前言
首先什么是内联汇编?
内联汇编是在C,C++代码内部嵌入一部分汇编代码, 这部分代码会被编译器跳过直接拼接.
为什么要用内联汇编?
这种情况一般是由于我们对于当前的编译器的能力感到不满意, 所以需要代替编译器来优化一些代码片段. 当然我们可以完全进行汇编实现, 直接把函数写成一个.asm汇编文件(这个文件可以用yasm, nasm, masm进行编译为object文件参与代码链接). 内联汇编相比较而言不用实现整个函数, 比如函数的入栈和出栈的操作, 栈指针也不需要你去计算然后移动, 只需要用寄存器实现高效率的计算.
内联汇编需要特殊的编译器或者命令吗?
内联汇编属于正常C++编译器的特性, 不需要额外的编译命令. 但是MSVC目前只支持32位的内联汇编, 64位汇编据官方说法是没必要. 如果使用Clang进行编译的话就没有问题, 都支持.
微软原话:Inline assembly is not supported on the ARM and x64 processors. 具体官方链接在这里:https://docs.microsoft.com/zh-cn/cpp/assembler/inline/inline-assembler?view=msvc-160
正文
一. 32位汇编
a. 首先创建一个win32的空项目, 这一步省略, 可以参考我前面的文章.
b. 一个简单的内联汇编代码如下:
#include <stdio.h>
int main()
{
int test = 1;
__asm
{
mov eax, test //把test的值写入eax寄存器
dec eax //寄存器数值减一
mov test, eax //把eax的值写回test变量中
}
printf("test:%d\n", test); //test 为0
return 1;
}c. 整体看起来是这样的:

可以看到写32位的内联汇编只需要修改代码, 不需要更改VS的任何配置就可以.
补充一个内联汇编的技巧:
操作数组和_asm行代码:

__asm后面可以直接跟一行汇编代码. 另外汇编代码支持[]的索引操作符.
但是, 这里有个容易犯错的地方:
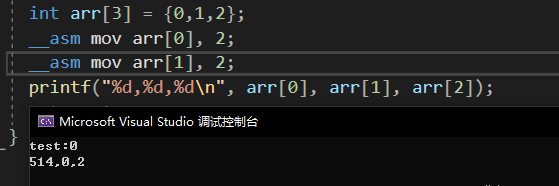
这个易错点就是[]里面的index是字节offset, 不是元素的index. 从上图中可以看到mov arr[1], 2; 这个代码实际上把2写到了arr的第0个元素arr[0]的第二个字节上了, 也就是增加上了512, 加上它自己的2,所以元素0是514.
正确的写法是:

二. 64位汇编
相比较于32位汇编, 64位要麻烦一点, 因为VS原生不支持64位汇编,所以这里需要使用clang来帮助编译.
首先把刚刚这段代码直接用VS的x64配置编译:

会有如下错误:
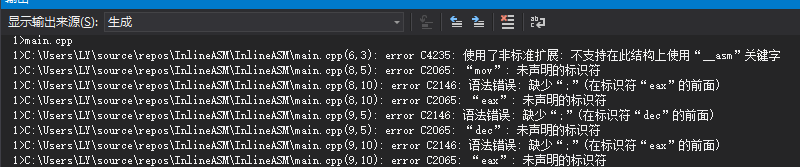
说的很清楚, 该架构不支持内联汇编__asm关键字.
解决方法如下:
1. 在VS2019中使用LLVM Clang作为工具集:

成功后如下:

你有可能没有安装Clang工具集. 打开Visual Studio Installer:



这个安装流程已经提过很多次了, 所以这里就只是示范图片.
安装好了以后, 注释掉clang不支持的数组操作,可以直接编译运行如下:

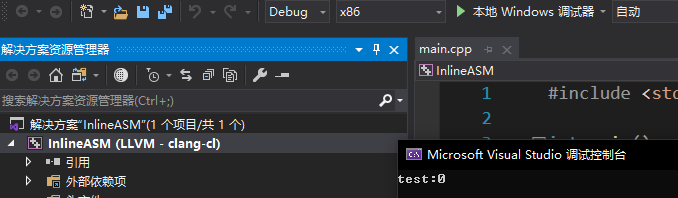

32位 64位内联汇编在clang下都没有任何问题.
2. 使用custom build, 使用clang单独编译64位内联汇编
如果你的项目比较小, 那第一种方法完全可以解决你的问题. 但是, 如果你的项目需要和别的VS项目一起协同, 整个项目使用Clang作为工具集并不是一种很保险的操作.
这种情况下, 我们单独将内联汇编代码集中到一个cpp中, 将这个cpp单独使用clang来进行编译. 这样的话, 项目整体还是作为VS项目. 这种单独用clang编译某些源码的操作就是custom build, 客户自定义生成.
首先你需要安装好llvm的clang编译器, 打开控制台cmd, 输入clang --version:

如果正确显示则没有问题. 如果没有安装的话,请看我上一篇文章安卓控制台的开发中有写到.
a. 先创建一个custom.cpp来写内联汇编函数.
int asminc(int a)
{
asm(
"inc %[_a] \n" //_a是下面指定的符号名对应传入变量int a;
//\n是表示换行,如果没有这个换行符实际上等于 inc%[_a] inc%0
"inc %0 \n" //%0表示第0个传入参数和上一句的意义实际上是一样的,都表示 int a
:[_a]"+r"(a) //这里表示输出列表,
//_a表示asm代码里面的符号名,"+r"表示会修改a的值,(a)中的a表示int a映射到asm代码块中
: //这里表示输入列表, 如果只是读取值的变量就写到这里
: //这里是寄存器保留列表, 如果加上eax的话, 编译器会在运行汇编之前保证eax寄存器是可用的, 否则
//eax可能还保留着上面的代码需要的数据
);
return a;
}b. 增加custom build命令行:
右键InlineASM项目,点击属性打开项目属性页,增加自定义生成工具命令行:

其中 32位的命令行是:
clang-cl -c %(Filename).cpp --target=i386 -o $(OutputPath)%(Filename).obj
64位的命令行是:
clang-cl -c %(Filename).cpp --target=x86_64 -o $(OutputPath)%(Filename).obj
clang是跨平台的编译器, 主要根据target来决定将cpp编译成什么系统架构, 编译选项如下:
Target Triple
The basic option is to define the target architecture. For that, use -target <triple>. If you don’t specify the target, CPU names won’t match (since Clang assumes the host triple), and the compilation will go ahead, creating code for the host platform, which will break later on when assembling or linking.
The triple has the general format <arch><sub>-<vendor>-<sys>-<abi>, where:
arch=x86_64,i386,arm,thumb,mips, etc.sub= for ex. on ARM:v5,v6m,v7a,v7m, etc.vendor=pc,apple,nvidia,ibm, etc.sys=none,linux,win32,darwin,cuda, etc.abi=eabi,gnu,android,macho,elf, etc
clang-cl是Windows下的clang工具名称, cl是命令行风格的意思, 当然用clang也是可以的, 只是有些时候会提醒你使用clang-cl代替clang.
如果有任何的编译选项的问题,比如头文件路径问题啊,指令集的问题, 可以参考这个文章:https://clang.llvm.org/docs/UsersManual.html#c-ms
修改cpp文件的类型为自定义生成工具:

点击自定义生成工具,然后点击应用, 这时候左边会出现自定义生成工具的页标 .点击自定义工具下的常规, 查看命令行和输出是否正确, 默认状态下是和上面的clang命令一致的.
但是如果你不小心修改了, 可以选择继承父项目恢复它:

c. 修改main.cpp中的调用, 运行:

asm函数内部对传入参数加了两次1, 输出为3, 正确.
c. 再加上刚刚的dec的函数:

注意看, 这两种内联汇编代码风格是完全不一样的. asmdec中是intel风格, 而 asminc中是属于AT&T风格. 这两种风格都支持, 各有好坏.
AT&T语法参考https://gcc.gnu.org/onlinedocs/gcc/Extended-Asm.html
intel语法参考最开始微软的文章: https://docs.microsoft.com/zh-cn/cpp/assembler/inline/inline-assembler?view=msvc-160
64位下两种语法都没问题:

32位下会有这个编译问题:
error : expected '(' after 'asm'
也就是32位下不支持这种Intel语法, 由于32位汇编和64位汇编基本上是不一样的. 所以不存在一套汇编代码32位,64位共用的情况, 32位下可以不用custom build直接使用MSVC进行编译就行.
又想了一下, 刚开始的LLVM Clang作为工具集在x86的配置下明显是支持Intel语法的, 所以我这里的clang 命令行肯定有些关于Windows或者微软的某些传入参数没有打开导致Intel语法不能使用.
这个也不是很紧要, 如果以后我发现了再更新到这篇文章.
总结
32位的内联汇编:
MSVC支持 Intel语法
Clang支持 Intel和AT&T语法
64位的内联汇编:
MSVC不支持:
Clang支持 Intel和AT&T语法
另外, 虽然上文全部展示的是x86的汇编, 但是实际上Armeabi和Arm64的汇编都可以通过Clang用AT&T语法来做, intel语法不支持Arm.
所以我建议用clang来进行内联汇编的编译, 另外统一使用AT&T语法(汇编代码肯定每个架构一套, 统一的意思是指同一种内联风格).
最后
内联汇编能有哪些提升,:
1. 调节某些指令的顺序使CPU指令的pipeline的利用率最大化
2. 增加寄存器数据的利用率, 避免从栈内存加载和保存临时数据
其中1的提升是比较小的, 这部分编译器其实做的很不错了.
相比较而言, 2的提升可以很大. 这种提升主要是在代码块需要进行大量数据的load参与计算,计算完成后再把计算的数据store到内存地址上,
其中可能有很多的中间计算结果. 如果编译器没有分配好寄存器资源, 可能导致中间计算结果会在计算过程中被临时保存到栈内存的变量地址中,
下次用的时候再从内存里加载回来, 这种操作对代码的运行来说是非常影响效率的.
经验来看的话, 经过深度优化的汇编代码应该可以比编译器O2优化等级的代码快上20%以上.