一、MongoDB Map Reduce
Map-Reduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。MongoDB提供的Map-Reduce非常灵活,对于大规模数据分析也相当实用。
基本语法:
db.collection.mapReduce( function() {emit(key,value);}, //map 函数 function(key,values) {return reduceFunction}, //reduce 函数 { out: collection, query: document, sort: document, limit: number } )
使用 MapReduce 要实现两个函数 Map 函数和 Reduce 函数,Map 函数调用 emit(key, value), 遍历 collection 中所有的记录, 将 key 与 value 传递给 Reduce 函数进行处理。
Map 函数必须调用 emit(key, value) 返回键值对。
参数说明:
- map :映射函数 (生成键值对序列,作为 reduce 函数参数)。
- reduce 统计函数,reduce函数的任务就是将key-values变成key-value,也就是把values数组变成一个单一的值value。。
- out 统计结果存放集合 (不指定则使用临时集合,在客户端断开后自动删除)。
- query 一个筛选条件,只有满足条件的文档才会调用map函数。(query。limit,sort可以随意组合)
- sort 和limit结合的sort排序参数(也是在发往map函数前给文档排序),可以优化分组机制
- limit 发往map函数的文档数量的上限(要是没有limit,单独使用sort的用处不大)
二、示例
我们通过下面的一个例子来理解上面的概念
mongodb的student集合中存在以下数据:
/* 1 */ { "_id" : ObjectId("5c735e26b21aeac107319873"), "stu_name" : "张三", "course" : "英语", "score" : 70, "level" : "C" } /* 2 */ { "_id" : ObjectId("5c735e26b21aeac107319874"), "stu_name" : "张三", "course" : "数学", "score" : 95, "level" : "A" } /* 3 */ { "_id" : ObjectId("5c735e26b21aeac107319875"), "stu_name" : "张三", "course" : "语文", "score" : 91, "level" : "A" } /* 4 */ { "_id" : ObjectId("5c735e26b21aeac107319876"), "stu_name" : "张三", "course" : "历史", "score" : 98, "level" : "A" } /* 5 */ { "_id" : ObjectId("5c735e26b21aeac107319877"), "stu_name" : "李四", "course" : "数学", "score" : 88, "level" : "B" } /* 6 */ { "_id" : ObjectId("5c735e26b21aeac107319878"), "stu_name" : "李四", "course" : "英语", "score" : 93, "level" : "A" } /* 7 */ { "_id" : ObjectId("5c735e26b21aeac107319879"), "stu_name" : "李四", "course" : "语文", "score" : 99, "level" : "A" }
要求:统计出每个学生的level为A的成绩的总和,并按学生名字进行分组显示
其执行的逻辑过程如下图所示:

在mongo shell里面执行:
db.student.mapReduce( function() { emit(this.stu_name,this.score); }, function(key, values) {return Array.sum(values)}, { query:{level:"A"}, out:"total_score" } )
/* 1 */ { "result" : "total_score", "timeMillis" : 171.0, "counts" : { "input" : 5, "emit" : 5, "reduce" : 2, "output" : 2 }, "ok" : 1.0 }
结果表明,共有 5 个符合查询条件("level":"A")的student, 在map函数中生成了 5 个键值对文档,最后使用reduce函数将相同的键值分为 2 组。
具体参数说明:
- result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。
- timeMillis:执行花费的时间,毫秒为单位
- input:满足条件被发送到map函数的文档个数
- emit:在map函数中emit被调用的次数,也就是所有集合中的数据总量
- ouput:结果集合中的文档个数(count对调试非常有帮助)
- ok:是否成功,成功为1
- err:如果失败,这里可以有失败原因,不过从经验上来看,原因比较模糊,作用不大
查看真正的统计结果:
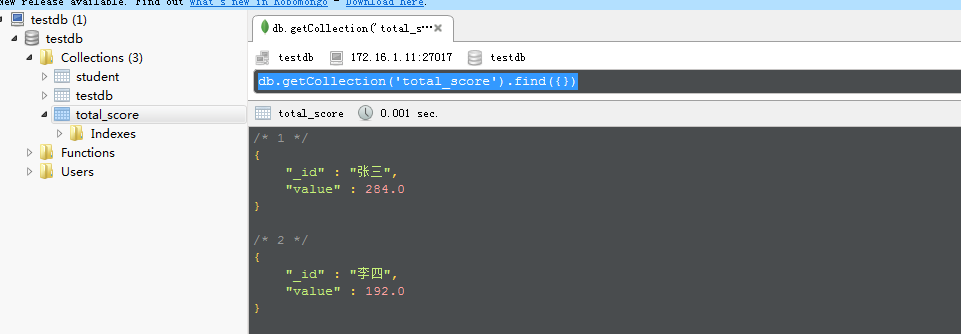
三、用spring-data-mongodb来实现上面的操作
1、新建