损失函数
一、 什么是损失函数
任何模型训练的第一步是明确损失函数。模型训练过程无非就是在优化损失函数,从而找到让损失函数最小的模型的参数
损失函数是衡量网络输出合真实值的差异
损失函数并不使用测试数据来衡量网络的性能
损失函数用来指导训练过程,使得网络的参数向损失降低的方向改变
假设我们的神经网络用作分类,损失函数定义为交叉熵损失函数,当神经网络的输出层做了softmax,输出当前的输入,对应各个类别的概率,选取概率最高的类别,最后再通过交叉熵损失函数来检测当前神经网络输出的类别与真实标签的类别是否一致,从而反向调整网络
二、 绝对误差函数(Absolute value、L1-norm)
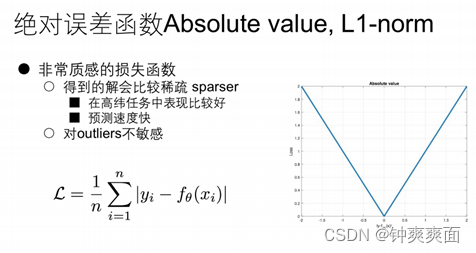
该函数进行求导,求出的梯度都是恒定的,
即当我们的误差很大时,求出来的梯度也都是恒定的,所以对outliers不敏感
三、 方差函数(Square error,Euclidean loss, L2-norm)
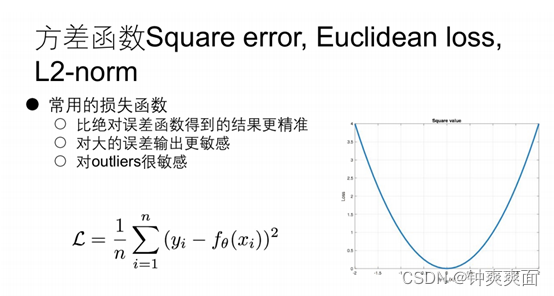
当我们的误差很大时,求出来的梯度也会变大的,所以对outliers敏感
四、 交叉熵Corss-entropy-loss
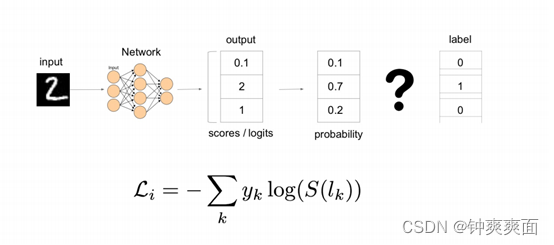
S是softmax函数
K为类别的数量
L为label独热编码标签
将softmax输出的所有概率与对应的独热编码标签进行相乘,最终计算的出损失函数的值,(只有真实标签与相对应的概率进行计算)

求导计算:

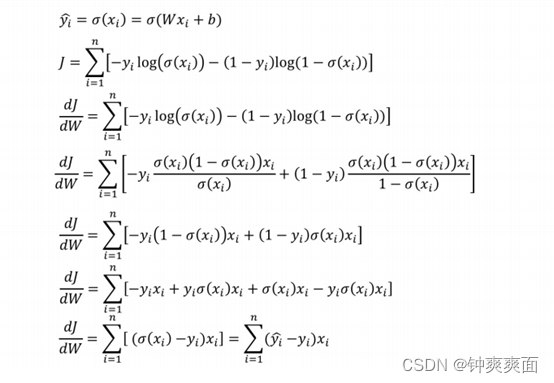
五、 Multi-label分类
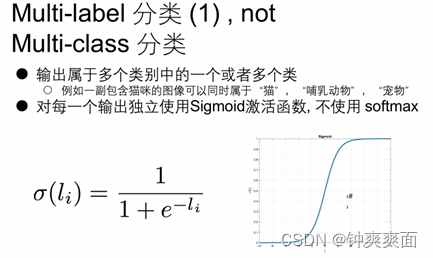
类别之间不是互斥的,可以同属于多个类别
最后输出层不使用softmax,而是单独使用Sigmoid,最后为输出的概率,
假设最后输出三个值,分别为x1=9,x2=8,x3=6, 将x1,x2,x3,分别使用Sigmoid,得出的概率分别是0.6,0.7,0.8,那么意味着,输入属三个类别的概率是多少,与softmax不同的是概率之和不等于1。

K等于标签类别的合集
累加属于真实值标签的输出值,加上不属于该标签的输出值。