1、背景
06年,Google发布了《BigTable: A Distributed StorageSystem for Structured Data》,由PowerSet实现并开源,HBase是一种分布式、可扩展的大数据存储结构,如果在HBase中存放了时序数据,常常需要访问最近的若干数据LastN。本文基于上述背景进行LastN的优化实现。
2、方案设计
hbase版本基于公司hbase组件1.0.19-kwai,假设Rowkey为:分钟级时间戳,由于hbase根据rowkey的字典序从小到大存储,因此,显而易见可以使用,设置startRowkey、stopRowkey,同时设置reverse函数。
3、scan and reversed scan
3.1、scan
用户可以通过hbase client的scan操作完成多样的查询,常见的有startRow、endRow、Filter、caching、batch、reversed等,其中scan操作涉及到reverse的几种场景。cloudera官方文档,有对几种场景的详细说明https://docs.cloudera.com/documentation/enterprise/6/6.3/topics/admin_hbase_scanning.html
下边从图文的角度
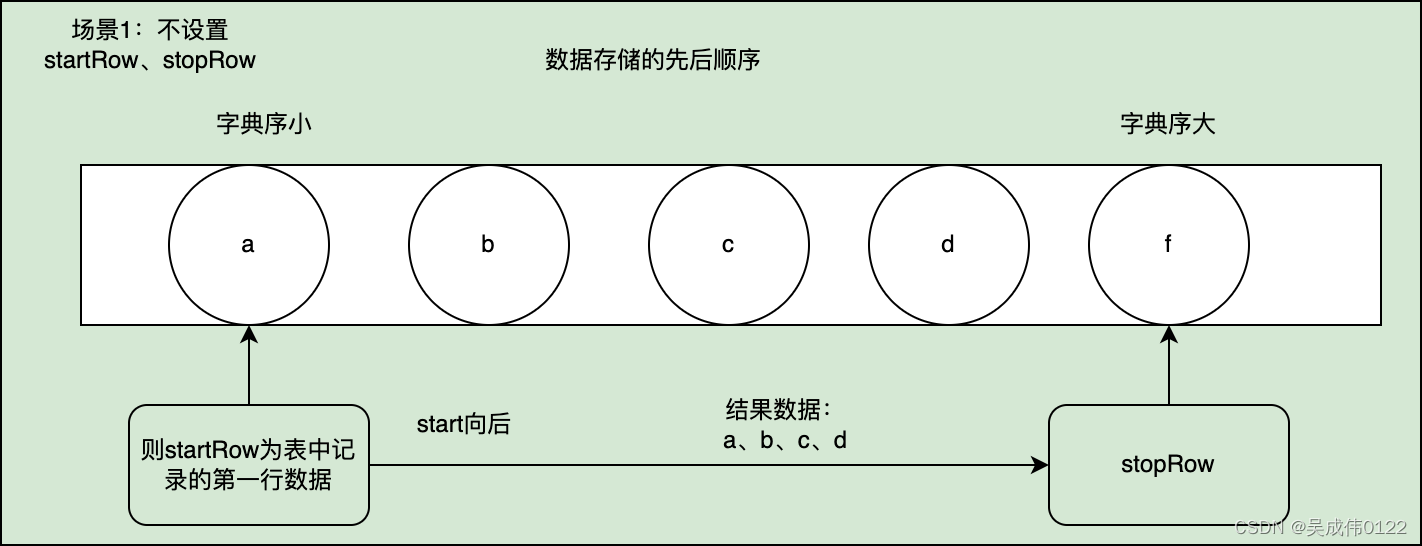
正确scan场景:不设置startRow、stopRow
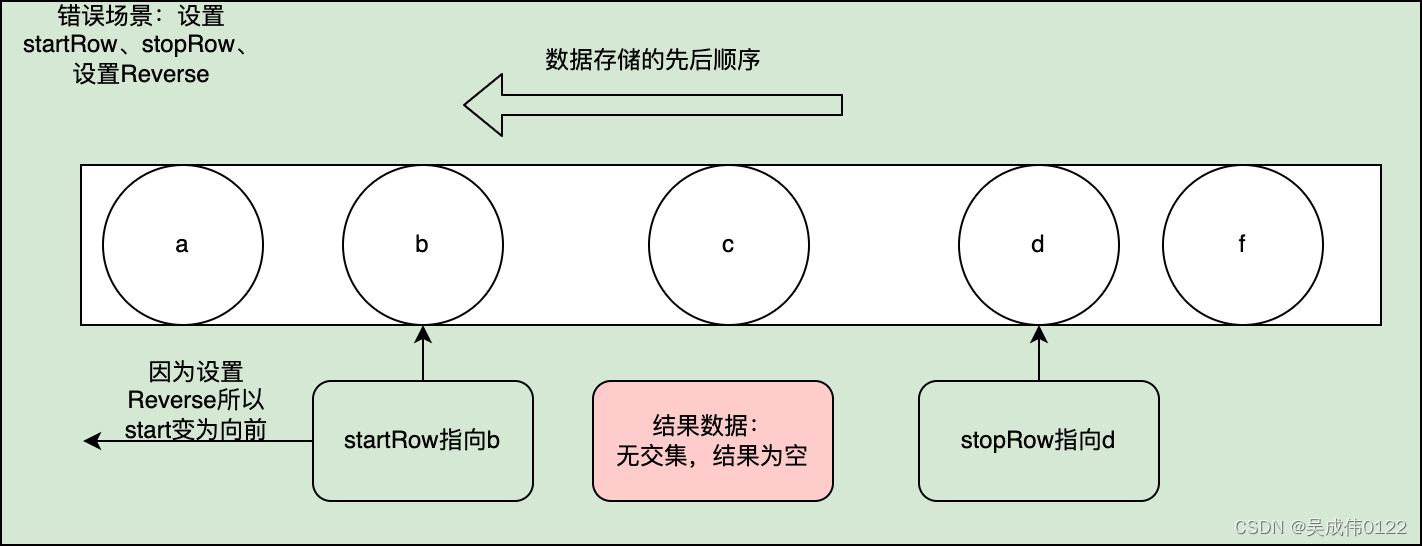
错误场景:设置startRow、stopRow,设置Reverse,但未正确使用
3.2、reversed scan
设置startRow、stopRow,正确使用Reversed
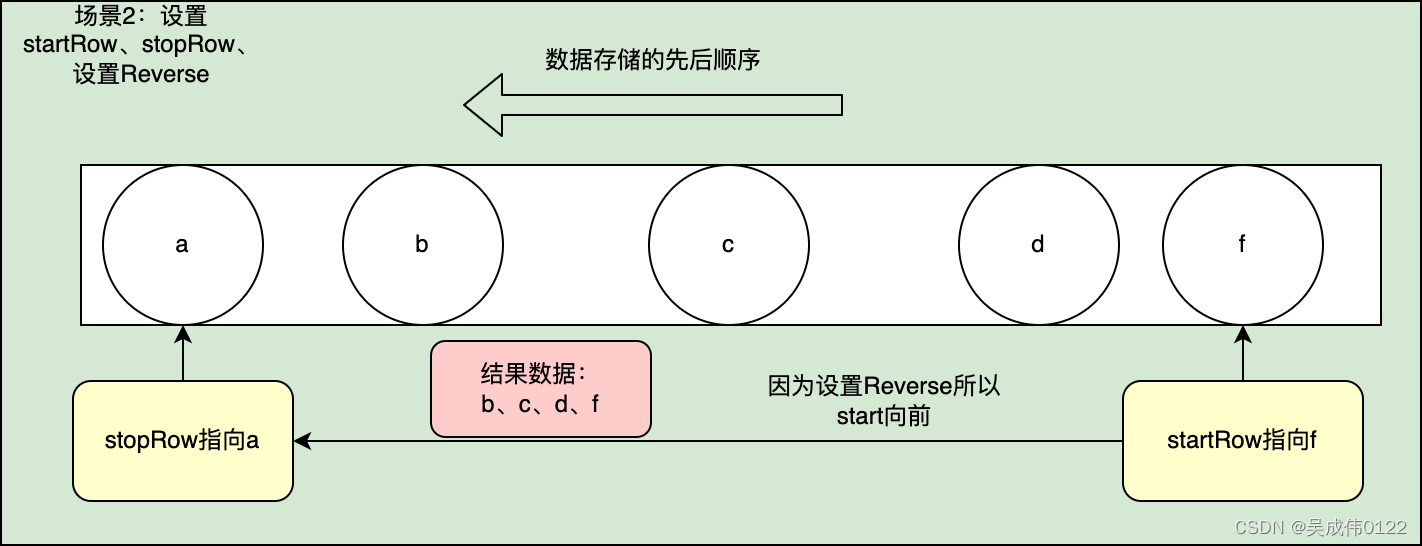
同时通过源码阅读,分析scan.next()–>scan.nextRow—>nextInternal()–>isStopRow(),从startRow不断去找stopRow,因此设置reversed就是比较器的方向改变,从startRow另一个方向迭代。
3.3、reversed效率测试
| 数据样本 | 时间段 | 正序(ms) | 逆序(ms) |
|---|---|---|---|
| 样本数据1 | 1000个点 | 152 | 152 |
| 样本数据2 | 30720个点 | 1492 | 1964 |
| 样本数据3 | 30720个点 | 1589 | 2080 |
| 通过较大数据量的reverse查询,发现逆序比正序的效率低。 |
官方对于reverse性能相比顺序读下降的issue https://issues.apache.org/jira/browse/HBASE-4811?jql=text%20~%20%22reverse%22
那么为什么reverse的性能会慢于顺序读呢?下面开始分析。
4、HBase的数据存储结构
根据hbase的数据模型可知,hbase是列式存储,按照列簇将数据分别存储,HBase的一列列簇(Column Family)本质是一棵LSM树,该LSM树分为内存部分和磁盘部分,内存部分HBase使用SkipList跳表,磁盘部分使用独立文件块组成。
4.1、LSM
定义:
- LSM树是一个横跨内存和磁盘的,包含多颗"子树"的一个森林。
- LSM树分为Level 0,Level 1,Level 2 … Level n 多颗子树,其中只有Level 0在内存中,其余Level 1->n在磁盘中。
- 内存中的Level 0子树一般采用排序树(红黑树/AVL树)、跳表或者TreeMap等这类有序的数据结构,方便后续顺序写磁盘。
- 磁盘中的Level 1->n子树,本质是数据排好序后顺序写到磁盘上的文件,只是叫做树而已。
- 每一层的子树都有一个阈值大小,达到阈值后会进行合并,合并结果写入下一层。
- 只有内存中数据允许原地更新,磁盘上数据的变更只允许追加写,不做原地更新。
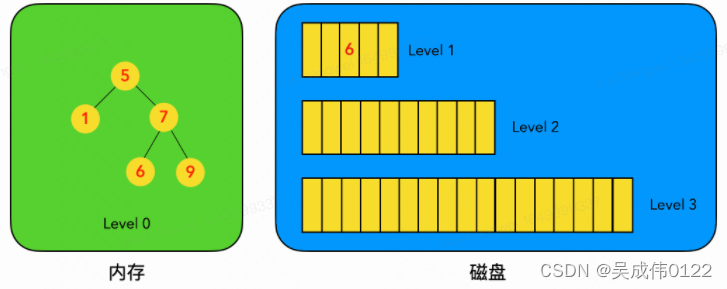
即HBase中的一个CF对应一个StoreScanner,一个storeScanner由MemStoreScanner和StoreFileScanner构成,分别对应对内存与磁盘的检索,具体而言,内存部分使用skipList数据结构,ConcurrentSkipListMap实现,磁盘部分数据位于HFile内。
5、HBase的写数据流程与数据编码
5.1、客户端处理阶段
客户端将用户的写入请求进行预处理,并根据集群元数据定位写入数据所在的RegionServer,将请求发送给对应的RegionServer
5.2、Region写入阶段
RegionServer接收到写入请求之后将数据解析出来,首先写入WAL,再写入对应Region列簇的MemStore
5.3、MemStore Flush阶段
当Region中MemStore容量超过一定阈值,系统会异步执行flush操作,将内存中的数据写入文件,形成HFile。
HBase执行flush操作之后将内存中的数据按照特定格式写成HFile文件。
基本流程为:
MemStore(CellSkipListSet)—>Scanner.next–cell(keyValue)->appendGeneralBloomFilter(cell)—>appendDeleteFamilyBloomFilter(cell)—>(HFile.Writer)writer.append(cell)
首先新建Scanner,从CellSkipListSet取cell(keyValue),在内存中使用BloomFilter以及标记为DeleteFamil、DeleteFamilVersion的cell,将cell写入DataBlock中。
一个cell在内存中写入DataBlock这个过程中,需要注意的是这个过程分为两步:
1、Encoding KeyValue :使用特定的编码对cell进行编码处理。
HBase中主要的编码器有DiffKeyDeltaEncoder、FastDiffDeltaEncoder以及PrefixKeyDeltaEncoder等。编码的基本思路是,根据上一个KeyValue和当前KeyValue比较之后取delta,展开讲就是rowkey、column family以及column分别进行比较然后取delta。假如前后两个KeyValue的rowkey相同,当前rowkey就可以使用特定的一个flag标记,不需要再完整地存储整个rowkey。这样,在某些场景下可以极大地减少存储空间。
2、将编码后的KeyValue写入DataOutputStream
随着cell的不断写入,当前Data Block会因为大小超过阈值(默认64KB)而写满。写满后Data Block会将DataOutputStream的数据flush到文件,该Data Block此时完成落盘。
编码处理之后,可以极大减少存储空间,注意这里已经没有完成的rowkey信息(下文会举例说明)。实际上对于海量数据而言,IO资源优化重要性不言而喻,除了设计异步的compaction来降低文件个数,达到提高读取性能的目的。同样在读写流程中做了压缩、编码等优化。
6、HBase的读数据流程与数据解码
和写流程相比,HBase读数据的流程更加复杂。主要基于两个方面的原因:
一是因为HBase一次范围查询可能会涉及多个Region、多块缓存甚至多个数据存储文件;
二是因为HBase中更新操作以及删除操作的实现都很简单,
- 更新操作并没有更新原有数据,而是使用时间戳属性实现了多版本;
- 删除操作也并没有真正删除原有数据,只是插入了一条标记为"deleted"标签的数据,而真正的数据删除发生在系统异步执行Major Compact的时候。
很显然,这种实现思路大大简化了数据更新、删除流程,但是对于数据读取来说却意味着需要去除这些干扰:读取过程需要根据版本进行过滤,对已经标记删除的数据也要进行过滤。
6.1、hbaseClient-hbaseServer
1.client访问zk,获取hbase:meta表所在的RegionServer节点信息
2.根据rokwey向RegionServer发送读请求,同时将元数据缓存到内存,由RegionServer来进行数据处理。
3.get、scan,实现都是scan(get是特殊的scan)
scan操作没有设计成1次RPC请求,因为可能全表扫描,带来两个后果
- 大量数据传输会导致集群网络带宽等系统资源短时间被大量占用,严重影响集群中其他业务。
- 客户端很可能因为内存无法缓存这些数据而导致客户端OOM
故,一次scan会被拆分为多个RPC请求,每个RPC请求被称为一次next请求,每次只返回规定数量的结果。
一次next()操作,客户端先从本地缓存中检查是否有数据,如果有数据就直接返回,如果没有就发起一次RPC请求到服务器端获取,成功之后缓存到内存中。
单次RPC的请求数由参数caching设定,默认为Integer.MAX_VALUE,没有太大,容易OOM,太小,多次RPC操作,网络成本高。
为防止返回一行数据,但数据量很大的情况,客户端可以通过setBatch来设置一次RPC请求数据的列数量。
setMaxResultSize设置每次RPC请求返回数据量大小(不是条数),默认2G。
6.2、Server端Scan框架体系
一次scan可能会跨region。
对于这种扫描,客户端会根据hbase:meta元数据将扫描的起始区间[startKey, stopKey)进行切分,切分成多个互相独立的查询子区间,每个子区间对应一个Region。比如当前表有3个Region,Region的起始区间分别为:[“a”, “c”),[“c”, “e”),[“e”, “g”),客户端设置scan的扫描区间为[“b”, “f”)。因为扫描区间明显跨越了多个Region,需要进行切分,按照Region区间切分后的子区间为[“b”, “c”),[“c”, “e”),[“e”, “f”)。
RegionServer接收到客户端的get/scan请求之后做了两件事情:首先构建scanneriterator体系;然后执行next函数获取KeyValue,并对其进行条件过滤。
6.2.1、 构建Scanner Iterator体系
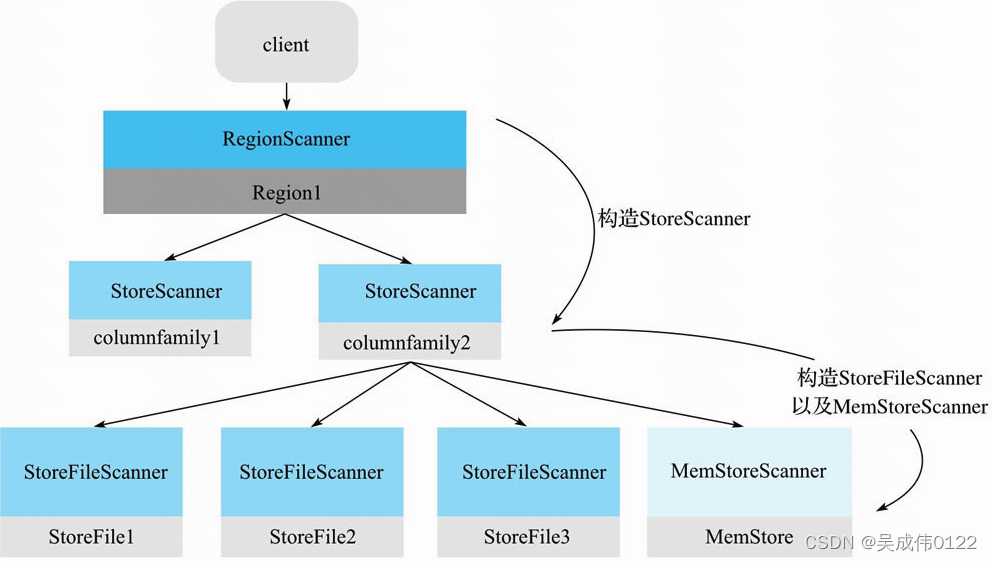
Scanner的核心体系包括三层Scanner:RegionScanner,StoreScanner,MemStoreScanner和StoreFileScanner。三者是层级的关系:
- 一个RegionScanner由多个StoreScanner构成。一张表由多少个列簇组成,就有多少个StoreScanner,每个StoreScanner负责对应Store的数据查找。
- 一个StoreScanner由MemStoreScanner和StoreFileScanner构成。每个Store的数据由内存中的MemStore和磁盘上的StoreFile文件组成。相对应的,StoreScanner会为当前该Store中每个HFile构造一个StoreFileScanner,用于实际执行对应文件的检索。同时,会为对应MemStore构造一个MemStoreScanner,用于执行该Store中MemStore的数据检索。
需要注意的是,RegionScanner以及StoreScanner并不负责实际查找操作,它们更多地承担组织调度任务,负责KeyValue最终查找操作的是StoreFileScanner和MemStoreScanner。
这里补充下Hbase的一个列族本质上是一棵LSM树,上文已介绍,此处不再赘述。
构造好三层Scanner体系之后,还需要如下图过程。
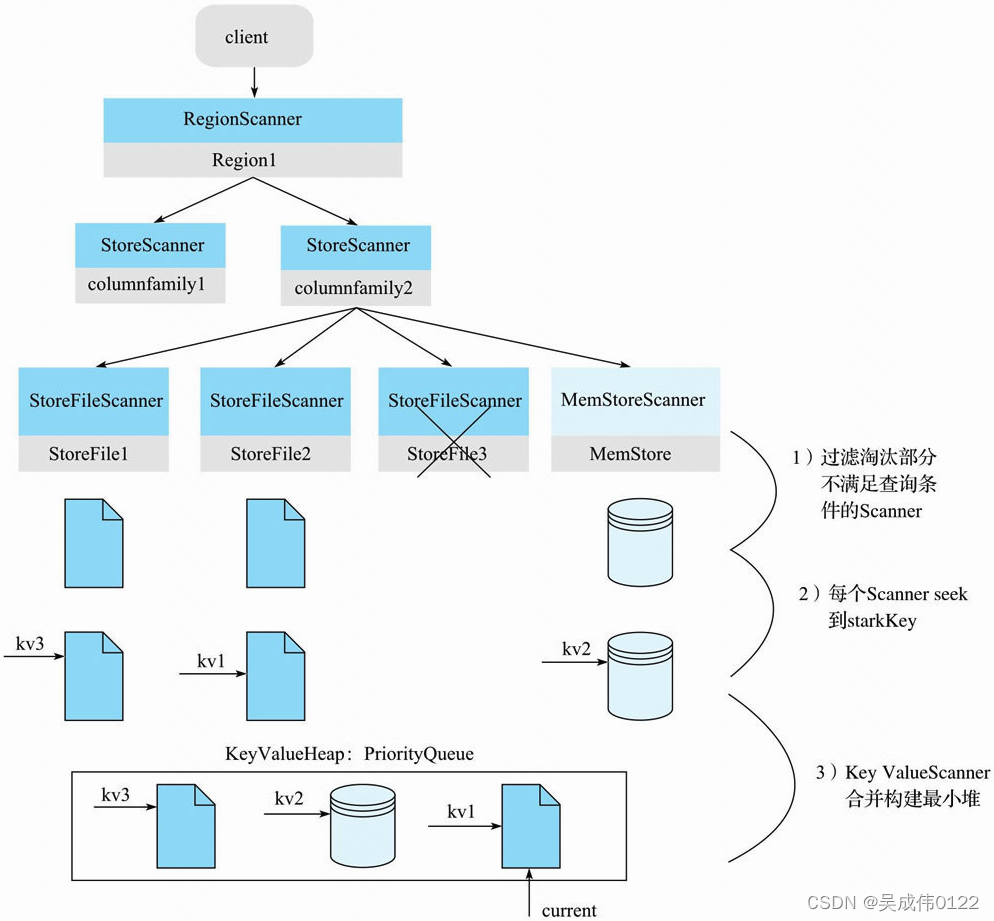
1)过滤淘汰部分不满足查询条件的Scanner
2)每个Scanner seek 到starkKey
这个步骤在每个HFile文件中(或MemStore)中seek扫描起始点startKey。如果HFile中没有找到starkKey,则seek下一个KeyValue地址
3)KeyValueScanner合并构建最小堆。将该Store中的所有StoreFileScanner和MemStoreScanner合并形成一个heap(最小堆),所谓heap实际上是一个优先级队列。在队列中,按照Scanner排序规则将Scanner seek得到的KeyValue由小到大进行排序。最小堆管理Scanner可以保证取出来的KeyValue都是最小的,这样依次不断地pop就可以由小到大获取目标KeyValue集合,保证有序性。
6.2.2、根据HFile索引树定位目标Block
由上述可知,数据会被保存到memStore和Hfile,实际上对于hbase对于海量数据而言,大部分数据都被保存在磁盘中,因此这里主要考虑磁盘上数据的查找。
HRegionServer打开HFile时会将所有HFile的Trailer部分和Load-on-open部分加载到内存,Load-on-open部分有个非常重要的Block——Root Index Block,即索引树的根节点。
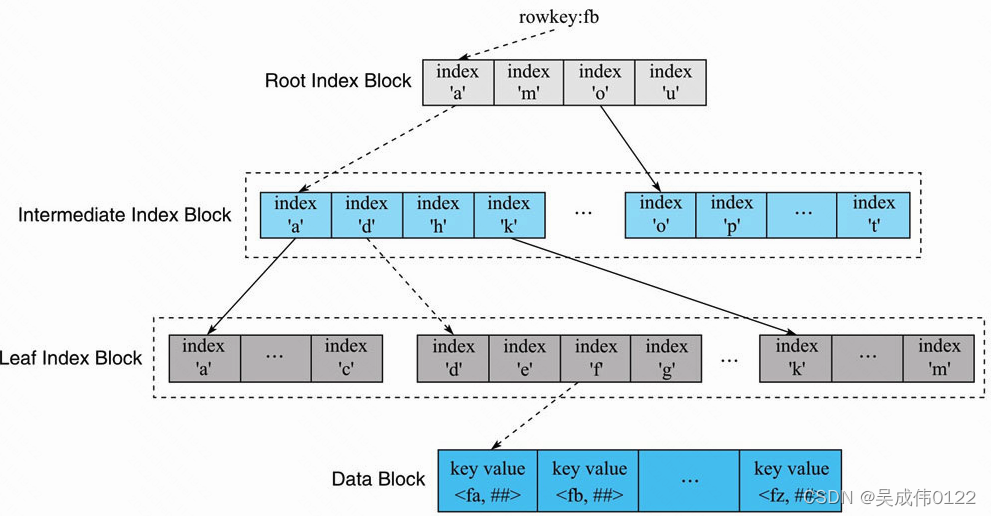
上面三行中每一个方框表示一个IndexEntry,由BlockKey、Block Offset、BlockDataSize三个字段组成,BlockKey是整个Block的第一个rowkey,如Root Index Block中"a", “m”, “o”,"u"都为BlockKey。Block Offset表示该索引节点指向的Block在HFile的偏移量。HFile索引树索引在数据量不大的时候只有最上面一层,随着数据量增大开始分裂为多层,最多三层。
1)用户输入rowkey为’fb’,在Root Index Block中通过二分查找定位到’fb’在’a’和’m’之间,因此需要访问索引’a’指向的中间节点。因为Root IndexBlock常驻内存,所以这个过程很快。
2)将索引’a’指向的中间节点索引块加载到内存,然后通过二分查找定位到fb在index 'd’和’h’之间,接下来访问索引’d’指向的叶子节点。
3)同理,将索引’d’指向的中间节点索引块加载到内存,通过二分查找定位找到fb在index 'f’和’g’之间,最后需要访问索引’f’指向的Data Block节点。4)将索引’f’指向的Data Block加载到内存,通过遍历的方式找到对应KeyValue。
上述流程中,Intermediate Index Block、Leaf Index Block以及Data Block都需要加载到内存,所以一次查询的IO正常为3次。但是实际上HBase为Block提供了缓存机制,可以将频繁使用的Block缓存在内存中,以便进一步加快实际读取过程。
通过6.2.2可知,HFile索引树定位目标Block的方式,以及5.3章节可知,Flush到磁盘上时会首先进行编码操作,然后选择压缩算法,进行数据压缩;同样,从磁盘中读数据时,首先就需要解压缩、解码。由写过程编码后可知rowkey信息未被完整保留,而是为了节约存储成本,底层实际采用的是delta方式的存储。即如果两个key拥有公共前缀,则两个key的实际形态是公共前缀+后面一个不同的字符进行存储,并非存储完整的两个key,所以 在reverse逆序读的时候不仅仅需要读当前key,还需要找到前面第比他小的key来进行key的delta补全。
下面以官方文档中Prefix_Encoding为例说明,左图为未使用编码格式,右图为Prefix_Encoding。
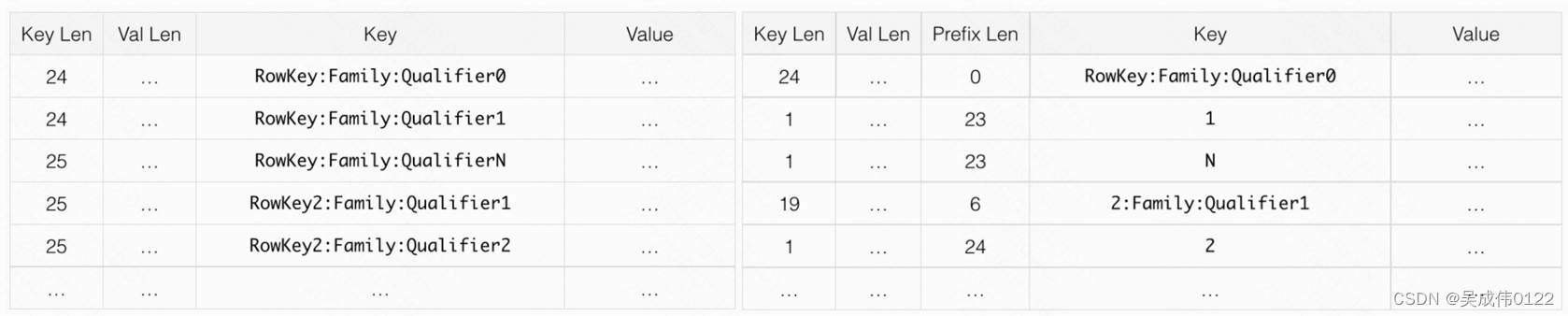
由上图可知,HFile定位到Bolck时,reverse逆序读需要根据Prefix Leny以及Key Len不断向上迭代,直至补全本身的rowkey信息,相比于顺序读会有更多的迭代过程,由于当数据量巨大时,差异会更加明显。
7、结论
-
HBAS通过region/store/LSM/block的多层方式存储数据,每一级存储都有相应的索引,所以从宏观上来说,索引结构对正向扫描和反向扫描的支持是一样的。
-
为了节省存储空间,HBASE对数据进行了编码,对反向扫描不友好。
-
如果要追求最佳的性能,推荐用lomg.max - timestamp的方式,来实现顺序扫描。
参考文章
https://www.cs.umb.edu/~poneil/lsmtree.pdf
https://hbase.apache.org/1.4/book.html#data.block.encoding.enable
https://klevas.mif.vu.lt/~ragaisis/ADS2006/skiplists.pdf
https://issues.apache.org/jira/browse/HBASE-4811?jql=text%20~%20%22reverse%22