用python实现编程实现文件合并和去重操作
1.查看python环境

2.编写mapper函数和reducer函数
在/usr/local/hadoop/wc文件夹下(如果没有文件夹就创建一个)
gedit mapper.py
mapper.py
#!/usr/bin/env python3
# encoding=utf-8
lines = {
}
import sys
for line in sys.stdin:
line = line.strip()
key, value = line.split()
if key not in lines.keys():
lines[key] = []
if value not in lines[key]:
lines[key].append(value)
lines[key] = sorted(lines[key])
for key, value in lines.items():
print(key, end = ' ')
for i in value:
print(i, end = ' ')
print()
gedit reducer.py
reducer.py
#!/usr/bin/env python3
# encoding=utf-8
import sys
key, values = None, []
for line in sys.stdin:
line = line.strip().split(' ')
if key == None:
key = line[0]
if line[0] != key:
key = line[0]
values = []
if line[1] not in values:
print('%s\t%s' % (line[0], line[1]))
values.append(line[1])
3.可运行权限设定与查看
chomod a+x ./mapper.py
chomod a+x ./mapper.py

4.在Hadoop上运行实现文件合并和去重操作
编写A.txt,B.txt
gedit A.txt
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x

gedit B.txt
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
在Hadoop上运行Python代码
如果hdfs命令有问题就添加下环境变量
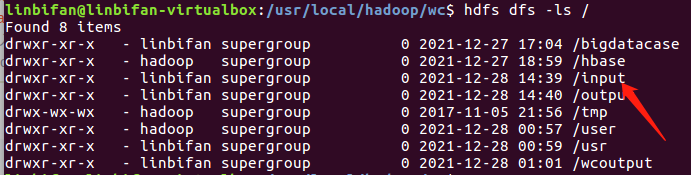
export PATH=$PATH:/usr/local/hadoop/bin

如果没有input文件夹则需要创建

export STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-*.jar
hadoop jar $STREAM \
-file /usr/local/hadoop/wc/mapper.py \
-mapper /usr/local/hadoop/wc/mapper.py \
-file /usr/local/hadoop/wc/reducer.py \
-reducer /usr/local/hadoop/wc/reducer.py \
-input /input/* \
-output /output