字典树
好不容易不用学EXKMP,开森,实际上字典树很简单,我们看:
已知有 n 个长度不一定相同的母串,以及一个长度为 m 的模式串 T,求该模式串是否是其中一个母串的前缀。如果将模式串 T 挨个去比较,则算法复杂度会很高,达到 O(n×m),是否有高效的方法呢?
已知一个长度为 n 的字符串 S,求该字符串有多少个不相同的子串。朴素的做法,可以先枚举出所有的子串,这样时间复杂度为 O(n^2),之后再去重,直接做算法复杂度很高,改成哈希或者用 set、map 处理,整体复杂度仍然会很高。
实际上,我们可以用 Trie 树来高效求解这两个问题。
Trie 树又称字典树或者单词查找树,是一种树形结构的数据结构,支持字符串的插入、和查询操作,常用于大量字符串的检索、去重、排序等。Trie 树利用字符串的公共前缀,逐层建立起一棵多叉树。在检索时类似于在字典中查单词,从第一个字符开始遍历,在 Trie 树中一层一层往下查找,查找效率可以达到 O(n),n 为查找字符串的长度。
下图是一棵以词:a、to、tea、ted、ten、i、in、inn构成的字典树,其中带下划线的结点为 终端结点(从根结点到终端结点的遍历过程就是 Trie 中存储的一个字符串)。注意$表示的根节点,是空的
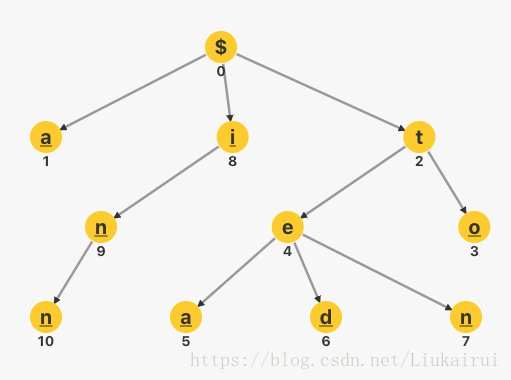
Trie 树有以下特点:
1.Trie 树的根结点上不存储字符,其余结点上存且只存一个字符。
2.从根结点出发,到某一结点上经过的字符,即是该结点对应的前缀。每个结点的孩子结点存储的字符各不相同。
3.Trie 树牺牲空间来换取时间,当数据量很大时,会占用很大空间。如果字符串均由小写字母组成,则每个结点最多会有 2626 个孩子结点,则最多会有 26n26n 个用于存储的结点,nn 为字符串的最大长度。(实际上这个可以优化)
4.Trie 树常用于字符串的快速检索,字符串的快速排序与去重,文本的词频统计等。
使用字典树我们首先要建立trie的数据结构,注意:与二叉树不同,二叉树我们用的数据结构是node,是为点做的数据结构,而trie是为整个数做的数据结构!
下面给出构建数据结构的代码
const int MAX_N = 10000; // Trie 树上的最大结点数
struct Trie {
int ch[MAX_N][26]; // ch 保存了每个结点的 26 个可能的子结点编号,26 对应着 26 种小写字母,也就是说,插入的字符串全部由小写字母组成。初始全部为 -1
int tot; // 总结点个数,初始为 0
int cnt[MAX_N]; // 每个结点
void init() { // 初始化 Trie 树
tot = 0;
memset(cnt, 0, sizeof(cnt));
memset(ch, -1, sizeof(ch));
}
};然后我们开始写插入函数,注意,插入函数的参数是char *X,所以调用的时候给的应该是数组而不是字符串!具体见这个题的调用:传送门
void insert(char *str) {
int p = 0; // 从根结点(0)出发
for (int i = 0; str[i]; ++i) {
if (ch[p][str[i] - 'a'] == -1) { // 该子结点不存在
ch[p][str[i] - 'a'] = ++tot; // 新增结点
}
p = ch[p][str[i] - 'a']; // 在 Trie 树上继续插入字符串 str
}
cnt[p]++;
}现在开始写查询函数
int find(char *str) { // 返回字符串 str 的出现次数
int p = 0;
for (int i = 0; str[i]; ++i) {
if (ch[p]==NULL||ch[p][str[i] - 'a'] == -1) {
return 0;
}
p = ch[p][str[i] - 'a'];
}
return cnt[p];
}但是,这个有一个问题,ch数组开了MAXN*MAXC的大小,这是严重的空间浪费,可能会整道题都MLE。这时,可以使用内存动态分配的小技巧。我们在一个结点一定有子结点的时候再给它开辟大小为 MAX_C 的子结点指针数组就可以了,这样能减少很多不必要的内存开销。就像线段树的lazy标记一样,不用就在哪里皮这不动
至此,给出字典树模板两个,个人还是喜欢第一个
第一个
const int MAX_N = 10000; // Trie 树上的最大结点数
const int MAX_C = 26; // 每个结点的子结点个数上限
struct Trie {
int *ch[MAX_N]; // ch 保存了每个结点的 26 个可能的子结点编号,26 对应着 26 种小写字母,也就是说,插入的字符串全部由小写字母组成。初始全部为 -1
int tot; // 总结点个数(不含根结点),初始为 0
int cnt[MAX_N]; // 以当前结点为终端结点的 Trie 树中的字符串个数
void init() { // 初始化 Trie 树,根结点编号始终为 0
tot = 0;
memset(cnt, 0, sizeof(cnt));
memset(ch, 0, sizeof(ch)); // 将 ch 中的元素初始化为 NULL
}
void insert(char *str) {
int p = 0; // 从根结点(0)出发
for (int i = 0; str[i]; ++i) {
if (ch[p] == NULL) {
ch[p] = new int[MAX_C]; // 只有 p 当包含子结点的时候才去开辟 ch[p] 的空间
memset(ch[p], -1, sizeof(int) * MAX_C); // 初始化为 -1
}
if (ch[p][str[i] - 'a'] == -1) { // 该子结点不存在
ch[p][str[i] - 'a'] = ++tot; // 新增结点
}
p = ch[p][str[i] - 'a']; // 在 Trie 树上继续插入字符串 str
}
cnt[p]++;
}
int find(char *str) { // 返回字符串 str 的出现次数
int p = 0;
for (int i = 0; str[i]; ++i) {
if (ch[p]==NULL||ch[p][str[i] - 'a'] == -1) {
return 0;
}
p = ch[p][str[i] - 'a'];
}
return cnt[p];
}
} tire;第二个
#include <iostream>
#include <string.h>
using namespace std;
const int maxn = 10010;
struct Trie {
int ch[maxn][26];
int cnt[maxn];
int num;
void init() {
memset(ch[0], 0, sizeof(ch[0]));
cnt[0] = 0;
num = 0;
}
int newnode() {
++num;
memset(ch[num], 0, sizeof(ch[num]));
cnt[num] = 0;
return num;
}
void insert(char *s) {
int u = 0;
for (int i = 0; s[i]; ++i) {
if (!ch[u][s[i] - 'a']) {
ch[u][s[i] - 'a'] = newnode();
}
u = ch[u][s[i] - 'a'];
++cnt[u];
}
}
int query(char *s) {
int u = 0;
for (int i = 0; s[i]; ++i) {
if (!ch[u][s[i] - 'a']) {
return 0;
}
u = ch[u][s[i] - 'a'];
}
return cnt[u];
}
} trie;
int main() {
trie.init();
trie.insert("china");
trie.insert("chinese");
trie.insert("children");
trie.insert("check");
cout << trie.query("ch") << endl;
cout << trie.query("chi") << endl;
cout << trie.query("chin") << endl;
cout << trie.query("china") << endl;
cout << trie.query("beijing") << endl;
return 0;
}