1.写在前面
原文来自知网《基于视觉-文本关系对齐的跨模态视频片段检索》
这是一篇关于利用文本进行视频片段检索的论文。
2.论文要点
论文总结了前人研究工作的缺点,并借助图结构在表达关系时的强大能力与图卷积网络的近年发展,,提出了跨模态关系对齐的图卷积框架 CrossGraphAlign,
具体就是CrossGraphAlign首先为查询文本和待检索视频分别生成文本关系图和视觉关系图。接着CrossGraphAlign中的视觉-文本关系对齐的图卷积网络试图匹配一段时间内的文本关系图和视觉关系图。最后基于匹配结果,CrossGraphAlign将预测查询文本在视频中的起时和结束时间。
即通过分别构建文本关系图,视觉关系图来建模查询文本与视频片段中的语义关系。,再通过跨模态对齐图卷积网络来评估文本关系与视觉关系的相似度。
2.1 文本关系图模块
输入查询文本,输出以实体特征为节点,文本关系特征为边的图。 G L = ( O L , E L ) , 其 中 O L = { o 1 L , o 2 L . . . o n L } G^L = (O^L, E^L),其中O^L=\{o^L_1,o^L_2...o^L_n\} GL=(OL,EL),其中OL={
o1L,o2L...onL},表示文本中的实体的特征集合。
首先将文本解析为依存树,而后使用场景图解析提取文本关系,最后使用词向量方法GloVe来特征化场景图,从而构建出文本关系图。如下:

2.2 视频关系图模块
输入目标检测结果,构建以视觉物体特征为节点,视觉关系为边的图。它的图构建与文本类似,其特征提取主要包括视觉物体特征提取和视觉关系特征提取
-
视觉物体特征提取:基于 Faster R-CNN 进行视觉物体的特征提取;
RoIPooling 层 在特征图 (即, 图 中的 backbone feature) 上提取每一区域的特征, 作为实例特征 (instance feature). 同时, 我们还将目标识别出的类别经过 GloVe 方法表征为向量, 作为标签特征 (label feature), 与实例特征拼接 (concat) 后一起作为视觉物体特征. 为了进一步表示物体的位置信息, 我们将物体的归一化的坐标作为**位置特征 (location feature),**与上述特征一起拼接, 形成视觉物体特征. 提取后的视觉物体特征将作为视觉关系图的节点特征; -
视觉关系特征提取:我们基于在场景图生成任务中常用的 Union Box 概念进行视觉物体间关系的提取;
给定两个目标的边界框 (x1, y1,w1, h1) 与 (x2, y2, w2, h2), Union Box 用于表示两个物体边界框的最小外接框 (min (x1, x2), min (y1, y2), max (w1, w2), max (h1, h2)). 在获得 Union Box 后,我们仿照视觉物体特征提取的方式, 利用 RoI Pooling 提取关系特征为视觉关系的边特征 E V E^V EV,这里的关系并没有被显示表达,可以在学习中学习合适的表达。
2.3 关系对齐模块
根据文本关系与视觉关系图进行双方的匹配,输出符合查询文本描述的片段。
首先改造图卷积网络 ,以期对关系图进行自身信息的更新; 而后对视觉关系图与文本关系图进行特征表示, 用于计算匹配度分数. 具体而言, 我们提出以关系为中心的更新 (relationshipcentric update) 机制和关系图特征嵌入

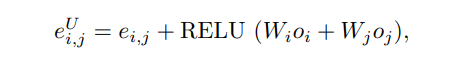
3.实验数据集
本文提出的方法在TACoS和ActivityNet Caption上进行了实验,实验结果表明:在基线模型中加入CrossGraphAlign后,模型在各个交叠比下的召回率得到了明显的提升。效果最佳。

