最近在写自动化用例的时候涉及到了大量的文本文件/字符串处理,常用的有正则表达式re、grep、sed、awk命令,在Linux中常用的是grep命令,而用python代码中,最常用的文本提取与处理就是正则表达式,从字符串中抓取有用的关键信息。本文对常用的几种re模块中的搜索函数进行了总结。
本文示例使用的是python3.7版本,re模块版本2.2.1
re模块搜索函数
re模块有12个函数,常用的字符串搜索函数为findall和search。两者的区别为:search用于查找第一个匹配项,匹配成功则返回一个匹配的对象,否则返回None;findall用于查找多个匹配项并返回一个列表。
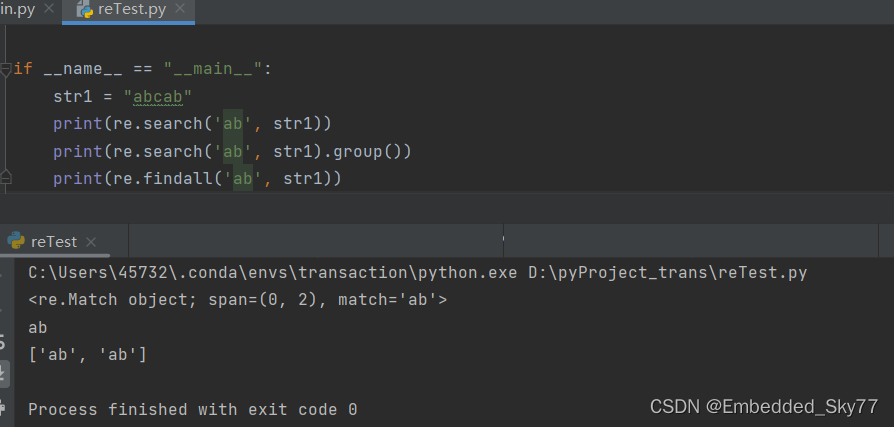
re.match与search类似,不过因为只从字符串的开始进行匹配,使用场景较少;
re.finditer与findall类似,不过因为返回一个迭代器,使用起来不如findall直接返回一个列表方便。
修饰符-可选
re模块有9个修饰符来控制匹配的模式如re.M、re.I,该修饰符都是2的幂次方值,可以叠加使用,通过按位或符号“|”。其中常用的有:
re.M用于多行匹配;
re.I使匹配对大小写不敏感;
re.DOTALL 或简写为 re.S: DOT表示.,ALL表示所有,连起来就是.匹配所有,包括换行符\n。而默认模式下.是不能匹配行符\n的。
注意事项
正则表达式模式
| 独立使用 | |
|---|---|
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
| * | 匹配0个或多个的表达式。 |
| + | 匹配1个或多个的表达式。 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式(找到最近的直接返回,不查找最长的) |
| {n} | 匹配n个前面表达式。例如,"o{2}“不能匹配"Bob"中的"o”,但是能匹配"food"中的两个o。 |
| […] | 用来表示一组字符,单独列出。如[ab] 匹配一个 ‘a’或一个’b’ |
| a|b | 匹配a或匹配b |
| \w | 匹配数字字母下划线 |
| \W | 匹配非数字字母下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| 组合使用举例 | |
|---|---|
| [ab]{2} | 取a或b,匹配两次。即匹配’aa’或’bb’ |
| [ab]{1,2} | 取a或b,匹配一次或两次(贪婪方式)。即优先匹配’aa’、‘bb’、‘ab’、‘ba’,再匹配单个’a’或’b’ |
| (.*)\n | 匹配任意字符到直到最后一个换行符之前的字符 |
| (.*?)\n | 匹配任意字符到第一次出现换行符之前的字符 |
r 的作用
python中字符串使用反斜杠(’\’)来表示特殊形式如\t、\b,或者把特殊字符转义成普通字符如\\;字符串前的r表示raw,即不对转义符号进行转义,全部理解为普通字符串。
在正则表达式中,r同样表示不进行特殊转义,而不同点在于正则中多了一步:先将参数付给正则表达式,然后再将正则式与字符串进行匹配**(如果存在转义符则再次转义)**的步骤。如果正则中参数0存在反斜杠而不进行转义,依旧会在进行匹配时先进行转义,随后再和参数1进行匹配。
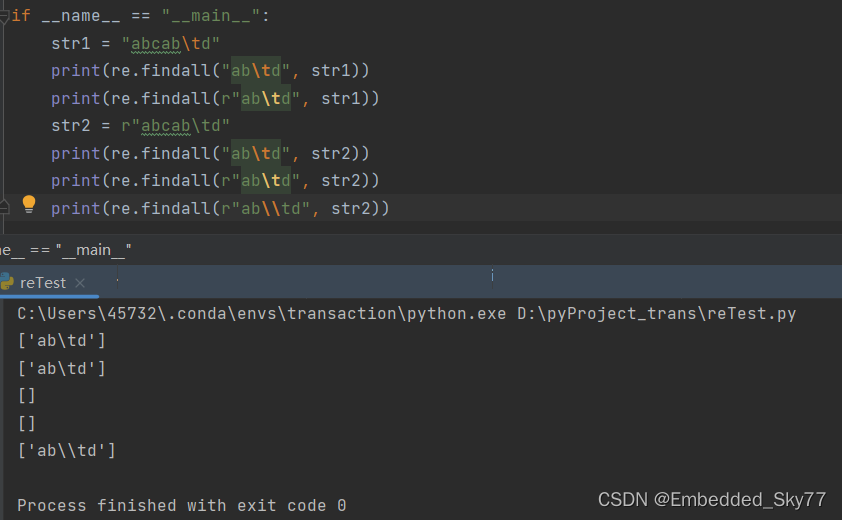
第一种情况:在正则的参数中转义为了制表符,与同样不转义的str1匹配成功。
第二种情况:在正则的参数中不转义,而与str1匹配时,python解释为了制表符,匹配成功。
第三种情况:在正则的参数中转义为制表符;而str2中只有不转义的两个字符\和t,匹配失败。
第四种情况:在正则的参数中不转义,入参即为\t,而与str2匹配时,python解释为了制表符;而str2中只有不转义的两个字符\和t,匹配失败。
第五种情况:在正则的参数中不转义,入参即为\t,而与str2匹配时,python解释为了两个字符\和t,匹配成功。