CNN的可视化与理解
在之前我们讨论了一系列内容
- 注意力机制:注意力如何成为我们可以添加到当前的神经网络中的机制,让模型在不同的时间步长上专注于输入的不同部分,然后构建通用自注意力层,用来构建新的神经网络模型
- Transformer:我们可以使用自注意力来构建这个新的神经网络模型,它完全依赖于对注意力的处理
但是我们在面对视觉任务的时候,我们如何判断神经网络学到了什么,假设我们训练了一个卷积神经网络模型,那么神经网络内部寻找的中间特征是什么,如果能够观察神经网络内部并了解不同的层在寻找什么特征
卷积层可视化
我们有这样的想法,即线性分类器正在学习一组模板,每个类都有一个模板,并且类分数是由我们的线性分类器计算的,是学习模板和输入图像的内积
当我们推广到卷积神经网络的时候,我们也有同样的想法
对于网络中第一层的卷积核,经过学习之后,当它继续围绕图像滑动之后,就可以获取一个内积(代表匹配度)
如果我们将这些卷积核可视化,那么就会发现,过滤器作为一个图像,可以对匹配的图像给出强烈响应,所以通过可视化卷积核的方法,我们可以对这些层所要寻找的特征有所了解
下面是四个不同模型,在ImageNet数据集上进行预训练之后,将第一层卷积核进行可视化

我们可以看到,尽管不同模型的架构不同,但是第一层卷积核想寻找的特征却是很接近
如果我们想将可视化方法应用在更高层上,会有一些问题,这是因为在第一层卷积层,卷积核通常会学习到一些基本的视觉特征,如边缘和颜色。例如,一个卷积核可能会在检测到垂直边缘时产生高的激活值。我们可以通过将这些卷积核的权值可视化为图像来查看这些特征。
但是在更深的卷积层,卷积核通常会学习到更复杂的特征。由于这些特征是在高维空间中学习的,因此可能难以直接可视化。然而,可以通过一些方法(例如,反卷积或特征反向投影)来尝试理解这些特征。
但是我们仍然可以在第二层上看到一些情况,那就是,他们仍然在寻找一种斑点图案或边缘,但现在不再寻找边缘或RGB特征空间中的斑点,而是寻找特征空间中由前一个卷积层产生的斑点或边缘

但是我们仍然无法对这些卷积核在寻找什么这件事上有一种强烈的直觉,卷积核可视化这个方法也无法让我们理解更高层的卷积核在做什么,所以我们需要使用其他方法来尝试理解卷积神经网络的其他层在干什么
我们先尝试跳过前面的卷积层,然后直接尝试理解最后一个全连接层在干什么
全连接层可视化
AlexNet的FC7层有4096个特征,使用线性变换之后可以提供ImageNet数据集中一千个类的类分数,所以我们可以尝试做的一件事是理解这个4096维向量表示什么
这个训练好的AlexNet在干什么呢?它获取我们的输入图像并将其转换为4096维向量,然后在该 4096 维向量之上应用线性分类器,所以我们可以尝试通过了解4096 维向量内部发生的事情来可视化地理解
我们使用训练好的AlexNet模型,在测试集的图像上进行前向推理,然后记录每个图像所生成的4096维特征向量,一旦我们收集了这类图像数据集及其特征向量,我们就可以尝试使用各种技术将它们可视化,首先我们在这些特征向量上使用最近邻算法

回想我们第一次使用最近邻算法的时候,是直接使用像素进行计算的,这个时候最近邻算法倾向于包含相似像素的图像判定为一类,尽管同一个类别的图像并不是真的同一个类别
在这里,我们使用AlexNet计算的特征向量进行最近邻搜索,这可以让我们理解分类器是如何学习特征空间中图像彼此之间的接近程度的,或者说,分类器是如何根据图像的特征向量来判断哪些图像是一个类别的
我们看上图中的例子,以第二行的大象类别为例,尽管不同图像中的背景和大象有不小的区别,但是仍然可以很好地完成分类,或者说,AlexNet在对图像进行处理的时候,忽略了图像中很多低级像素内容
亦或者可以这样理解,在这个向量中以某种方式编码像大象这样的东西,然后得到这样一个很好的特征向量
降维方法可视化
我们可以在4096维特征空间中训练分类器,但是我们这些三维空间中的人类很难去理解这个高维空间,所以只能想办法进行降维,让维数降低到二维三维,才可以进行人类可理解的可视化显示
这里首先是主成分分析(principal component analysis,PCA)方法,这是一种线性降维方法,可以尽可能保留高维特征空间的结构,并且进行线性的降维投影

然后还有一种方法就是t-SNE算法(t-Distributed Stochastic Neighbor Embedding),这是一种用于数据可视化的降维技术,特别擅长处理高维数据。这种算法由Laurens van der Maaten和Geoffrey Hinton于2008年开发。t-SNE主要用于可视化高维数据集在二维或三维空间的分布,特性是非线性、保留局部结构和高维可视化
- 非线性:与主成分分析(PCA)等线性降维技术不同,t-SNE是一种非线性降维技术。这使得它能够处理复杂的数据模式。
- 保留局部结构:t-SNE尤其擅长保留数据的局部结构。这意味着在高维空间中相近的点在低维空间中也会相近。
- 高维可视化:由于t-SNE通常用于将数据降维到二维或三维,因此它是一种非常有用的数据可视化工具。
需要注意的是,尽管t-SNE有很多优点,但它也有一些限制。例如,t-SNE对超参数的选择很敏感,对于不同的超参数可能会得到非常不同的结果。此外,t-SNE的运算成本相当高,对于大规模数据集可能难以处理。
然后,我们对AlexNet在MNIST上计算的特征向量进行降维可视化,就可以看到,对于十种数字,的确倾向于不同的区域,这让我们知道,这个网络的确可以以某种方式对不同类进行编码

卷积激活的可视化
另外一种理解卷积神经网络想寻找什么东西的方法,就是将中间层的卷积激活可视化
比如说AlexNet的第五个卷积层,其输出特征图是13x13大小,128通道,这意味着第五个卷积层中有128个卷积核,所以我们可以尝试将单个通道的特征图转化为灰度图,当然,其中会有大量的纯黑色图像,因为激活函数的存在
对于特征图不为零的,我们与原始输入图像对齐,以下图为例,我们输入一张人像图,其中的一个卷积核实际上类似于人脸形状,这就是因为这个卷积核以某种方式与人脸或者人类肤色对齐了,所以让我们感觉,也许这个神经网络这一层内的卷积核以某种方式学会了对人脸或人类肤色做出反应

我们可以将这些卷积激活进行可视化,让我们有一些直觉,去感觉这些不同的卷积核可能会响应什么不同特征
为什么大多数图片都是黑色的,可能是因为ReLU是非线性的,任何负数都会被设置为零,任何正数都会原封不动,同时当我们可视化这个东西时,我们需要以某种方式将其压缩为0-255区间,可能对图像的整体亮度产生一些影响
最大激活区域(Maximally Activating Patches)
这个概念描述的是在给定神经网络层级中,能产生最大激活值的图像片段或区域;在训练卷积神经网络时,每一层的神经元都会学习到对某些特征的响应,例如颜色、形状或更复杂的图像特征。当输入图像中包含这些特征时,相应的神经元会被 “激活”。因此,“Maximally Activating Patches” 就是那些能引发特定神经元最强烈反应的图像区域,也叫最大激活图块。
通过观察这些最大激活区域,我们可以理解和解释神经网络是如何 “看” 图像的,以及它是如何做出决策的。这对于理解神经网络的工作原理,提高模型的性能,以及提高模型的可解释性都是非常有用的。
因为这是一个卷积神经网络,所以激活网格中的特征网格中的每个元素,实际上都对应于输入图像中的一些有限大小的图块(最小是一个卷积核大小,最大是整张图大小),这是因为假设卷积核都是3x3大小,两次卷积堆叠,一个元素就取决于5x5的一个图块,三次堆叠就是取决于7x7的图块
还是那个训练好的模型,我们这一次选择中间的卷积层,然后输入所有的图像,并且找到那些所选神经元作出最高响应的图块,然后记录并且显示这些图块,我们就可以尝试了解所选神经元正在寻找什么特征

从上图我们可以看到,第一行的元素,在尝试寻找狗鼻子样式的特征,或者看其他的元素,对应的最大激活区域都有很类似的特征
这种最大激活区域的可视化方法,可以让我们了解中间卷积层在识别什么
通过遮挡方式的显著性可视化
所以我们可以尝试做的另一件事,是了解这些网络使用输入图像中的哪些像素来计算结果,这个对分类问题很重要

我们还是有一个训练好的模型,然后我们输入一张大象图片,然后得到了正确的分类结果,我们想知道,其中哪些像素,对于网络将图片分类为大象这件事上,做出了更大贡献
我们对大象图片进行一些处理,使用灰色方块将某些地方遮挡住(或者将图像中某些区域的像素替换掉),然后将这个图像传入卷积神经网络,然后重复这个过程,每次覆盖不同区域,然后输入到网络中进行分类,计算网络中每个位置有大象的概率,然后我们就可以得到一个代表分布概率的显著性图(saliency map)(上图右侧),我们就可以看到哪些像素对于分类很重要
如果我们将大象所在位置遮挡,那么相应的显著性地图上大象的预测概率就会下降很多,这是很直观的,意味着神经网络实际上以某种方式在看图像的正确部分做出分类决定
我们在其他图片上重复这种方式,可以得到类似的结果:我们遮挡住天空或者山脉,那么神经网络仍可以准确预测(或者很自信的将其归类正确),但是如果我们将车或者帆船遮挡,那么就不会那么准确
但是,如果你的数据集里面,存在了可以让神经网络作弊的方式,使得神经网络看错但是仍然得到正确答案,那么我们通过这种方式就可以看出神经网络是否有问题,或者说判断神经网络是否在看那些我们认为它在做正确决定时候应该看的图像部分,比如说神经网络看到海上帆船的图片,它看到特定颜色的海水就判断图片为帆船,而不是看到帆船才判断图片为帆船
但是这种方式,要计算很多次,计算量大,所以我们在考虑其他的方式
反向传播方式的显著性可视化
首先获取我们的输入图像,即这只可爱的狗(下图所示),然后在反向传播中,我们可以计算狗得分相对于输入图像中每个像素的梯度,这告诉我们输入图像中的每个像素,如果我们稍微改变那个像素,那么它会在多大程度上影响网络末端的分类分数,在显著性图中,亮度较高的区域表示这些像素对模型的决策影响较大

利用这种图像梯度,我们可以得到一个梯度显著性图(也叫梯度回传图),就上图右下角的有点类似于幽灵的图片,它告诉我们,最能改变分类分数的像素实际上是狗内部的像素,如果我们要更改狗外部的一些像素,那么分类分数可能不会改变那么多
所以这再次让我们知道,神经网络正在查看图像的正确部分,你可以使用它来获得一些关于神经网络正在学习什么的直观理解(如下图所示)

但是注意一下,我们使用这种方式必须有一个已经训练好的模型了,如果我们在一个还没有训练好的模型上这样操作,那么我们得到的显著性图可能会非常杂乱
这是因为卷积结构实际上对计算的函数有很强的正则化作用,也就是使得模型尽可能利用更多特征来进行判断,但是未训练的模型还没有学习到如何有效地从输入图像中提取有用的信息,模型对任何特定的输入图像或类别都没有偏好,所以我们无法从梯度显著性图中得到有意义的解释。
也就是说,图像中的任何区域都不会对模型的输出产生显著的影响,因为模型还没有学习到如何区分不同的类别或特征。
然而,随着模型的训练过程的进行,它将开始学习到如何从数据中提取有用的特征,这时我们就可以开始使用梯度显著性图来理解和解释模型的行为了。
显著性图:无监督分割
我们已经得到了梯度的显著图,我们是不是可以根据这个显著图,去无监督的分割出图像中的对象,比如说下图中,我们可以分割出蚱蜢、蛇等对象

我们可以尝试使用这些显著图,并在这些神经网络计算所得的显着图上使用某种图像处理技术,然后我们就可以使用训练好的网络,来以某种方式实现对输入图像中与对象类别对应的部分的分割操作
所以我们有这种想法,使用梯度信息计算每个像素,查看每个像素对最终输出分数的影响有多大,这样可以理解神经网络正在做什么,但是我们不局限于此,我们想使用梯度信息来查看网络内部寻找的中间特征
通过引导反向梯度寻找的中间特征
我们想使用梯度信息来查看网络内部寻找的中间特征,那么我们使用训练好的模型,然后对一张图片进行测试并且完成中间层开始的反向传播,然后就可以看到哪些像素不会影响分类结果,但是会影响中间层神经元的值,或者说查看哪些像素对中间神经元的影响最大
注意一下,我们使用训练好的模型和一个图像完成前向推理之后,不是从损失函数或者分类结果开始反向传播的,而是从中间层开始的
引导反向传播的基本思想是:在反向传播过程中,如果某个神经元的激活值是负的,那么就将这个神经元的梯度设为零。这意味着,只有那些既被激活又对特定类别有正影响的特征,才会被视为对该类别的预测重要。
对于使用 ReLU 激活函数的网络,这可以通过在反向传播过程中将所有负的梯度设为零来实现。这样做的直观理解是,我们只关心那些激活值为正(即被激活)并且对预测结果有正向贡献的神经元。
使用这种方法来可视化的时候,可以使图像变得更好,便于我们查看哪些像素对神经元的输出有更大影响,下图就展示了不同神经元在寻找哪些特征,或者说哪些像素的确对神经元的输出有重大影响

梯度上升
之前我们是针对训练好的模型来测试图像,看哪些像素会影响到神经元输出或者分类结果,我们现在可以更进一步,不是去测试图像,而且尝试去找到一个可以最大化神经元输出的图像
激活最大化是一种用于理解深度学习模型,特别是 CNN 的方法。它的基本思想是生成一张图像,这张图像能最大化某一特定神经元的激活值。通过这种方式,我们可以直观地理解这个神经元是如何响应输入的。
同时我们也要使用正则化函数,来使得我们的图像变得自然,避免过拟合和保持生成的图像的可解释性,否则生成的图像可能会出现过度复杂、难以解释,或者在人类看来并不像是任何有意义图像的情况。这是因为神经网络可能会过度地在每个像素上调整细节,以获取可能的最大激活,而这些细节可能对人眼是无法理解的。

具体来说,激活最大化首先选择一个神经元,然后创建一张随机噪声图像或者零元素图像。接着,它使用梯度上升方法来修改这张图像(这有些类似于训练网络模型,使损失函数最小),使得所选神经元的激活值最大化。这个过程持续多次迭代,直到图像收敛(如)。
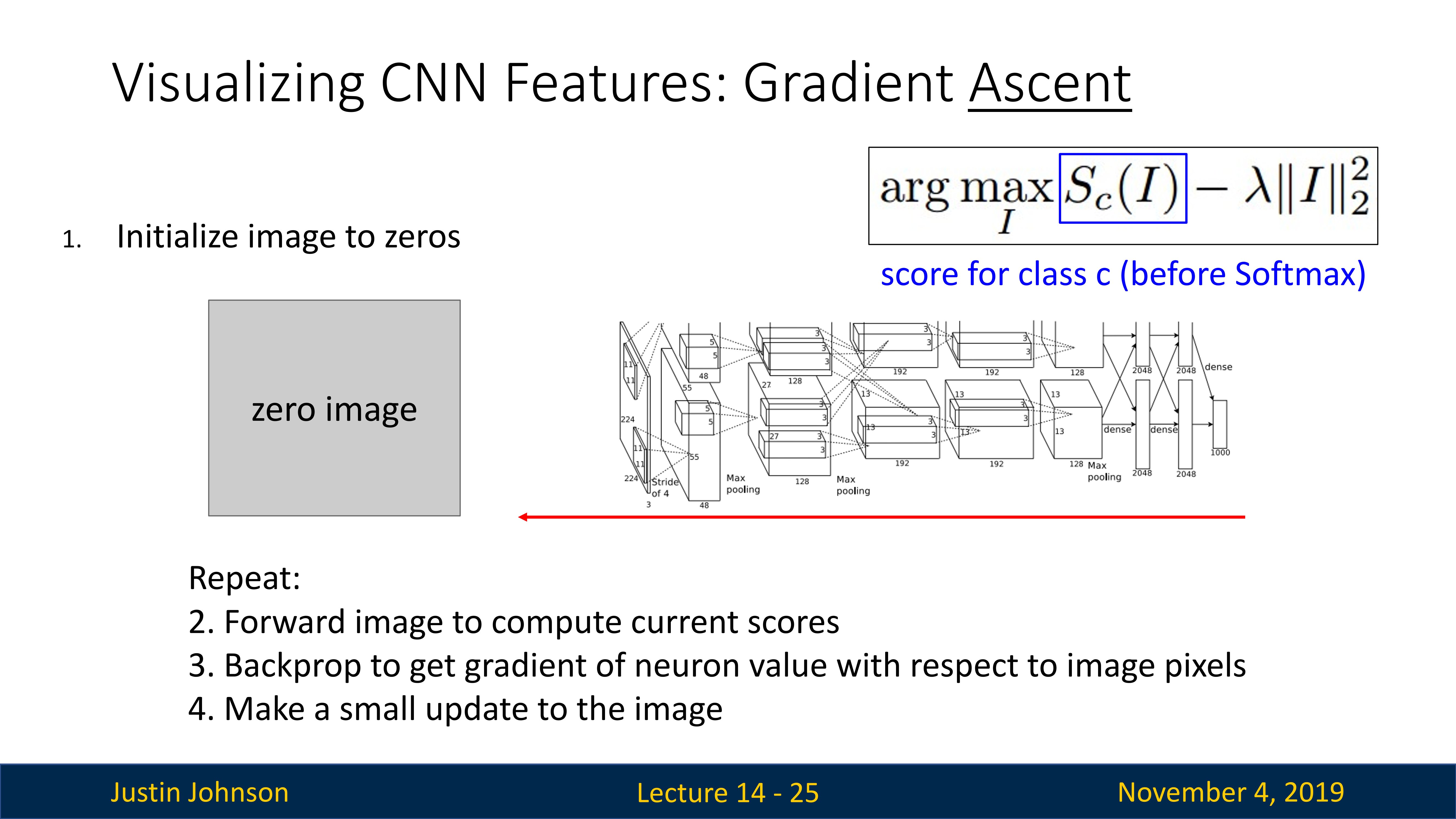
通过这种方式,我们可以生成一张图像,这张图像能够“激活”模型中的一个特定神经元。这可以帮助我们理解这个神经元在寻找什么样的特征,从而提供一种理解模型如何工作的方法。例如,对于一个图像分类模型,我们可以使用激活最大化来理解模型是如何识别出不同类别的。

上面这张图就是使用已经训练好的模型,对神经元进行反向传播生成的一些最大化激活图像,可以看到一些有点粗糙的形状,因为所使用的正则化器不是特别好,所以图像并不是特别逼真,所以一直有人尝试发明更好的正则化器使得这种方式生成的图像更自然,比如说下图中的图像就更为自然

当然,有的人对于使用更复杂的自然图像正则化器来生成看起来更逼真的图像这件事非常着迷,所以就有了一些非常奇特的正则化器,它实际上基于一个生成对抗网络,可以生成一些非常精美自然的图像(如下图所示)

这种研究方向的初衷是为了理解神经网络实际上在寻找什么,讲师Justin博士认为,越执着于强大的正则化器来寻找这些最大激活图像,就越会误入歧途,所以当他看到这样精美的图像时,很难说其中有多少是卷积神经网络实际正在寻找的;他倾向于使用简单的正则化器,认为这样才可以更纯粹地了解卷积神经网络在寻找什么样的原始图像和特征
对抗性样本
对抗性攻击是一种针对神经网络的攻击方式,通过向输入数据中加入极小的扰动(对于人类几乎无法察觉的改变),可以导致神经网络产生错误的预测。
这种现象首次在2014年由Ian Goodfellow等人的研究中发现。他们发现,通过优化一个目标函数,可以生成特定的噪声,将这个噪声添加到原始图像上,即使这个噪声非常小到人眼几乎看不出来,但却能够导致神经网络完全改变其预测结果。这种被添加了噪声的图像被称为对抗性样本(Adversarial Example)。
下图中,分别对大象和帆船图像中加入人类无法察觉的噪声,会导致神经网络预测结果的严重偏差。

对抗性攻击揭示了深度学习模型在面对微小扰动时的脆弱性,这对于深度学习的安全性和鲁棒性研究具有重要意义。例如,在自动驾驶、医疗诊断等关键领域,对抗性攻击可能会导致严重的后果。
对于如何防御对抗性攻击,目前还没有十分完美的解决方案,但已有一些常用的防御策略,如对抗性训练(在训练过程中加入对抗性样本),或是输入转换(例如,对输入进行降噪或压缩,以去除可能的对抗性噪声)。
特征反转
特征反转(Feature Inversion)是一种在计算机视觉中常用的技术,旨在理解卷积神经网络的内部运行机制。其核心思想是,给定一个图像,得到神经网络中的特定层的特征表示,使用梯度下降法,试图重建一个在特征上与原始输入图像尽可能相近的图像。

特征反转的过程通常是通过优化算法(如梯度下降或梯度上升)实现的。首先,我们从CNN中选择一个特定层,然后将一张输入图像通过网络前向传播,得到该层的特征表示。接下来,我们创建一张随机噪声图像,并通过网络前向传播到相同的层,得到该噪声图像的特征表示。然后,我们定义一个损失函数,其值为这两个特征表示之间的差异,最后使用优化算法来最小化这个损失。在这个过程中,噪声图像会被不断调整,使得它在网络中的特征表示尽可能接近原始图像的特征表示。
这种技术可以帮助我们理解神经网络中的每一层在学习什么。例如,如果我们选择的是网络的第一层,那么通过特征反转生成的图像通常会与原始图像非常接近,因为第一层通常学习到的是低级特征,如边缘和颜色等。然而,如果我们选择的是网络中更深的层,那么生成的图像可能会更加模糊和抽象,因为这些层通常学习到的是更高级的、抽象的特征。
特征反转为我们提供了一种直观的方法,去理解神经网络中的每一层在图像识别过程中的作用,从而有助于我们更好地理解和改进神经网络模型。