损失函数可以分成两大类:分类和回归。这里我们对这两类进行了细分和讲解。
回归损失:
- L1loss(L1损失)
L1损失,也称平均绝对误差(MAE),简单说就是计算输出值与真实值之间误差的绝对值大小。这种度量方法在不考虑方向的情况下衡量误差大小。和MSE的不同之处在于,MAE需要线性规划这样复杂的工具来计算梯度,同时,MAE对异常值更加稳健,因为它不使用平分。 由于L1 loss在零点不平滑,所以用的比较少。 - SmoothL1Loss
L1loss的平滑版。如果绝对元素误差低于1则使用平方项的标准,否则L1项。 它对异常值的敏感度低于MSELoss,并且在某些情况下可以防止爆炸梯度。
- MSELoss(L2损失)
L2损失,也称均方误差,度量的是预测值和实际观测值间差的平分的均值。它只考虑误差的平均大小,不考虑其方向。但由于经过平分,与真实值偏离较多的预测值会受到更为严重的惩罚。同时MSE的数学特性很好,这使得计算梯度变得更容易。 - MBELoss
平均偏差误差,它和L1损失很相似,唯一区别就是这个函数没有绝对值,它可以用来确定模型存在正偏差还是负偏差。

注意:L1、L2损失函数与L1、L2正则化是两个不同的东西。
L1损失函数与L2损失函数的对比分析:
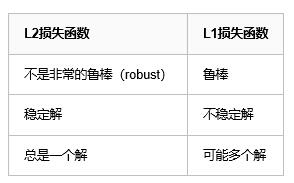
鲁棒性(robustness):
因为与最小平方相比,最小绝对值偏差方法的鲁棒性更好,因此,它在许多场合都有应用。最小绝对值偏差之所以是鲁棒的,是因为它能处理数据中的异常值。这或许在那些异常值可能被安全地和有效地忽略的研究中很有用。如果需要考虑任一或全部的异常值,那么最小绝对值偏差是更好的选择。
从直观上说,因为L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数来得大( e vs e^2 ),因此模型会对这个样本更加敏感,这就需要调整模型来最小化误差。如果这个样本是一个异常值,模型就需要调整以适应单个的异常值,这会牺牲许多其它正常的样本,因为这些正常样本的误差比这单个的异常值的误差小。
稳定性:
最小绝对值偏差方法的不稳定性意味着,对于数据集的一个小的水平方向的波动,回归线也许会跳跃很大。在一些数据结构(data configurations)上,该方法有许多连续解;但是,对数据集的一个微小移动,就会跳过某个数据结构在一定区域内的许多连续解。在跳过这个区域内的解后,最小绝对值偏差线可能会比之前的线有更大的倾斜。相反地,最小平方法的解是稳定的,因为对于一个数据点的任何微小波动,回归线总是只会发生轻微移动;也就说,回归参数是数据集的连续函数。
分类损失
- CrossEntropyLoss
交叉熵损失,常在分类问题中使用,随着预测概率偏离实际标签,交叉熵会逐渐增加。
它将nn.LogSoftmax()和nn.NLLLoss()组合在一个单独的类中。所以使用它并不需要在网络中加入softmax。在多分类任务中,它非常有用。它具有可选参数权重,为1D Tensor,为每个类分配权重。 当您拥有不平衡的训练集时,这尤其有用。 - NLLLoss
负对数似然损失函数。在前面加上LogSoftMax就等价于CrossEntropyLoss。 在多分类任务中很有用。如果提供,则可选参数权重应为1D Tensor,为每个类分配权重。 当您拥有不平衡的训练集时,这尤其有用。
后面这些还不是很清楚什么时候使用,以后再补充。
6、PoissonNLLLoss
target是泊松脉冲分布的负对数似然损失函数。
7、KLDivLoss
KL散度,KL散度是连续分布的有用距离度量,并且在对(离散采样的)连续输出分布的空间执行直接回归时通常是有用的。
8、BCELoss
二分类用的交叉熵,用的时候需要在该层前面加上 Sigmoid 函数。
9、BCEWithLogitsLoss
BCELoss的改进。这种损失将Sigmoid层和BCELoss组合在一个单独的类中。 这个版本在数值上比使用普通的Sigmoid后跟BCELoss更稳定,因为通过将操作组合成一个层,我们利用log-sum-exp技巧来实现数值稳定性。
10、MarginRankingLoss
评价相似度的损失。
11、HingeEmbeddingLoss
在给定输入张量x和包含值(1或-1)的标签张量y的情况下测量损失。 这通常用于测量两个输入是相似还是不相似,例如, 使用L1成对距离作为x,并且通常用于学习非线性嵌入或半监督学习。
12、MultiLabelMarginLoss
多类别(multi-class)多分类(multi-classification)的 Hinge 损失,是上 MultiMarginLoss 在多类别上的拓展。
13、SoftMarginLoss
多标签二分类问题。
14、MultiLabelSoftMarginLoss
上面的多分类版本。
15、CosineEmbeddingLoss
余弦相似度的损失,目的是让两个向量尽量相近
16、MultiMarginLoss
多分类(multi-class)的 Hinge 损失,
17、TripletMarginLoss