1、数据准备
对于训练,需要两个数据集:一个用于train,一个用于validation(边训练边测试,用于检测模型变化)。
具体过程参考博文caffe学习系列:训练自己的图片集(超详细教程),简要步骤如下:
(1)准备好训练和测试样本。
可以先准备好一个一样的数据集,然后从中每一类抽取一定的比例作为测试样本。如取5个类别的图片,每一类100张,共500张。每一类随机抽取20张作为测试,于是训练集为80*5=400张,测试集为20*5=100张。把训练集和测试集的图片分别放在一个单独的文件夹中,如trian_img和test_img。
(2)生成lmdb文件。
首先,新建两个txt文件train.txt和test.txt,列出train_img和test_img的文件名和对应的label(如分类数为5,则取label为0,1,2,3,4,不要取别的,否则会影响训练的精度)。可以参考上述博文的shell脚本:
#!/usr/bin/env sh
DATA=data/re/
MY=examples/myfile
echo "Create train.txt..."
rm -rf $MY/train.txt
for i in 3 4 5 6 7
do
find $DATA/train -name $i*.jpg | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MY/train.txt
done
echo "Create test.txt..."
rm -rf $MY/test.txt
for i in 3 4 5 6 7
do
find $DATA/test -name $i*.jpg | cut -d '/' -f4-5 | sed "s/$/ $i/">>$MY/test.txt
done
echo "All done" 其中,可以把第8行的
sed "s/$/ $i/"
换成
sed "s/$/ $((i-3))/"
就可以直接生成label为0-4的txt,而不用像博客里的再手动更改。
其次,也可以用python代码来执行这个过程,甚至可以手动编写,只要能生成这两个txt文件就可以了,生成后的格式如下:
train/348.jpg 0 train/360.jpg 0 train/374.jpg 0 ... ...
test/303.jpg 0 test/317.jpg 0 test/316.jpg 0 ... ...
然后,调用caffe自带的convert_imageset工具来生成lmdb文件。可以参考博文里的shell脚本:
#!/usr/bin/env sh
MY=examples/myfile
echo "Create train lmdb.."
rm -rf $MY/img_train_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_height=256 \
--resize_width=256 \
/home/xxx/caffe/data/re/ \
$MY/train.txt \
$MY/img_train_lmdb
echo "Create test lmdb.."
rm -rf $MY/img_test_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_width=256 \
--resize_height=256 \
/home/xxx/caffe/data/re/ \
$MY/test.txt \
$MY/img_test_lmdb
echo "All Done.."
实际上,这一段脚本执行的核心内容是调用了下面的命令。(同样的,也可以使用python来做这个步骤,或者直接手动在终端执行这些命令行)
build/tools/convert_imageset \
--shuffle \
--resize_height=256 \
--resize_width=256 \
/home/xxx/caffe/data/re/ \
$MY/train.txt \
$MY/img_train_lmdb
其中的参数主要有:
shuffle:乱序;
resize_height、resize_width:把图片变换到需要的大小;
图片源文件所在的目录;
上一步生成的txt描述文件的路径;
目标lmdb的路径。
执行完上述脚本后,会在指定的目录下生成两个文件夹:img_train_lmdb和img_test_lmdb,里面就是进行训练和测试所需的lmdb文件。
2、计算均值,生成均值文件
之所以要计算均值,是为了在后面进行训练和测试的输入时,先把数据减去这个均值,即把数据进行中心化,使数据分布在原点附近,从而加快训练的速度和精度。
caffe自带了计算均值的工具compute_image_mean,使用方法为:
build/tools/compute_image_mean examples/myfile/img_train_lmdb examples/myfile/mean.binaryproto
其中,我们只计算train数据集的均值,在validation中也是直接使用这个值,因为train和validation是同源的图片,它们的均值是很接近的。
3、创建模型,并编辑配置文件
一个caffe模型主要有以下几个配置文件:
solver.prototxt:指定模型的训练参数
train_val.prototxt:指定train和validation的具体网络结构
deploy.prototxt:指定模型使用时的网络结构(这个结构和train_val的结构基本相似,只是train_val输入的是一个个批次的训练数据,输出的是accuracy和loss,而deploy输入的一般是单个图片,输出的类别编号和概率,里面的网络结构是一样的)
其中,solver.prototxt的内容如下:
net: "examples/my_file/train_val.prototxt" test_iter: 2 #2 iteration every test test_interval: 50 #Test every 50 iteration(batch) base_lr: 0.001 lr_policy: "step" gamma: 0.1 stepsize: 100 display: 50 max_iter: 200 momentum: 0.9 weight_decay: 0.005 solver_mode: CPU snapshot: 50 snapshot_prefix: "examples/my_file/minemodel"
具体参数意义如下:
net:指定train_val.prototxt的路径
test_iter:每次validation时,执行测试的iteration数(一个iteration就是输入一个batch的数据,进行一次迭代),一般一次测试要覆盖一次测试集的大小,即根据训练集大小和batchsize(在train_val.prototxt中设置)来确定
test_interval:validation的间隔,如该数值为50就是说每训练50个iteration就进行一次test
base_lr:基本学习率,与后面的lr_policy配合使用
lr_policy:学习率的下降策略,可用的策略和学习率的计算方式如下
- fixed: 保持base_lr不变. - step: 如果设置为step,则还需要设置一个stepsize, 返回 base_lr * gamma ^ (floor(iter / stepsize)),其中iter表示当前的迭代次数 - exp: 返回base_lr * gamma ^ iter, iter为当前迭代次数 - inv: 如果设置为inv,还需要设置一个power, 返回base_lr * (1 + gamma * iter) ^ (- power) - multistep: 如果设置为multistep,则还需要设置一个stepvalue。这个参数和step很相似,step是均匀等间隔变化,而multistep则是根据 stepvalue值变化 - poly: 学习率进行多项式误差, 返回 base_lr (1 - iter/max_iter) ^ (power) - sigmoid: 学习率进行sigmod衰减,返回 base_lr ( 1/(1 + exp(-gamma * (iter - stepsize))))
还有人做了学习率的变化图,膜拜一下:
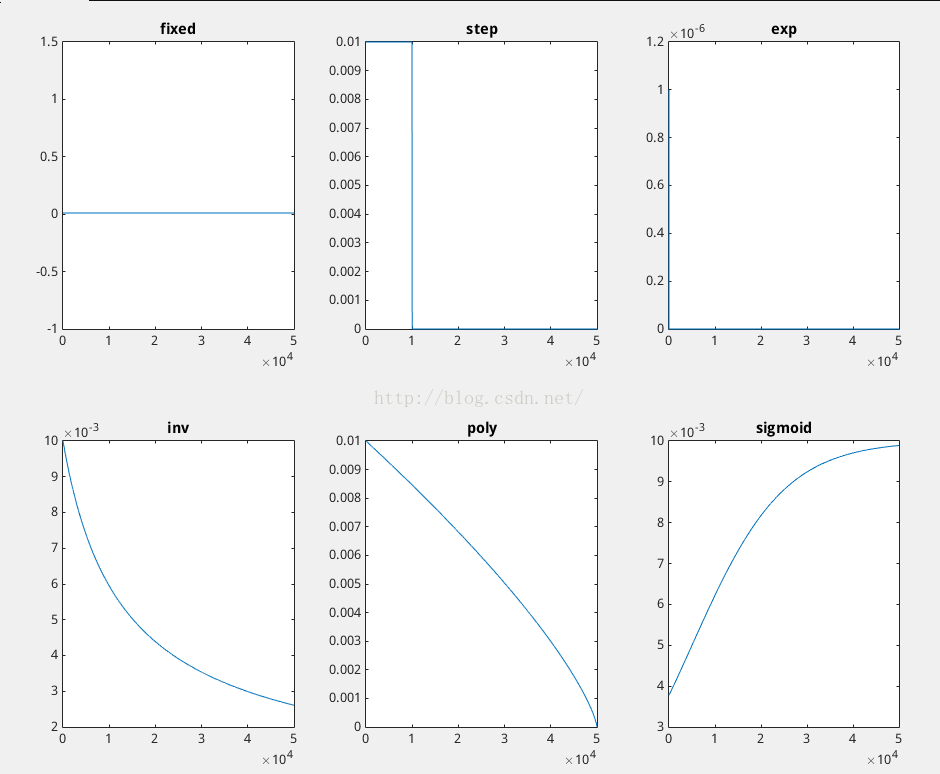
gamma、stepsize:学习率下降策略的参数,不同的策略可能参数不太一样
display:每隔多少次iteration输出一次执行结果
max_iter:训练的迭代次数,实测可以随时按control+c终止训练,并不会崩溃,而且还会把最后一次训练的结果保存到指定目录。一般需要对训练集进行100个epoch左右,如有10000张训练图片,batchsize为100(即一次iteration就会使用100张图片),那么iteration的次数应该为:100*n/batchsize = 100 * 10000 / 100 = 10000(n为训练集大小)
momentum:动量,类似于物理的动量,使参数不会剧烈变化。如一般的SGD更新参数的方式为x = x - α * dx,而带momentum的更新方式为v = β * v − α * dx,x = x + v
weight_decay:参数衰减比例,防止过拟合
solve_mode:训练的模式,CPU或GPU(没有GPU训练速度比TensorFlow慢)
snapshot:存储训练快照的频率,如该参数为50,表示每隔50次iteration会自动存储一次模型快照
snapshot_prefix:模型快照的存储路径
train_val.prototxt的内容如下:
name: "CaffeNet"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "examples/my_file/mean.binaryproto"
}
data_param {
source: "examples/my_file/img_train_lmdb"
batch_size: 50
backend: LMDB
}
}
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "examples/my_file/mean.binaryproto"
}
data_param {
source: "examples/my_file/img_test_lmdb"
batch_size: 50
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
...
...
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 5
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "fc8"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "fc8"
bottom: "label"
top: "loss"
}
其中,网络的第一个layer是data,即数据输入层,配置文件指定了两个data层,一个用于train,一个用于validation的test,分别用include { phase: TRAIN }和include { phase: TEST }来区分。
cov1后面的就是具体的网络层,常用的层有:
Convolution:卷积层
Pooling:池化层
LRN:局部归一化
ReLU:激活函数
InnerProduct:全连接层
Dropout:随机丢弃
最后的是InnerProduct全连接层,Accuracy层、SoftmaxWithLoss层,分别输出分类编号、准确率、损失值。其中,最后一个InnerProduct的num_output应该设置为实际类别的数量,如图片分为5类,则该值为5
其他的参数意义如下:
transform_param:对数据做预处理的相关参数
data_param:数据源的相关参数
mirror:是否做镜像,如果为true,会对输入的图像随机进行左右对称变换
crop_size:剪切成指定大小
mean_file:指定均值文件的路径,就是上面第2步生成的文件路径
source:数据源的路径,就是第1步生成的lmdb文件夹的路径
batch_size:一个batch的大小。一次iteration实际上是对一个batch的数据进行处理,并根据它们的平均结果来更新参数
backend:数据源的格式
param:本层的参数变化,如果一层有两个param,则第一个指定weight,第二个指定bias
weight_filler:该层的weight参数初始化方法,(据说gaussian配合softmax使用,xavier配合relu使用,未验证)
bias_filler:该层的bias参数初始化方法
lr_mult:用lr_base乘以lr_mult作为该层的参数学习率下降比例
decay_mult:用weith_dacay乘以decay_mult作为该层的weight_decay
4、进行训练
准备好数据,编辑好配置文件,就可以开始训练了,命令如下
build/tools/caffe train -solver examples/myfile/solver.prototxt
训练过程会根据指定的参数,每隔一定的iteration就会输出训练和测试的结果,并把快照存储到指定的目录
至此,训练步骤完成。