图像分割任务,其目的是实现像素级分类,输出结果是一个与输入图像尺寸相同的二维矩阵,矩阵中的值对应该像素所属的类别。
1 概述
1.1 任务类型
-
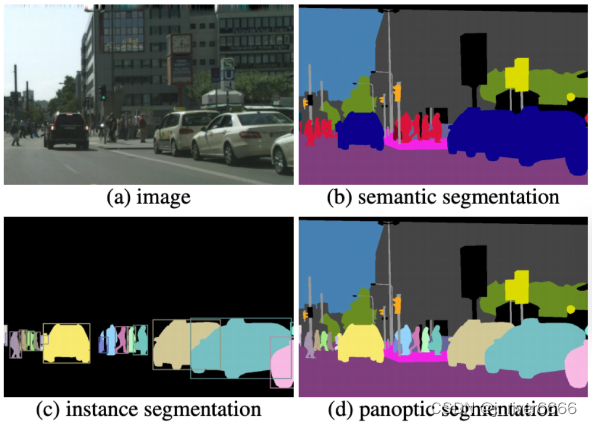
语义分割:每个像素所属类别(包括stuff和object类), 同类别相邻实例间无法区分
-
实例分割:每个object类别和mask(只有object类)
-
全景分割:每个像素所属类别和object类别的实例id, 同类别相邻实例可区分
1.2 评价指标
-
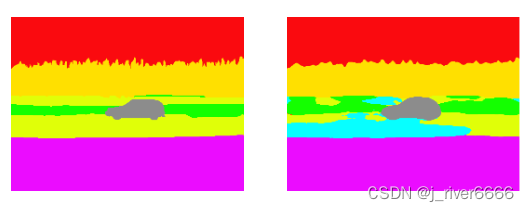
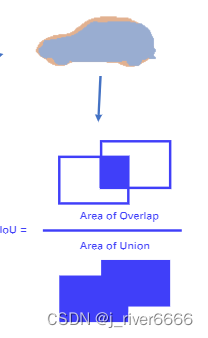
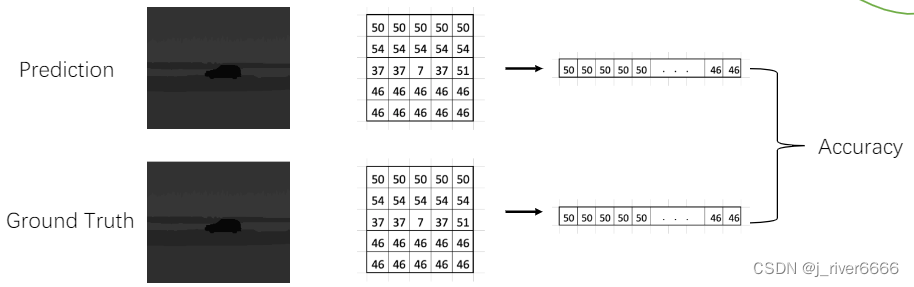
mIOU:每一类别的分割交并比的平均值

-
mAcc:分类正确率的平均值
2 语义分割模型
2.1 FCN
FCN,全称fully convolutional networks
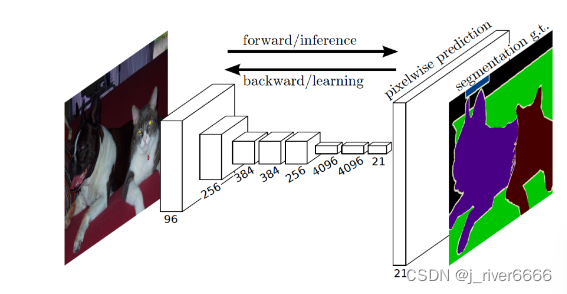
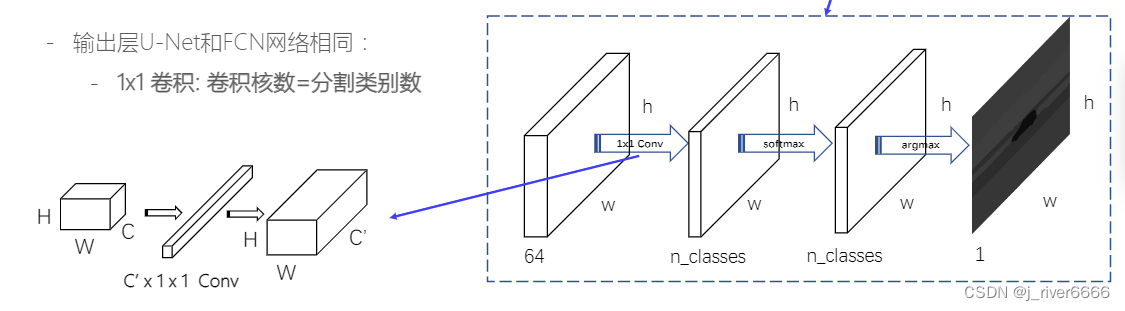
分割的输出结果是一个与输入图像尺寸相同的二维矩阵,矩阵中的值对应该像素所属的类别。FCN中使用1x1 conv代替fc层,将输出的特征维度调整到所需要的维度。
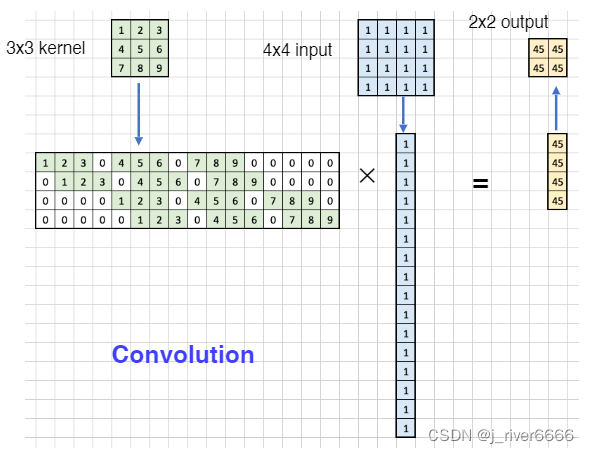
分割过程中,先对图像进行下采样,提取图像特征,此时feature map的尺寸不断减小;后续为了输出与原图大小相同的feature map,需要进行上采样。上采样的方式一般有三种:up-sampling、Transpose Conv、Un-pooling
-
up-sampling:Bilinear Interpolation

-
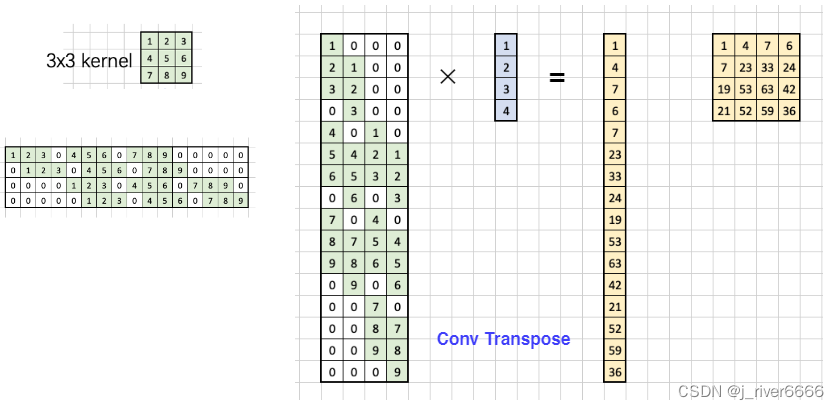
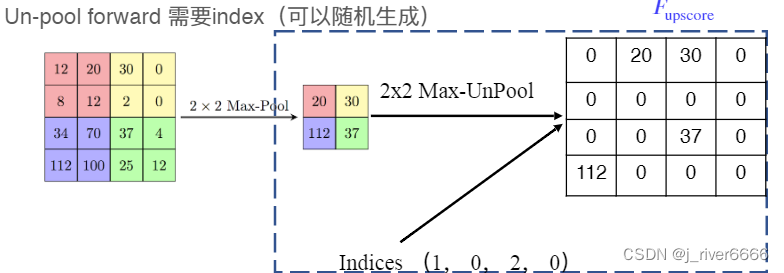
Transpose Conv, 反卷积
-
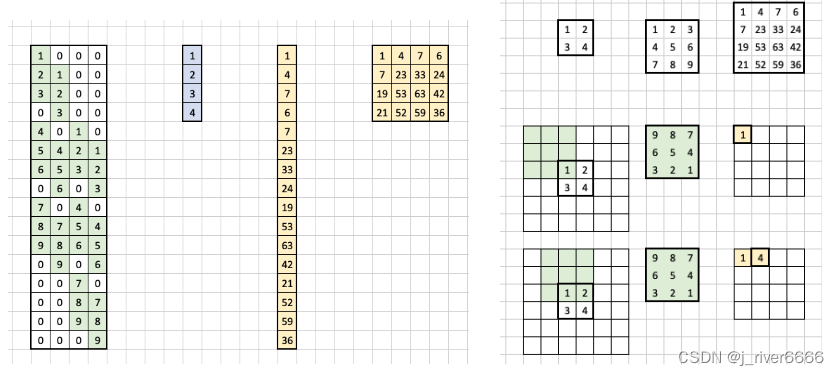
Un-pooling
2.1.1 模型结构
上采样策略:采用多尺寸feature map进行上采样,然后element-wise add进行特征融合

2.1.2 优缺点
-
优点
-
任意输入尺寸
-
结合了浅层信息
-
-
缺点
-
分割结果不够精细(没有充分考虑浅层信息)
-
没有有效考虑上下文信息(感受野较小)
-
2.2 U-Net
2.2.1 模型结构
U-Net,采用encoder-decoder的U形结构。上采样过程中,特征融合是采用Concatenate形式;如果尺寸不匹配,采用crop操作获取对应尺寸的feature map。

2.2.2 优缺点
-
优点:每次上采样concat上一层feature map, 更加充分的利用了浅层信息,有利于提高边缘精度
-
缺点:显存占用大
2.3 PSP-Net
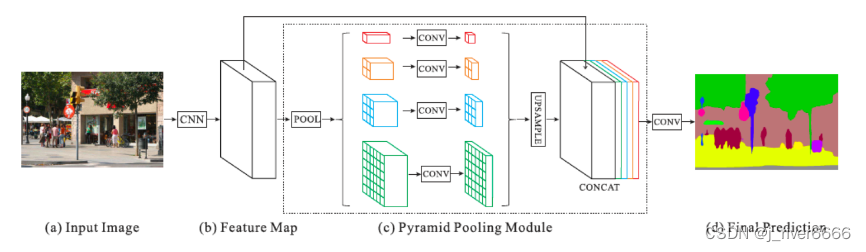
PSP-Net(Pyramid Scene Parsing Network),在FCN的基础上,为了更好的考虑全局信息,引入了空洞卷积和Spatial Pyramid Pooling模块,提升模型性能。
2.3.1 模型结构
-
整体结构
-
backbone
Dilated ResNet, 在原resnet中引入空洞卷积,增大感受野

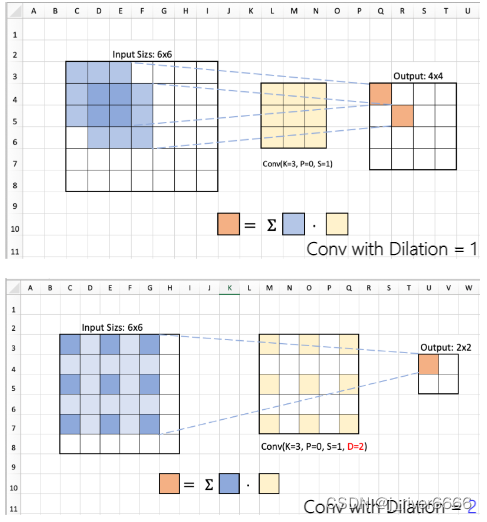
空洞卷积: 引入了一个称为 “扩张率(dilation rate)”的超参数(hyper-parameter),该参数定义了卷积核处理数据时各值的间距。
1. 增大感受野
2. 不降低分辨率(stride=1 , padding)
3. 不引入额外参数和计算
-
Spatial Pyramid Pooling模块:通过对输入特征图进行不同尺度的池化操作,融合了多个尺度的特征信息,并与原特征图进行concat,更好的结合了局部特征和全局特征。模块主要包括一下操作:
-
Adaptive Pool
-
1X1 Conv
-
Upsample
-
Concat
-

2.4 DeepLab系列
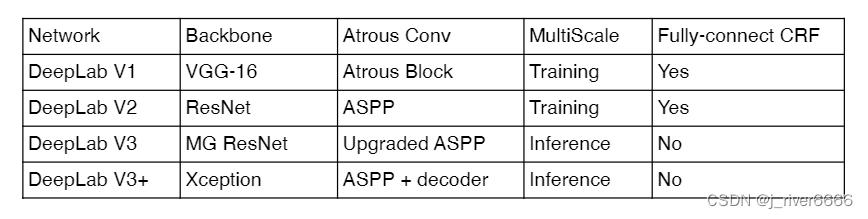
DeepLab系列是谷歌团队提出的一系列语义分割算法。
-
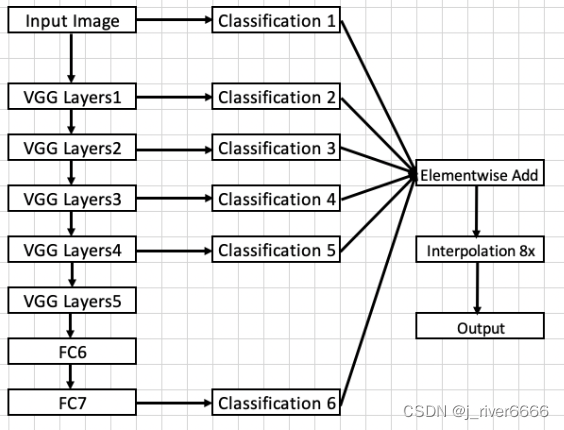
DeepLab V1
-
整体结构

-
-
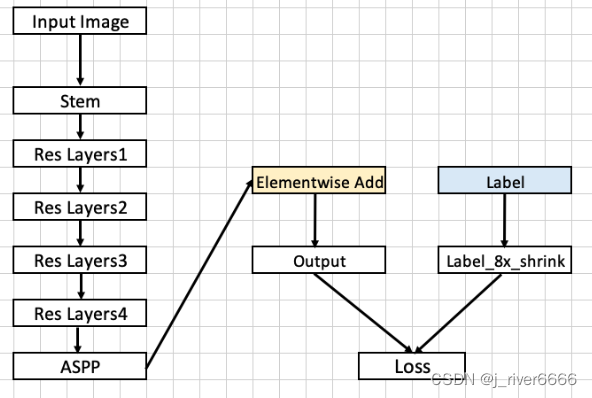
DeepLab V2
-
整体结构

-
ASPP

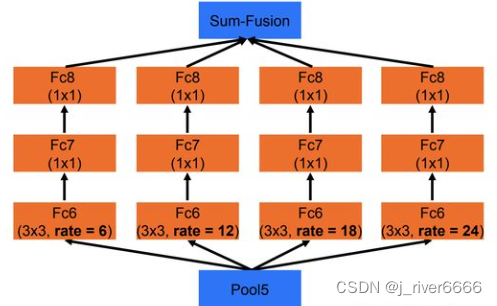
-
ASPP模块的目的与PSP-Net中的SPP模块相似,融合了不同尺度的特征信息,综合考虑局部特征和全局特征。区别在于:ASPP采用了不同dilation系数的空洞卷积+elementwise add操作, SPP采用了不同尺寸的池化+concat操作。
-
DeepLab V3
-
整体结构
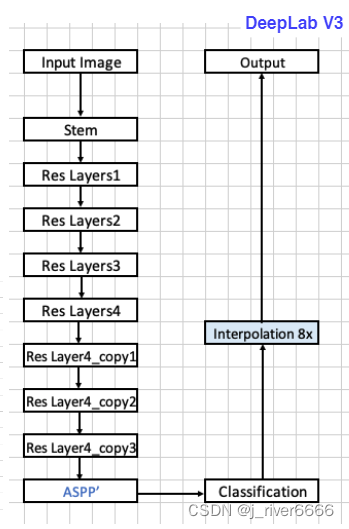
-
upgraded ASPP 模块
upgraded aspp模块相比aspp做了一些调整,更好地融合多尺度信息。
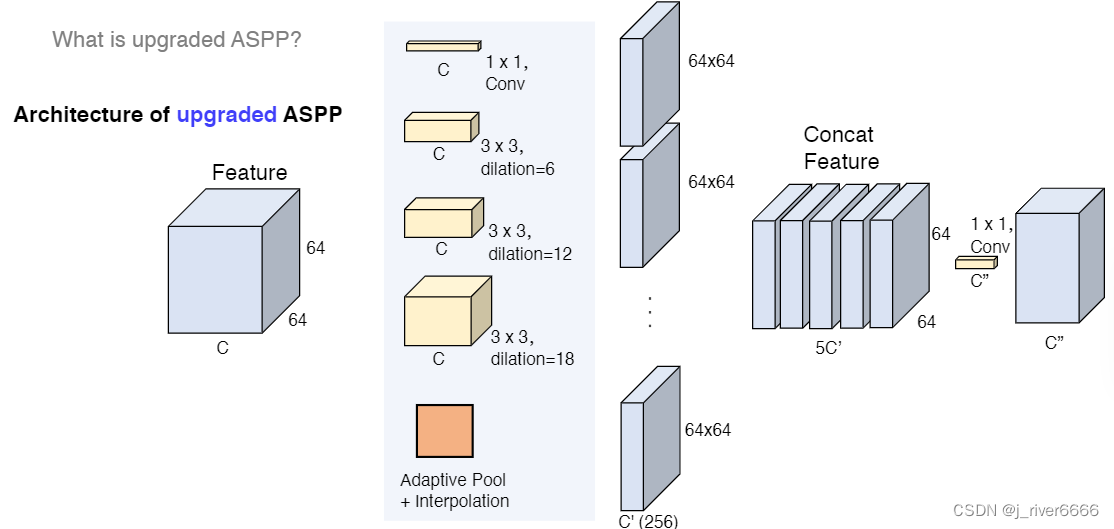
-
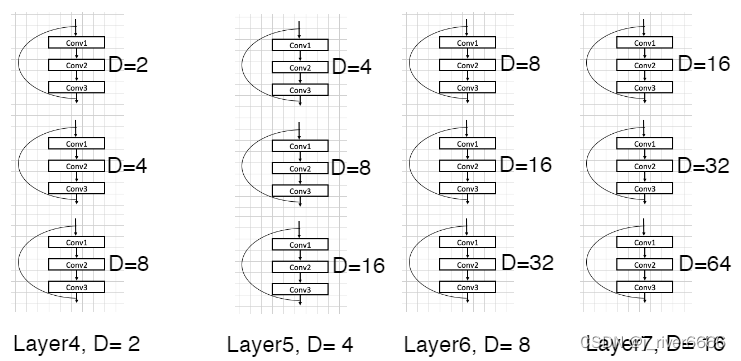
multi-grid
DeepLab v3的Multi-Grid策略参考了HDC(hybrid dilated convolution )的思想,它的思想是在一个block中连续使用多个不同扩张率的空洞卷积。HDC的的提出是为了解决空洞卷积可能会产生的gridding问题。这是因为空洞卷积在高层使用的扩张率变大时,它对输入的采样会变得很稀疏,进而导致丢失一些局部信息。而且会丢失一些局部相关性反而捕获了长距离一些语义上不相关的信息。
Gridding产生的原因是因为连续的空洞卷积使用了相同的扩张率。在图(a)中,连续使用了三个空洞卷积,那么对中心点分类结果的影响则源自于周围分连续的像素点。HDC的原理是对连续的空洞卷积使用不同的扩张率,如图(b)中使用的扩张率依次是 ,那么影响中心点类别的则是连续的一个区域,因此也更容易产生连续的分割效果。

Block-1到Block-4直接复制的残差网络的原始结构,然后又把block4复制了3次,得到了block5-7,它们使用了不同的扩张率,增大感受野的同时避免产生Gridding问题。

-
-
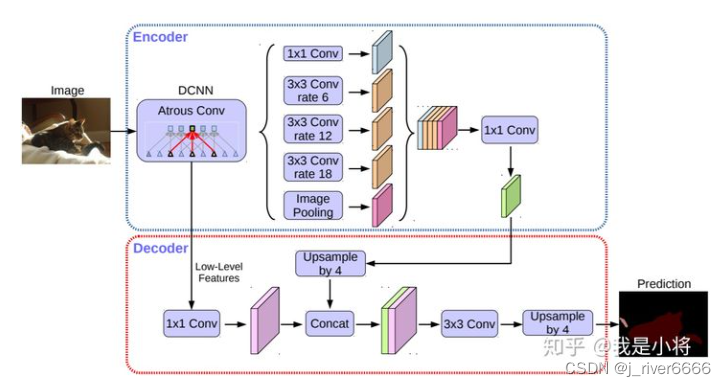
DeepLab V3+
DeepLabv3+模型的整体架构如下图所示,它的Encoder的主体是带有空洞卷积的骨干网络,然后接带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP)),引入多尺度信息;相比DeepLabv3,v3+引入了Decoder模块,其将浅层信息与深层信息进一步融合,提升分割边界准确度。
-
整体结构
-
backbone:Dilated Xception
-
decoder
对于DeepLabv3,经过ASPP模块得到的特征图的output_stride为8或者16,其经过1x1的分类层后直接双线性插值到原始图片大小,这是一种非常暴力的decoder方法,特别是output_stride=16。然而这并不利于得到较精细的分割结果,故v3+模型中借鉴了EncoderDecoder结构,引入了新的Decoder模块。首先将encoder得到的特征双线性插值得到4x的特征,然后与encoder中对应大小的低级特征concat,如ResNet中的Conv2层,由于encoder得到的特征数只有256,而低级特征维度可能会很高,为了防止encoder得到的高级特征被弱化,先采用1x1卷积对低级特征进行降维(paper中输出维度为48)。两个特征concat后,再采用3x3卷积进一步融合特征,最后再双线性插值得到与原始图片相同大小的分割预测。
-
2.5 HRNet系列
HRNet 是 2019 年由微软亚洲研究院提出的一种全新的神经网络,不同于以往的卷积神经网络,该网络在网络深层仍然可以保持高分辨率,因此预测的语义信息更准确,在空间信息上也更精确。
在之前所讲述的分割网络架构,主要包括两部分: Encoder和Decoder。Encoder部分,主要通过分辨率压缩(downsample--下采样),使得语义聚合,获取了丰富的语义特征,适合用做分类,但在连续下采样过程中丢失了许多空间信息,不利于分割这种对位置敏感的任务;为了提升分割的精度,Decoder部分逐步增大分辨率,最后得到高分辨率的feature map,这样的高分辨率特征对于位置敏感的任务是更友好的,能够保留更多的空间信息。但是在先下采样、再上采样的过程中,特征图分辨率先减小后增大,仍然会丢失空间信息。基于此,HRNet设计了一种保持高分辨率特征图的网络,从而可以得到更好更准的位置信息。
-
recover high resolution(encoder- decoder, 如PSP-Net、DeepLab)

-
maintain high resolution (HRNet)

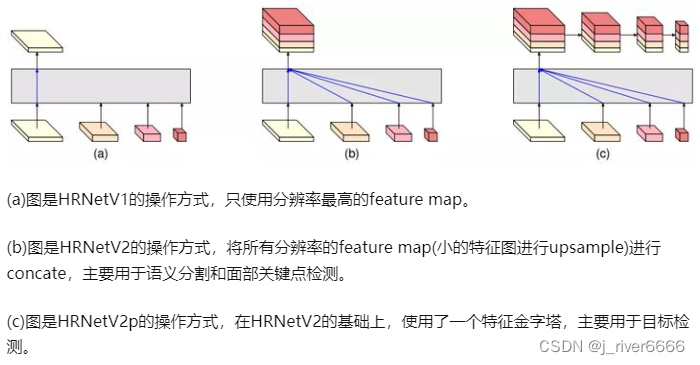
不同分辨率的特征图融合方式:

Head结构多样化:
2.5.1 MScaleOCR
MscaleOCRNet 从属于 HRNet 系列,相比于 HRNet 网络结构,它是在 HRNet 分割后的结果上计算每个像素与图像其他像素的一个关系权重,与原特征进行一个叠加构成 OCRNet 网络,再基于 OCRNet 进行分层多尺度训练形成最终的 MscaleOCRNet。
2.6 transformer系列
2.6.1 SegFormer
3 实例分割/全景分割模型

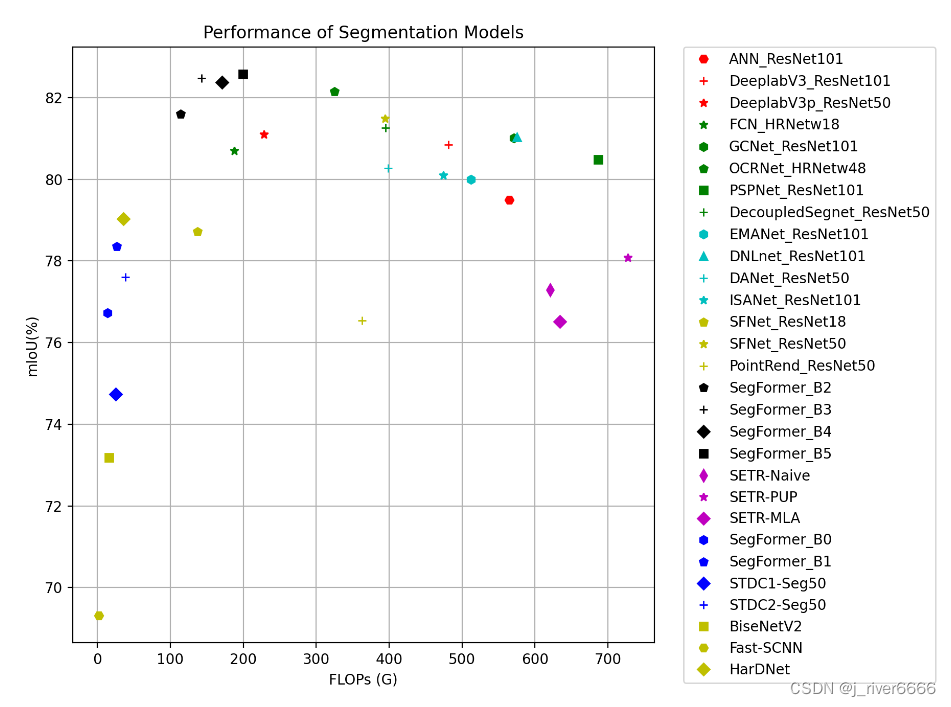
4 模型性能总览