用离线版本:plotly.offline
最简单的绘制方式:iplot([数据]),plot和iplot最大区别在于是不是创建一个新的网页来显示图表,后面会演示。
首先看看iplot模式。
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
dic1 = {
'x':[1,2,3,4],
'y':[1,3,5,8]
}
iplot([dic1])
# 可以试试plot([dic1])感受区别
可以看到,使用plotly绘制出来的图和matplotlib绘制的明显区别是:
1、图表中的数据可以显示出具体数值(可交互性);
2、右上角有很多对图片细节进行查看的工具(扩展性)。
尝试大量数据的绘制
利用go.Scatter存放数据
import plotly.graph_objects as go
import numpy as np
import random
x = np.random.randn(30)
y = np.random.randn(30)
go.Scatter(x=x,y=y)
当数据比较多,往往会先把数据存放在go.Scatter内,再集中调用。

调取go.Scatter数据绘制散点图
iplot([go.Scatter(x=x,y=y)])
# iplot([数据]),注意这里数据是放在中括号内
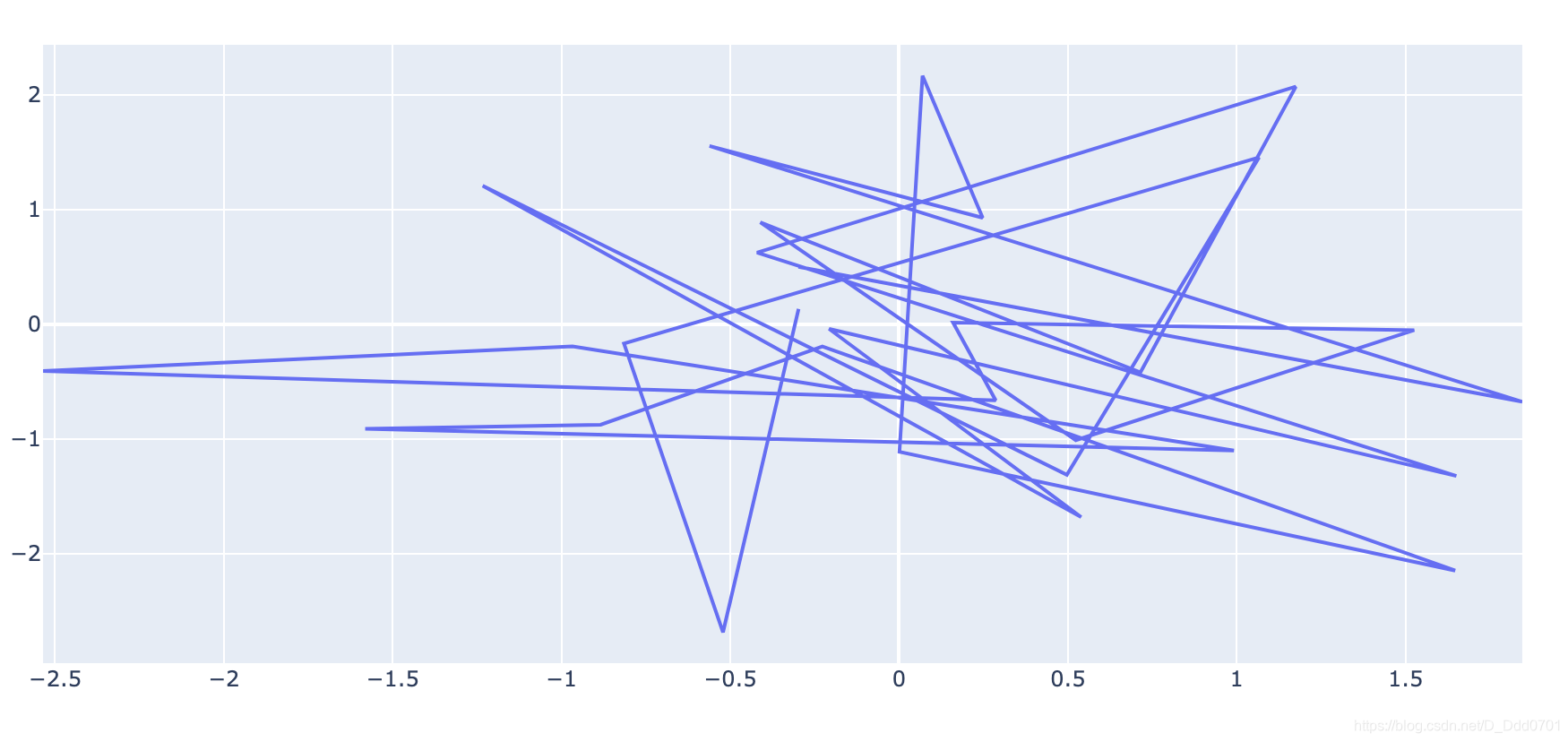
这样的数据是非常乱的,实际上我们只需要绘制散点图,这里需要设置模式:mode='markers'
iplot([go.Scatter(x=x,y=y,mode='markers')])
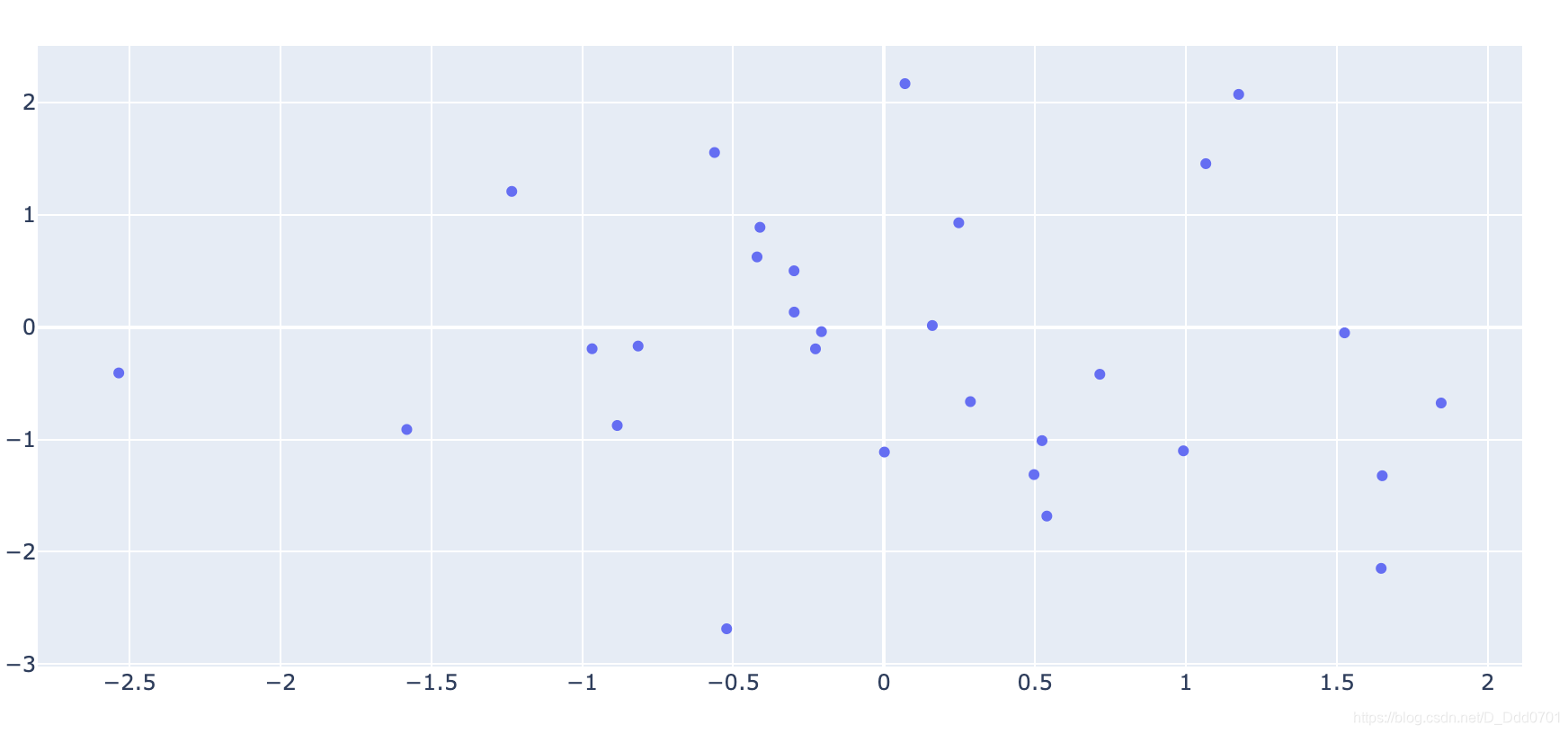
散点图
go对象标准写法
import plotly
import plotly.graph_objs as go
import numpy as np
from plotly.offline import download_plotlyjs , init_notebook_mode,plot ,iplot
n =1000
x = np.random.randn(n)
y = np.random.randn(n)
trace = go.Scatter(x=x, y=y, mode='markers', marker=dict(color='red',size=3,opacity=0.5))
data=[trace]
iplot(data)
go.Scatter语句的标准写法:
第一步、产生数据。
第二步、把数据放入go对象。将go.Scatter()赋值在一个变量内例子用trace,并且在go.Scatter内用marker=dict()调整细节,其中color表示颜色,size表示散点大小,opacity表示透明度。
第三步、创建一个data变量存放go对象。
第四步、(可选) data变量是一个数组列表,所以可以存放超过一个以上的go对象。
第四步、iplot(data)绘制。
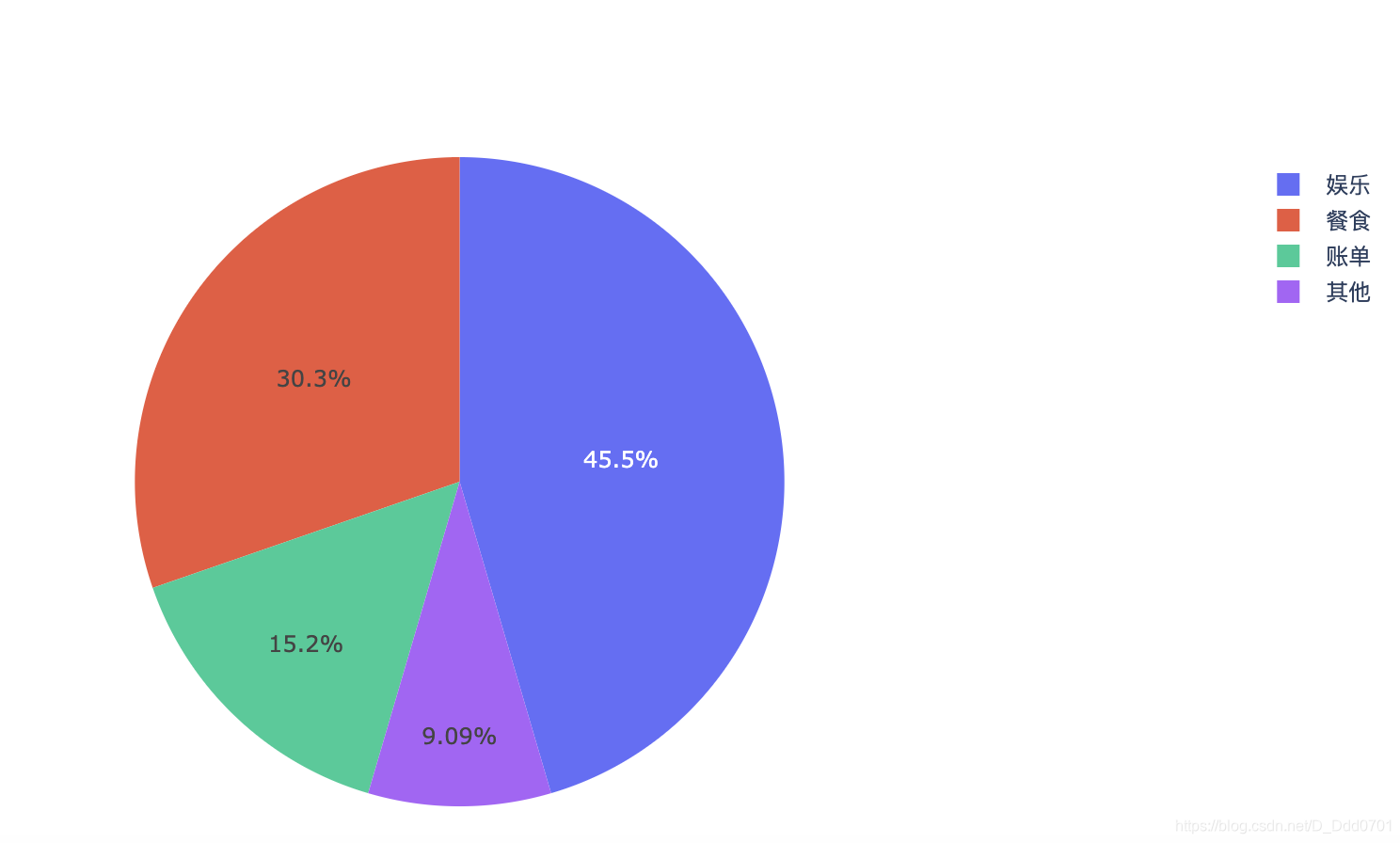
饼图
groups=['餐食','账单','娱乐','其他']
amount=[1000,500,1500,300]
colors=['#d32c58','#f9b1ee','#b7f9b1','#b1f5f9']
trace=go.Pie(labels=groups, values=amount)
data=[trace]
iplot(data)
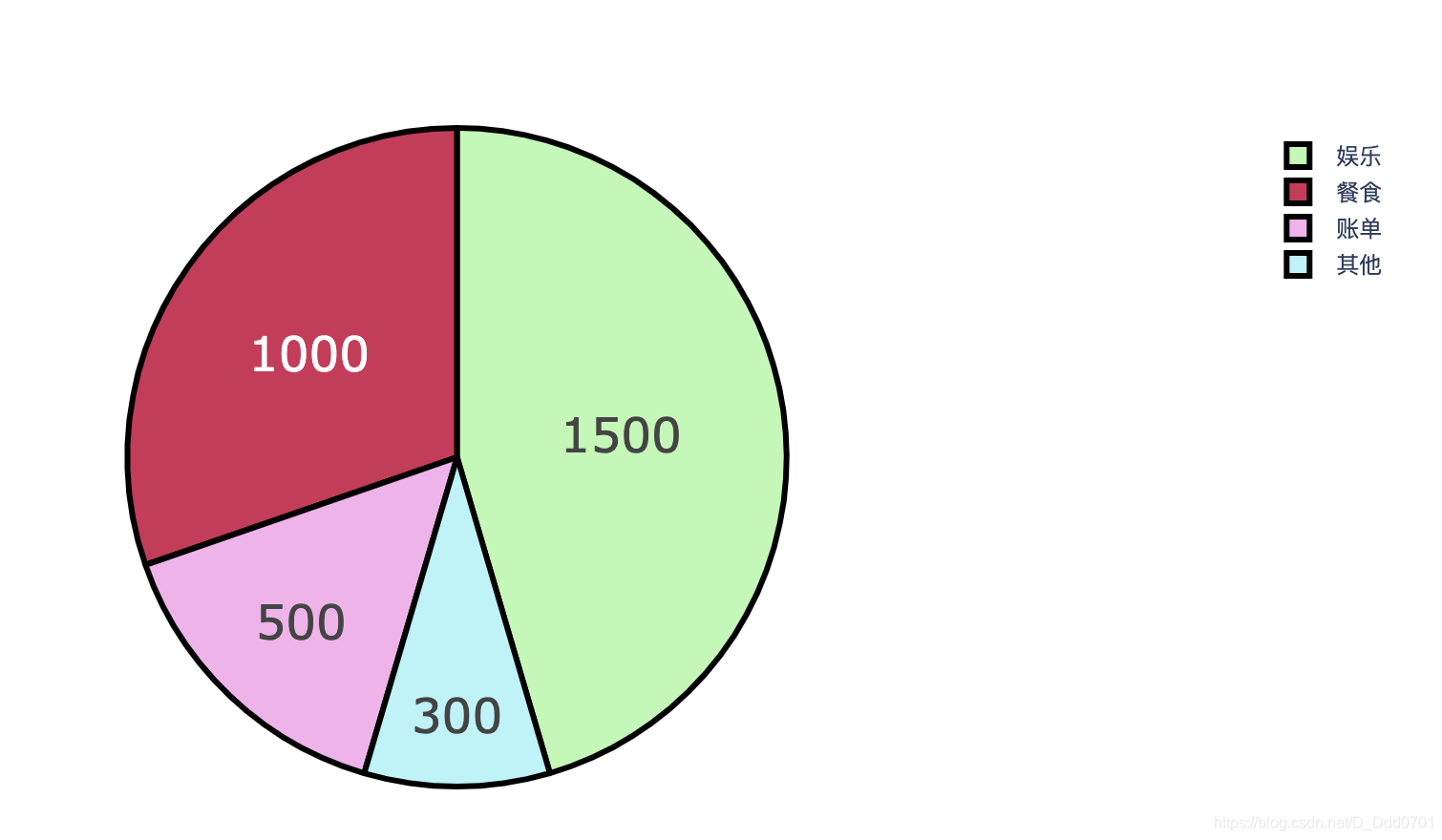
丰富一下细节:
trace=go.Pie(labels=groups, values=amount, hoverinfo='label+percent', textinfo='value',
textfont=dict(size=25), marker=dict(colors=colors,line=dict(color='#000000',width=3)))
# hoverinfo='label+percent':显示标签+百分比
# textinfo='value':饼图上文字显示value值
# textfont=dict(size=25):文字大小25号
# marker=dict(colors=colors,line=dict(color='#000000',width=3)):颜色用colors内的颜色,线条用黑色,宽度3。
data=[trace]
iplot(data)
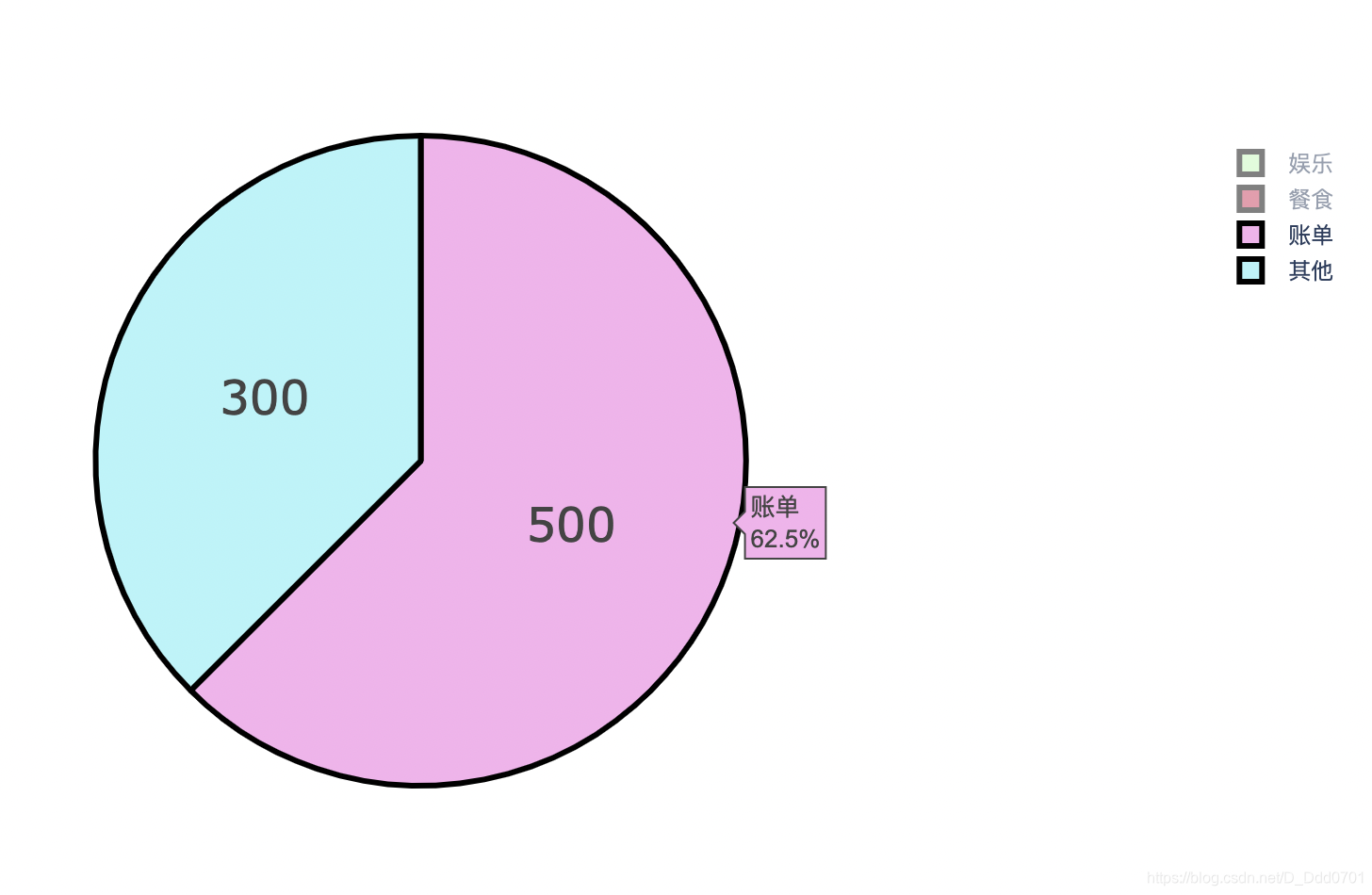
也可以只显示需要的部分,并且百分比会重新计算:
使用自定义数据(PUBG吃鸡游戏数据)绘制
数据来源
网站:kaggle网
利用Pandas联动Plotly
利用Pandas读取csv文件数据:
from plotly.offline import download_plotlyjs , init_notebook_mode,plot ,iplot
import plotly.graph_objs as go
import pandas as pd
pubg = pd.read_csv("PUBG.csv")
pubg.head()

做可视化要求数据是数值类型,用info语句查看:
pubg.info()

查看字段:
pubg.columns

处理数据结构
df_pubg = pubg.apply(pd.to_numeric,errors = 'ignore')
# 所有的数据转化成数值类型,错误忽略
df_new_pubg = df_pubg.head(100)
绘制散点图
trace = go.Scatter(x = df_new_pubg.solo_RoundsPlayed ,y = df_new_pubg.solo_Wins , name = 'Rounds Won' ,mode='markers')
layout = go.Layout(title =" PUBG win vs round played " ,plot_bgcolor='rgb(230,230,230)' ,showlegend=True)
# 对输出内容进行设置
# plot_bgcolor:背景颜色
# showlegend=True:显示图示
fig = go.Figure(data=[trace] , layout=layout)
# 把trace和layout组合在一张画布上
iplot(fig)
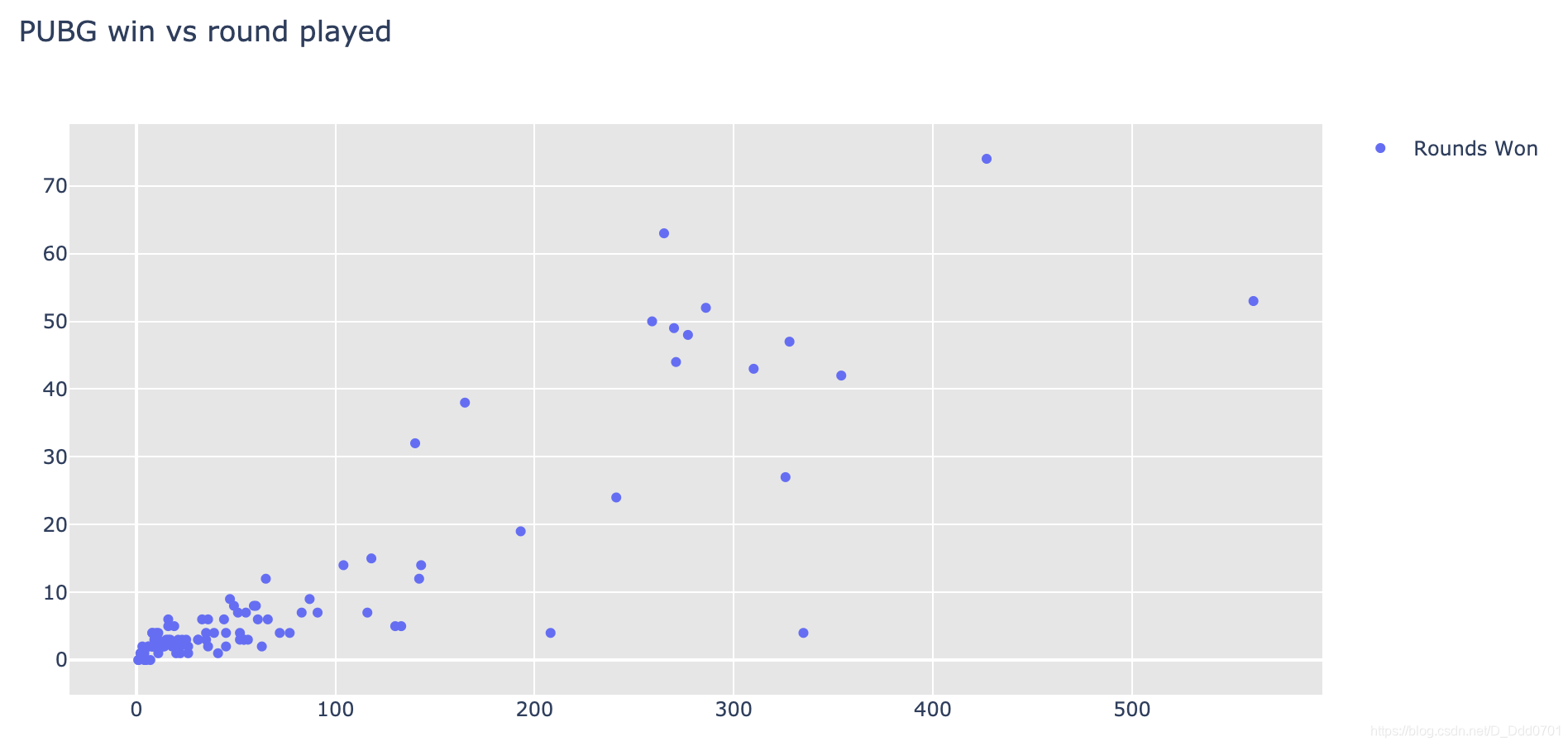
两组数据绘制柱状图
trace1 = go.Bar(x=df_new_pubg.player_name, y=df_new_pubg.solo_RoundsPlayed, name='Rounds Play')
trace2 = go.Bar(x=df_new_pubg.player_name, y=df_new_pubg.solo_Wins, name='Wins')
layout = go.Layout(barmode='group')
fig = go.Figure(data=[trace1,trace2] , layout=layout)
iplot(fig)
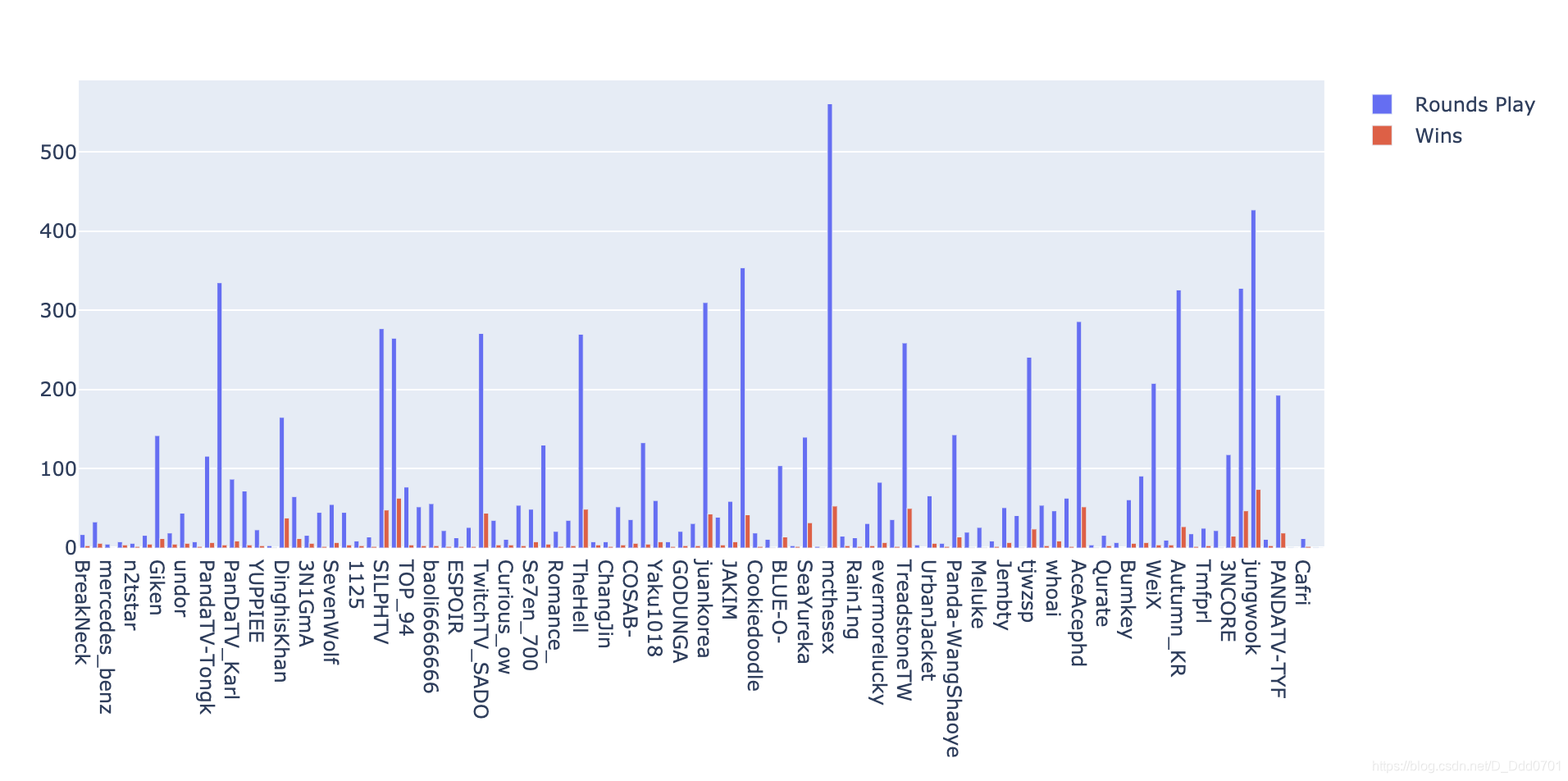
density密度图
数据沿用数据可视化分析2.3的PUGB吃鸡数据文件。
from plotly.offline import download_plotlyjs , init_notebook_mode,plot ,iplot
import plotly.graph_objs as go
import pandas as pd
pubg = pd.read_csv("PUBG.csv")
df_pubg = pubg.apply(pd.to_numeric,errors = 'ignore')
df_new_pubg = df_pubg.head(100)
import plotly.figure_factory as ff
2维图表需要两组数据:
x = df_new_pubg.solo_Wins
y = df_new_pubg.solo_TimeSurvived
设置参数:
colorscale = ['#7A4579','#D56073','rgb(236,158,105)',(1,1,0.2),(0.98,0.98,0.98)]
先不加入参数看看绘制效果
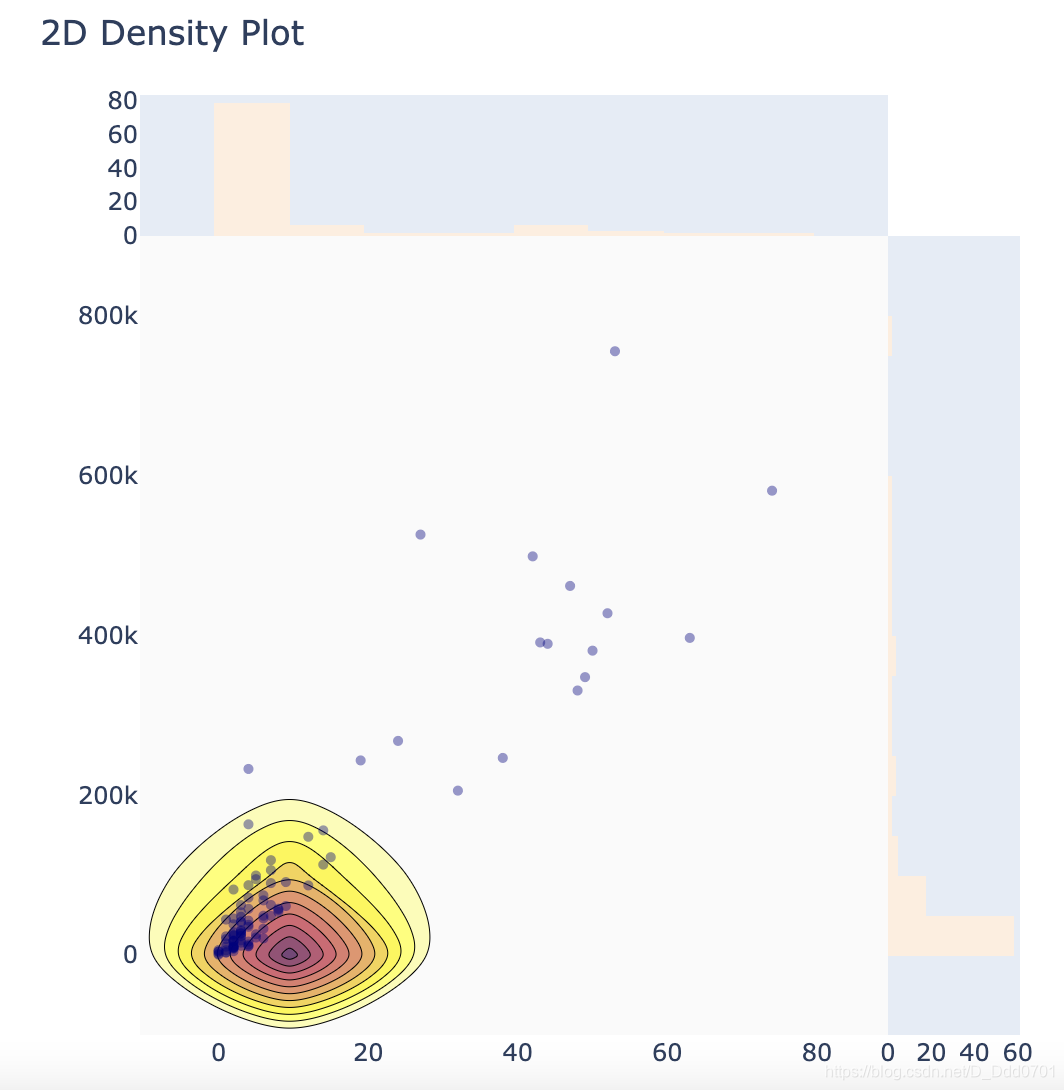
fig=ff.create_2d_density(x,y)
iplot(fig ,filename='histgram_subplot')
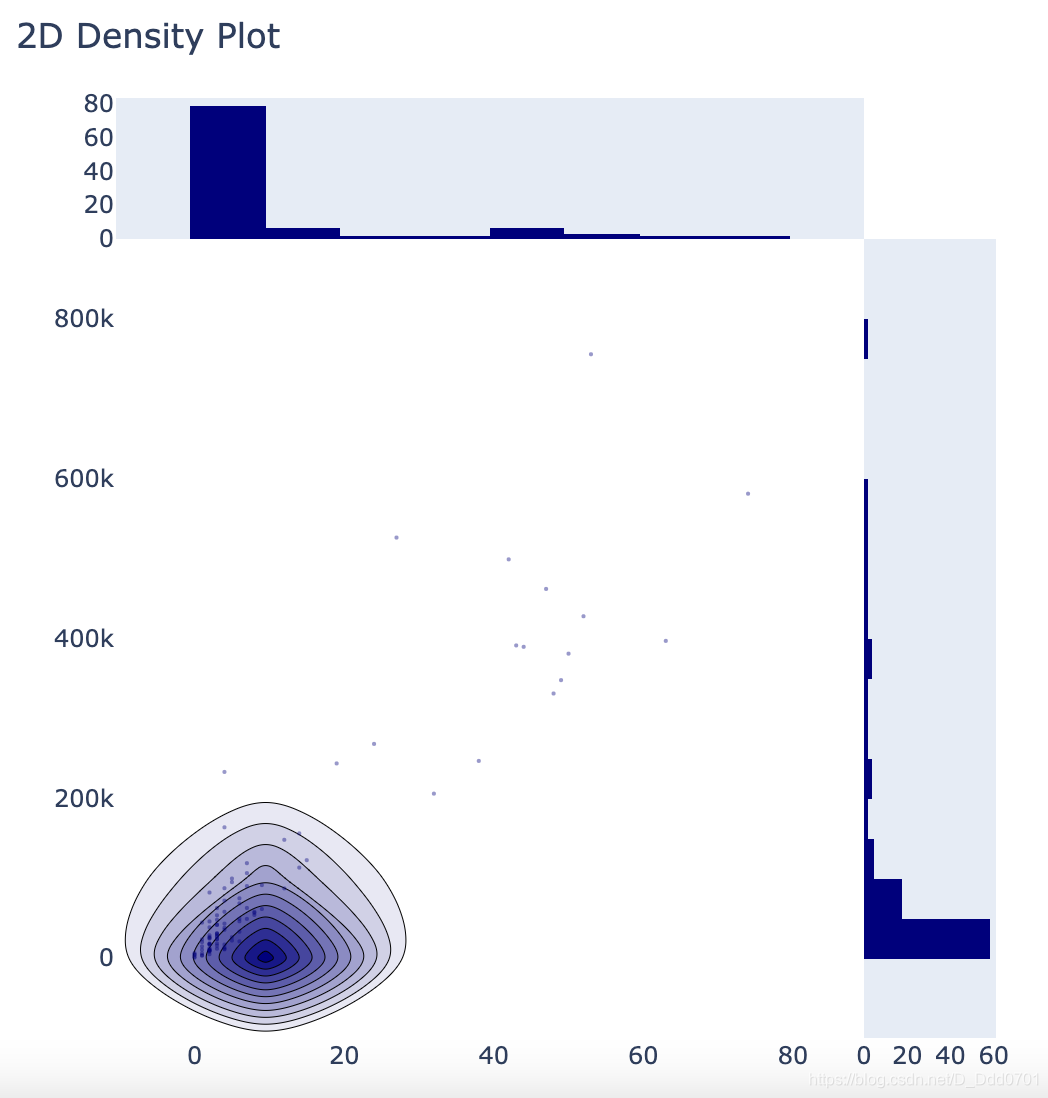
通过调色板进行颜色优化:
fig = ff.create_2d_density(x,y , colorscale= colorscale)
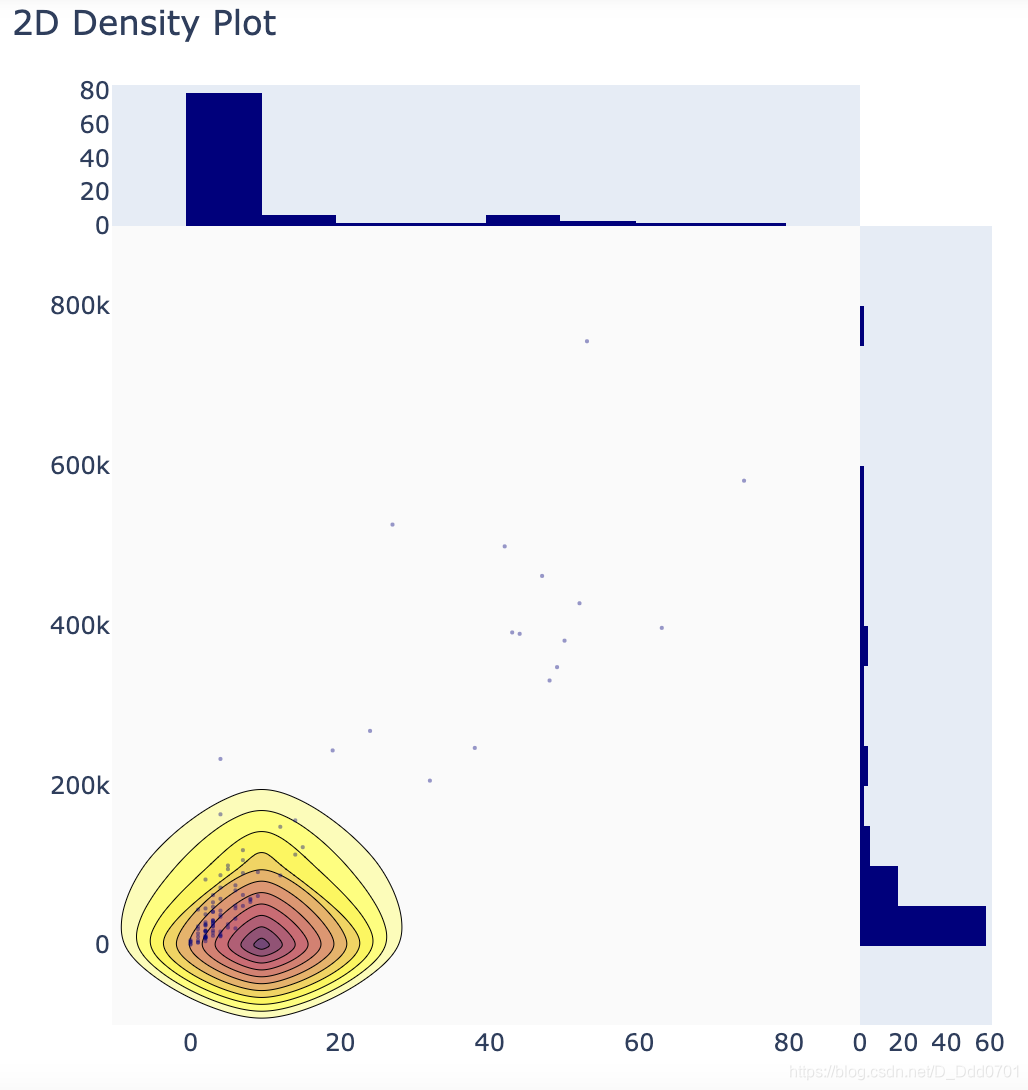
这里的密度图和直方图的颜色并不一致,接下来调整直方图颜色:
fig = ff.create_2d_density(x,y , colorscale= colorscale ,hist_color='rgb(255,237,222)' , point_size= 5)
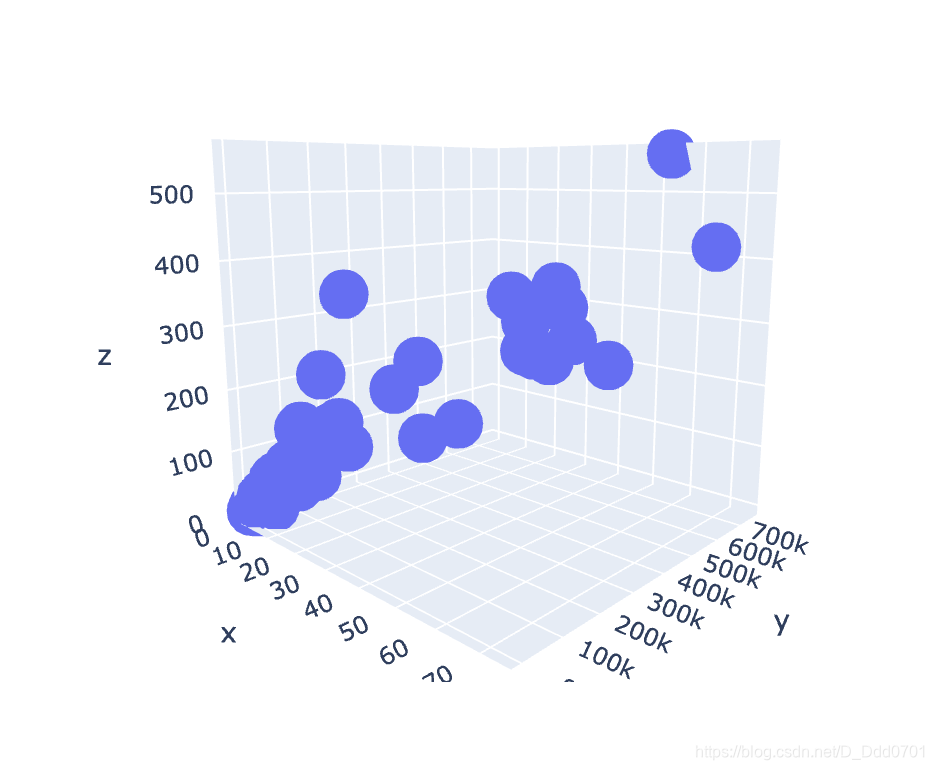
3d散点图
3d图就需要三个数据:
x = df_new_pubg.solo_Wins
y = df_new_pubg.solo_TimeSurvived
z = df_new_pubg.solo_RoundsPlayed
利用go语句给trace赋值:
trace1 = go.Scatter3d(
x=x,
y=y,
z=z,
mode='markers'
)
data=[trace1]
fig=go.Figure(data=data)
iplot(fig)
对marker参数进行优化:
trace1 = go.Scatter3d(
x=x,
y=y,
z=z,
mode='markers',
marker=dict(
size=12,
color=z,
colorscale='Viridis',
# 采用Viridis调色板
opacity=0.8,
showscale =True
# 增加图示
)
)
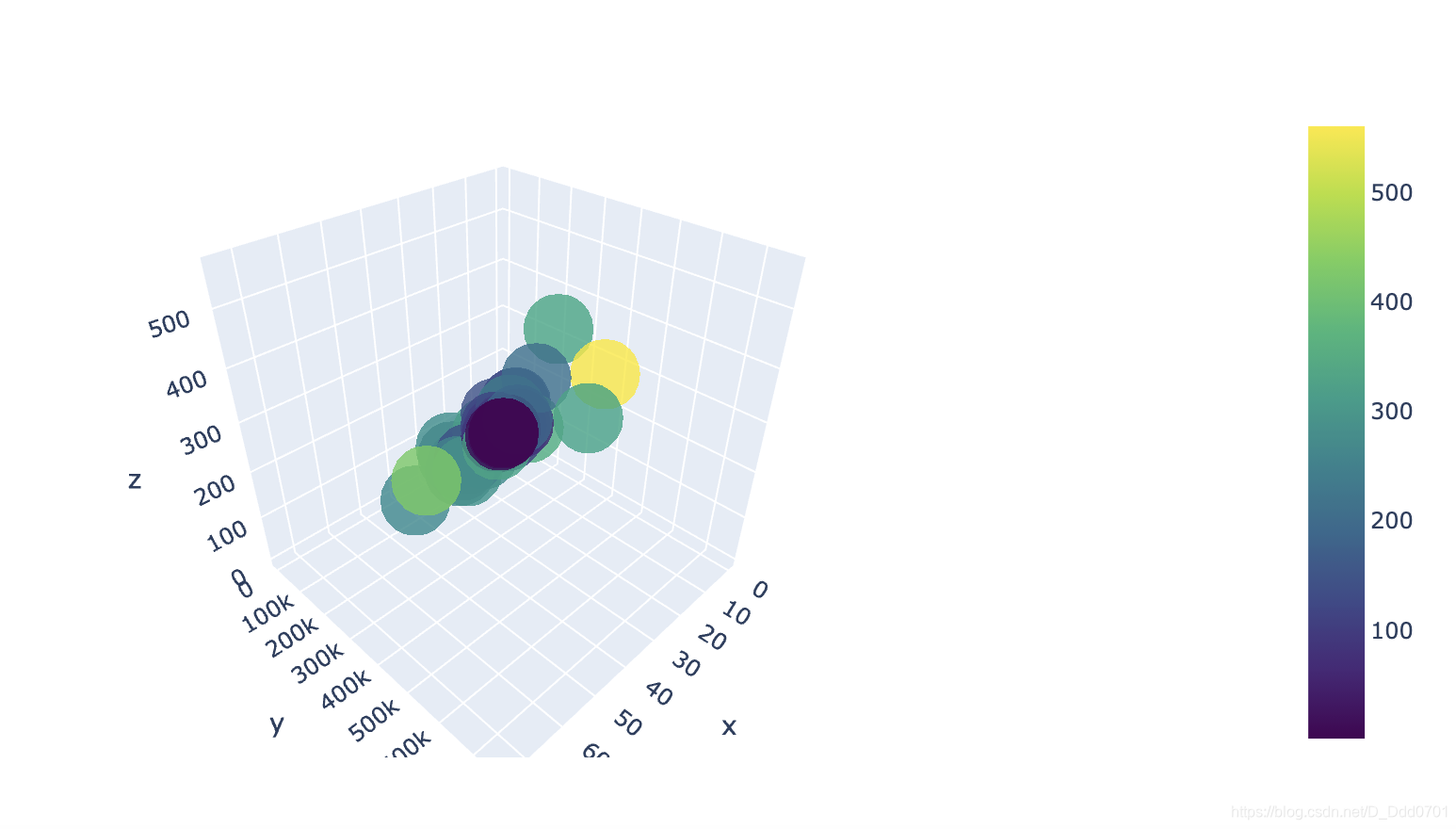
颜色越浅表面玩的次数越多。
再增加一个布局文件:
layout = go.Layout(margin=dict(
l=0,
r=0,
t=0,
b=0
))
fig = go.Figure(data=data , layout=layout)
iplot(fig,filename='3d')
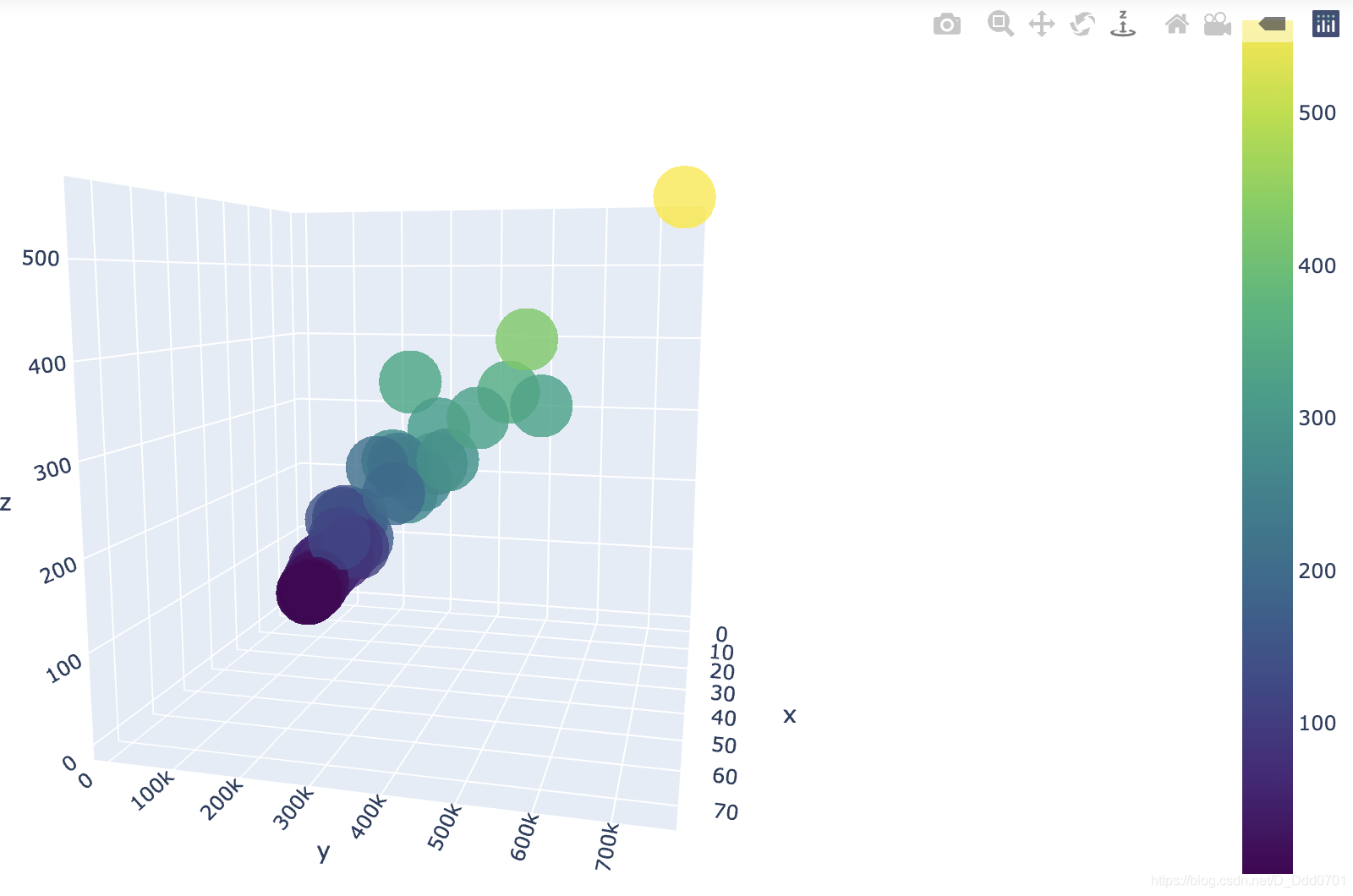
在线制图
在网上互动可视化是plotly最强大的特点之一。
首先需要在plotly官网点击Sign Up注册账号:plotly官网
登陆完成之后点击Settings:
之后找到API接口:
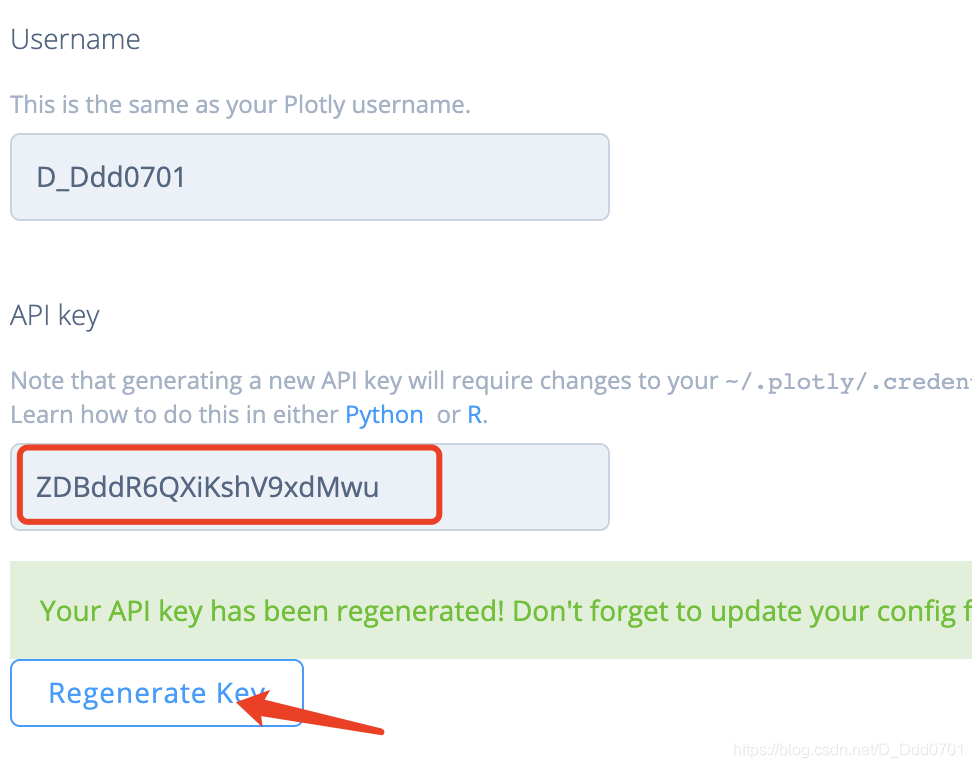
生成临时密码:
安装chart_studio库:
开始上传图片:
import chart_studio
import chart_studio.plotly as py
chart_studio.tools.set_credentials_file(username='D_Ddd0701',api_key='ZDBddR6QXiKshV9xdMwu')
# 输入网站上注册的用户名和生成的API
init_notebook_mode(connected=True)
# 笔记本和线上做连接
# 把刚才的代码复制过来,加入py.iplot
fig = go.Figure(data=data , layout=layout)
py.iplot(fig,filename='3d')
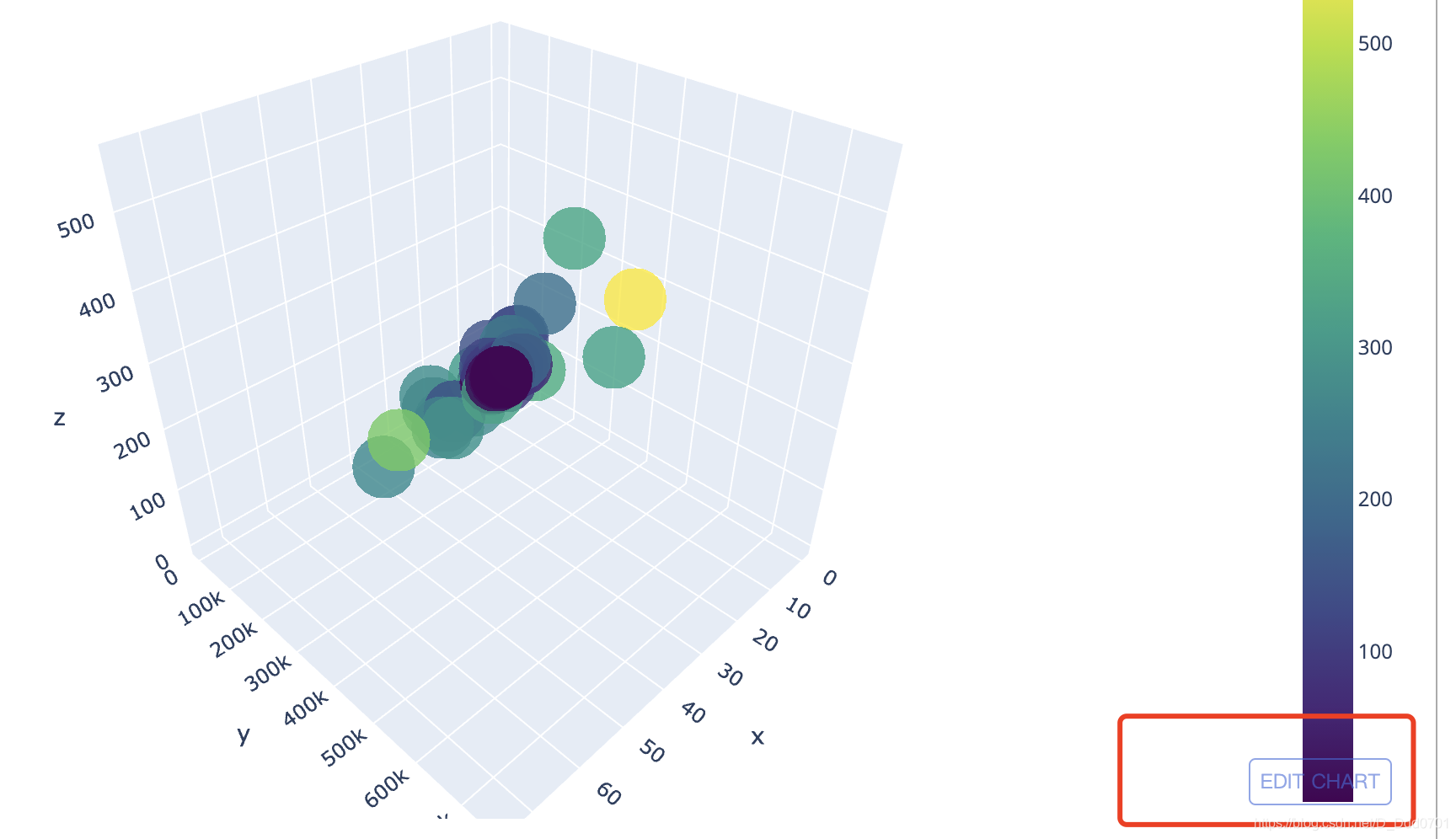
点击右下角EDIT按钮,进入网页发现图片已经上传上去,点击Save储存。

确定内容后再次点击Save:
此时图片已经被上传到个人File内:
点击Viewer可以浏览,也可以点击Editor编辑。
同样,也可以去参观别人做的图学习一下别人怎么做的。
实时金融数据绘制
本案例用苹果和特斯拉股票做例子。
利用Pandas导入数据
from plotly.offline import download_plotlyjs , init_notebook_mode,plot ,iplot
import plotly.graph_objects as go
import pandas as pd
df = pd.read_csv('APPL.csv')
df.head()

可以看到数据包含日期,开盘收盘成交量等数据。
绘制图表
利用go语句存放数据:
trace1=go.Scatter(
x=df['Date'],
y=df['AAPL.Close']
)
iplot([trace1])
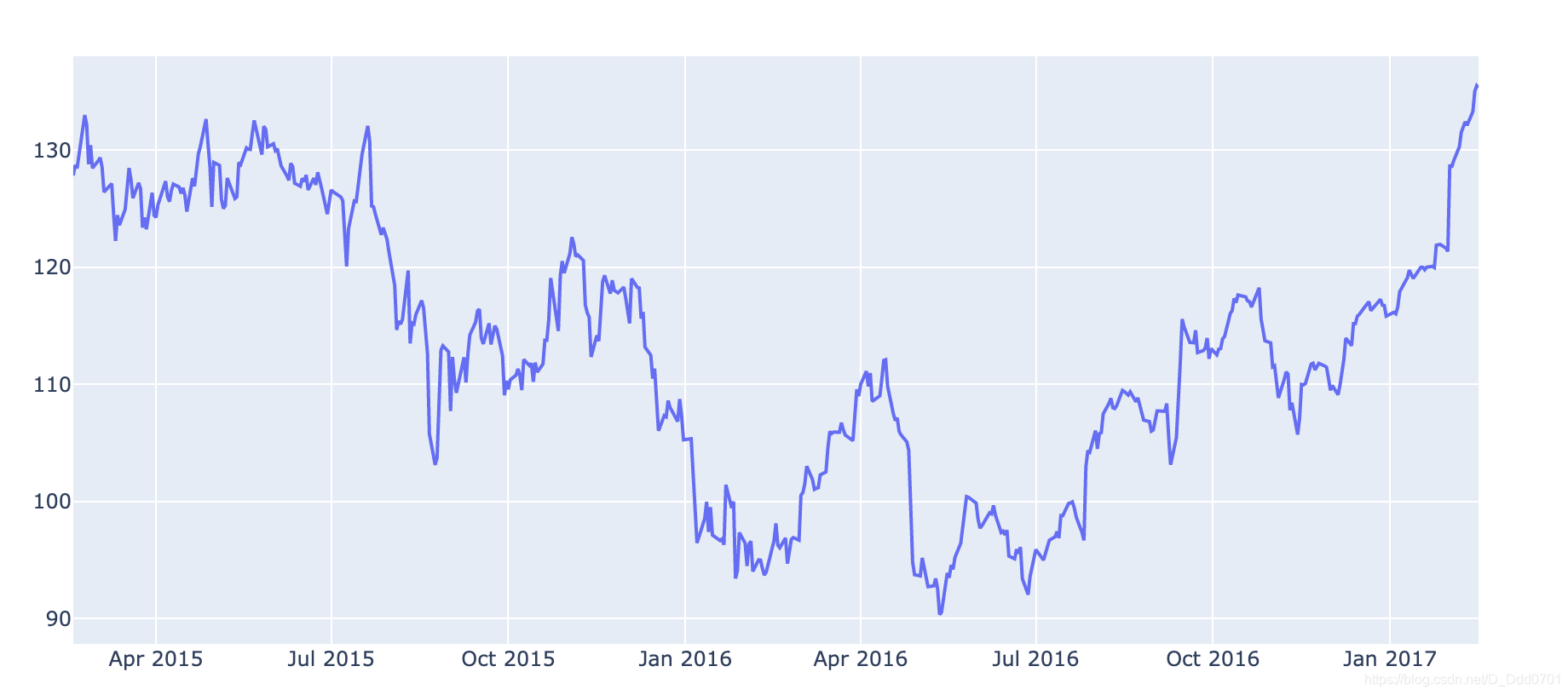
利用同样的方法绘制特斯拉。我们这里绘制特斯拉股票的最高价和最低价。
df2 = pd.read_csv('Tesla.csv')
trace_a = go.Scatter(
x = df2.date,
y = df2.high,
name = "Tesla High",
line = dict(color = '#17BECF'),
opacity =0.8
)
trace_b = go.Scatter(
x = df2.date,
y = df2.low,
name = "Tesla Low",
line = dict(color = '#7f7f7f'),
opacity =0.8
)
data=[trace_a, trace_b]
iplot(data)
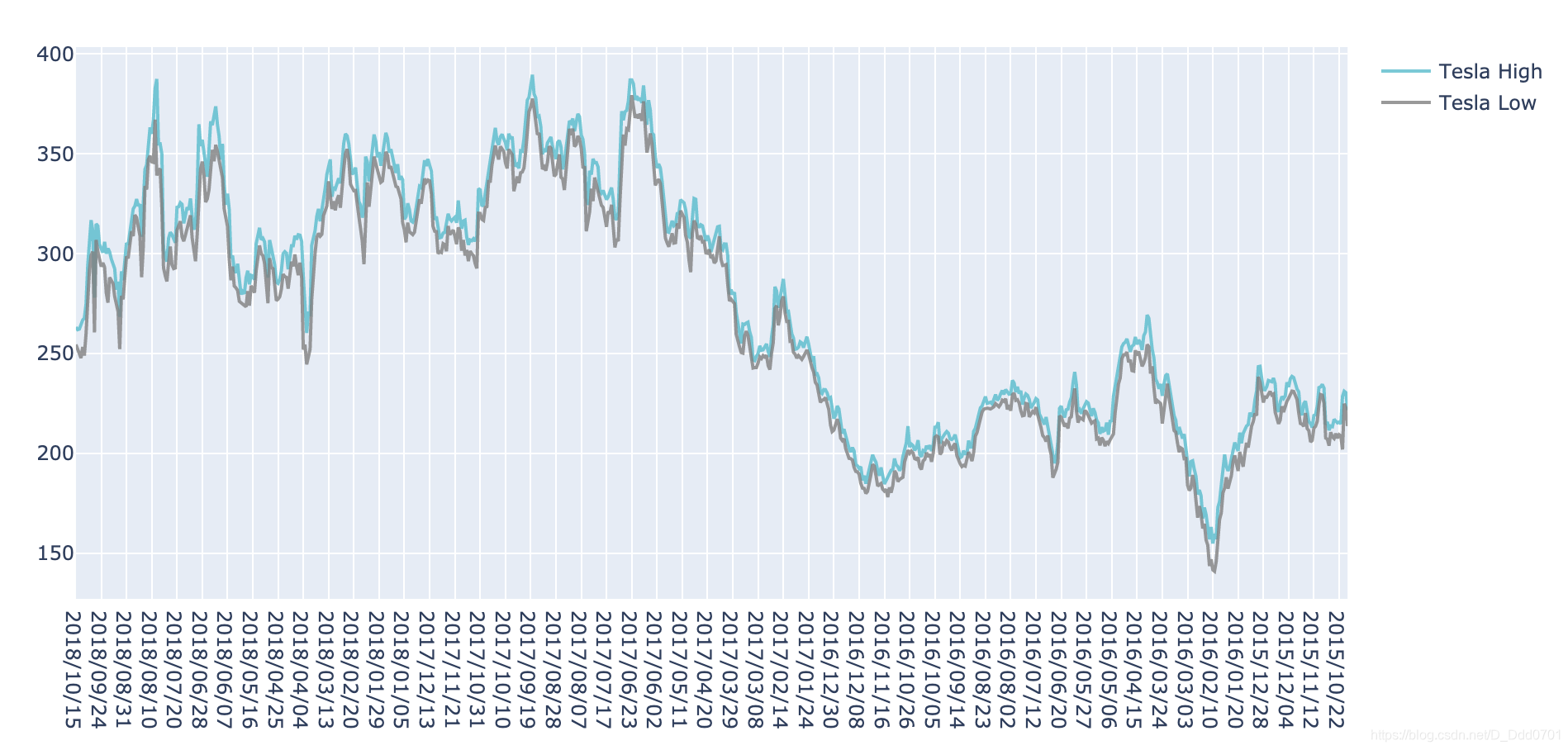
对布局做一些调整Layout:
layout = dict(title = "Tesla stock High vs Low")
fig = dict(data = data,layout = layout)
iplot(fig)
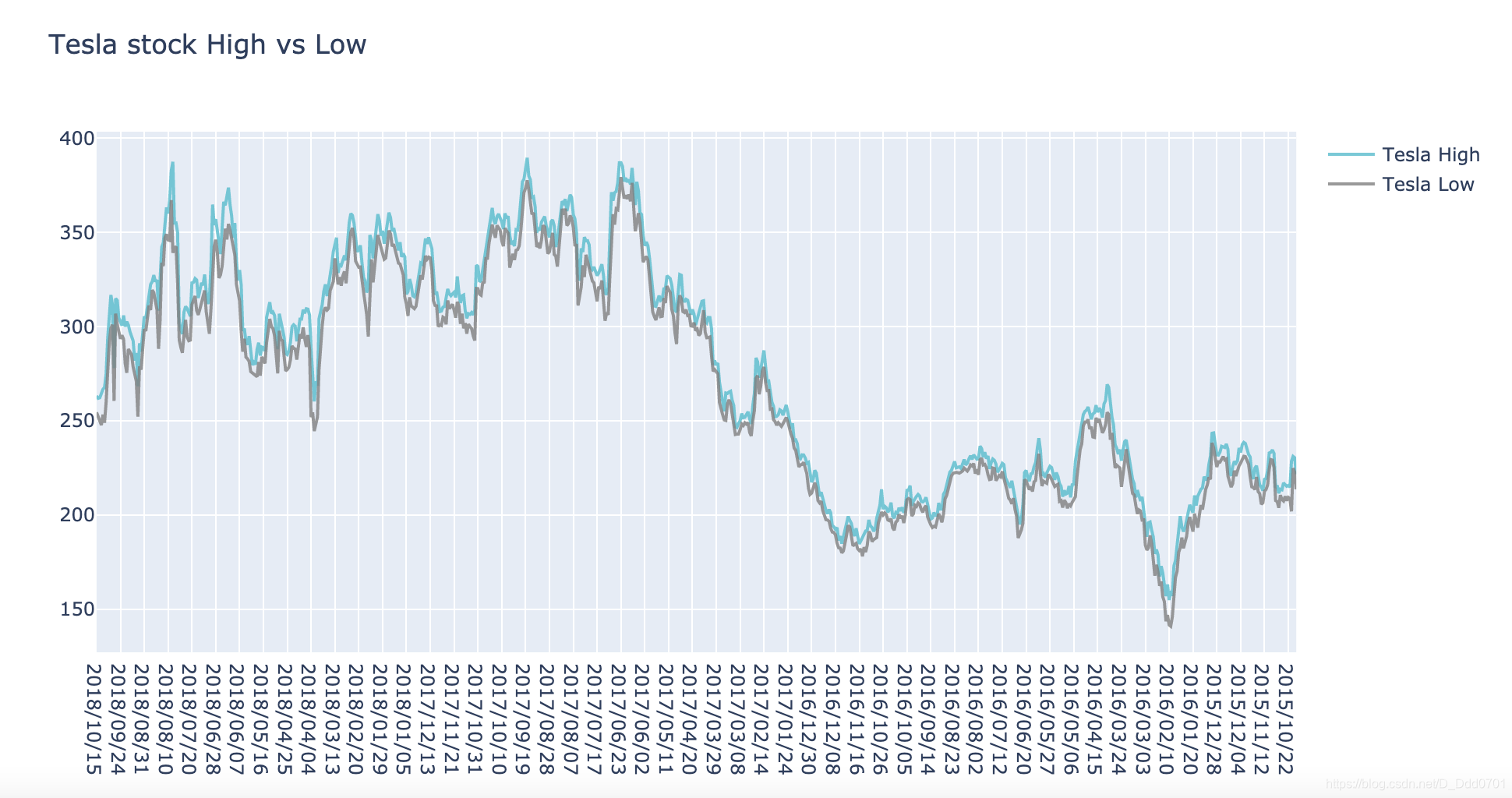
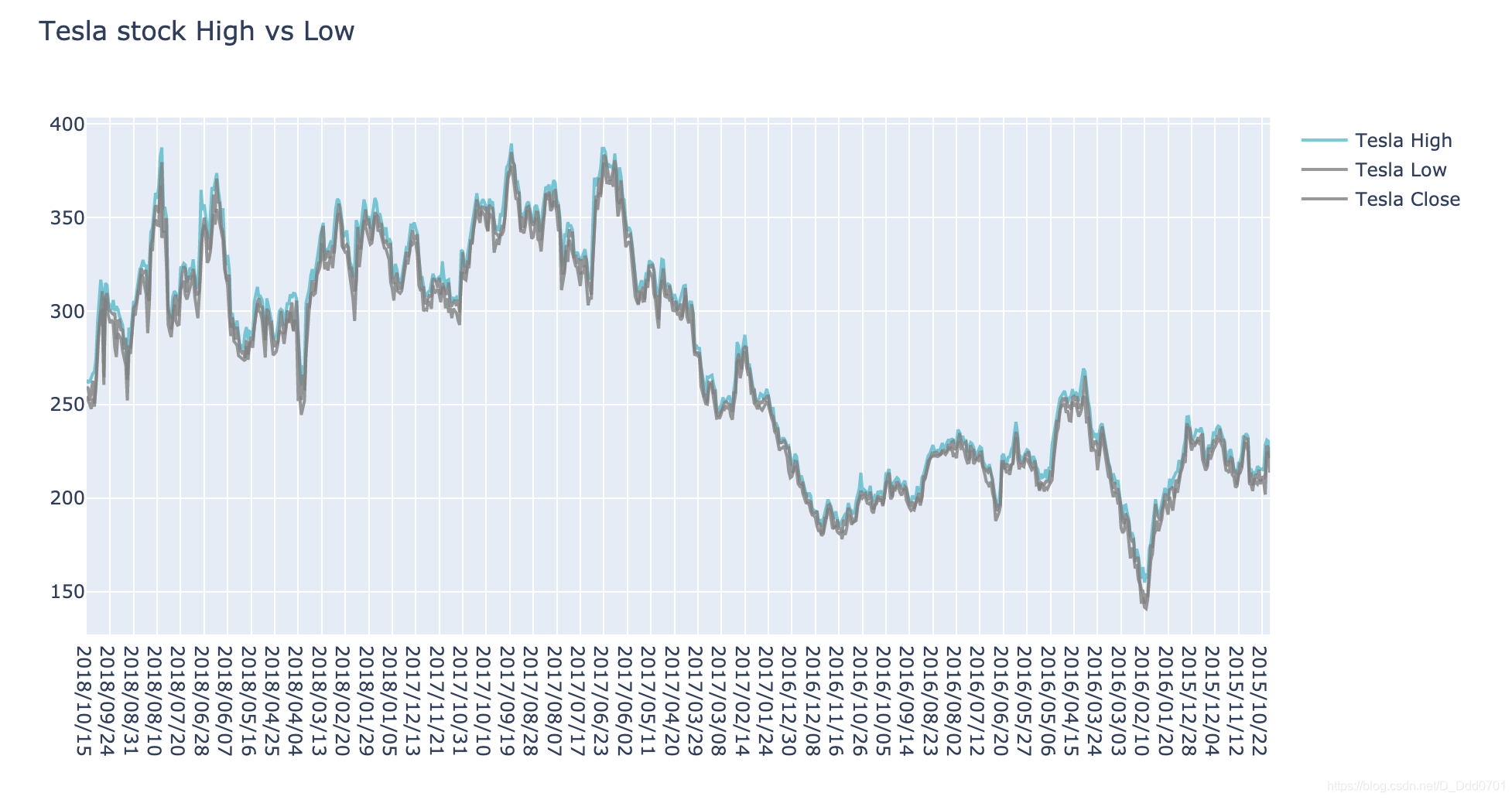
再加入一根收盘价线:
trace_c = go.Scatter(
x = df2.date,
y = df2.close,
name = "Tesla Close",
line = dict(color = '#7f7f7f'),
opacity =0.8
)
data =[trace_a,trace_b,trace_c]
引入金融特性——范围选择器
import plotly.express as px
fig = px.line(df2 , x='date',y='close') # 导入df2数据,x轴是date,y是close
fig.update_xaxes(rangeslider_visible=True) # 范围选择器
fig.show()
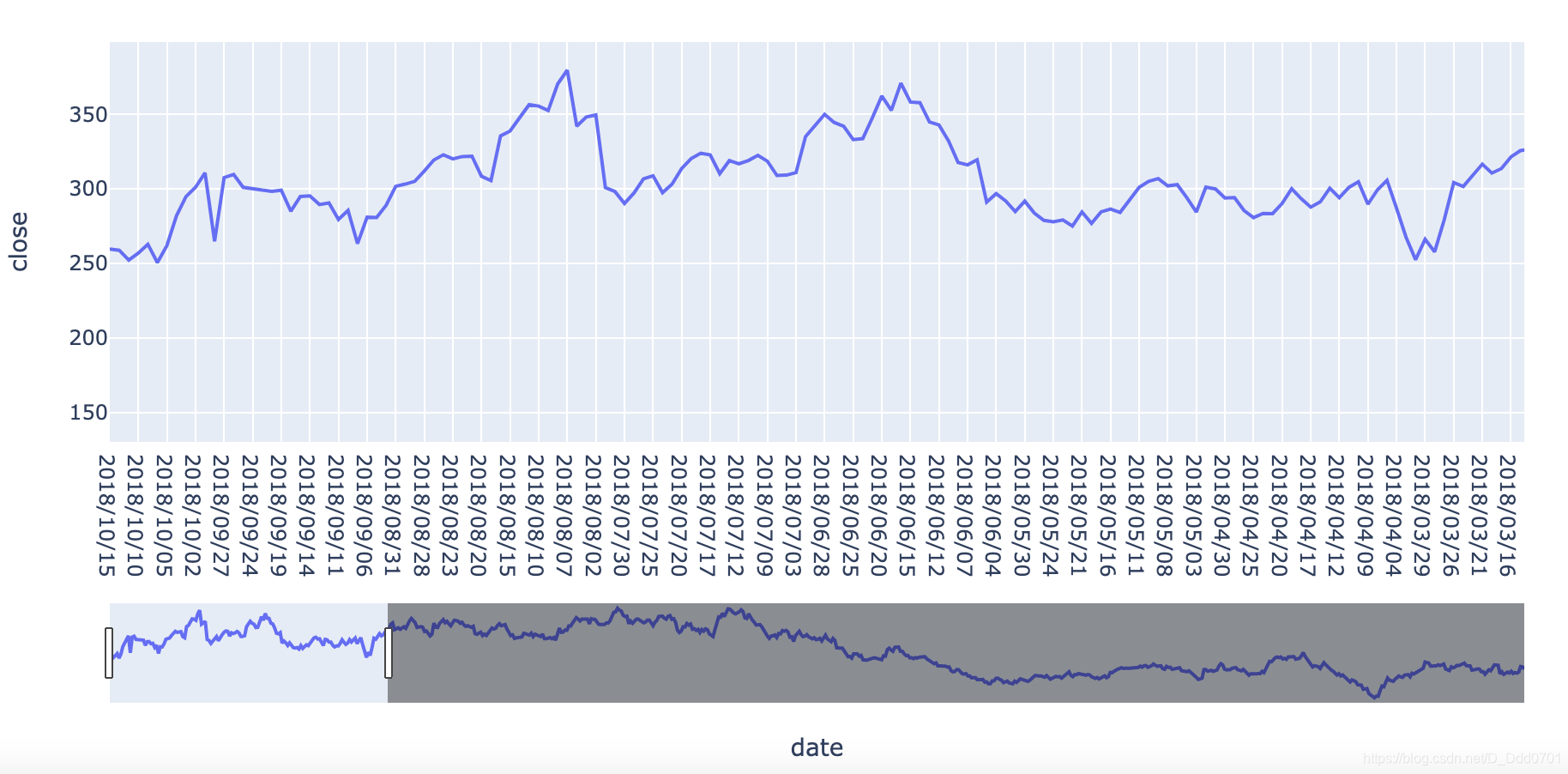
再看看苹果的:
fig = px.line(df, x='Date', y='AAPL.High', title='Time Series with Rangeslider')
fig.update_xaxes(rangeslider_visible=True)
fig.show()
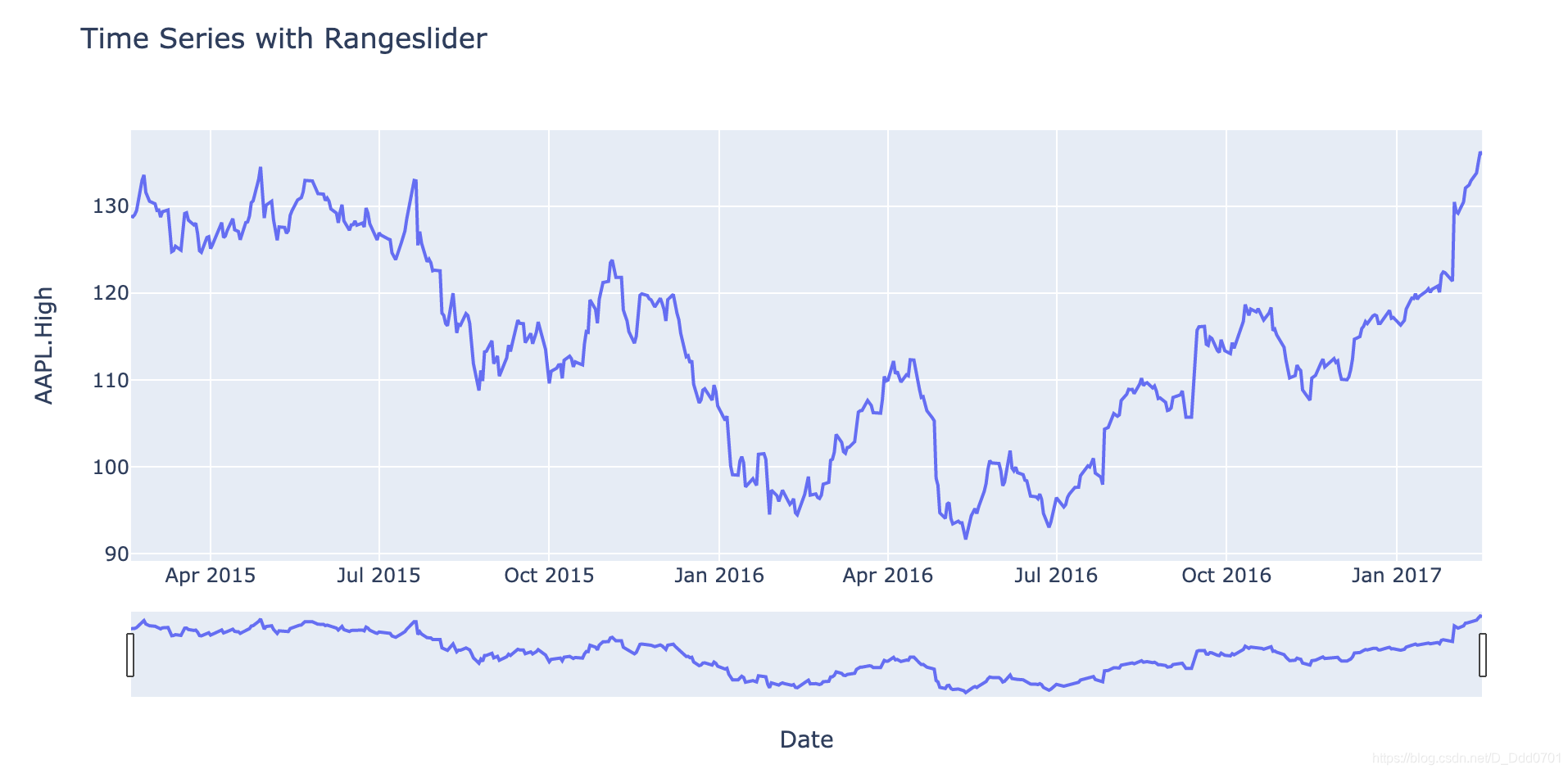
引入金融特性——日线,5日线等快捷键
fig = px.line(df, x='Date', y='AAPL.High', title='Time Series with Rangeslider')
fig.update_xaxes(rangeslider_visible=True,
rangeselector = dict(
buttons=list([
dict(count=1,label="1d",step="day",stepmode="backward"),
dict(count=5,label="5d",step="day",stepmode="backward"),
dict(count=1,label="1m",step="month",stepmode="backward"),
dict(count=3,label="3m",step="month",stepmode="backward"),
dict(count=6,label="6m",step="month",stepmode="backward"),
dict(count=1,label="1y",step="year",stepmode="backward"),
dict(step="all") #恢复到之前
])
)
)
fig.show()
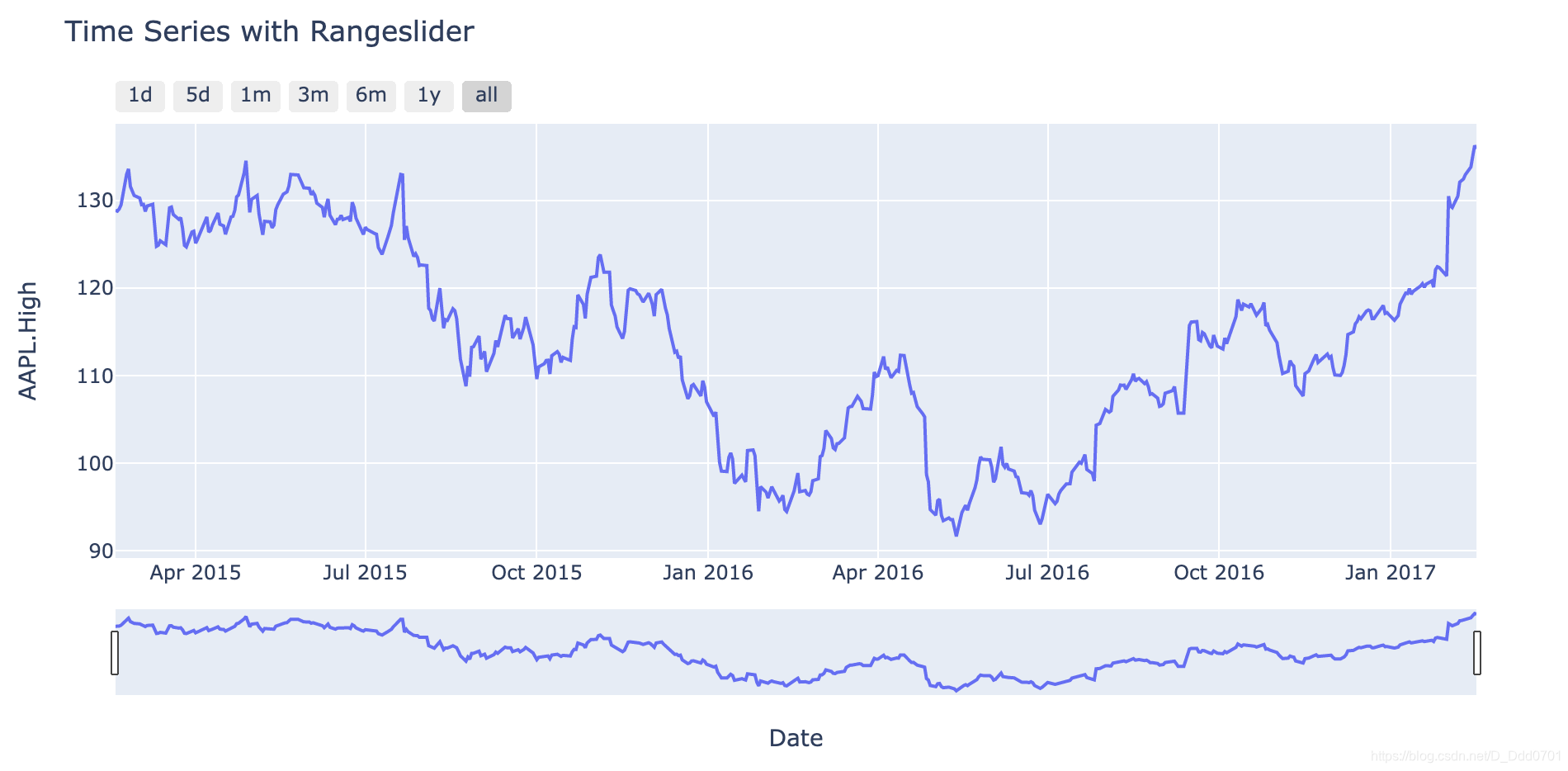
引入金融特性——蜡烛图
蜡烛图代码:
go.Candlestick(
x=日期,
open=开盘价,
high=最高价,
low=最低价,
close=收盘价
)
fig = go.Figure(data=[go.Candlestick(
x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close']
)
]
)
ig = go.Figure(data=[go.Candlestick(
x=df['Date'],
open=df['AAPL.Open'],
high=df['AAPL.High'],
low=df['AAPL.Low'],
close=df['AAPL.Close']
)
]
)
fig.update_xaxes(rangeslider_visible=True,
rangeselector = dict(
buttons=list([
dict(count=1,label="日",step="day",stepmode="backward"),
dict(count=5,label="五日",step="day",stepmode="backward"),
dict(count=1,label="月线",step="month",stepmode="backward"),
dict(count=3,label="季线",step="month",stepmode="backward"),
dict(count=6,label="半年线",step="month",stepmode="backward"),
dict(count=1,label="年线",step="year",stepmode="backward"),
dict(step="all")
])
)
)
fig.show()
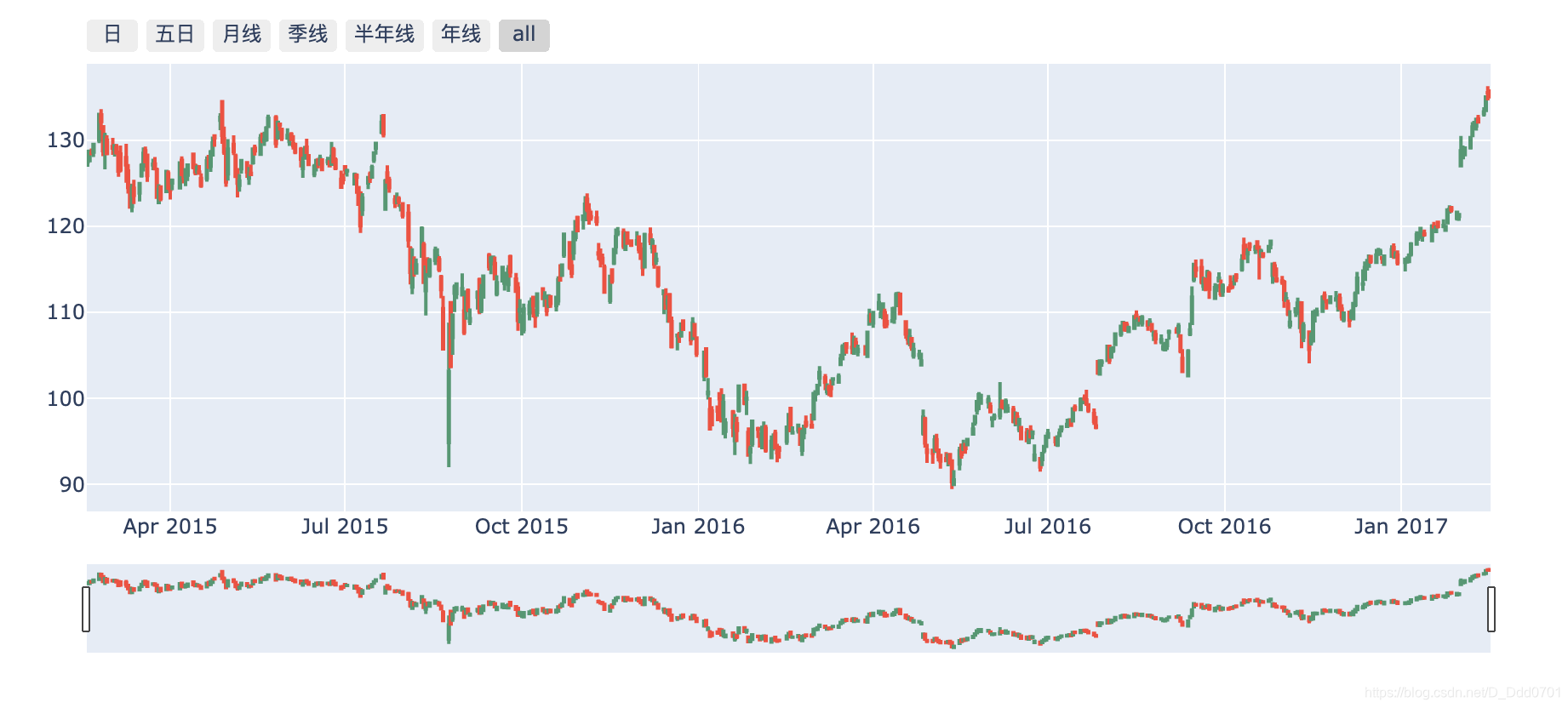
引入金融特性——指标
import cufflinks as cf
cf.set_config_file(offline=True,world_readable=True) #设置offline=True和python关联
用cf自带模拟器生成k线数据:
df= cf.datagen.ohlc()
df.head()
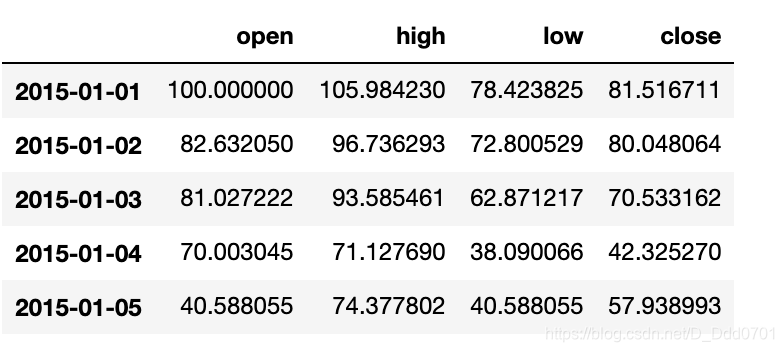
qf=cf.QuantFig(df) # 把df内的数据变为金融数据

用qf.iplot()画K线图:
qf.iplot()
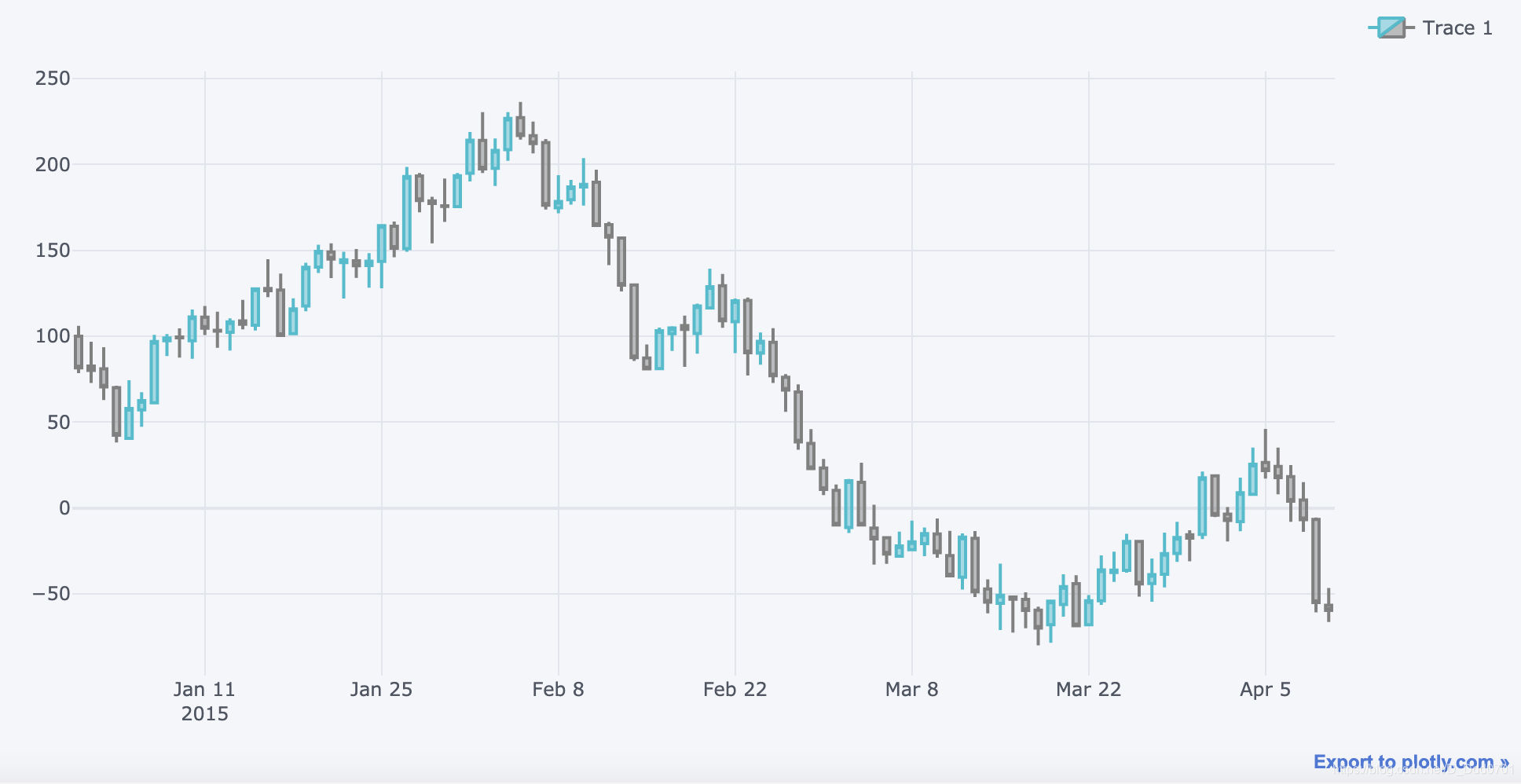
增加macd指标
增加macd指标:qf.add_macd()
qf.add_macd()
qf.iplot()
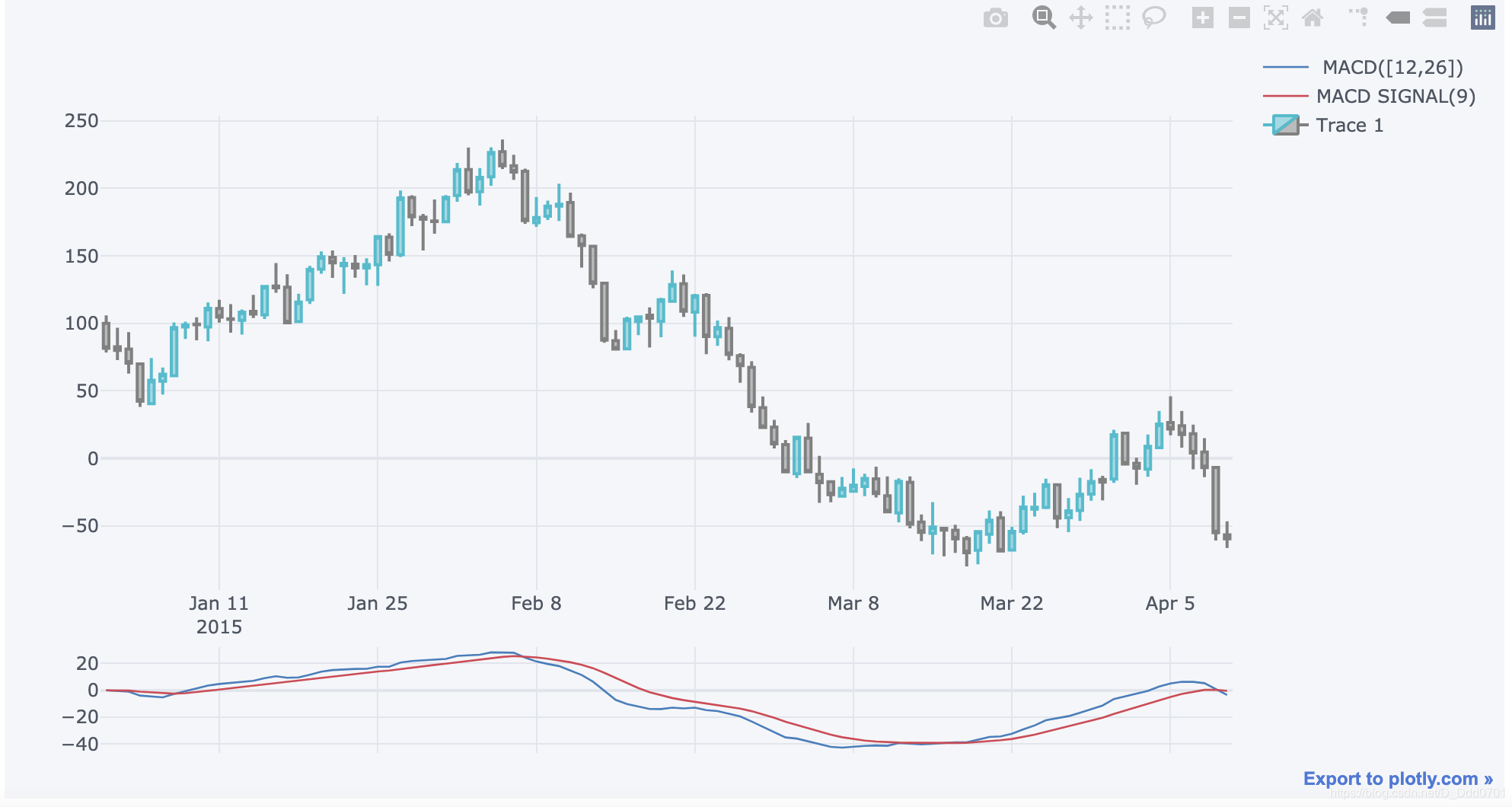
增加rsi指标
增加rsi指标:qf.add_rsi()

这里根据个人,输入数值:
qf.add_rsi(6,80) #周期6天触发值80
qf.iplot()
增加布林带通道
增加布林带通道:qf.add_bollinger_bands()
qf.add_bollinger_bands()
qf.iplot()
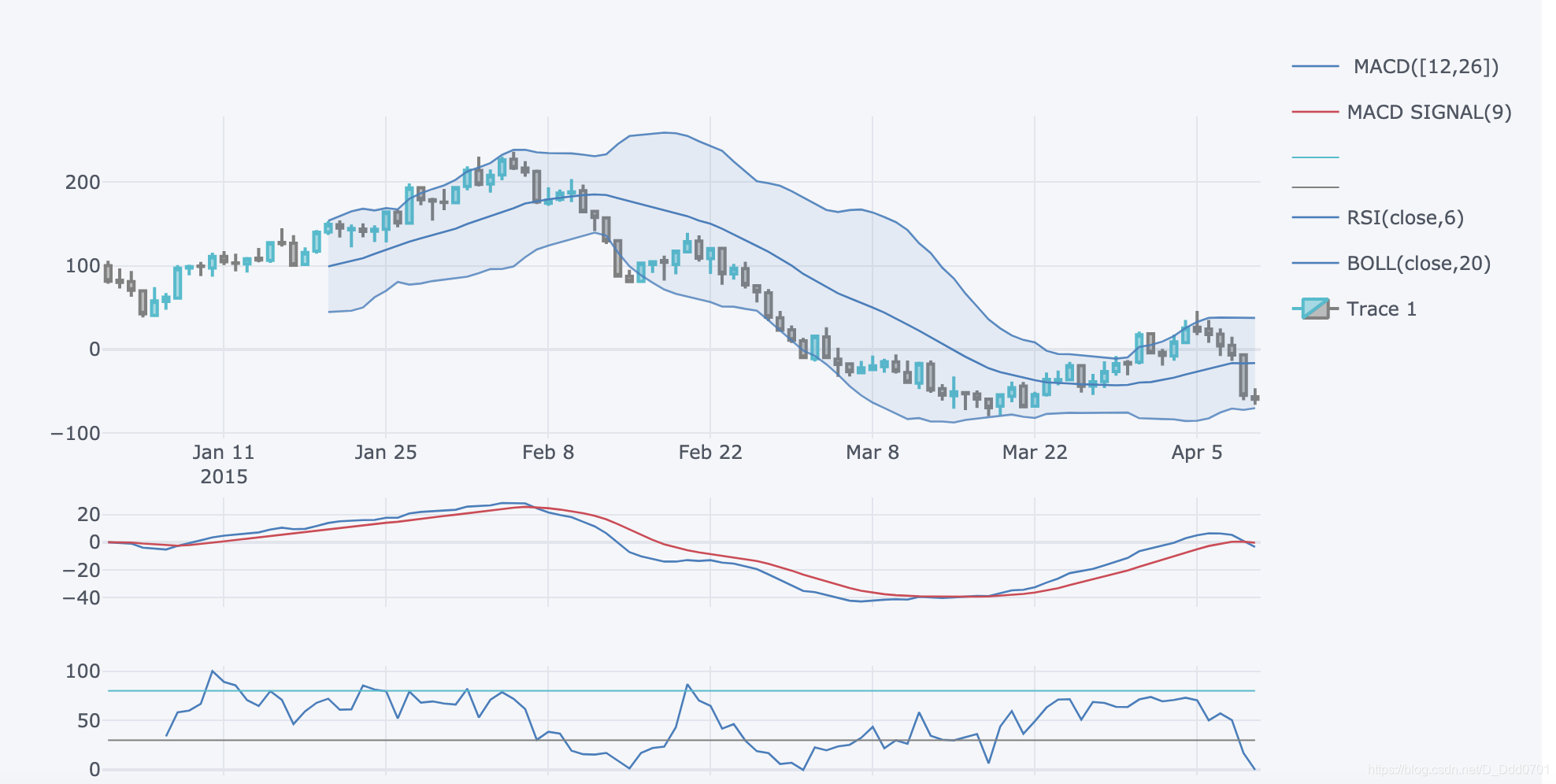
同样可以点击右上角关掉指标。
利用heatmap绘制热力图
引入类库:
import pandas as pd
import numpy as np
import chart_studio.plotly as py
import seaborn as sns
import plotly.express as px
%matplotlib inline #代表所有绘制的图表都内嵌在网页中
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
利用Pandas导入数据
flights = sns.load_dataset("flights")
flights.head()
这里使用的是seaborn自带数据库,可能会出现报错IncompleteRead,解决方法:
1、csv文件下载地址,点击下载。
2、将下载后的fights.csv拷贝放入seaborn-data文件夹。
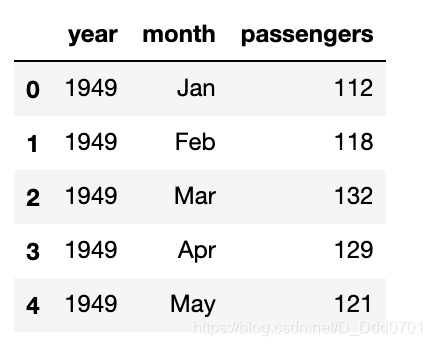
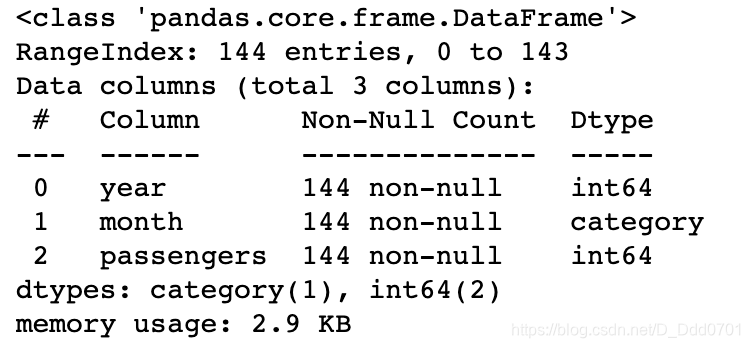
查看数据类型:flights.info()
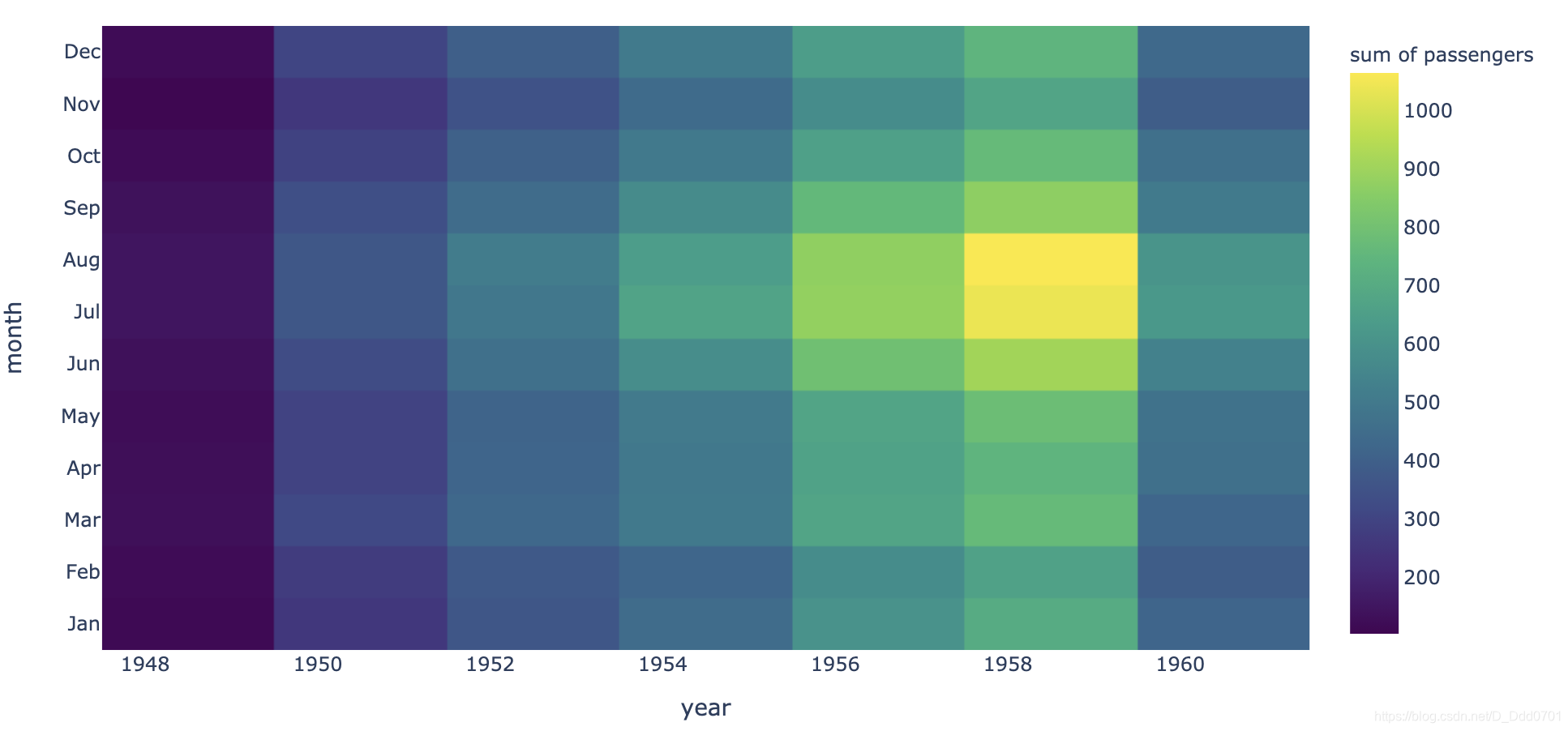
绘制热力图
热力图需要三个数据。
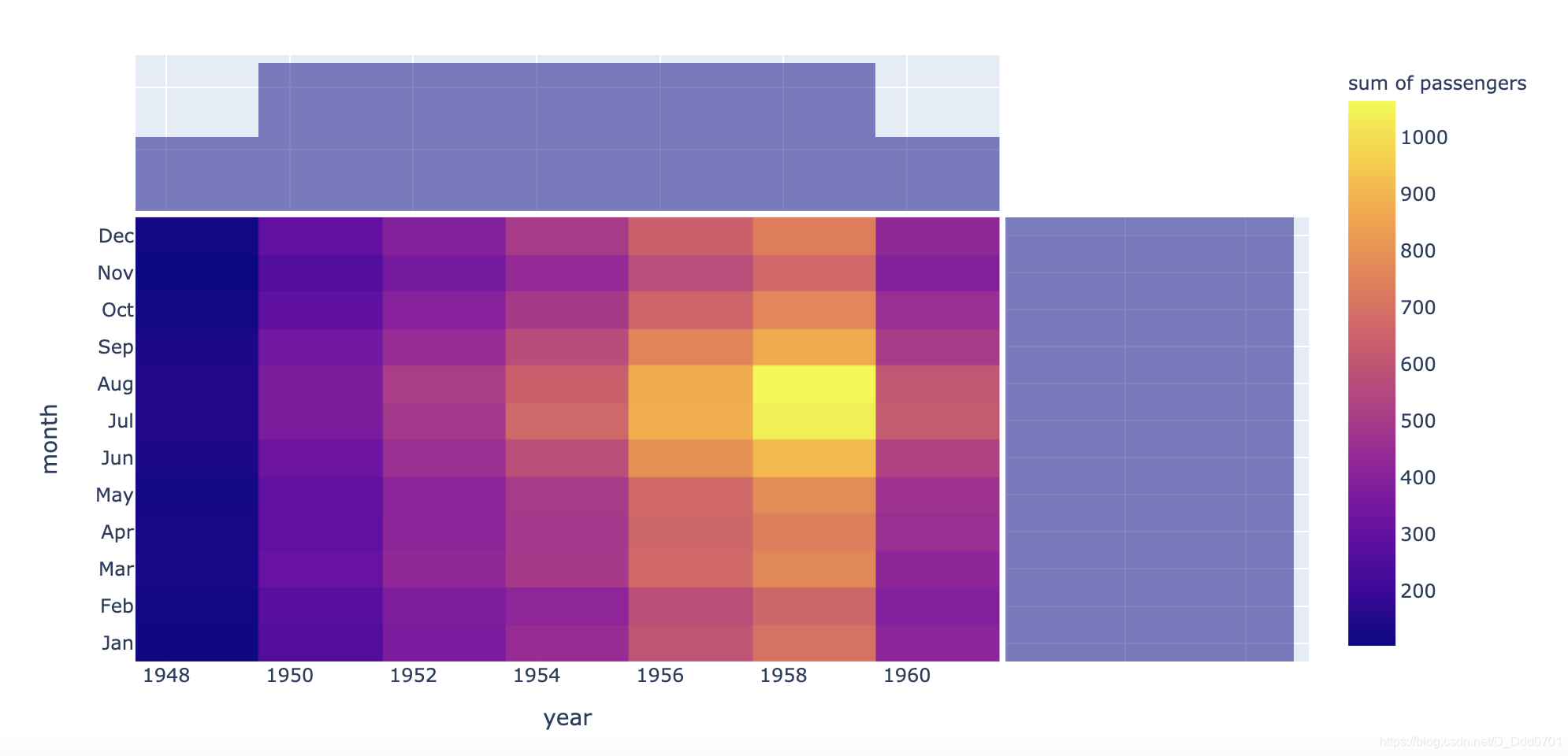
fig = px.density_heatmap(flights, x ='year' , y ='month' , z= 'passengers')

换个颜色:color_continuous_scale='配色器'
可选:One of the following named colorscales:
[‘aggrnyl’, ‘agsunset’, ‘algae’, ‘amp’, ‘armyrose’, ‘balance’,
‘blackbody’, ‘bluered’, ‘blues’, ‘blugrn’, ‘bluyl’, ‘brbg’,
‘brwnyl’, ‘bugn’, ‘bupu’, ‘burg’, ‘burgyl’, ‘cividis’, ‘curl’,
‘darkmint’, ‘deep’, ‘delta’, ‘dense’, ‘earth’, ‘edge’, ‘electric’,
‘emrld’, ‘fall’, ‘geyser’, ‘gnbu’, ‘gray’, ‘greens’, ‘greys’,
‘haline’, ‘hot’, ‘hsv’, ‘ice’, ‘icefire’, ‘inferno’, ‘jet’,
‘magenta’, ‘magma’, ‘matter’, ‘mint’, ‘mrybm’, ‘mygbm’, ‘oranges’,
‘orrd’, ‘oryel’, ‘oxy’, ‘peach’, ‘phase’, ‘picnic’, ‘pinkyl’,
‘piyg’, ‘plasma’, ‘plotly3’, ‘portland’, ‘prgn’, ‘pubu’, ‘pubugn’,
‘puor’, ‘purd’, ‘purp’, ‘purples’, ‘purpor’, ‘rainbow’, ‘rdbu’,
‘rdgy’, ‘rdpu’, ‘rdylbu’, ‘rdylgn’, ‘redor’, ‘reds’, ‘solar’,
‘spectral’, ‘speed’, ‘sunset’, ‘sunsetdark’, ‘teal’, ‘tealgrn’,
‘tealrose’, ‘tempo’, ‘temps’, ‘thermal’, ‘tropic’, ‘turbid’,
‘turbo’, ‘twilight’, ‘viridis’, ‘ylgn’, ‘ylgnbu’, ‘ylorbr’,
‘ylorrd’]
选择viridis试试。
fig = px.density_heatmap(flights, x ='year' , y ='month' , z= 'passengers' , color_continuous_scale='viridis')
用histogram方式统计
对x和y轴包含数据总数进行统计计数,需要使用marginal_x="histogram" ,marginal_y="histogram"
fig = px.density_heatmap(flights, x ='year' , y ='month' , z= 'passengers' ,marginal_x="histogram" ,marginal_y="histogram")
用3D折线图反应热力图
fig = px.line_3d(flights , x ='year' , y ='month' , z= 'passengers' ,color='year') # color='year'表示每一年的数据用不同颜色
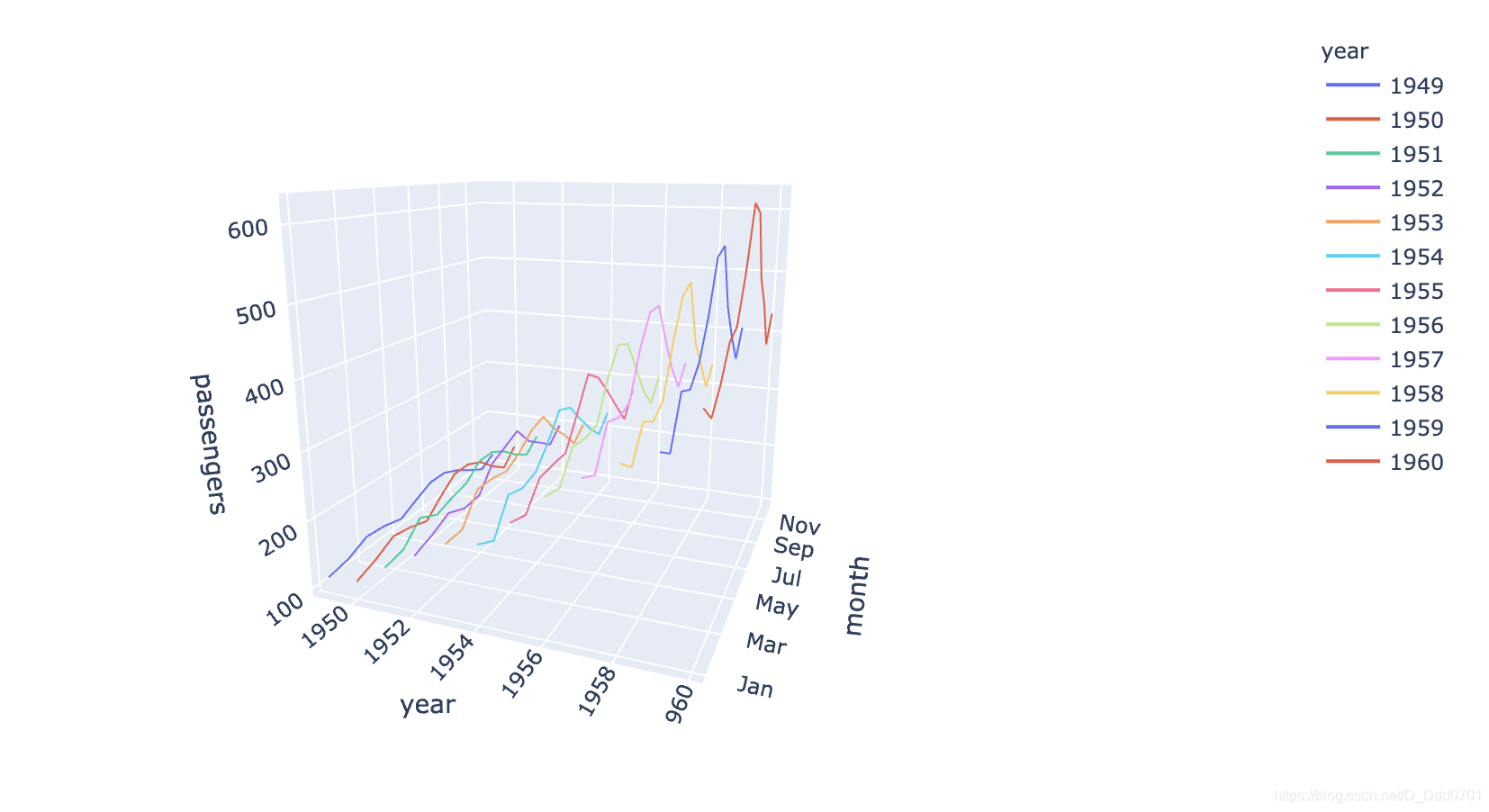
这和热力图反应的一致,随着年份增加,人数也在增加。7月数据一般最大的。
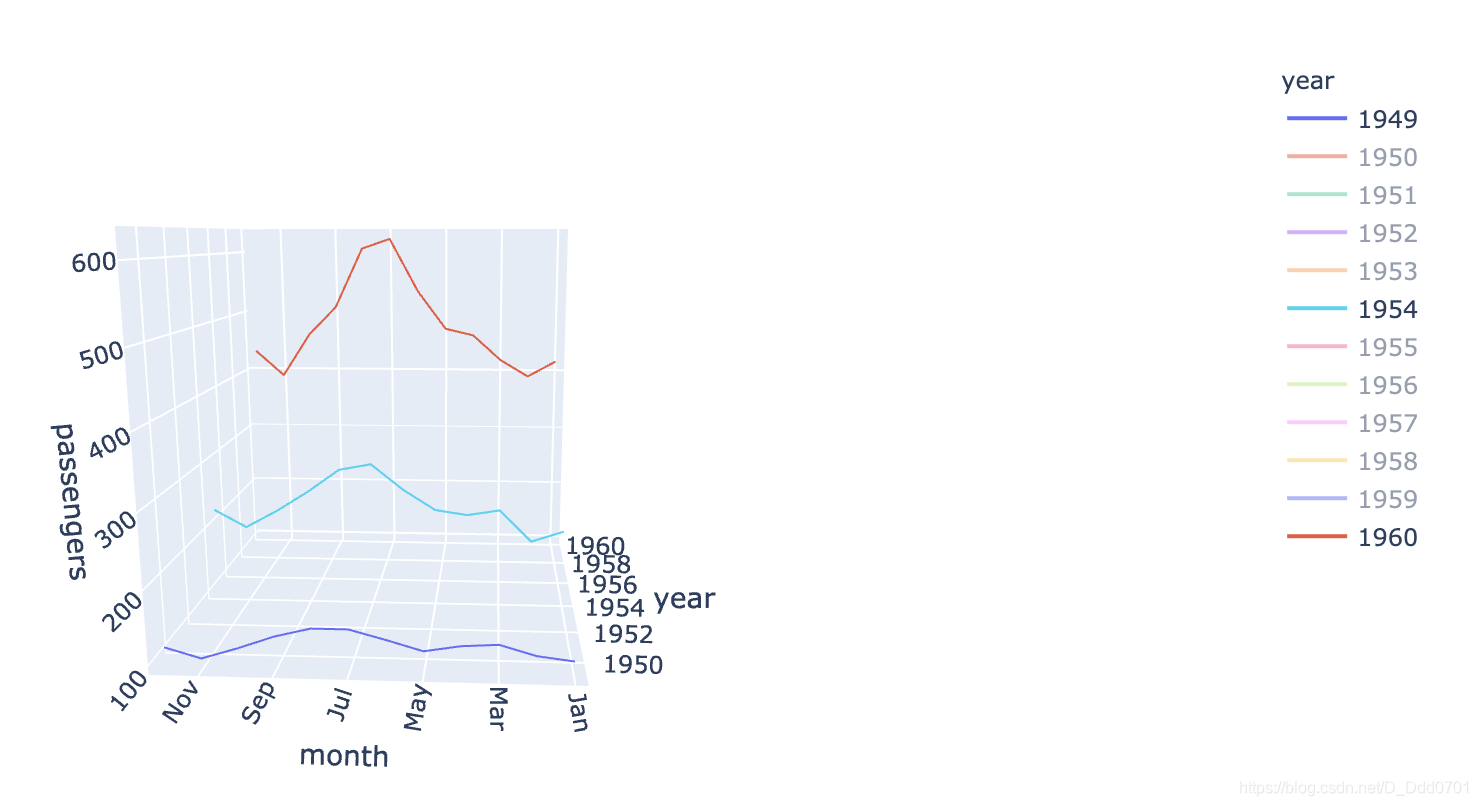
如果只看这么几年的数据,那么显示的变化规律会更加直观。
利用scatter绘制散点图
fig = px.scatter_3d(flights , x ='year' , y ='month' , z= 'passengers' ,color='year')
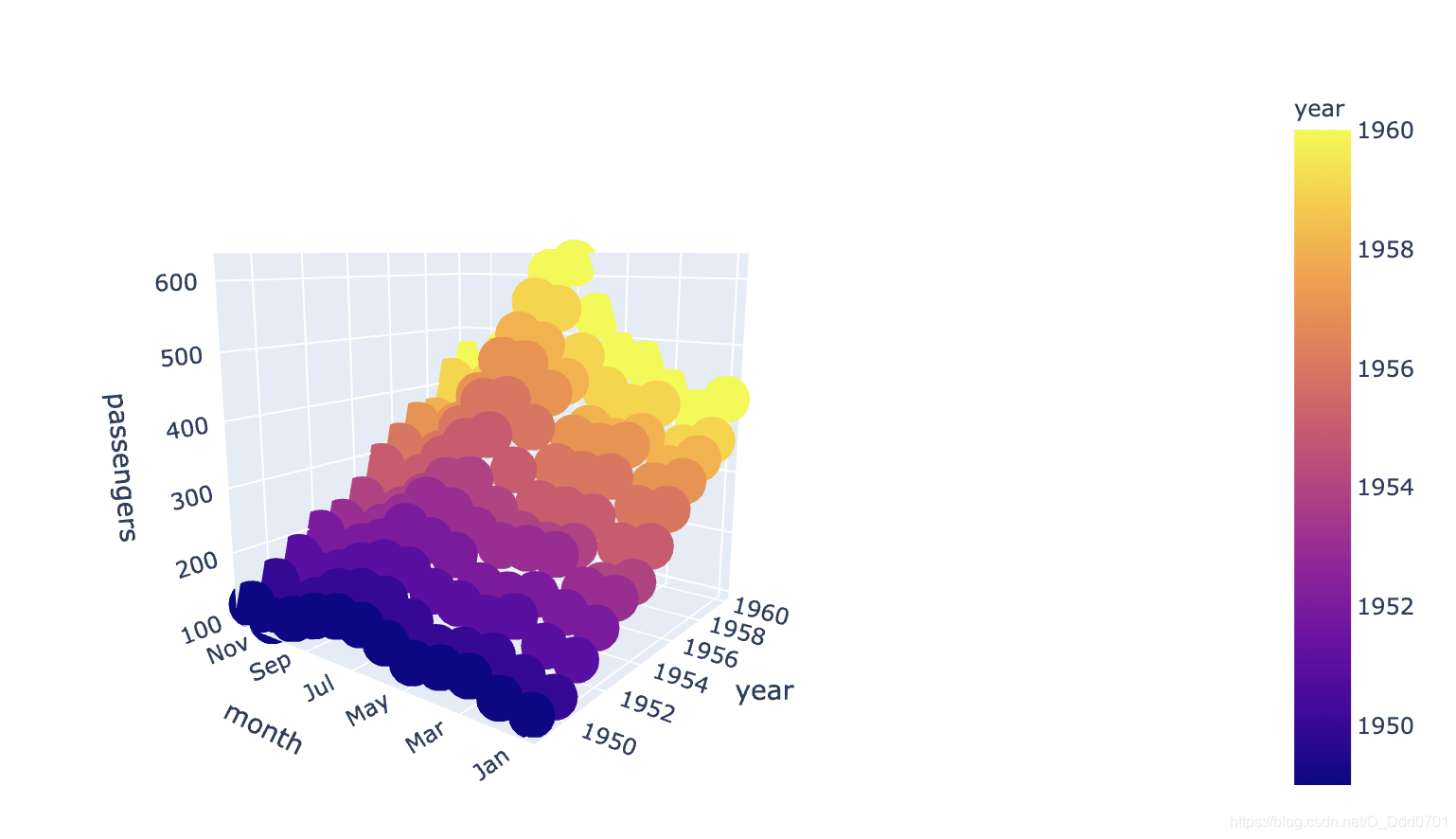
这个和折线图表现的结果类似。
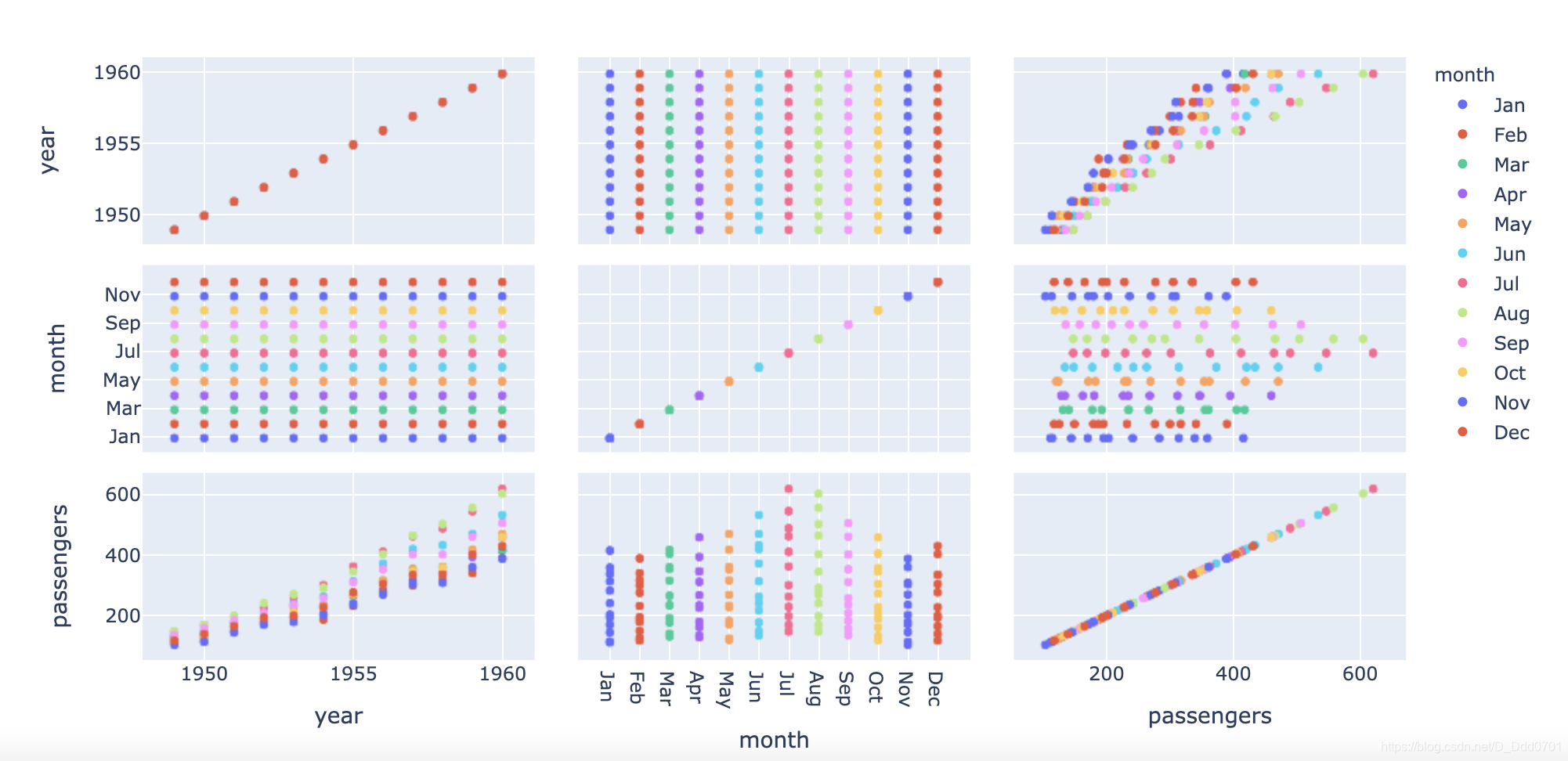
利用scatter_matrix绘制散点矩阵
但是有些时候,我们希望用2D的图把3D图的信息展示出来,刚才案例的数据3D图涉及到x,y,z三组变量,如果用2D展示,则需要把xy,xz,yz的关系用三张图绘制出来。这里需要使用到scatter_matrix功能。
fig = px.scatter_matrix(flights,color="month")
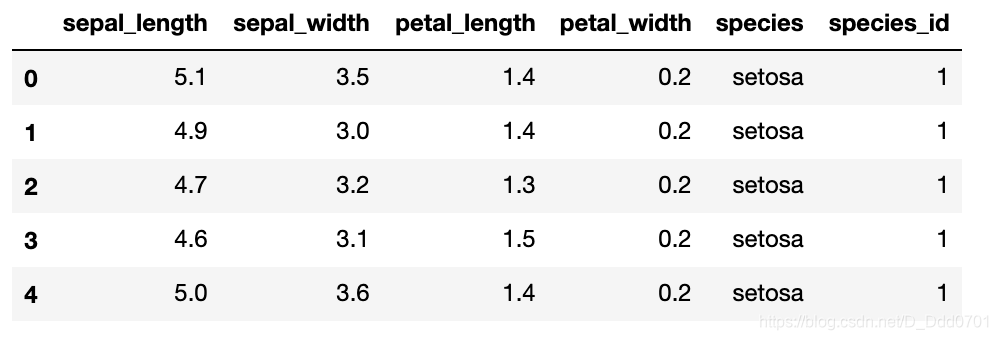
接下来我们用机器学习的经典数据Iris花卉数据集再做一次可视化分析。
Iris数据包括了三种鸢尾花的4个不同维度的属性值。我们希望通过数据集把三种种类的花分开。
df = px.data.iris()
df.head()
用刚才的散点矩阵来分析一下:
fig = px.scatter_matrix(df,color="species")
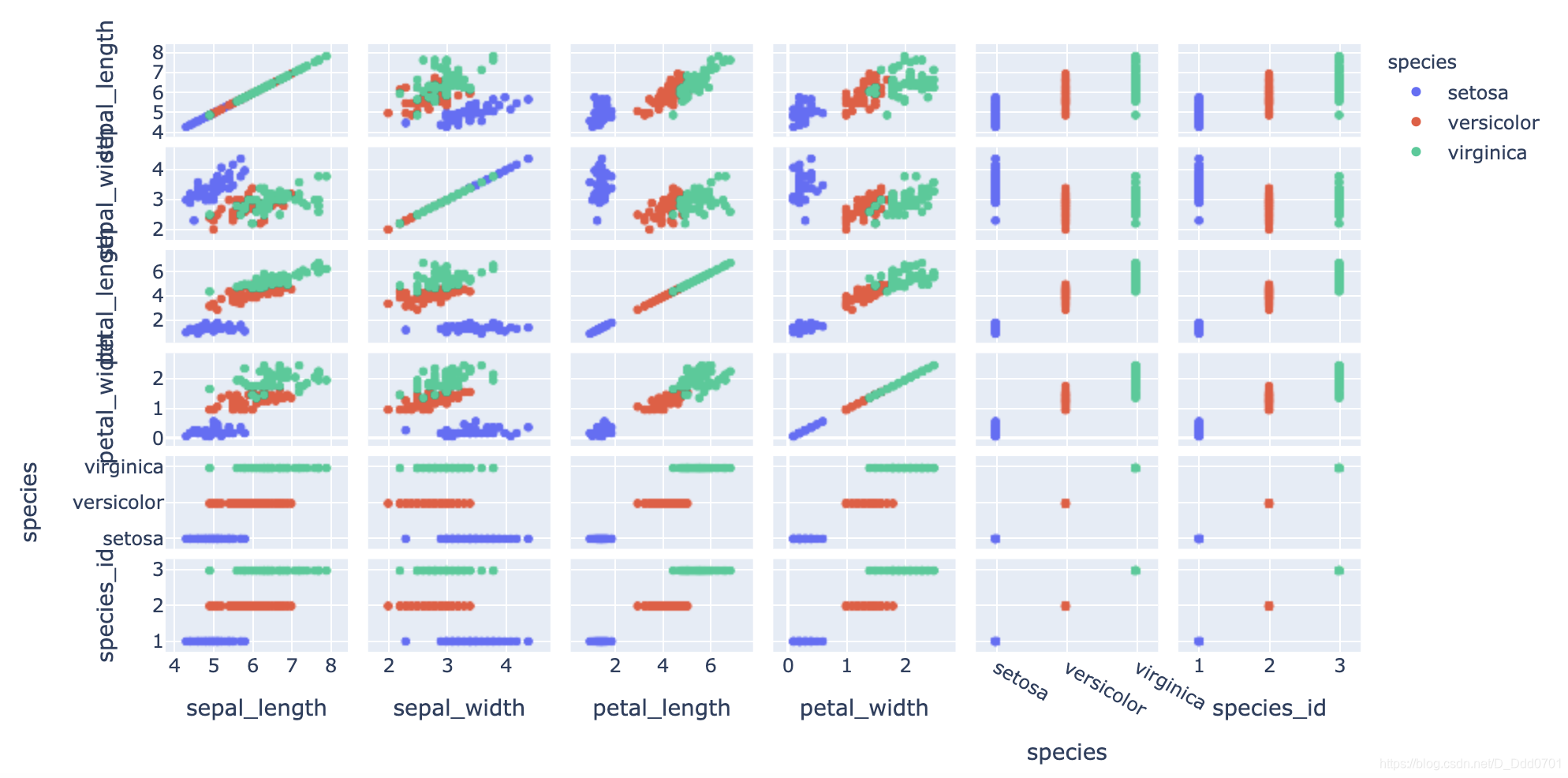
可以看到,使用petal_length和petal_width绘制分的是比较开的。
所以用这两个元素单独绘制一下散点图:
fig = px.scatter(df , x ='petal_length' , y='petal_width' , color='species' )
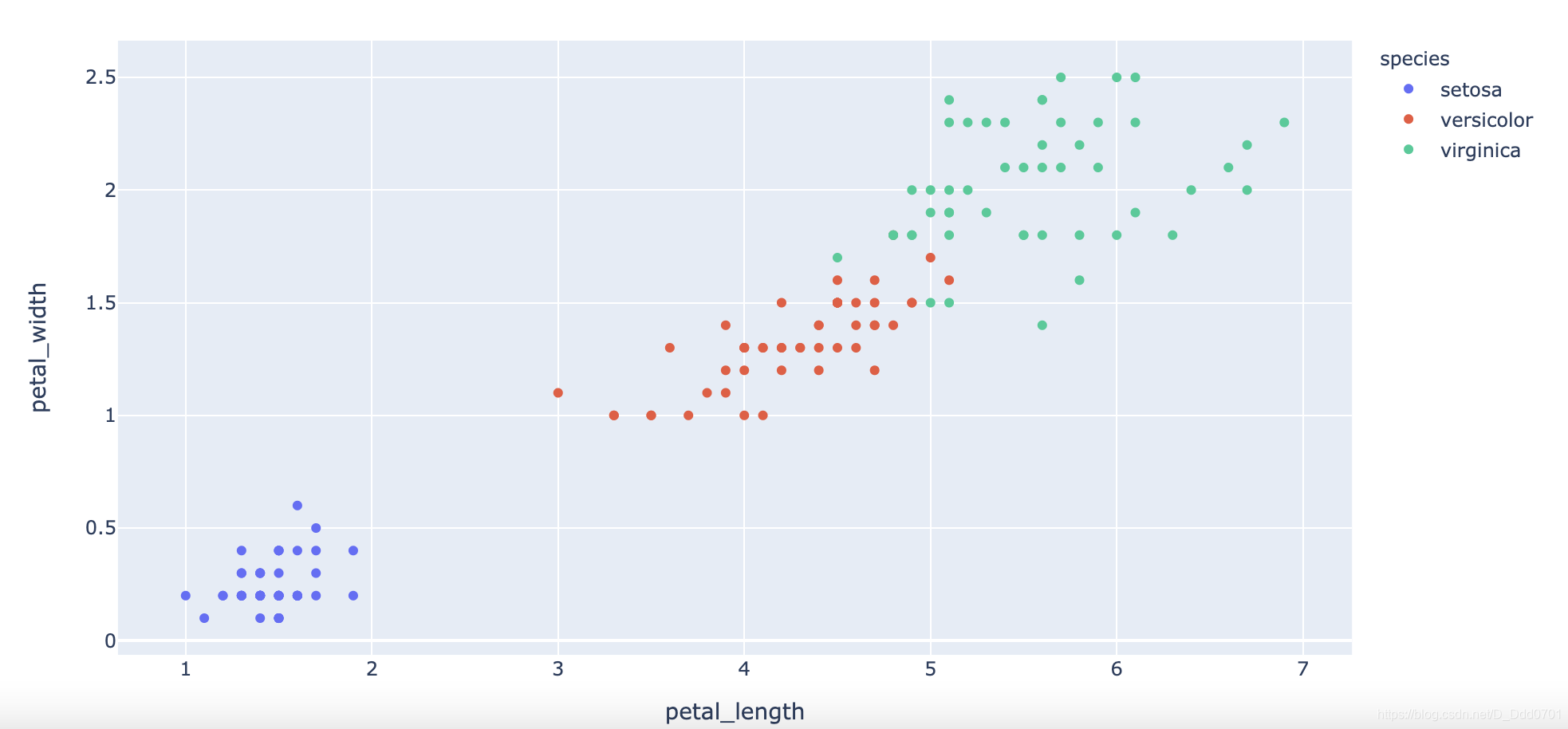
发现,这张图给的信息还不够多,所以我们再增加一个区分:size='petal_length'
fig = px.scatter(df , x ='petal_length' , y='petal_width' , color='species', size='petal_length')
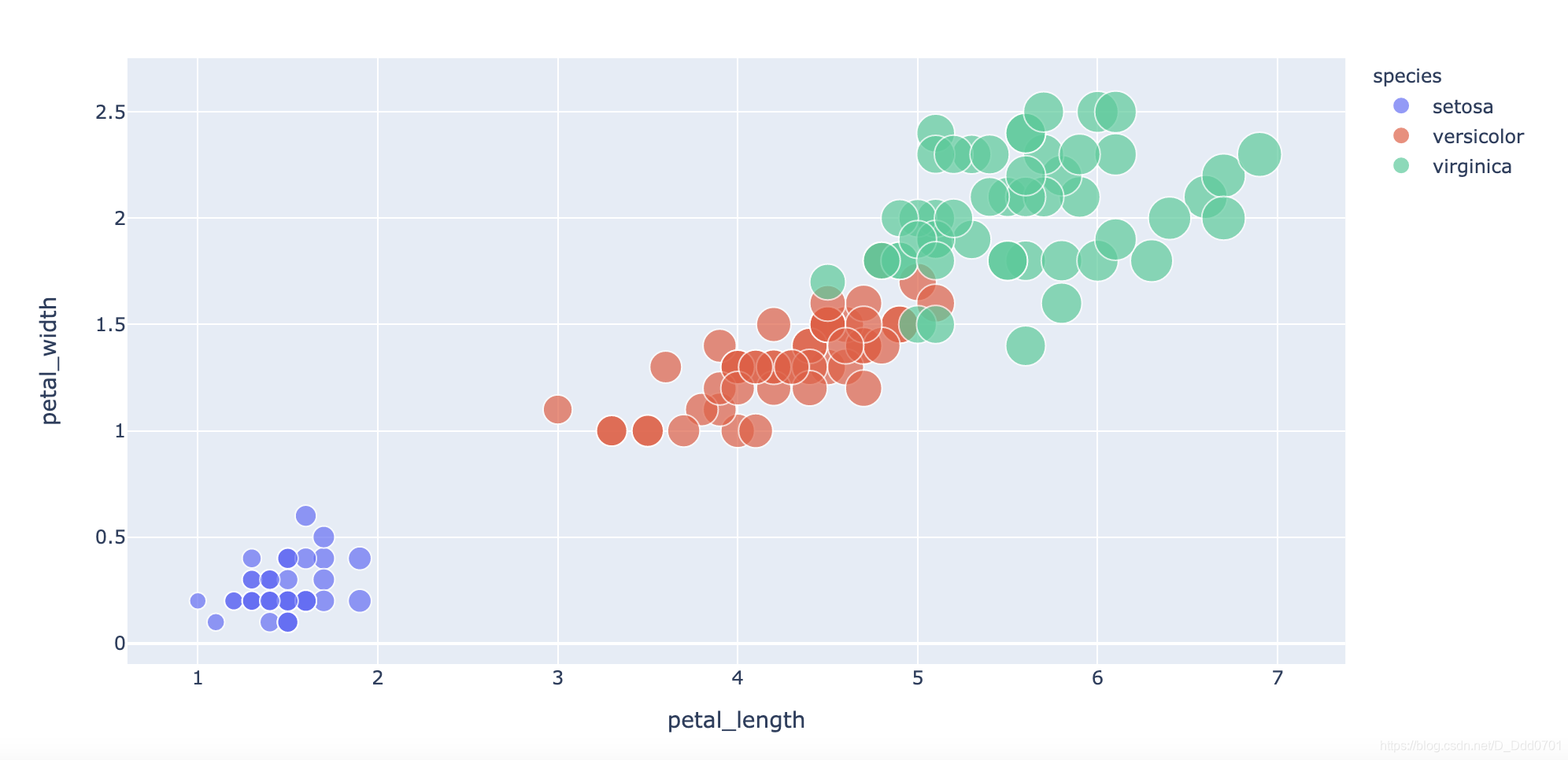
会发现setosa比较小,virginica比较大,这张图可以把蓝色分出来,红色和绿色中间有重叠,分开比较复杂。所以可以试一试3D。
fig = px.scatter_3d(df , x ='petal_length' , y='petal_width' ,z='sepal_width' , color='species' ,size='petal_length')
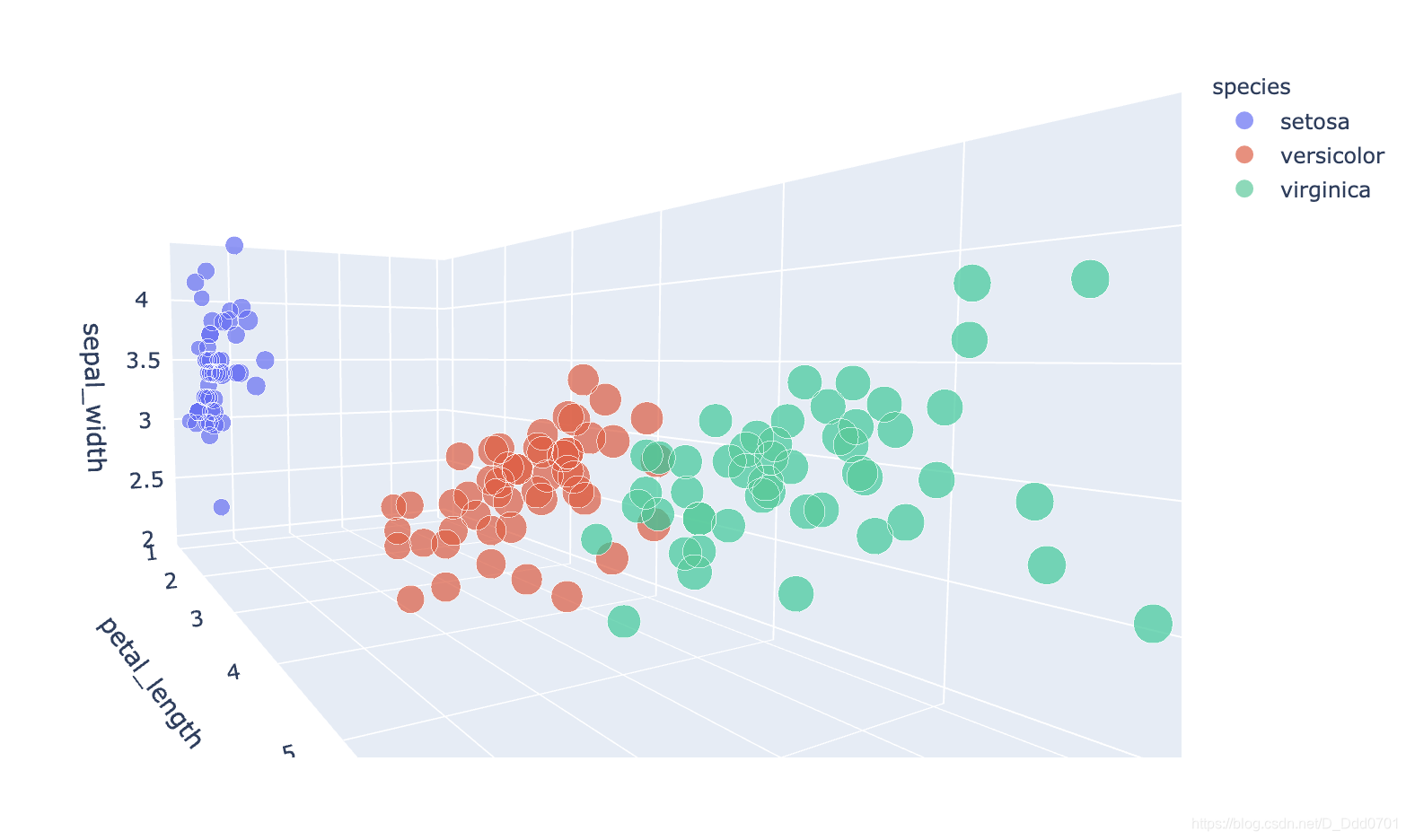
3D图发现在空间上会存在某个切面可以把三者分开。
利用scatter_geo绘制地理散点图
利用px自带数据库
使用自带数据库2007年gdp数据:
df = px.data.gapminder().query("year == 2007")
df.head()
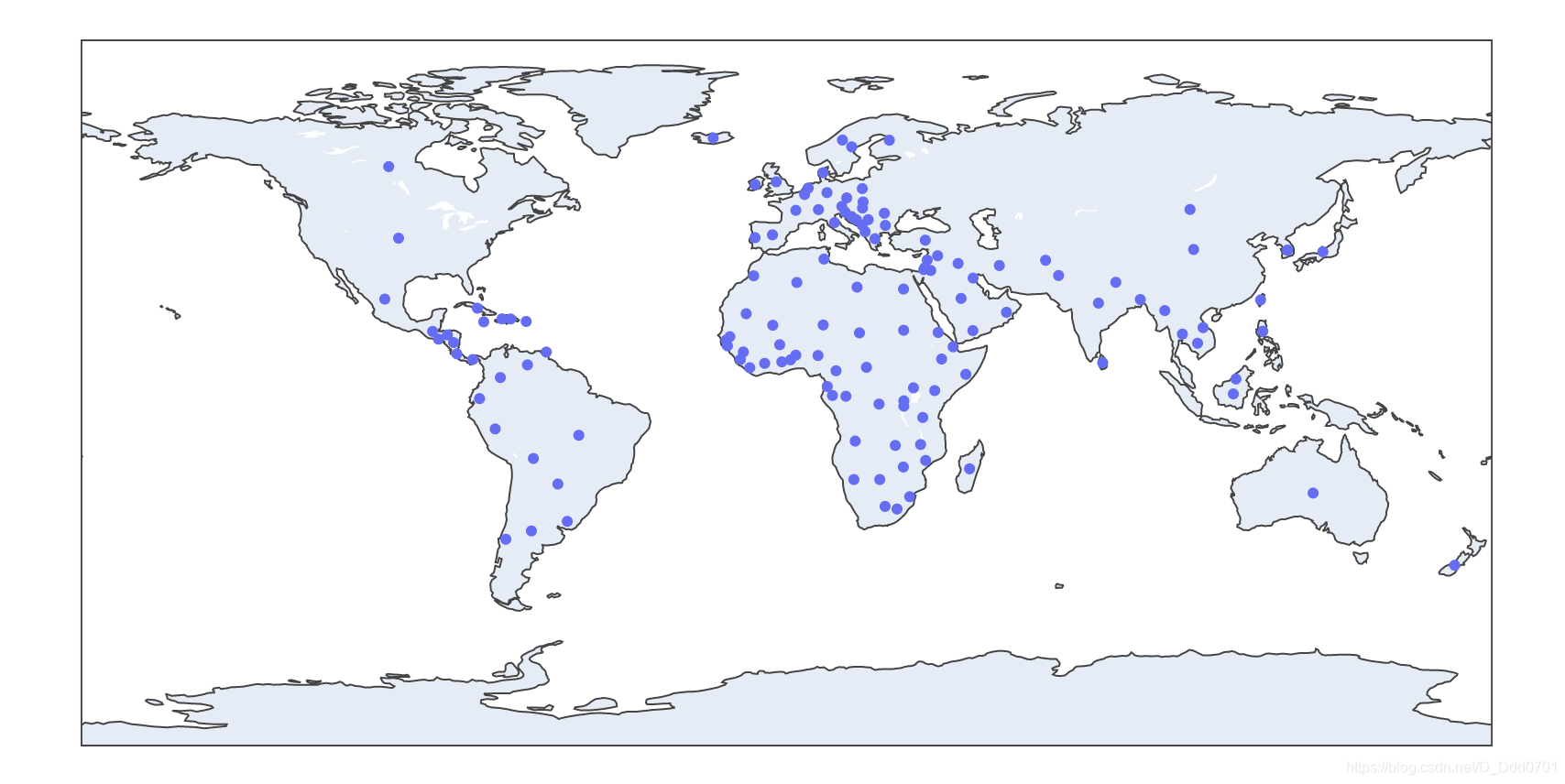
绘制地理信息图
fig = px.scatter_geo(df,locations="iso_alpha")
# locations='iso_alpha'表示自动适配地理信息
为了让显示更加具有辨识度,增加其他参数:
# color="continent"表示按洲不同颜色不同
# hover_name="lifeExp"表示显示数据集中lifeExp数值
# size='pop'表示用数据集中pop数据区别大小
# projection='orthographic'表示用地球投影模式
fig = px.scatter_geo(df,locations="iso_alpha",color="continent",hover_name="lifeExp",size='pop',projection='orthographic')
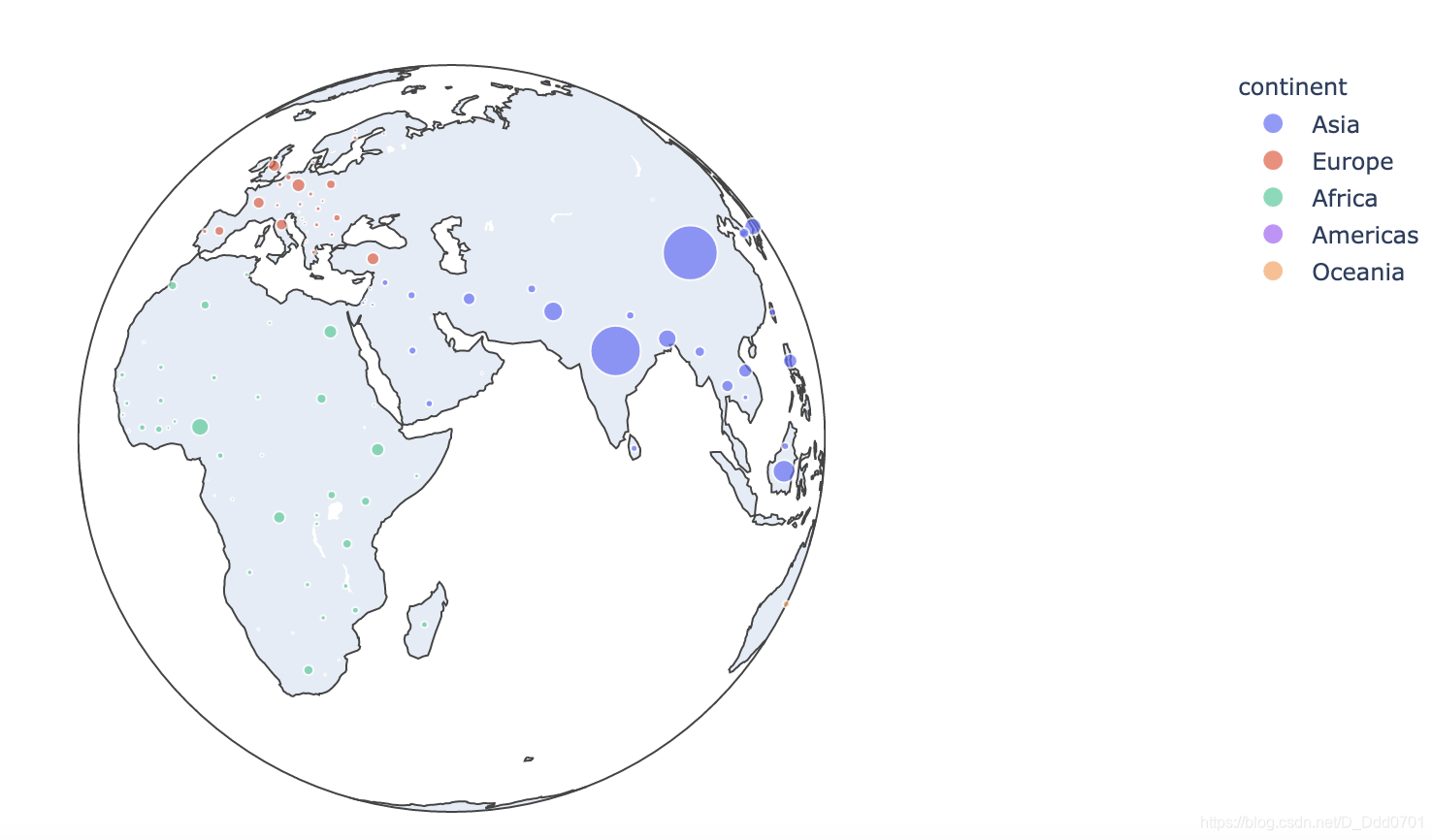
可以用的投影模式有:
One of the following enumeration values:
[‘equirectangular’, ‘mercator’, ‘orthographic’, ‘natural
earth’, ‘kavrayskiy7’, ‘miller’, ‘robinson’, ‘eckert4’,
‘azimuthal equal area’, ‘azimuthal equidistant’, ‘conic
equal area’, ‘conic conformal’, ‘conic equidistant’,
‘gnomonic’, ‘stereographic’, ‘mollweide’, ‘hammer’,
‘transverse mercator’, ‘albers usa’, ‘winkel tripel’,
‘aitoff’, ‘sinusoidal’]
利用choropleth功能绘制地图信息
import pandas as pd
import numpy as np
import plotly
import plotly.graph_objects as go
import chart_studio.plotly as py
import plotly.express as px
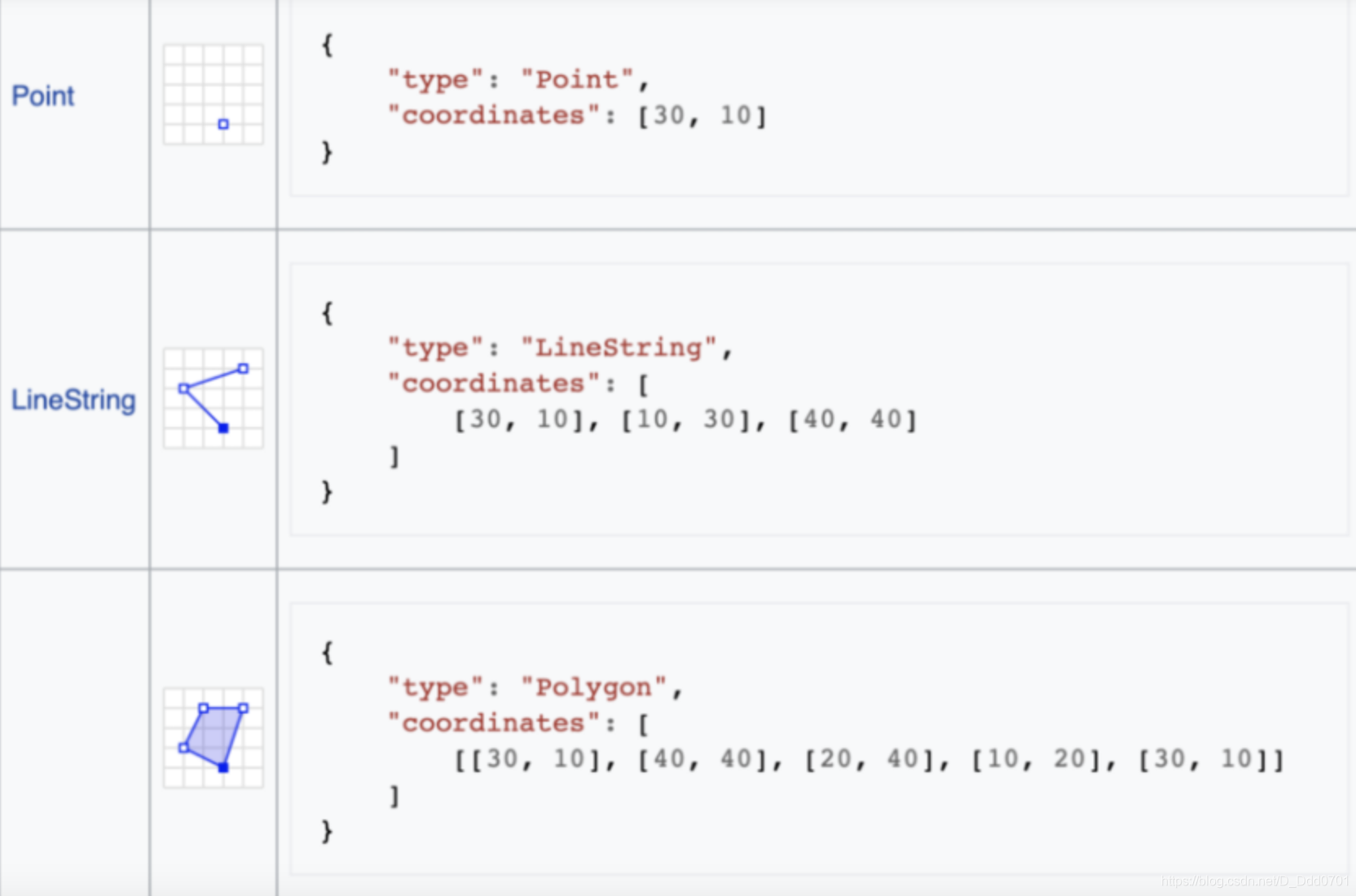
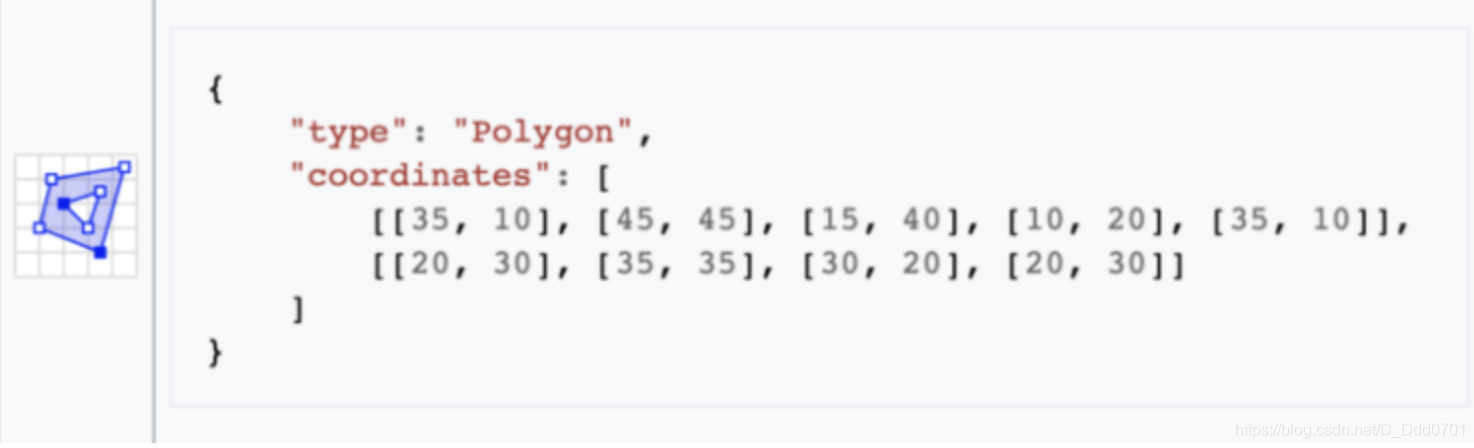
在绘制地图时,需要数据信息,但这个数据需要gps信息(经纬度坐标),如果没有则需要补充geojson信息。
例如,csv文件内的成都并不代表地图上的成都,csv文件的成都只是一个字符串,要让程序识别出这是地图上的成都应该包括成都的范围(经纬度的跨度等)。
这里例举一个具体的例子:

为了确定这个多边形的范围,我们用5个点去圈定他,这样就在一个空间内形成了多边形的地理信息。所有的区域信息可以总结为以下几点:
利用geojson功能绘制地理区域
从geojson官网“圈地”
为了获取geojson数据,需要在geojson的官网去“圈地”。geojson网址
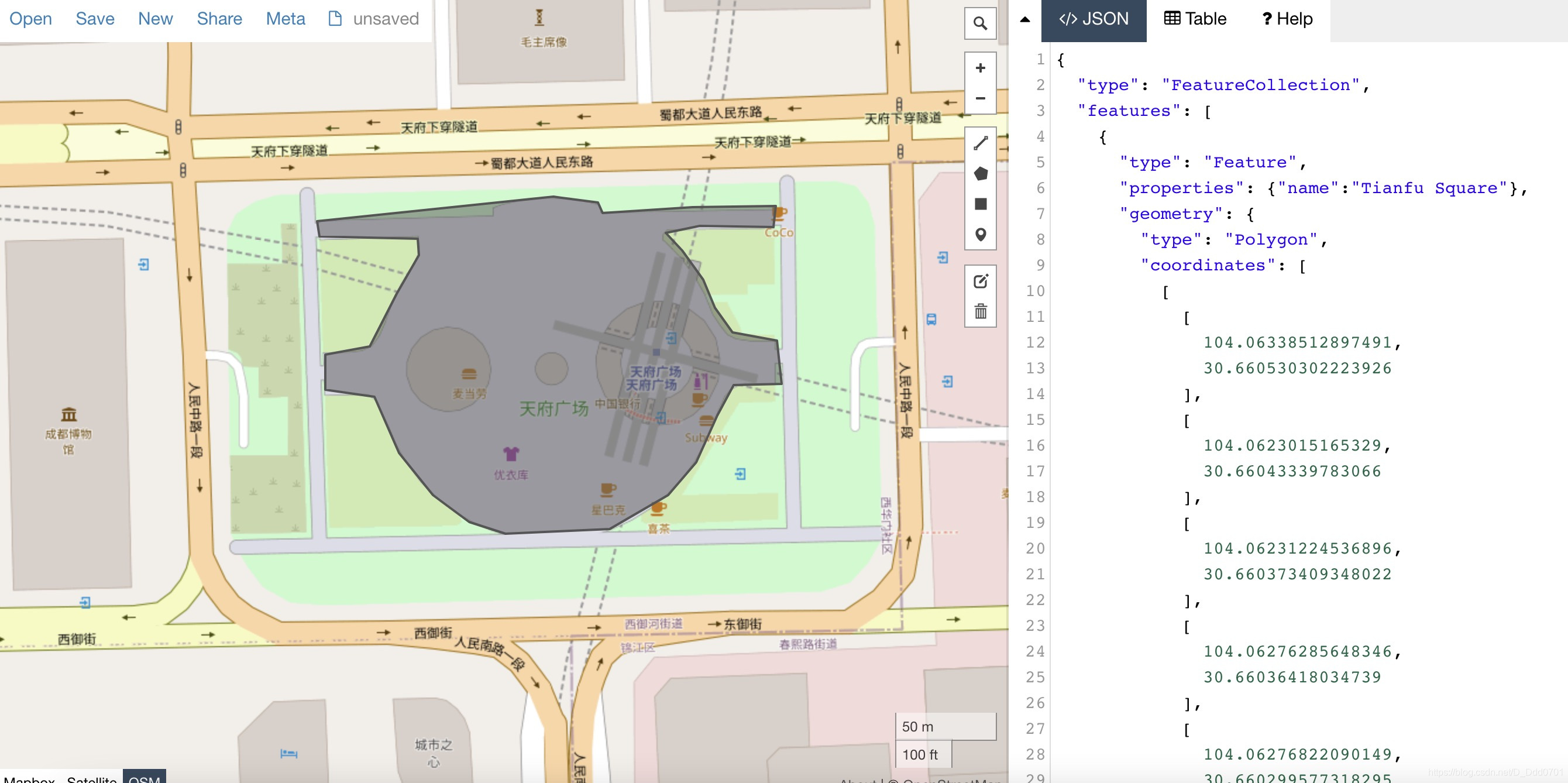
找到自己想要的地方(以成都市中心天府广场举例),框定区域会在右侧形成geojson格式的数据,点击Sava储存为geojson格式就行。

利用folium库在jupyter notebook上“圈地”
首先需要安装folium这个第三方库,安装方式同其他三方库一致。
from folium.plugins import Draw
import folium
m = folium.Map()
draw = Draw(export=True,filename="tianfu_square.geojson")
draw.add_to(m)

点击Export即可储存本地geojson格式文件。
利用choroplethmapbox绘制漂亮的地图
这里准备了一份数据:
geo = pd.read_csv("Geography.csv")
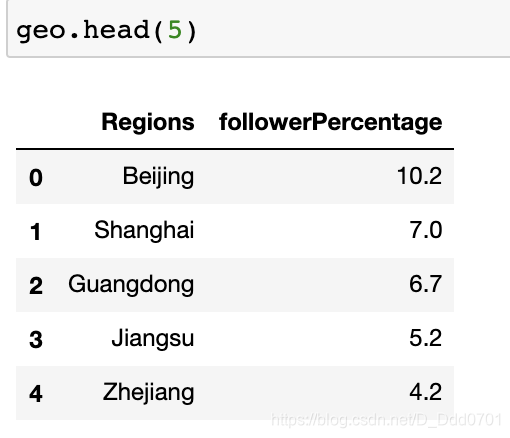
那么我们知道,要在地图上定位只有两种办法:1、给出指定的(x,y)坐标;2、geojson格式文件。显然对市给出坐标太过困难,所以这里选择第2种方式。
网上已经有人给出了一份全国市级地区的geojson文件,我们直接调用。
import json
with open('china_geojson.json') as file:
china = json.load(file)
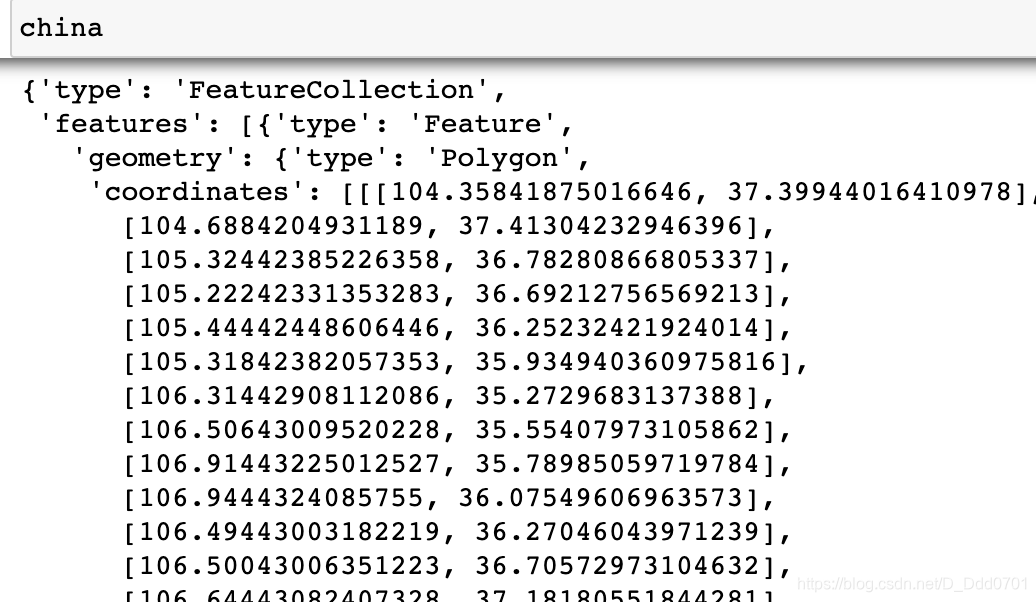
绘制图片:
# geojson=geojson数据
# locations=地图对应的id信息
# z=数值
fig = go.Figure(go.Choroplethmapbox(geojson=china,locations=geo.Regions,z=geo.followerPercentage
,colorscale='Cividis'))
# 直接绘制是不能显示的,必须需要fig.update_layout()渲染s
fig.update_layout(mapbox_style="carto-positron",mapbox_zoom=3,mapbox_center = {
"lat" : 35.9 ,"lon" : 104.2})
fig.update_layout(margin={
"t":0,"b":0,"l":0,"r":0})
fig

这个图看上去没有问题,但是因为Geography.csv文件中给的地标都是英文,我们更希望可以用中文展示:
geo2 = pd.read_csv('Geography2.csv')
geo2.head(5)
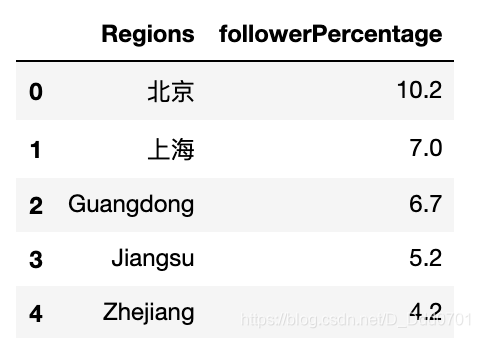
把之前的数据的北京和上海改成中文再运行一次:
fig = go.Figure(go.Choroplethmapbox(geojson=china,locations=geo2.Regions,z=geo2.followerPercentage
,colorscale='Cividis'))
fig.update_layout(mapbox_style="carto-positron",mapbox_zoom=3,mapbox_center = {
"lat" : 35.9 ,"lon" : 104.2})
fig.update_layout(margin={
"t":0,"b":0,"l":0,"r":0})
fig

发现,北京和上海都无法显示了。
这是因为我们的geojson文件id也是英文的,这里如果改成中文的北京上海就会和geojson的不匹配,所以无法显示。
如果修改id成中文就可以正确显示了。
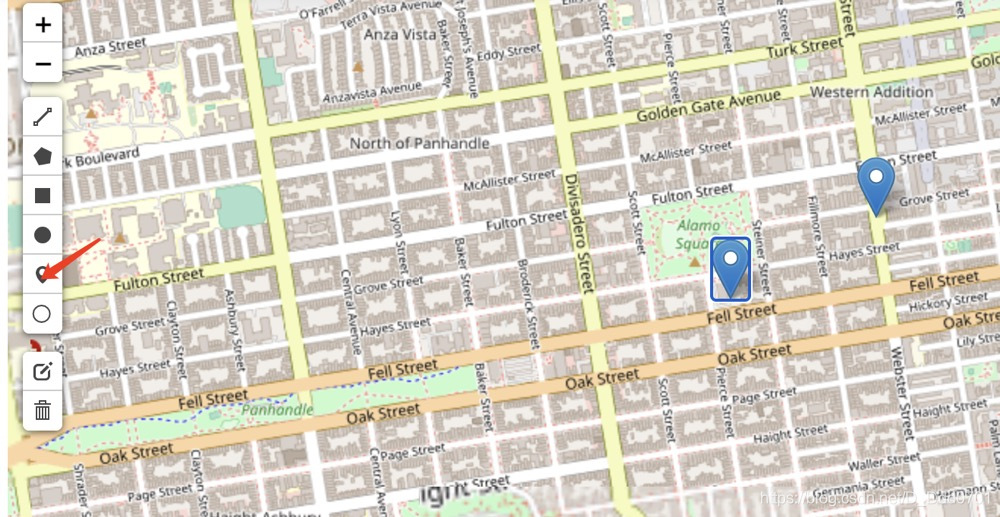
Folium绘制(x,y)定位图
我们想绘制出类似坐标定位的图:
首先导入一个数据集:
df = pd.read_csv('geo_pandas.txt')
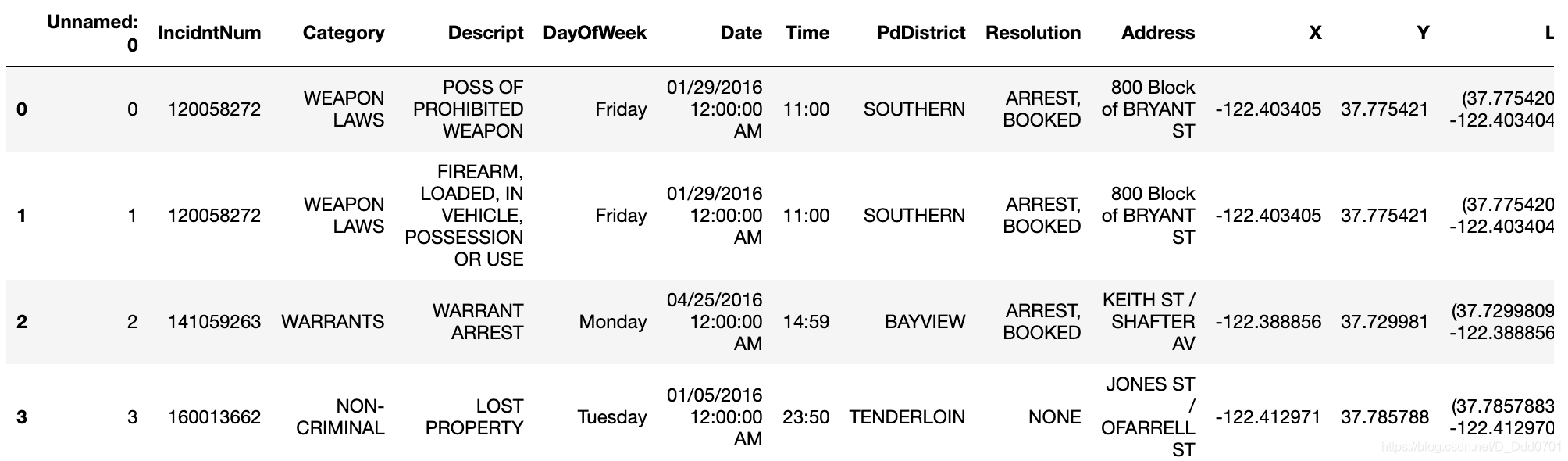
我们取数据集前100行。
limit=100
df = df.iloc[:limit,:]
我们可以用folium实现定位:
lat = 37.77
long = -122.42
m2 = folium.Map(location=[lat,long],zoom_start=12)
如果想要绘制定位点的图:
# 引入特征
incidents = folium.map.FeatureGroup()
# 组合经纬度
for lat, long in zip(df.Y, df.X):
incidents.add_child(
folium.CircleMarker(# 画小点点
[lat,long],
radius=5
)
)
m2.add_child(incidents)

还可以进一步美化:
for lat, long in zip(df.Y, df.X):
incidents.add_child(
folium.CircleMarker(# 画小点点
[lat,long],
radius=5,
fill = True, # 开启外圈填充
fill_color = 'blue', # 外圈填充蓝色
color = 'yellow', #内圈颜色黄色
fill_opacity = 0.6 #透明度
)
)
m2.add_child(incidents)

我们还是希望可以像demo一样,有一个标签(箭头)。
for lat, long in zip(df.Y, df.X):
incidents.add_child(
folium.CircleMarker(# 画小点点
[lat,long],
radius=5,
fill = True, # 开启外圈填充
fill_color = 'blue', # 外圈填充蓝色
color = 'yellow', #内圈颜色黄色
fill_opacity = 0.6 #透明度
)
)
lat1 = list(df.Y)
long1 = list(df.X)
label1 = list(df.Category)
for lat1, long1, label1 in zip(lat1, long1, label1):
folium.Marker([lat1, long1],popup=label1).add_to(m2)
m2.add_child(incidents)

这里我们只显示了前面100行数据,如果全部显示一共有15万个数据,会密密麻麻非常难受,所以这里如果想要全部显示应该怎么办呢?我们可以采用一种聚类的方式。
from folium.plugins import MarkerCluster
# 新建地图
m3 = folium.Map(location=[lat,long],zoom_start=12)
marker_cluster = MarkerCluster().add_to(m3)
lat1 = list(df.Y)
long1 = list(df.X)
label1 = list(df.Category)
for lat1, long1, label1 in zip(lat1, long1, label1):
folium.Marker([lat1, long1],popup=label1).add_to(marker_cluster)
# 这里不add_to(m3),而是add_to(聚类分组处理器)

随着滚轮放大缩小可以展示出具体和聚类的信息。
动态数据图的使用
使用普通散点图
首先导入各种类库
import pandas as pd
import numpy as np
import chart_studio.plotly as py
import cufflinks as cf
import seaborn as sns
import plotly.express as px
%matplotlib inline
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode(connected=True)
导入px自带数据集:
df_cnt = px.data.gapminder()
df_cnt.head()
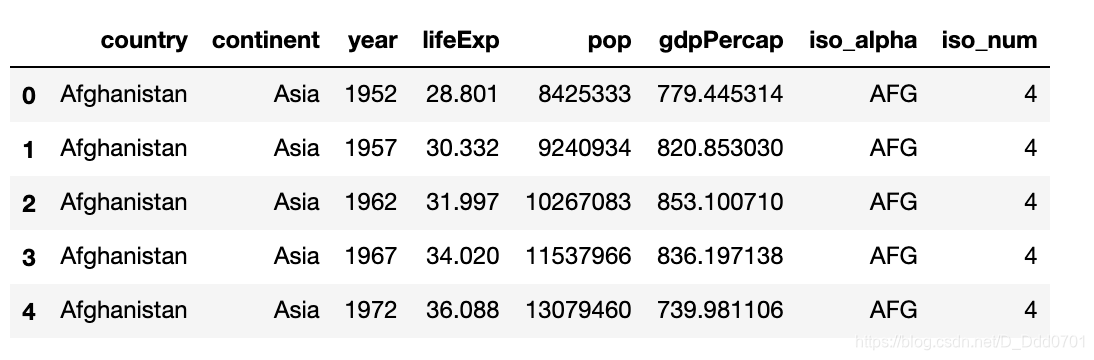
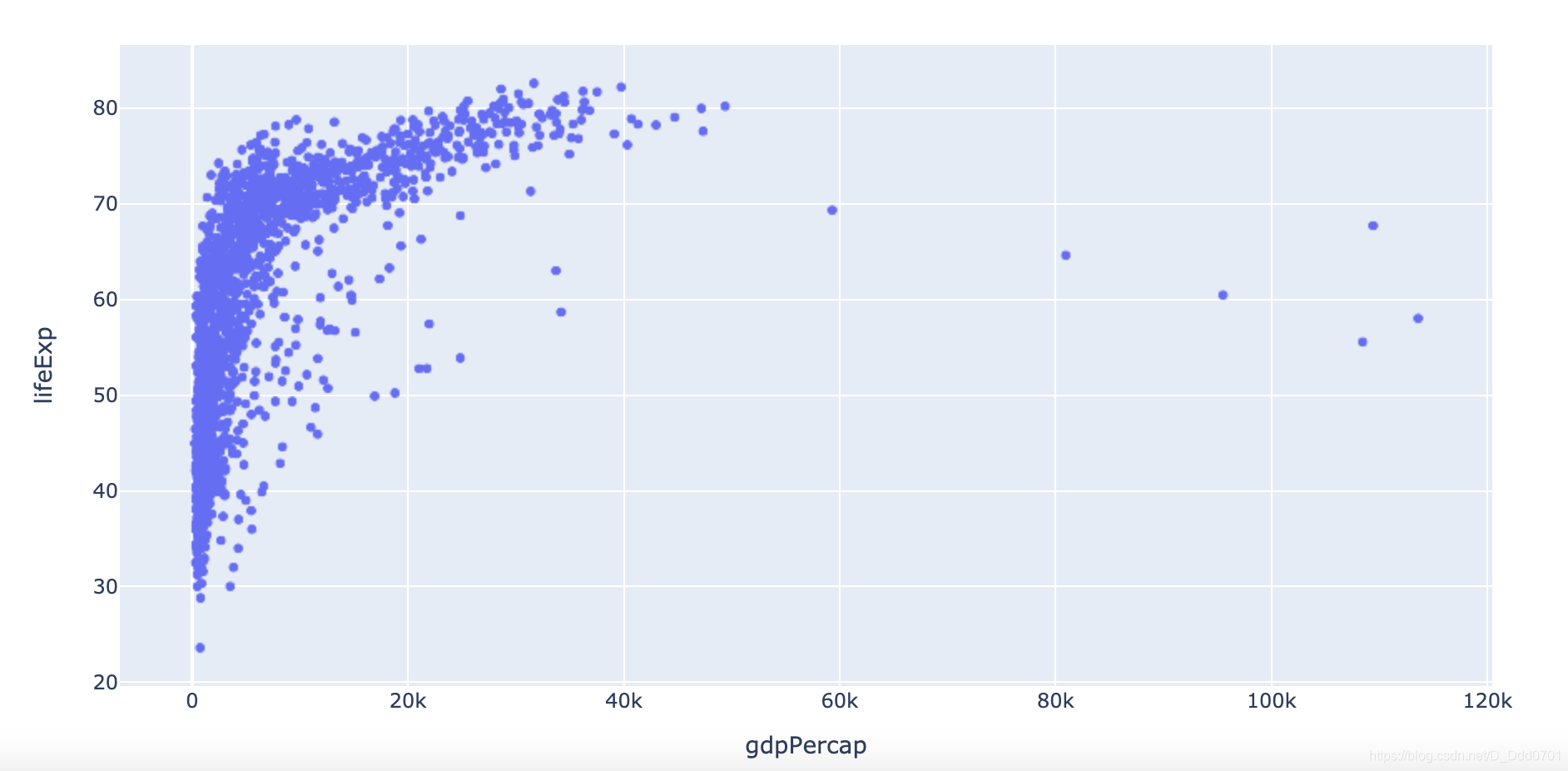
绘制散点图看一看gdpPercap和lifeExp的相关性:
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" )
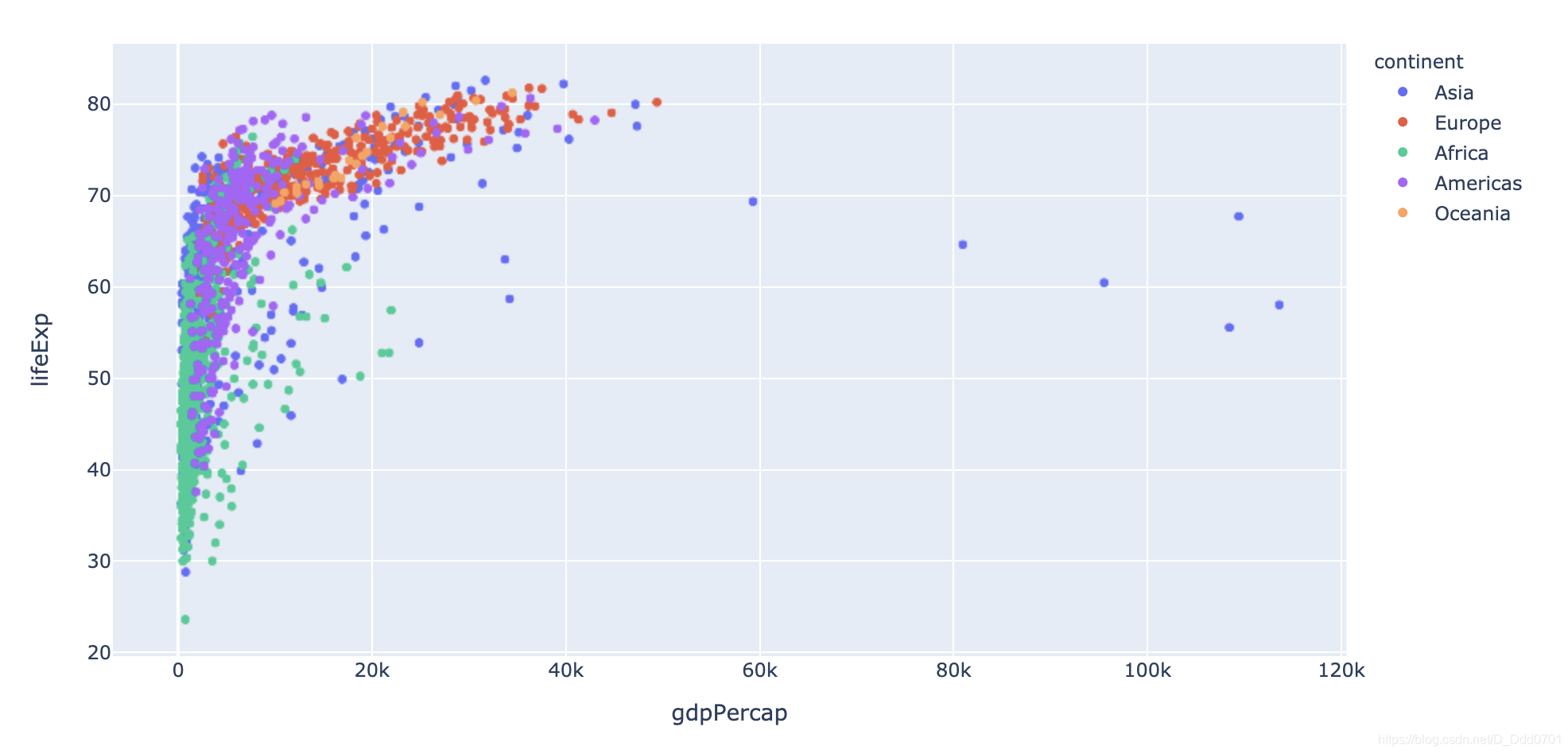
这里会发现数据叠在一起,不能分清楚各个国家之前情况如何,所以用颜色区分开:
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" ,color='continent')
这里会发现还是不容易区分,所以可以使用之前用过的一个办法——用科学计数法。
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" ,color='continent' ,log_x =True)
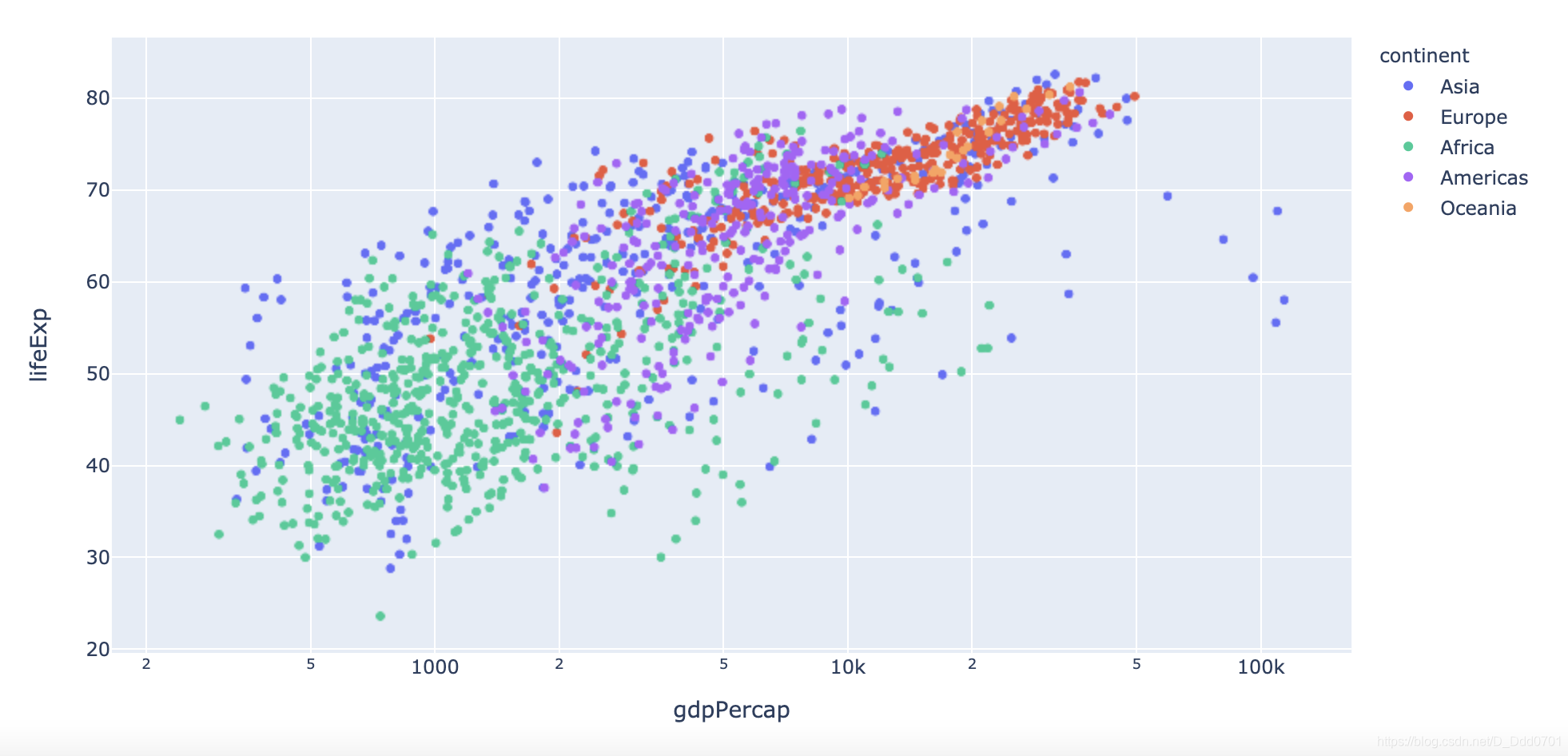
我们还想点到这个点上可以看到具体国家信息:
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" ,color='continent' ,log_x =True , hover_name="country")
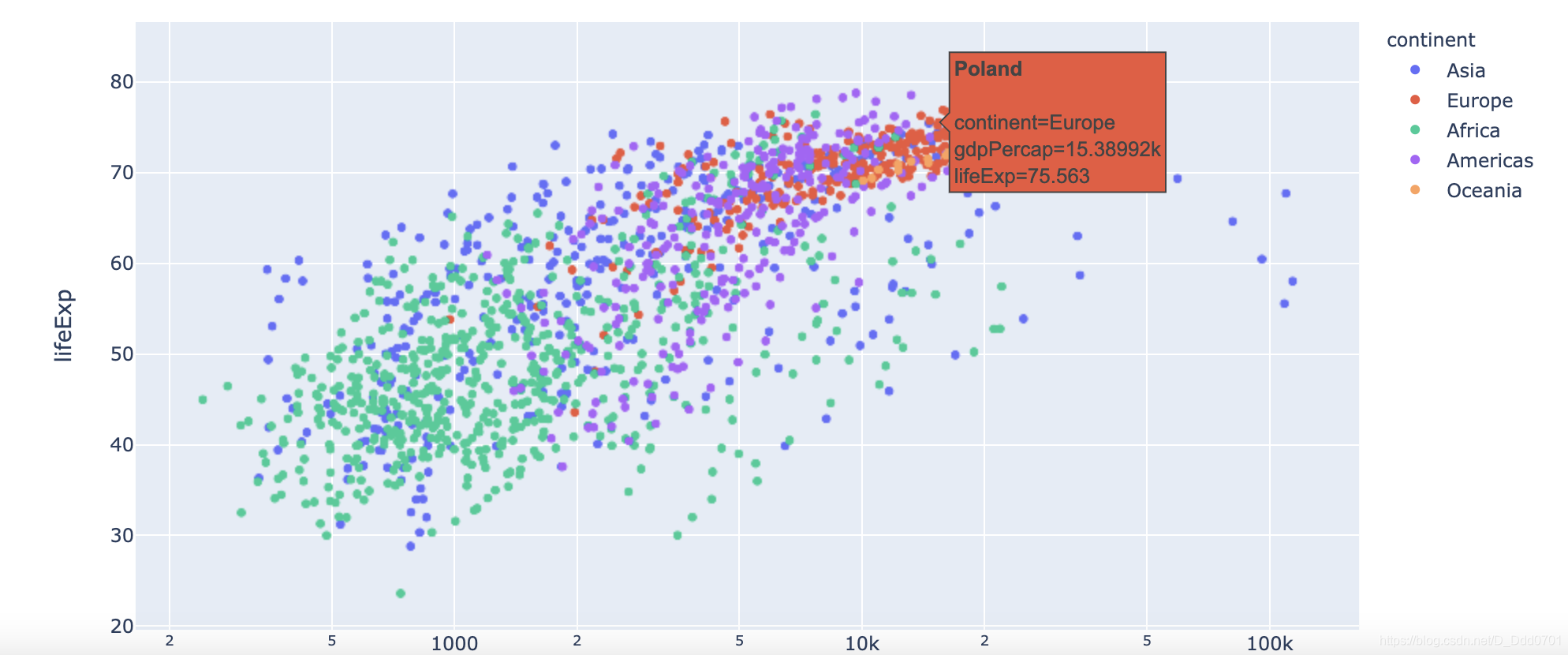
其实这张图依然比较杂乱,因为有几十年的数据,如果可以分开展示就会很好,这里就需要使用动态数据图。
使用动态散点图
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" ,color='continent' ,log_x =True , hover_name="country",
animation_frame="year")
#animation_frame="year"表示按年播放
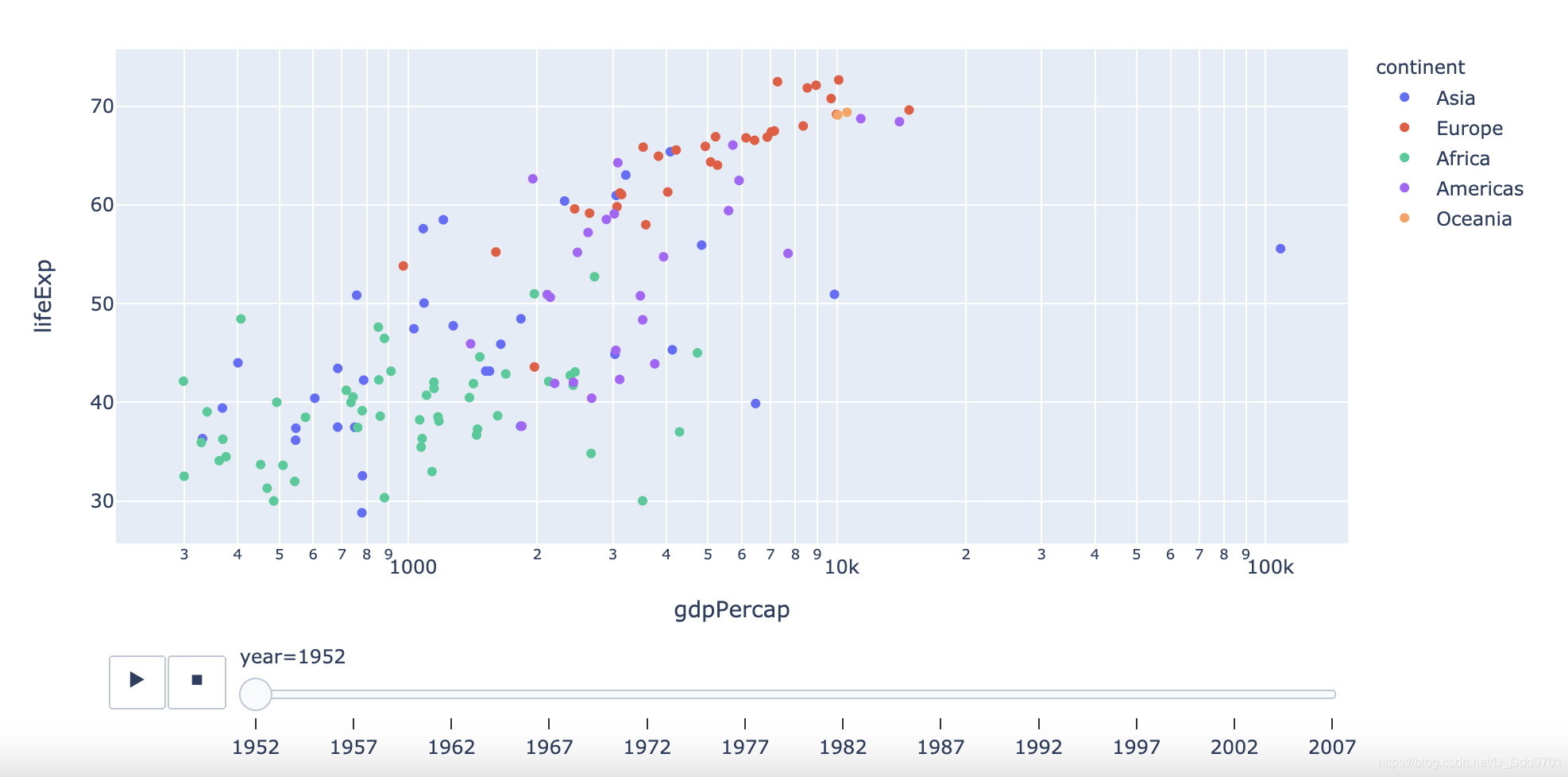
拖动下方滑块或者点击播放键可以播放每一年的数据情况。但是会发现随着时间增加,点会溢出表格,这是因为没有设置动态y轴。
一次性把动态x轴和动态y轴都加上:
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" ,color='continent' ,
log_x =True , hover_name="country",animation_frame="year",range_x=[100,100000],
range_y=[25,90])
这里还会存在一个问题,gdp实际的大小并不清晰,比如紫色和其他颜色到底gdp情况如何呢?所以可以调整size参数,用人口数量来区分。
px.scatter(df_cnt,x='gdpPercap' , y = "lifeExp" ,color='continent' ,
log_x =True , hover_name="country",animation_frame="year",range_x=[100,100000],
range_y=[25,90],size='pop',size_max=60)
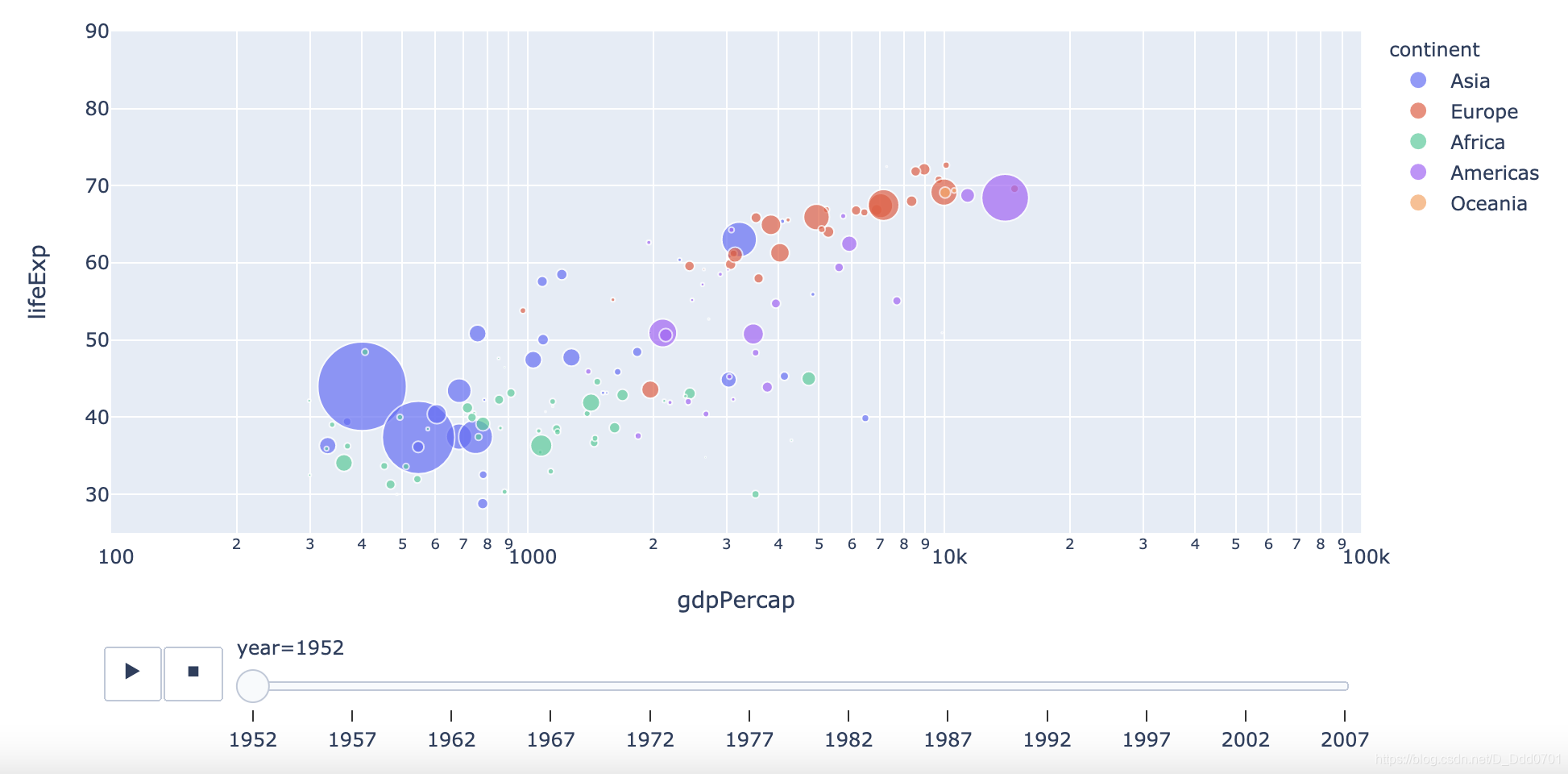
使用普通柱状图
px.bar(df_cnt,x='continent' , y='pop')
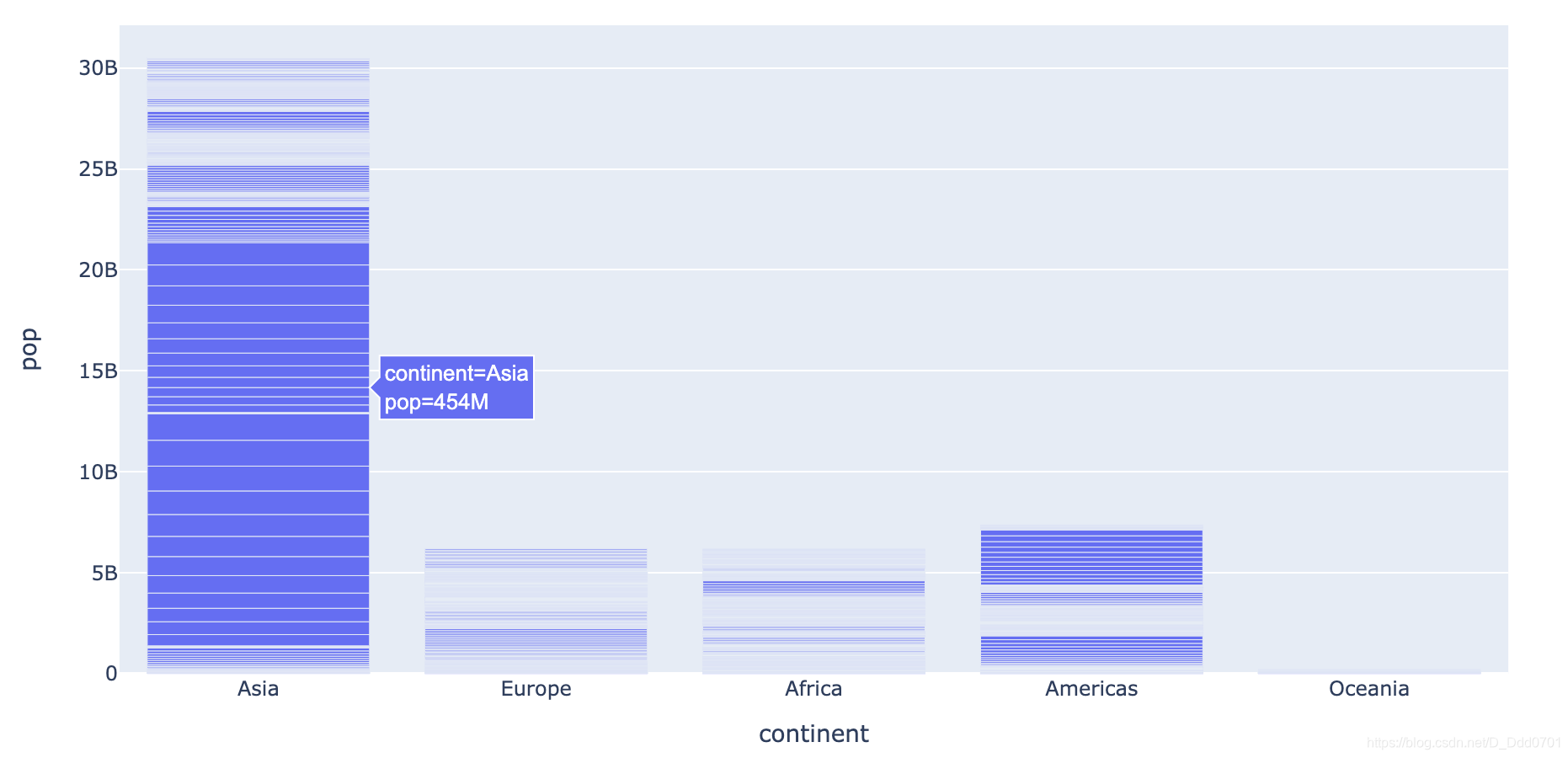
发现这里指上去不能看到这个柱子代表什么国家。所以增加hover_name="country"
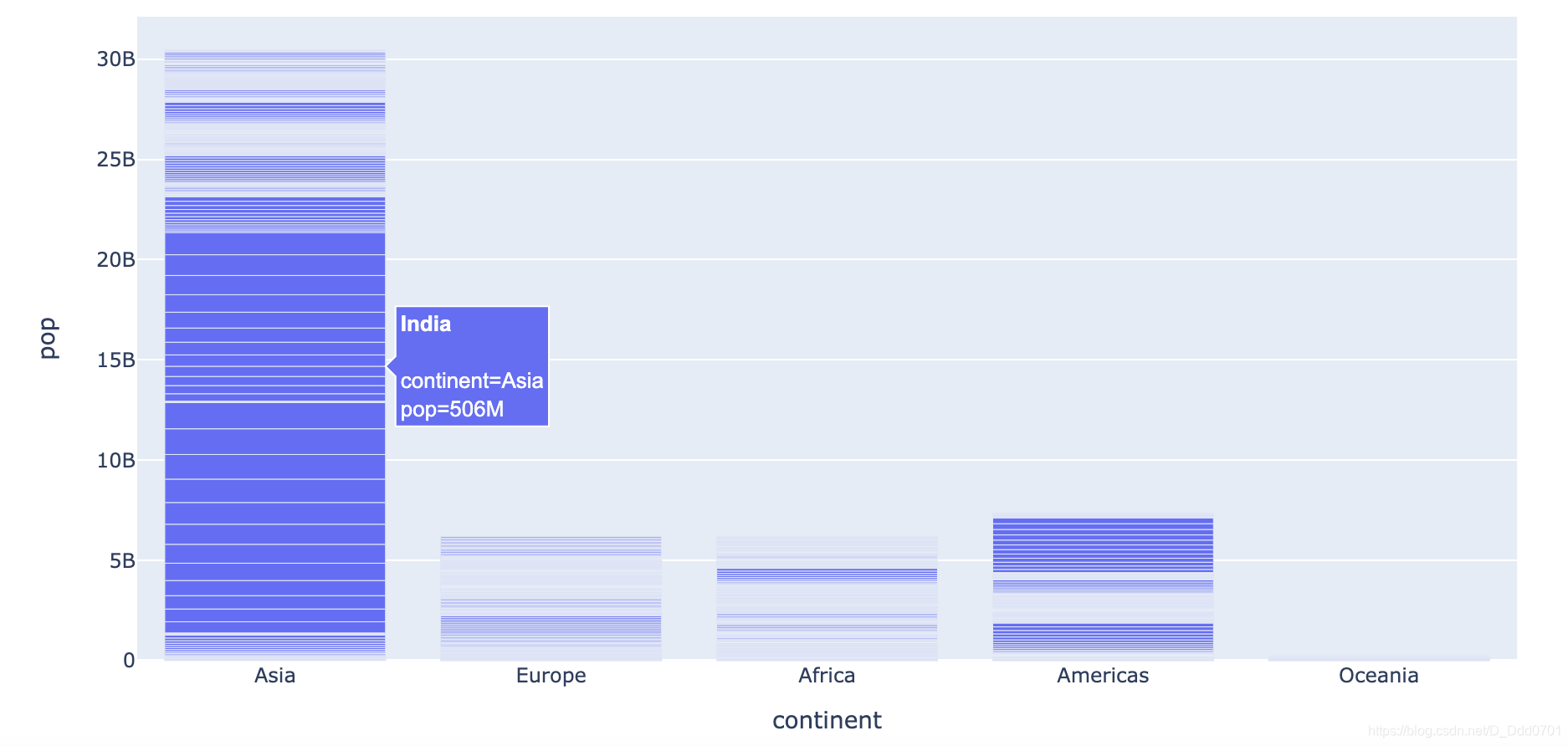
px.bar(df_cnt,x='continent' , y='pop',hover_name="country")
使用动态柱状图
px.bar(df_cnt,x='continent' , y='pop' , hover_name='country' ,color='continent' ,
animation_frame='year')
这里也会涉及到y轴显示问题,所以设计一下y轴范围:
px.bar(df_cnt,x='continent' , y='pop' , hover_name='country' ,color='continent' ,
animation_frame='year',range_y=[0,4000000000],animation_group='country')
# 这里的animation_group='country'类似MySQL中的groupby,表示按国家分组
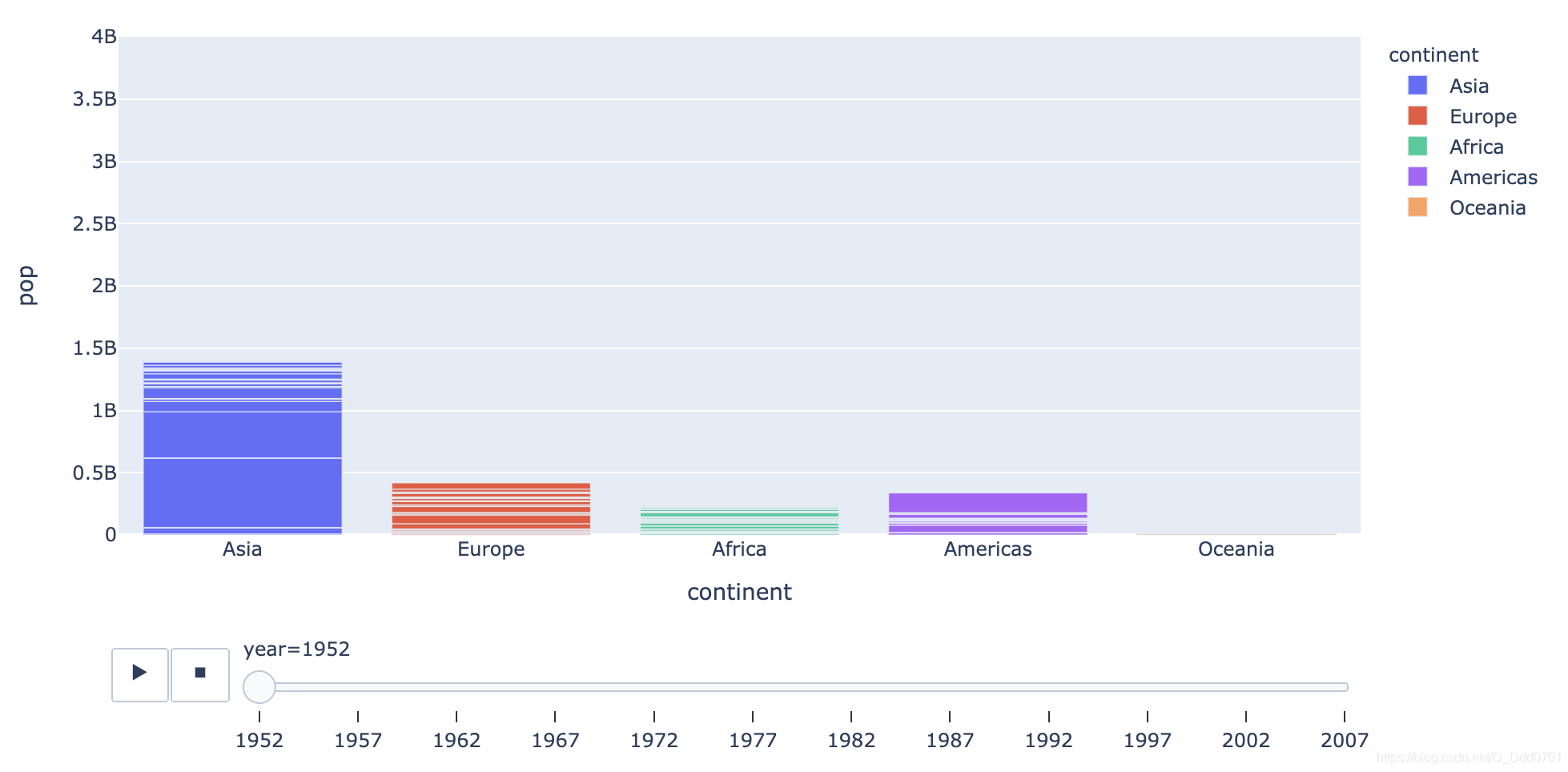
动态密度图
fig = px.density_contour(df_cnt, x="gdpPercap", y="lifeExp", color="continent", marginal_y="histogram",
animation_frame='year', animation_group='country', range_y=[25,100])
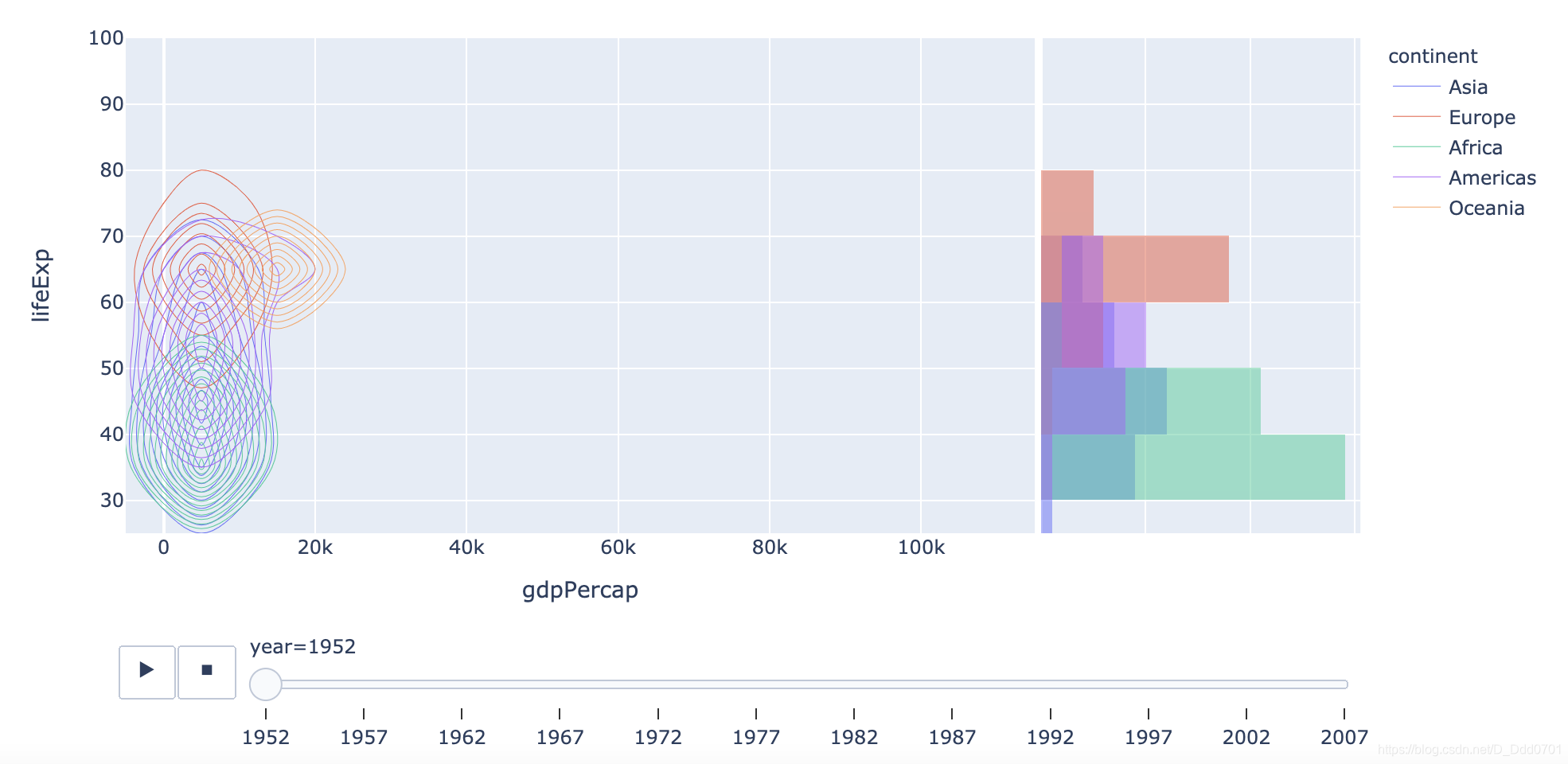
动态热力图
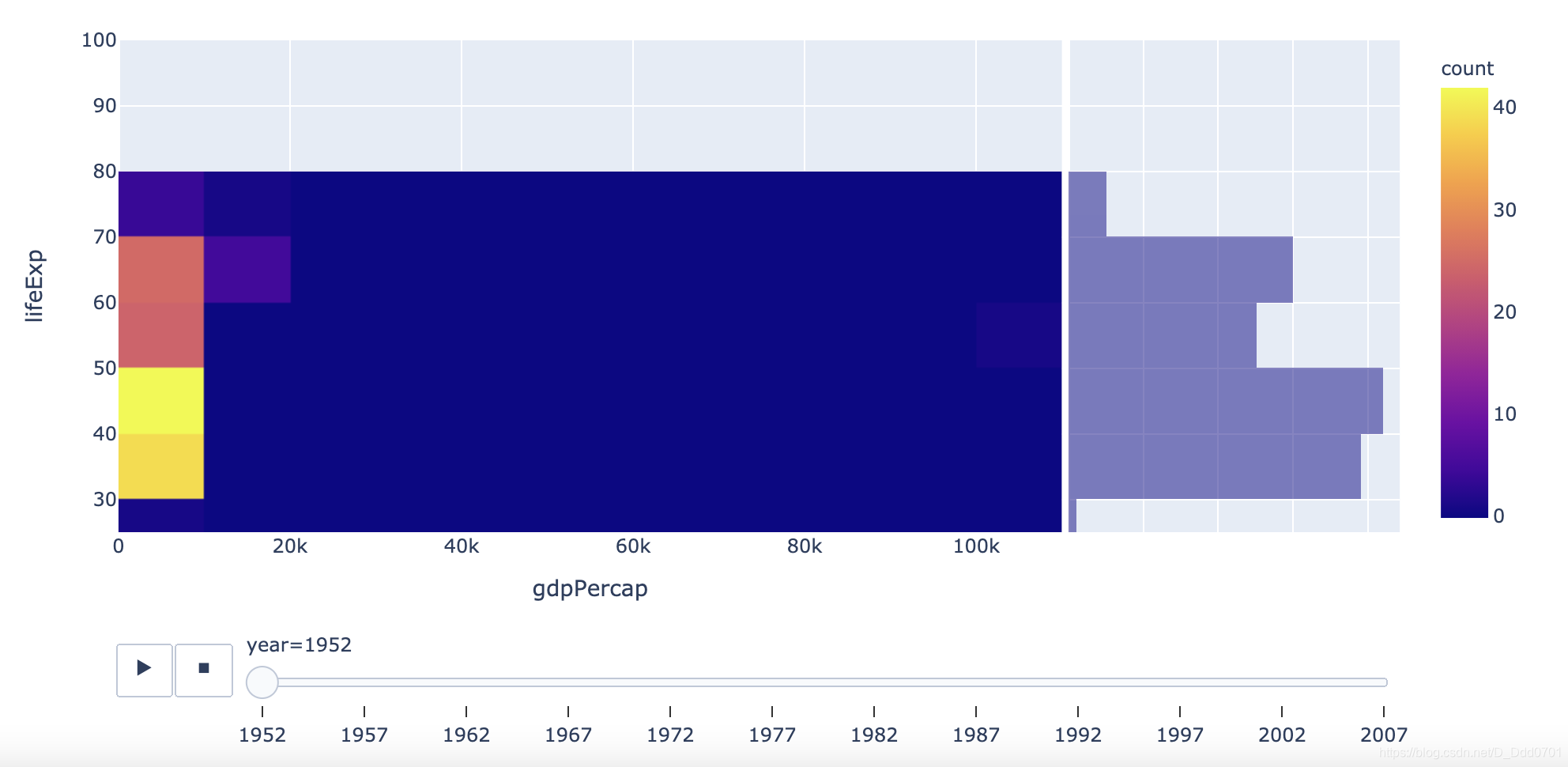
fig = px.density_heatmap(df_cnt, x="gdpPercap", y="lifeExp", marginal_y="histogram",
animation_frame='year', animation_group='country', range_y=[25,100])
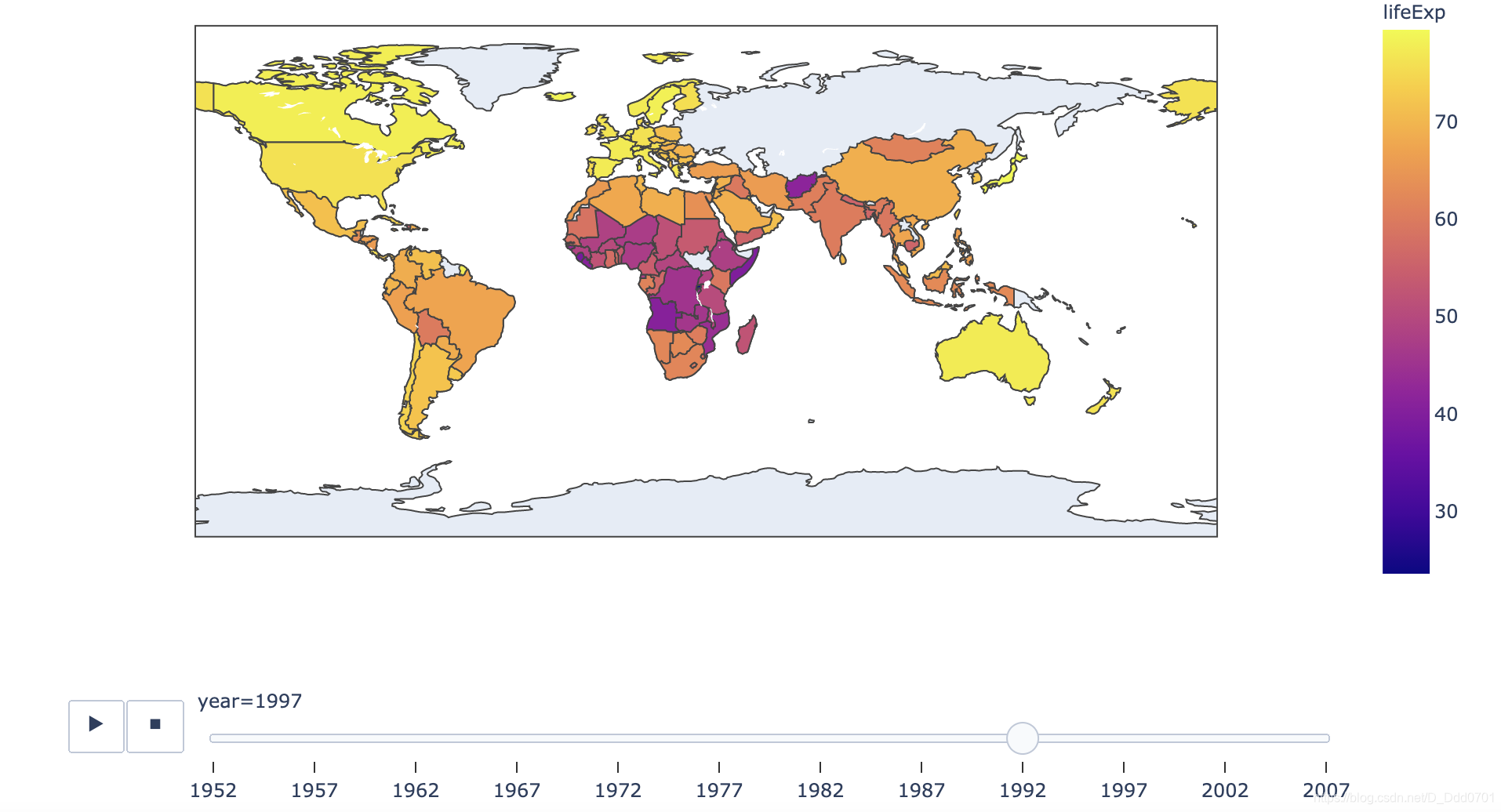
动态地理信息图
gapminder = px.data.gapminder()
px.choropleth(gapminder,
locations="iso_alpha",
color="lifeExp",
hover_name="country",
animation_frame="year",
color_continuous_scale='Plasma',
height=600
)
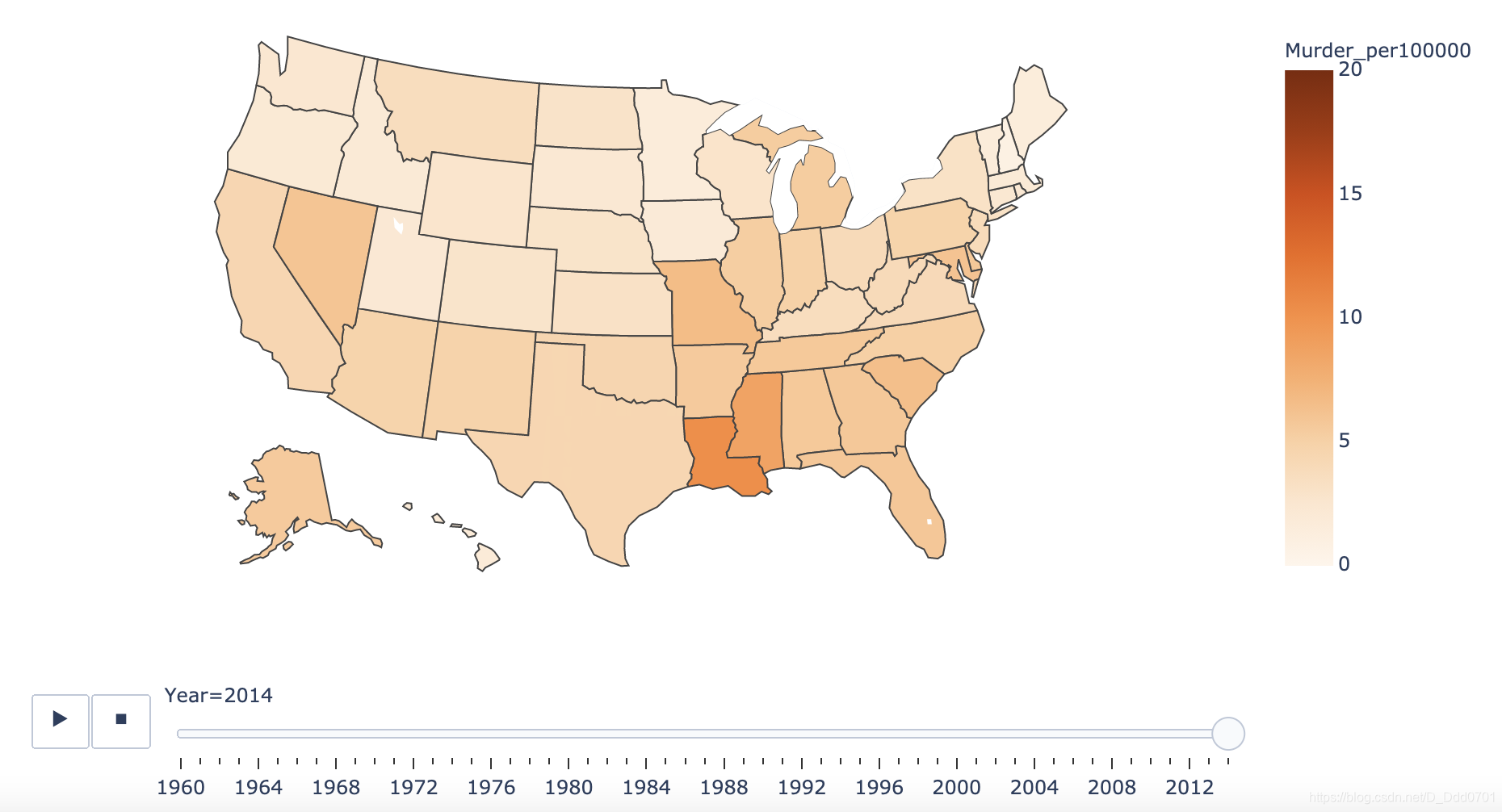
再用地图探究一下某地区犯罪率变化趋势:
df = pd.read_csv('CrimeStatebyState_1960-2014.csv')
df.head()

px.choropleth(df,
locations = 'State_code',
color="Murder_per100000", # 用每10万人犯罪数量区别
animation_frame="Year",
color_continuous_scale="oranges",
locationmode='USA-states', # 自带国家边界的geojson数据
scope="usa",
range_color=(0, 20),
title='Crime by State',
height=600
)