两年前写过一个库代码,写这个库代码的时候也是咨询了各路大神们,当时也是由于技能储备不足,完成的也是小心翼翼,也是如期上线.
两年时间过去了,最近在排查该项目现场某一性能问题的时候定位到可能是由于当时的类库实现的“不高效”引起的。首先看下直接表现出来的问题。
- CPU用户进程使用率低,系统进程使用CPU异常的高,这是非常反常的,更何况64个cpu核心都在系统进程中处于持续高的状态,而该服务本身并非一个CPU密集型任务,top 1下cpu的使用率截图如下:
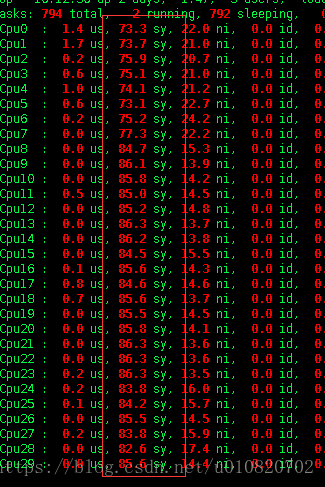
- 吞吐量下降,不拒绝服务,由于系统进程CPU持续偏高,导致服务效率低下,整个系统卡顿、相关的用户服务持续卡顿,先关的java进程都不稳定。
- 通过和其它节点进行比较发现卡顿的节点数据接入量较高,同样的服务和差不多的硬件配置,同时也观察到对于并发量较小的节点也存在系统进程占用过高的情况但是并不明显,看上去CPU在系统进程中频繁做一些消耗CPU的操作,top 1截图如下:
基于以上原因,大致进行了一些辅助的确认操作。
- 降低tomcat的并发线程数,企图通过这种方式限制接口的吞吐,也是观察到系统进程的CPU从低持续升高到80%左右。
- 重启了物理机器,也不见起效,表现出一致的行为。
- 杀掉该服务,CPU瞬间恢复到正常状态。
很确认就是这个服务的问题,为何最近会表现出性能问题而以前一直没有被发现,先从类库设计的目标来说起
- 这是一个文件上传和下载的库程序,相比之下下载要简单的多,上传就要复杂一些,上传服务要条用接口来检查某个目录是否存在
- 内部的文件上传和下载的接口是非线程安全的
- 对外提供线程安全的上传、下载接口同时尽可能提供高的下载、上传的吞吐量
该类库在实现的时候采用了以下设计思想
- 提供的上传和下载接口是线程安全的
- 下载接口使用对象池的形式封装内部的非线程安全的下载接口,对外提供多个线程共享一组下载对象的访问方式。
- 上传接口使用ThreadLocal 进行线程隔离,每个线程使用Lru缓存机制维护了自己的多个内部的文件上传接口,切每个上传接口绑定了不同的文件目录。文件上传操作首先从自己的ThreadLocal 变量中过去对应文件目录的写对象,如果获取不到则创建一个新的并加入LRU缓存,同时返回新的写对象。
核心代码块:
下面是核心类的成员,readerPool为下载文件的对象池,维护多个MyReader的长连接用户下载图片.thread为线程绑定变量,维护一组使用Lru缓存维护的写对象.键值为写文件的目录.
public class DHDFSFileManager {
private static Logger Log = Logger.getLogger(DHDFSFileManager.class);
private static volatile EFSConfig cfg;
private static volatile ArchiveTool tool;
// 对象池
private static volatile ObjectPool<MyReader> readerPool;
// 线程绑定
private static ThreadLocal<LRUAri<ArchiveWriter>> thread = new ThreadLocal<LRUAri<ArchiveWriter>>();
}
下载文件方法,这个方法比较简单,只需要及时的释放资源就可以了。因为每个资源只能同时被一个线程持有,以此保证多线程环境下的并发安全性.
/**
* <h1>下载文件
*
* @param archname
* fileName
* @return byte array image content
*/
public static byte[] downloadFile(String archname) {
long start = System.currentTimeMillis();
System.out.println("start download,time:" + start);
MyReader reader = null;
ArchiveReader ar = null;
ByteArrayOutputStream out = null;
try {
reader = readerPool.borrowObject();
ar = reader.getReader();
ArchiveInfo ai = tool.getArchiveInfos(archname);
String fileName = ai.getFilename();
int len = (int) ar.open(fileName);
System.out.println("fileLen:" + len);
out = new ByteArrayOutputStream();
byte[] buf = new byte[len];
int getData = 0;
while (getData < len) {
int ret = ar.read(buf, len);
if (ret > 0) {
getData += ret;
out.write(buf, 0, ret);
}
if (ret == -1) {
System.out.println("read faile");
break;
}
}
Log.debug("upload{time:" + new Date().toString() + ",fileName:" + archname + "}");
ar.close();
Log.info("文件下载成功,FileName:" + archname);
System.out.println("end download,time:" + System.currentTimeMillis());
System.out.println("interval time :" + (System.currentTimeMillis() - start));
Log.debug("interval time :" + (start - System.currentTimeMillis()));
return out.toByteArray();
} catch (Exception e) {
// 失败
reader.setIsValid(false);
e.printStackTrace();
Log.debug("downloadfail{time:" + new Date().toString() + ",interval time :"
+ (start - System.currentTimeMillis()) + ",fileName:" + archname + "}");
System.out.println("文件下载失败!!");
return null;
} finally {
try {
if (out != null) {
out.close();
}
} catch (Exception e) {
e.printStackTrace();
}
try {
// 释放资源
readerPool.returnObject(reader);
} catch (Exception e) {
e.printStackTrace();
}
}
}
上传文件方法,这里实现的时候都检查了一次对应目录是否存在不存在则创建“checkOrCreateBucket(bucket);”
/**
* <h1>上传文件
*
* @param img
* image byte array
* @param bucket
* bucket name
* @return filename
*/
public static String uploadFile(byte[] img, String bucket) {
long start = System.currentTimeMillis();
System.out.println("sdtart upload,time:" + start);
ArchiveWriter aw = null;
String archname = null;
try {
checkOrCreateBucket(bucket);
aw = getWriter(bucket);
aw.open("jpg");
int len = img.length;
System.out.println("length:" + len);
int writeData = 0;
int offset = 0;
while (writeData < len) {
int ret = aw.write(img, len - offset);
if (ret < 0) {
System.out.println("write faile");
throw new Exception("write faile");
}
System.out.println(ret);
writeData += ret;
offset += ret;
}
System.out.println("writeSize:" + writeData);
archname = aw.close();
Log.debug("upload{time:" + new Date().toString() + ",fileName:" + archname + "}");
System.out.println("end upload,time:" + System.currentTimeMillis());
System.out.println("interval time:" + (System.currentTimeMillis() - start));
Log.info("文件上传成功,FileName:" + archname);
// writer.setIsValid(false);
} catch (Exception e) {
e.printStackTrace();
Log.error("文件上传失败!!");
return archname;
} finally {
aw = null;
}
return archname;
}
public static void checkOrCreateBucket(String bucket) {
try {
if (!tool.isBucketValid(bucket)) {
synchronized (obj) {
if (!tool.isBucketValid(bucket)) {
tool.createBucket(bucket);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
getWriter方法用来使用特定的目录名称来获取对饮的写对象,同时负责维护绑定到ThreadLocal变量中的信息,

/**
* <h1>get ArchiveWriter from Thread Local
*
* @param bucket
* bucket name
* @return ArchiveWriter write file
*/
public static ArchiveWriter getWriter(String bucket) {
LRUAri<ArchiveWriter> writers = thread.get();
Log.debug(writers);
if (writers == null) {
writers = new LRUAri<ArchiveWriter>(30);
thread.set(writers);
}
ArchiveWriter writer = writers.get(bucket);
if (writer == null) {
synchronized (obj1) {
if (writers.get(bucket) == null) {
writer = tool.createArchiveWriter();
writer.init((byte) 3, (byte) 1, bucket);
writers.put(bucket, writer);
thread.set(writers);
}
}
}
return writer;
}
以上的代码整体上是高效的,却因为一句代码带来了严重的性能问题,即uploadFile方法中的
checkOrCreateBucket(bucket);由于这段代码出现在uploadFile中造成每次在调用上传文件的方法时都会去检查目录是否存在且创建一个目录,内部封装的检查方法可能实现的并不是很高效,导致在执行该操作的时候引起平凡的系统调用以及线程上下文切换。在并发达到一定程度的时候星性能急剧下降。
public static void checkOrCreateBucket(String bucket) {
try {
if (!tool.isBucketValid(bucket)) {
synchronized (obj) {
if (!tool.isBucketValid(bucket)) {
tool.createBucket(bucket);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
设计上并无大的不妥,由于代码疏忽将checkOrCreateBucket(bucket)的调用时机提前了,修改后的uploadFile方法删除了代码片段
checkOrCreateBucket(bucket);替换的将检查目录是否存在的逻辑转移到getWriter方法中.
修改后的getWriter方法如下:
public static ArchiveWriter getWriter(String bucket) {
LRUAri<ArchiveWriter> writers = thread.get();
Log.debug(writers);
if (writers == null) {
writers = new LRUAri<ArchiveWriter>(30);
thread.set(writers);
}
ArchiveWriter writer = writers.get(bucket);
if (writer == null) {
synchronized (obj1) {
if (writers.get(bucket) == null) {
checkOrCreateBucket(bucket);
writer = tool.createArchiveWriter();
writer.init((byte) 3, (byte) 1, bucket);
writers.put(bucket, writer);
thread.set(writers);
}
}
}
return writer;
}
即每次在创建每个Writer对象的时候检查是否存在对应的目录文件,这样只有在首次出现一个不存在的目录或者之前的目录被LRU算法过期后才去检查是否应该创建一个目录文件.
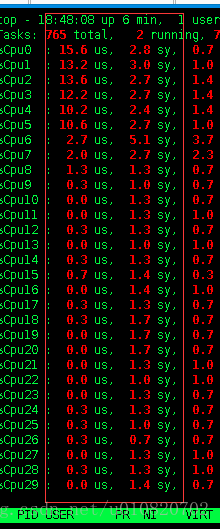
修改后的类库替换到生产环境后,持续观察了CPU的使用情况,如下

可以看到系统进程的占用量大大降低.且每个核心的CPU使用情况并不是持续的密集的。图片上传服务本身是IO密集型的作业,这是正常的表现。
使用资源池暴露线程安全的访问行为,一个资源在某一时刻只能被一个线程持有并使用,使用ThreadLocal将共享资源封闭在线程中。
对于常见的带有条件的测试操作,使用缓存可以有效降低频繁测试带来的性能开销,即便是一个实现高效的测试接口,糟糕的是通常情况下我们并不知道这个接口的实现细节。
总结一下:
7分设计,3分编码。额外的还需要持续的测试在测试。