SQL笔试训练
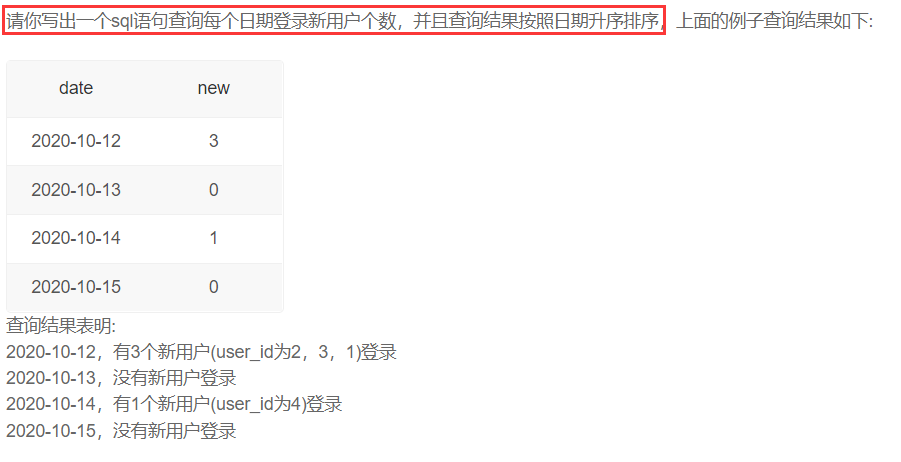
查询结果去重
两种答案

查找某个年龄段的用户信息


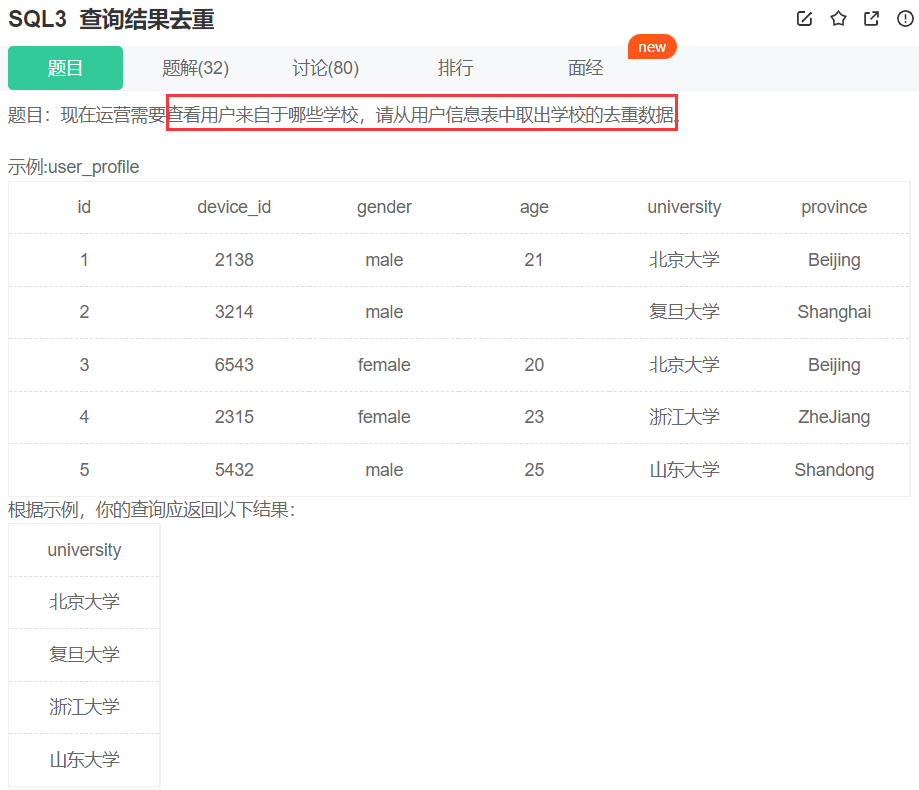
查找除复旦大学的用户信息
三种答案

用where过滤空值练习

三种答案


查询NULL时,不能使用比较运算符(=或者< >),需要使用IS NULL运算符或者IS NOT NULL运算符。
操作符混合运用
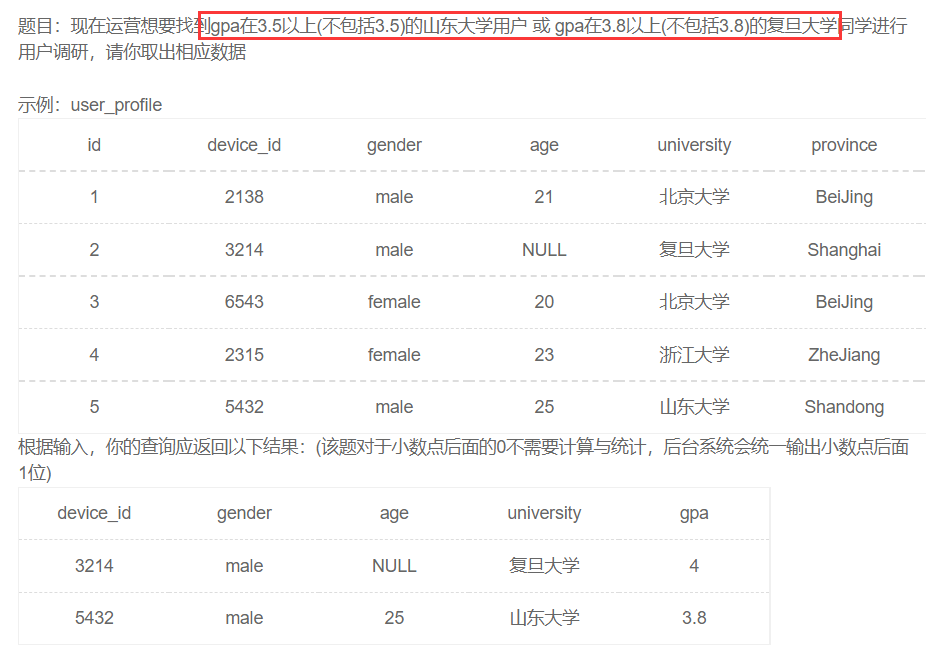
我这里写大括号方便区分,表示两个条件或两个条件

由于and的优先级大于or,所以可以省略括号,如果不确定可以用()来改变运算的优先级
查看学校名称中含北京的用户


考点 like
- like '%北京%'列名包括北京的字样
- like '北京%' 列名北京开头
- like '%北京' 列名北京结尾
匹配串中可包含如下四种通配符
- _:匹配任意一个字符;
- %:匹配0个或多个字符;
- [ ]:匹配[ ]中的任意一个字符(若要比较的字符是连续的,则可以用连字符“-”表 达 );
- [^ ]:不匹配[ ]中的任意一个字符。
实例


查找GPA最高值


计算男生人数以及平均GPA

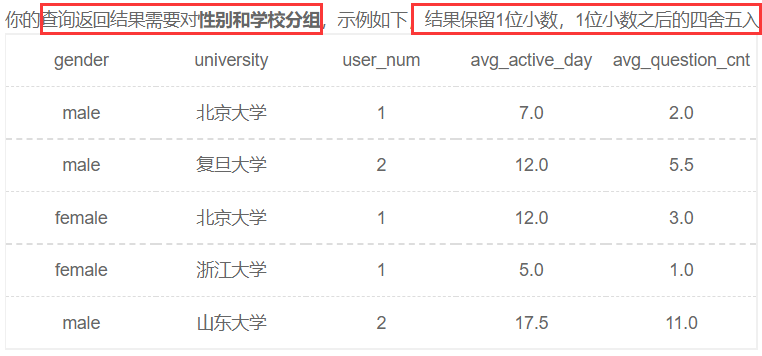
细节问题:根据输出示例,有两个问题需要注意
- 表头重命名,用as语法
- 此题要注意的是暗含条件,保留一位小数,使用ROUND()函数舍入到指定的长度或精度

分组计算练习题

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |

分组过滤练习题

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |
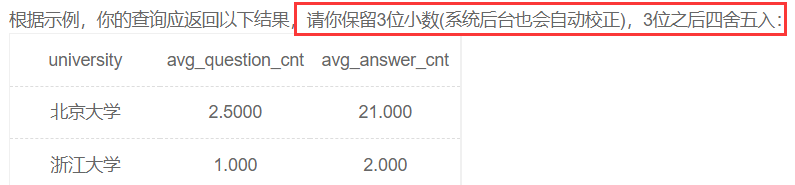
问题分解
- 限定条件:平均发贴数低于5或平均回帖数小于20的学校,avg(question_cnt)<5 or avg(answer_cnt)<20,聚合函数结果作为筛选条件时,不能用where,而是用having语法,配合重命名即可;
- 按学校输出:需要对每个学校统计其平均发贴数和平均回帖数,因此group by university,这里特别注意要对学校进行分组这个隐藏条件
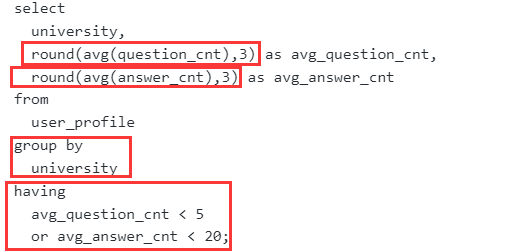
分组排序练习题

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |

问题分解
- 限定条件:无;
- 不同大学:按学校分组 group by university
- 平均发帖数:avg(question_cnt)
- 升序排序:order by avg_question_cnt

浙江大学用户题目回答情况
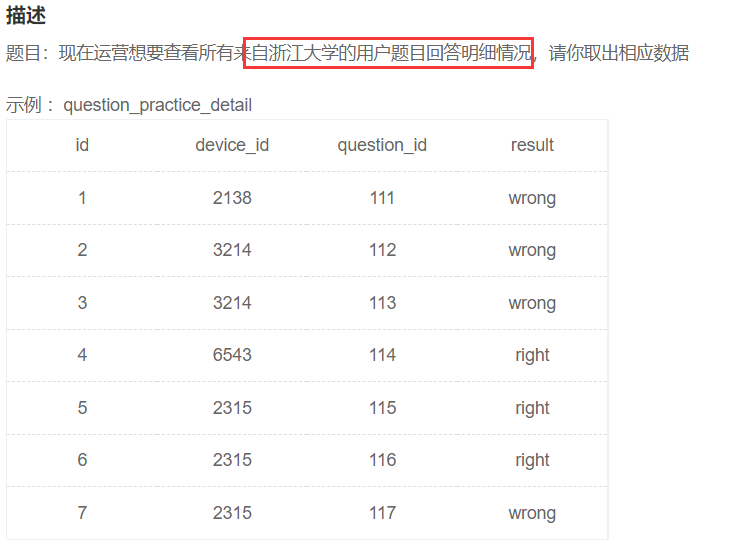
示例:user_profile
| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |

问题分解
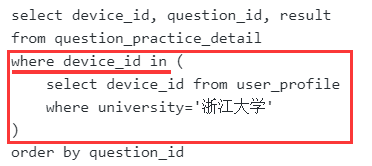
限定条件:来自浙江大学的用户,学校信息在用户画像表,答题情况在用户练习明细表,因此需要通过device_id关联两个表的数据;
- 方法1:join两个表,用inner join,条件是on up.device_id=qpd.device_id and up.university='浙江大学'
- 方法2:先从画像表找到浙江大学的所有学生id列表where university='浙江大学',再去练习明细表筛选出id在这个列表的记录,用where in

两种答案

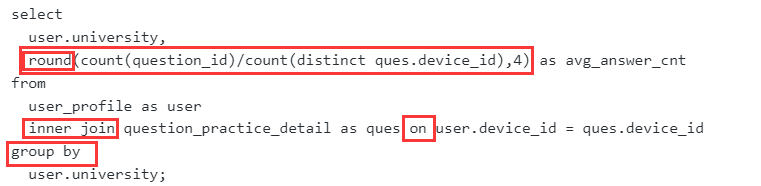
统计每个学校的答过题的用户的平均答题数

问题分解
- 限定条件:无;
- 每个学校:按学校分组,group by university
- 平均答题数量:在每个学校的分组内,该学校用户答题总次数除以答过题的不同用户个数 count(question_id) / count(distinct ques.device_id)
- 这个题的难点就在这里,要知道整个结果是把两个表联合在一起然后按学校分组了的,所以这个时候question_id的数量就是每个学校用户答题总次数,而distinct ques.device_id的总数量就答过题的不同用户个数,最核心的就是要站在“整个结果是把两个表联合在一起然后按学校分组了的”这个前提下去想
- 表连接:学校和答题信息在不同的表,需要做连接
统计每个学校各难度的用户平均刷题数

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |
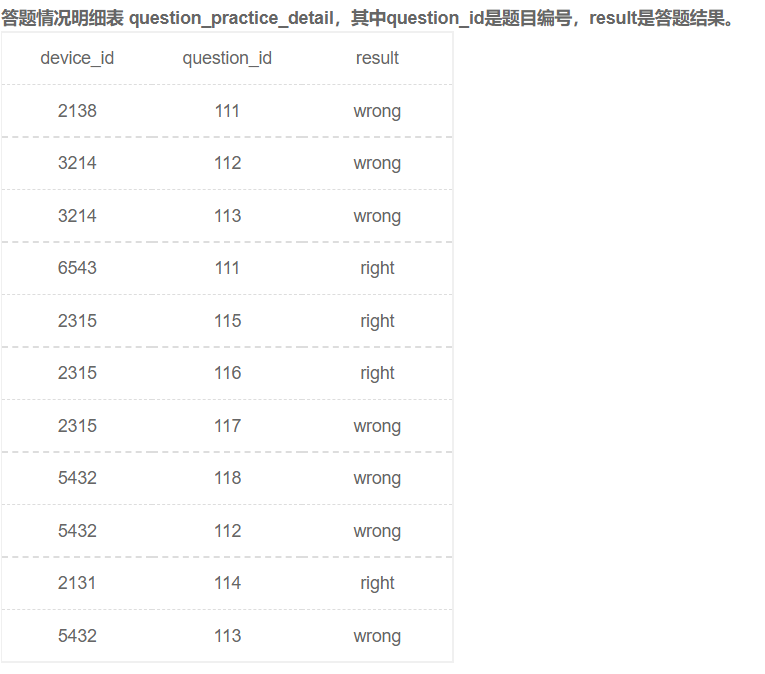
题库练习明细表:question_practice_detail
| id |
device_id |
question_id |
result |
| 1 |
2138 |
111 |
wrong |
| 2 |
3214 |
112 |
wrong |
| 3 |
3214 |
113 |
wrong |
| 4 |
6534 |
111 |
right |
| 5 |
2315 |
115 |
right |
| 6 |
2315 |
116 |
right |
| 7 |
2315 |
117 |
wrong |
| 8 |
5432 |
117 |
wrong |
| 9 |
5432 |
112 |
wrong |
| 10 |
2131 |
113 |
right |
| 11 |
5432 |
113 |
wrong |
| 12 |
2315 |
115 |
right |
| 13 |
2315 |
116 |
right |
| 14 |
2315 |
117 |
wrong |
| 15 |
5432 |
117 |
wrong |
| 16 |
5432 |
112 |
wrong |
| 17 |
2131 |
113 |
right |
| 18 |
5432 |
113 |
wrong |
| 19 |
2315 |
117 |
wrong |
| 20 |
5432 |
117 |
wrong |
| 21 |
5432 |
112 |
wrong |
| 22 |
2131 |
113 |
right |
| 23 |
5432 |
113 |
wrong |
表:question_detail
| id |
question_id |
difficult_level |
| 1 |
111 |
hard |
| 2 |
112 |
medium |
| 3 |
113 |
easy |
| 4 |
115 |
easy |
| 5 |
116 |
medium |
| 6 |
117 |
easy |
问题分解
- 限定条件:无;
- 每个学校:按学校分组group by university
- 不同难度:按难度分组group by difficult_level
- 平均答题数:总答题数除以总人数count(ques.question_id) / count(distinct ques.device_id)
- 由于结果需要三个表中的多列数据,因此进行关联
注:由于计算平均答题数的数据均来源于question_practice_detail,因此在联结时候应保全该表,以该表为本体联结另外两张表,通过device_id和question_id连接。

知识点补充
在合并表格的过程中,存在几种合并方式,下面简单介绍一下这些方式(此处以两张表格的情况为例解释)
- inner join 最终结果为在两张表格中都匹配上的数据项
- left join 最终结果为inner join结果加上左侧表格(此处为第一张表)未匹配上的数据
- right join 最终结果为inner join结果加上右侧表格(此处为第一张表)未匹配上的数据
- full join 最终结果为inner join加上左侧和右侧两张表中未匹配上的数据
备注:只写一个join时默认为inner join模式
查找山东大学或者性别为男生的信息

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |

问题分解
- 限定条件:学校为山东大学或者性别为男性的用户:university='山东大学', gender='male';
- 分别查看&结果不去重:所以直接使用两个条件的or是不行的,直接用union也不行(因为要求不去重,而用union 会去重),要用union all,分别去查满足条件1的和满足条件2的,然后合在一起不去重
union 和union all的区别
- union是合并两个查询语句的结果集,并排除重复项
- union all是不排除重复项的(符合题目要求)
union使用前提
使用union合并两个表时,需要两个表的结果集字段完全一样;
- 表一(SELECT device_id,gender,age,gpa );
- 表二(SELECT device_id,gender,age,gpa);

计算25岁以上和以下的用户数量

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |
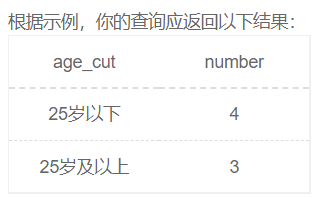

上面的一定要记得进行分组,这个地方我一开始就忘记了,然后end后面写的是第一列和第二列的别名,不过第二列还要统计总数量


查看不同年龄段的用户明细
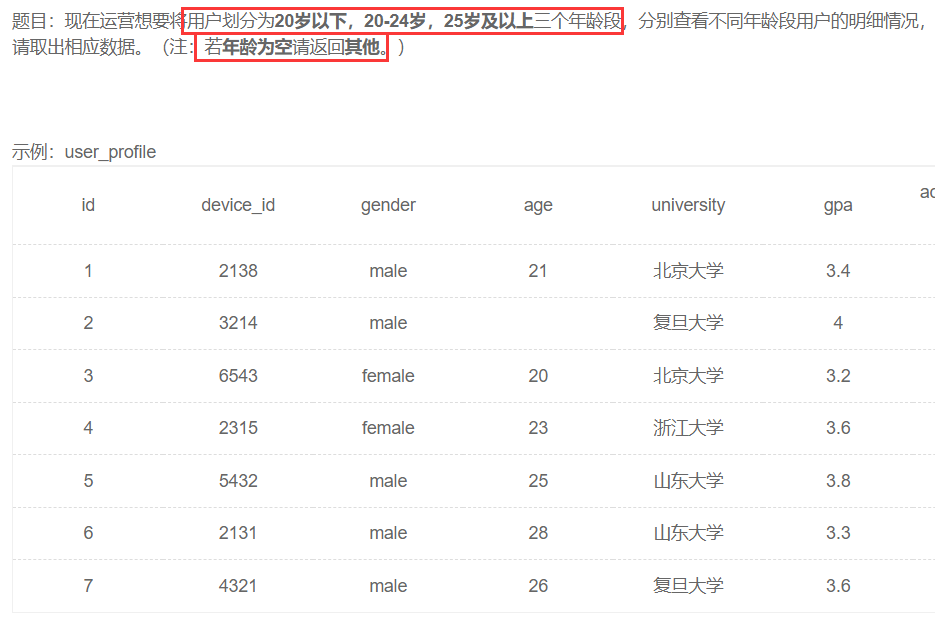
| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |


这个题目要区分上面的那个题目,上面分组了,这里没分组,我一开始就是给这个题目分组了,其实这里压根没有分组
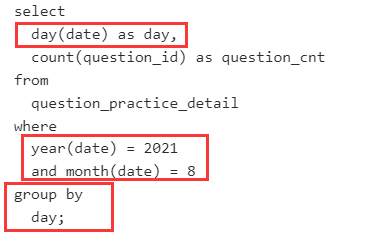
计算用户8月每天的练题数量
.
问题分解
- 限定条件:2021年8月,写法有很多种
-
- 比如用year/month函数的year(date)=2021 and month(date)=8
- 比如用date_format函数的date_format(date, "%Y-%m")="202108"
- 每天:按天分组group by date
- 题目数量:count(question_id)
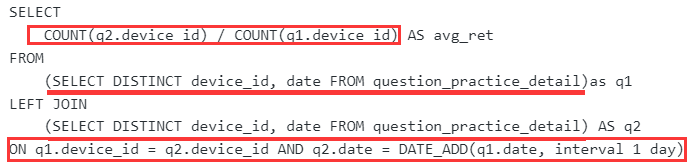
计算用户的平均次日留存率
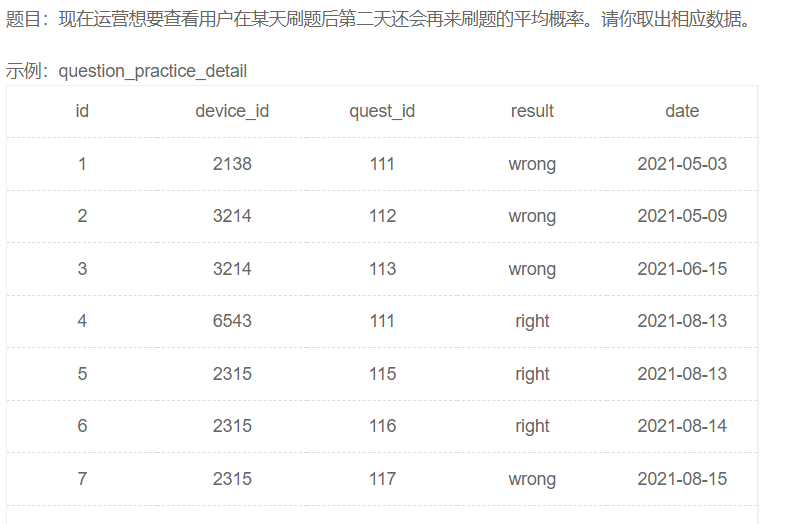

问题分解
限定条件:第二天再来。
- 解法1:表里的数据可以看作是全部第一天来刷题了的,那么我们需要构造出第二天来了的字段,因此可以考虑用left join把第二天来了的拼起来,限定第二天来了的可以用date_add(date1, interval 1 day)=date2筛选,并用device_id限定是同一个用户。
- 解法2:用lead函数将同一用户连续两天的记录拼接起来。先按用户分组partition by device_id,再按日期升序排序order by date,再两两拼接(最后一个默认和null拼接),即lead(date) over (partition by device_id order by date)
平均概率:
- 解法1:可以count(date1)得到左表全部的date记录数作为分母,count(date2)得到右表关联上了的date记录数作为分子,相除即可得到平均概率
- 解法2:检查date2和date1的日期差是不是为1,是则为1(次日留存了),否则为0(次日未留存),取avg即可得平均概率。
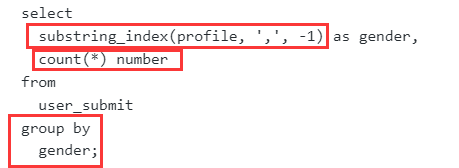
统计每种性别的人数

问题分解
- 限定条件:无;
- 每个性别:按性别分组group by gender,但是没有gender字段,需要从profile字段截取,按字符,分割后取出即可。可使用substring_index函数可以按特定字符串截取源字符串。因此,本题可以直接用substring_index(profile, ',', -1)取出性别。
-
- substring_index(FIELD, sep, n)可以将字段FIELD按照sep分隔:
-
-
- 当n大于0时取第n个分隔符(n从1开始)左边的全部内容;
- 当n小于0时取倒数第n个分隔符(n从-1开始)右边的全部内容;
-
- 多少参赛者:计数统计,count(device_id)

三种答案
用substring_index
依旧使用case和like即可简单实现
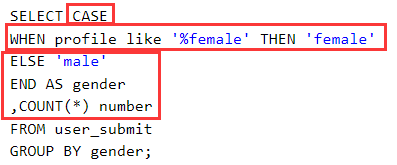
仅为两项可用if代替case,搭配like使用

提取博客URL中的用户名

问题分解
- 限定条件:无;
- 提取字段内信息:个人博客字段中的用户名是被字符/分隔的最后一个子串,使用substring_index函数可以按特定字符串截取源字符串 substring_index(FIELD, sep, n)可以将字段FIELD按照sep分隔: 因此,本题可以用substring_index(blog_url, '/', -1)取出用户名.
-
- (1).当n大于0时取第n个分隔符(n从1开始) 左边 的全部内容;
- (2).当n小于0时取 倒数第-n个 分隔符(n从-1开始) 右边 的全部内容;


截取出年龄



查找后多列排序

排序的顺序是完全按照规定执行的,如 order by 字段1,字段2 只有在排序的时候,字段1具多个相同的数据后,才会再按照字段2排序。 如果字段1是唯一的,则不会按照字段2去排序。

查找后降序排列



找出每个学校GPA最低的同学

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
male |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |

问题分解
限定条件:gpa最低,看似min(gpa),但是要留意,是每个学校里的最低,不是全局最低。min(gpa)的时候对应同学的ID丢了,直接干是拿不到最低gpa对应的同学ID的;SELECT device_id,university,min(gpa) FROM user_profile GROUP BY university; 因为学校与学生是一对多的关系,如果仅用min求出gpa最低的学生,查询结果中的id与学生不一定是对应的关系,因此此方法错误。

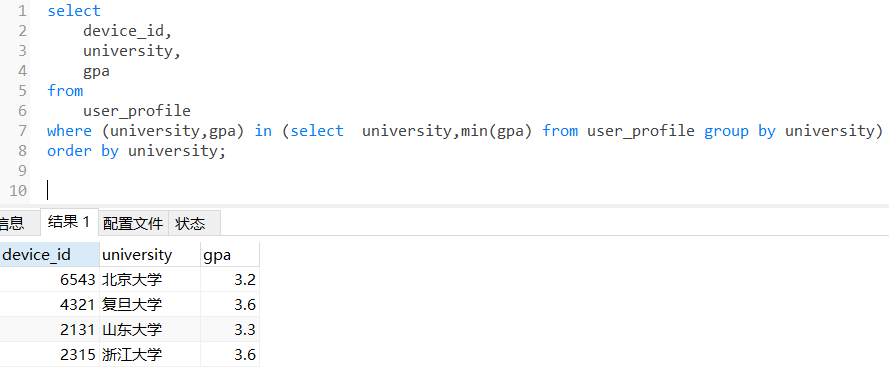
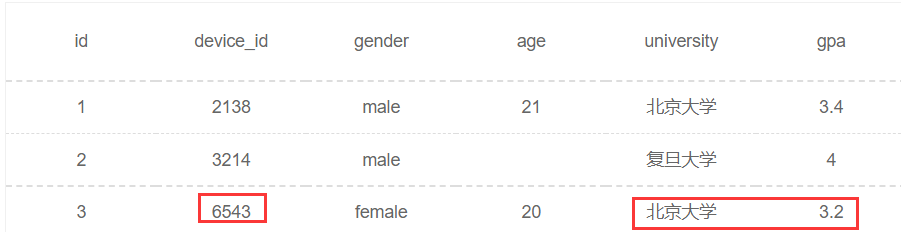
可以看到北京大学gpa的最低值是3.2对应的id是6543,第一种查出来的id是2138,很明显第一种是错的
两种思路
- 第一种方式是用group by把学校分组,然后计算得到每个学校最低gpa,再去找这个学校里和这个gpa相等的同学ID。注意这样如果最低gpa对应多个同学,都会输出,题目没有明确此种情况,心理明白就行。
- 第二种方式是利用窗口函数,先按学校分组计算排序gpa,得到最低gpa的记录在用子查询语法拿到需要的列即可。此题中rou_number可以得到排序后的位序,取位序为1即可得到最小值(升序时)。
三种答案



统计复旦用户8月练题情况

|
|
gender |
age |
university |
gpa |
active_days_within_30 |
|
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
| 2 |
3214 |
male |
复旦大学 |
4.0 |
15 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
| 7 |
4321 |
female |
26 |
复旦大学 |
3.6 |
9 |
问题分解
- 限定条件:需要是复旦大学的(来自表user_profile.university),8月份练习情况(来自表question_practice_detail.date)
- 从date中取month:用month函数即可;
- 总题目:count(question_id)
- 正确的题目数:sum(if(qpd.result='right', 1, 0))
- 按列聚合:需要输出每个用户的统计结果,因此加上group by up.device_id
细节问题
- 8月份没有答题的用户输出形式:题目要求『对于在8月份没有练习过的用户,答题数结果返回0』因此明确使用left join即可,即输出up表中复旦大学的所有用户,如果8月没有练习记录,输出0就好了,这个实现是通过sum(if(qpd.result='right', 1, 0))来实现的,只有result不是right,那就都是0,无论是答错了还是没有答都是0
- 表头:as语法重命名后两列就好

这里一开始我是先把两张表连接起来(用inner join),再用where去筛选。但是本题目是要求找出复旦大学中所有用户8月份的答题情况,复旦大学的用户中,有可能存在8月份没有答题的用户。若先把两张表连起来再用where筛选限定条件,那么运行结果会把属于复旦大学但是没有答题的用户剔除了,不符合本题要求。
我们要的结果是:复旦大学所有用户8月的作答情况,包含没有作答过的。

浙大不同难度题目的正确率

| id |
device_id |
gender |
age |
university |
gpa |
active_days_within_30 |
question_cnt |
answer_cnt |
| 1 |
2138 |
male |
21 |
北京大学 |
3.4 |
7 |
2 |
12 |
| 2 |
3214 |
male |
复旦大学 |
4 |
15 |
5 |
25 |
|
| 3 |
6543 |
female |
20 |
北京大学 |
3.2 |
12 |
3 |
30 |
| 4 |
2315 |
female |
23 |
浙江大学 |
3.6 |
5 |
1 |
2 |
| 5 |
5432 |
male |
25 |
山东大学 |
3.8 |
20 |
15 |
70 |
| 6 |
2131 |
male |
28 |
山东大学 |
3.3 |
15 |
7 |
13 |
| 7 |
4321 |
female |
26 |
复旦大学 |
3.6 |
9 |
6 |
52 |

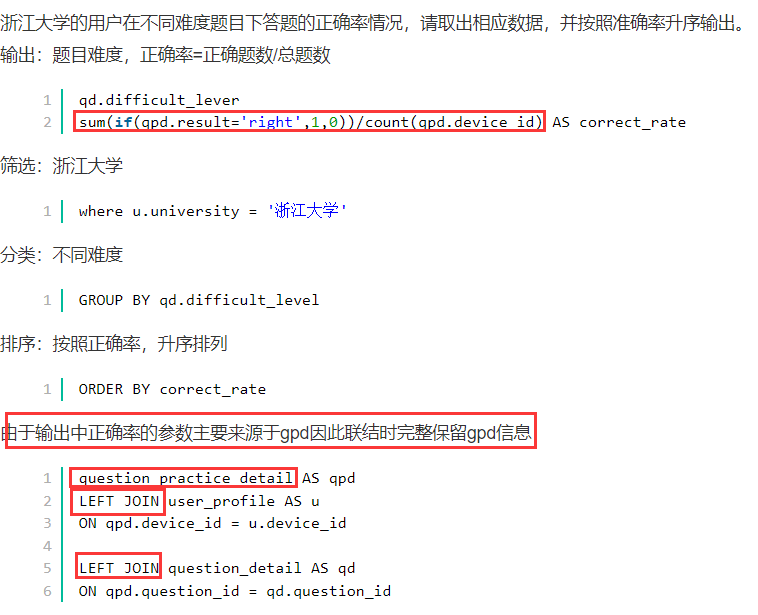
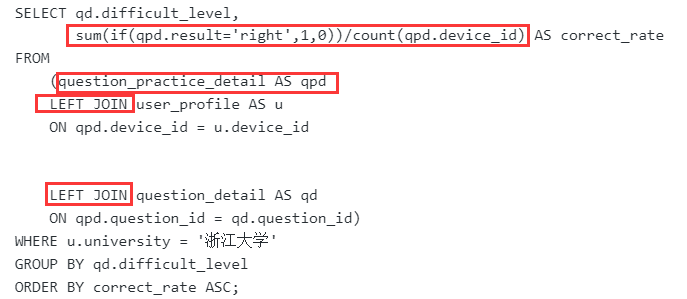
查找最晚入职员工的所有信息


知识点
- ORDER BY 根据指定的列对结果集进行排序,默认按照升序,降序 ORDER BY DESC
- LIMIT(m, n) 从第 m + 1 行开始取 n 条记录
- 最晚员工自然是 hire_data,最晚可以用排序 ORDER BY DESC 降序来得到,然后是获取第一条记录,这样理论上是有 bug 的,因为 hire_data 可能有多个相同的记录.
- select * from employees order by hire_date desc limit 0,1 所以这样写不严谨
查找入职员工时间排名倒数第三的员工所有信息


注意事项
- where ...in...和limit是不能一起用的,非要一起用就要做一定的修改,可以用where ...=...代替
-

- 若存在多人(如3人)同时在最晚的一天入职的情形,必须要考虑去重(使用distinct或者group by),distinct和group by的执行顺序都在limit前面,因为多个人最后一天入职的话那limit 2,1得到的只是降序后的第三条数据,而不是时间排名倒数第三的数据,其中时间排名倒数第一的就占了多条记录
- LIMIT(m, n) 从第 m + 1 行开始取 n 条记录
-

查找当前薪水详情以及部门编号dept_no
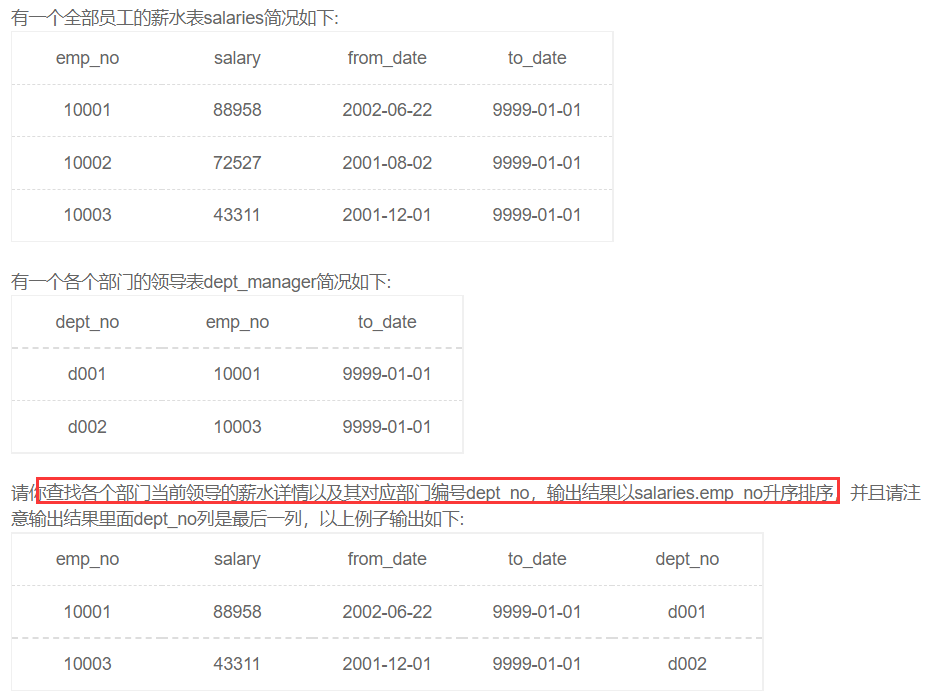

这里我一开始是用的左外连接,要仔细看输出结果来决定用什么连接!
查找薪水记录超过15条的员工号emp_no以及其对应的记录次数t
有一个薪水表,salaries简况如下:
| emp_no |
salary |
from_date |
to_date |
| 10001 |
60117 |
1986-06-26 |
1987-06-26 |
| 10001 |
62102 |
1987-06-26 |
1988-06-25 |
| 10001 |
66074 |
1988-06-25 |
1989-06-25 |
| 10001 |
66596 |
1989-06-25 |
1990-06-25 |
| 10001 |
66961 |
1990-06-25 |
1991-06-25 |
| 10001 |
71046 |
1991-06-25 |
1992-06-24 |
| 10001 |
74333 |
1992-06-24 |
1993-06-24 |
| 10001 |
75286 |
1993-06-24 |
1994-06-24 |
| 10001 |
75994 |
1994-06-24 |
1995-06-24 |
| 10001 |
76884 |
1995-06-24 |
1996-06-23 |
| 10001 |
80013 |
1996-06-23 |
1997-06-23 |
| 10001 |
81025 |
1997-06-23 |
1998-06-23 |
| 10001 |
81097 |
1998-06-23 |
1999-06-23 |
| 10001 |
84917 |
1999-06-23 |
2000-06-22 |
| 10001 |
85112 |
2000-06-22 |
2001-06-22 |
| 10001 |
85097 |
2001-06-22 |
2002-06-22 |
| 10002 |
72527 |
1996-08-03 |
1997-08-03 |

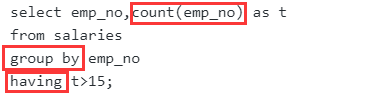
注意事项
- 由于是用到了聚合函数count,所以不能用where,应该用having
- 在一个查询中,HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前
查找employees表emp_no与last_name的员工信息


推荐使用方法2,因为效率更高,其中逆序就是降序
- 查询奇数的一般方法:字段名 &(位运算) 1
- 查询偶数的一般方法:emp_no=(emp_no>>1<<1)
但是,以上的一般方法,针对的是字段全是数字的情况,如果对于身份证这种中间隐藏了一部分的,奇数无法使用,所以更好的方法是使用正则化表达式
正则化表达式
^aa:以aa开头
aa$:以aa结尾
.:匹配任何字符
[abc]:[字符集合],包含中括号内的字符
[^abc]或[!abc]:[字符集合],不包含中括号内的字符
a|b|c:匹配a或b或c,如(中|美)国
:匹配前面的子表达式0次或者多次。如,zo能匹配’z’以及’zoo’。*等价于{0,}
+:匹配前面的子表达式1次或者多次。如,’zo+’能匹配’zo’,但不能匹配’z’。+等价于{1,}
{n}:n是一个非负整数,匹配前面的子表达式2次。如,o{2} 能匹配’food’中的两个o,但不能匹配’Bob’中的o
{n, m}:m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。
对所有员工的薪水按照salary降序进行1-N的排名
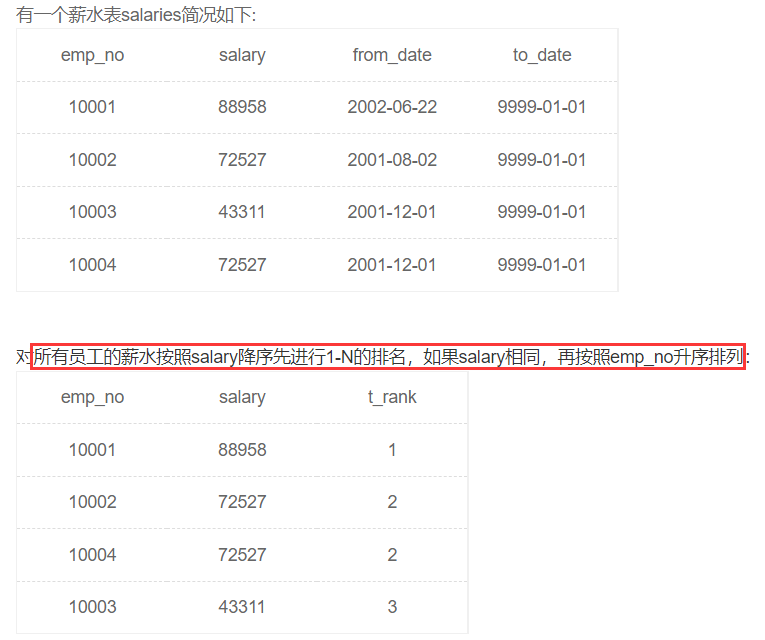

窗口函数

获取所有员工当前的manager
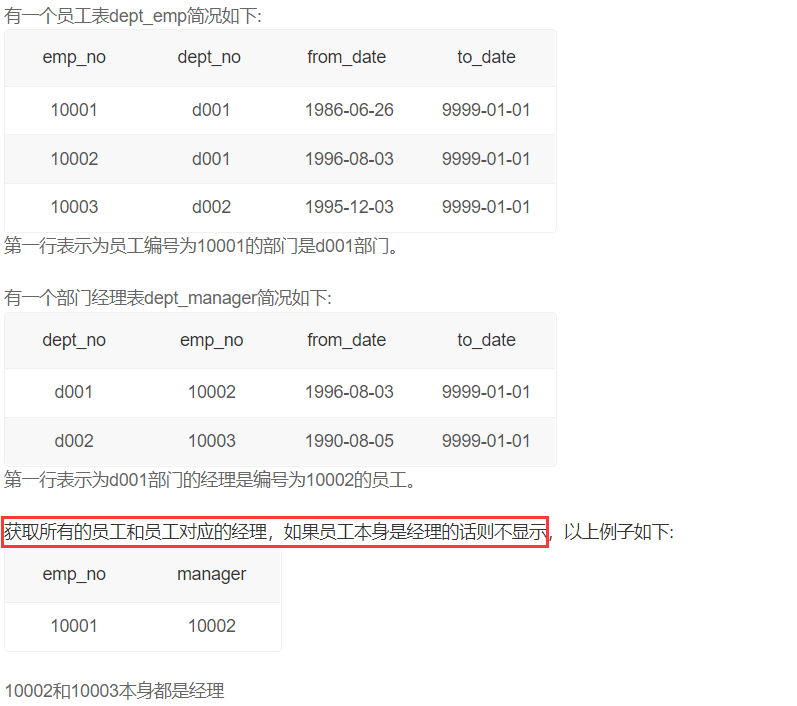
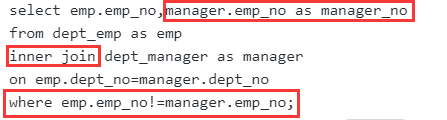
这个答案感觉不太好理解
统计各个部门的工资记录数
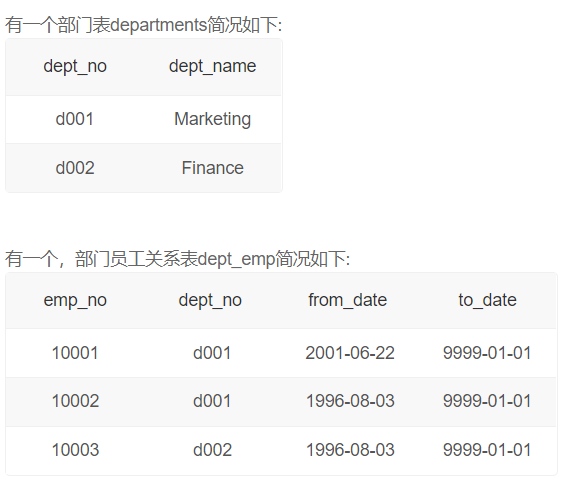


这里选择用departments表(中间表)来连接其他两个表,我之前以为必须要和其他两个表有共同字段的表才可以作这个中间表,如果都是用的内连接(inner join)那无论用哪个表作中间表连接其他的表都可以
为什么dept_name 不属于聚合键,依然可以直接多表连接?
根据我查找的资料官方解释是:当group by 后面跟上主键或者不为空唯一索引时,查询是有效的,因为此时的每一笔数据都具有唯一性。
Mysql官方网站对此的描述链接:MySQL :: MySQL 5.7 Reference Manual :: 12.20.3 MySQL Handling of GROUP BY
dept_no是departments表的主键,所以以上代码的结果具有唯一性。也就是说depat_name是对应dept_no的。
获取所有非manager员工当前的薪水情况

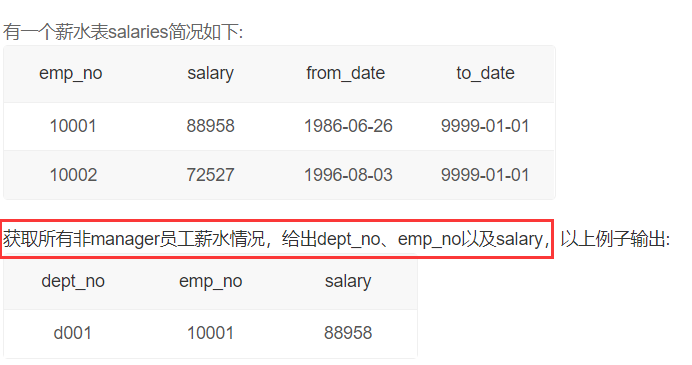
思路:先找到所有非manager员工emp_no,再内连接工资表和部门表即可

使用join查询方式找出没有分类的电影id以及名称

两种答案

推荐第一种,第二种答案的子查询即使不内连接也是可以的,但是题目要求用join连接
将employees表的所有员工的last_name和first_name拼接起来作为Name
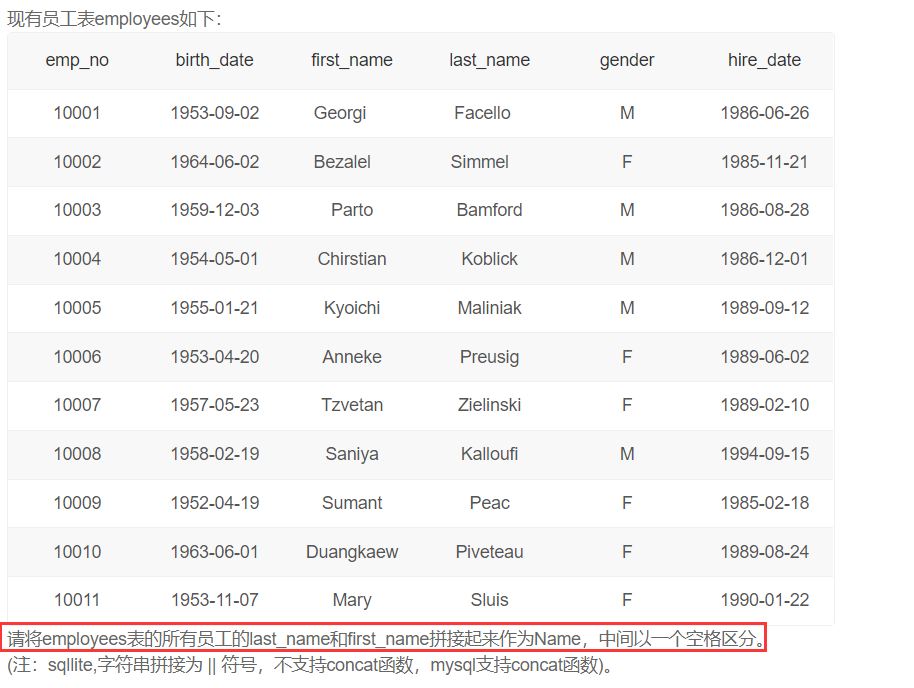

注意这里连接符号要用双引号引起来,不是单引号
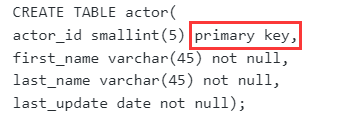
创建一个actor表,包含如下列信息

批量插入数据
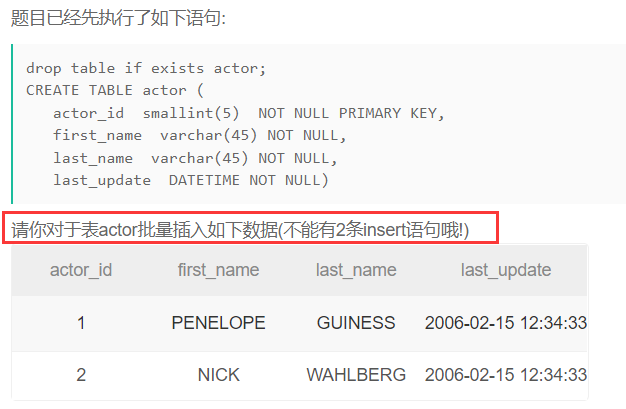

如果插入的字段和表的字段都是完全一样就可以用上面的写法,不一样就用下面的写法
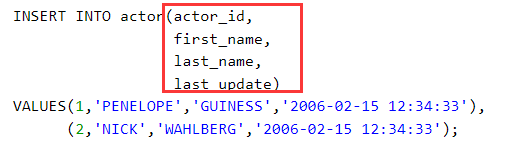
批量插入数据,不使用replace操作


mysql中常用的三种插入数据的语句
- insert into表示插入数据,数据库会检查主键,如果出现重复会报错;
- replace into表示插入替换数据,需求表中有PrimaryKey或者unique索引,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;
- insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据;
创建一个actor_name表
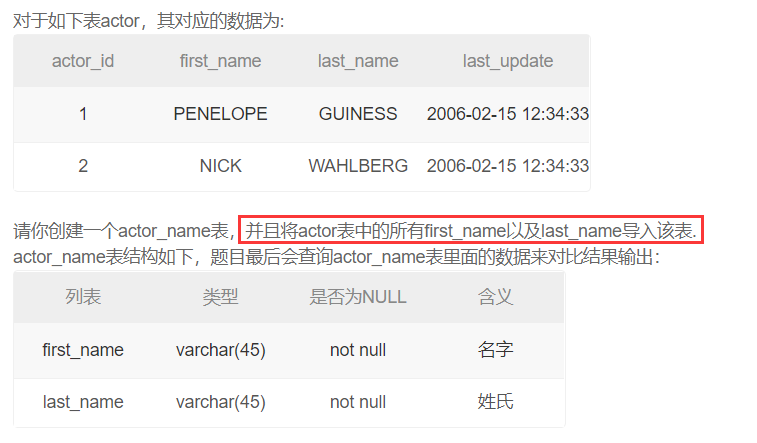

MYSQL创建数据表的三种方法
- 常规创建
create table if not exists 目标表 - 复制表格
create 目标表 like 来源表 - 将table1的部分拿来创建table2
create table if not exists 要创建表的表名 (select 字段名 from 表名 where 条件)
对first_name创建唯一索引uniq_idx_firstname


MySQL中给字段创建四种不同类型索引的基本语法

针对actor表创建视图actor_name_view
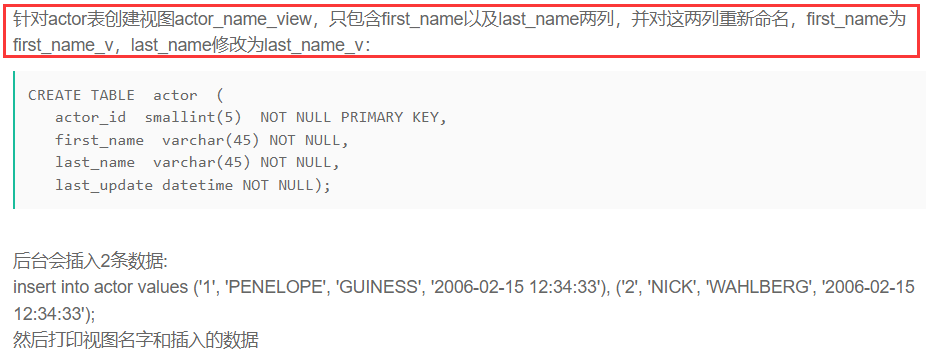

注意上面的as不能丢
针对上面的salaries表emp_no字段创建索引idx_emp_no


注意这里创建表的时候已经创建了索引
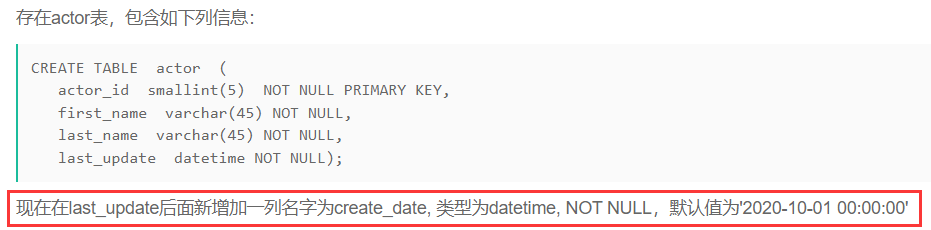
在last_update后面新增加一列名字为create_date

构造一个触发器audit_log

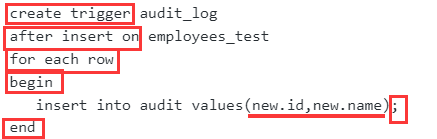
上面的audit里的emp_no就是employees_test的id
在MySQL中,创建触发器语法如下
CREATE TRIGGER trigger_name
trigger_time trigger_event ON tbl_name
FOR EACH ROW
trigger_stmt
其中:
- trigger_name:标识触发器名称,用户自行指定;
- trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
- trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
- tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
- trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
【NEW 与 OLD 详解】
MySQL 中定义了 NEW 和 OLD,用来表示
触发器的所在表中,触发了触发器的那一行数据,具体地:
- 在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
- 在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;
- 在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;
使用方法: NEW.columnName (columnName 为相应数据表某一列名)
删除emp_no重复的记录,只保留最小的id对应的记录

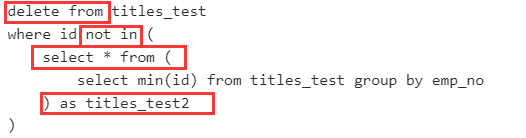
这里把 select min(id) from titles_test group by emp_no得出的表重命名为titles_test2那就不是原表了,所以就可以删除了

注意:mysql不允许在子查询的同时删除原表数据,所以下面的写法是错误的!
将所有to_date为9999-01-01的全部更新为NULL


基本的数据更新语法
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005

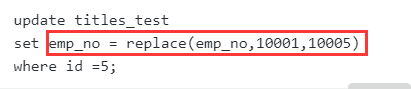
本题考查的是replace函数,其中包含三个参数
- 第一个参数为该字段的名称
- 第二参数为该字段的需要被修改值
- 第三个参数为该字段修改后的值
如果不强制使用replace函数,那还有下面的方式
使用insert

使用replace into

将titles_test表名修改为titles_2017

alter table titles_test rename to titles_2017
1. 修改表名
alter table 表名 rename to 新的表名;
2. 修改表的字符集
alter table 表名 character set 字符集名称;
3. 添加一列
alter table 表名 add 列名 数据类型;
4. 修改列名称 类型
alter table 表名 change 列名 新列别 新数据类型;
alter table 表名 modify 列名 新数据类型;
5. 删除列
alter table 表名 drop 列名;
- ALTER TABLE 表名 ADD 列名/索引/主键/外键等;
- ALTER TABLE 表名 DROP 列名/索引/主键/外键等;
- ALTER TABLE 表名 ALTER 仅用来改变某列的默认值;
- ALTER TABLE 表名 RENAME 列名/索引名 TO 新的列名/新索引名;
- ALTER TABLE 表名 RENAME TO/AS 新表名;
- ALTER TABLE 表名 MODIFY 列的定义但不改变列名;
- ALTER TABLE 表名 CHANGE 列名和定义都可以改变
在audit表上创建外键约束,其emp_no对应employees_test表的主键id


由于题目要求其emp_no对应employees_test表的主键id,所以才有下面的references employees_test(id)
创建外键语句结构
ALTER TABLE <表名>
ADD CONSTRAINT FOREIGN KEY (<列名>)
REFERENCES <关联表>(关联列)
查找字符串中逗号出现的次数


解析:把逗号去掉前后到长度差就是逗号到数目,LENGTH(replace(string, ',','')这个是去掉逗号的长度,不是把字符串中的逗号替换成空格
获取employees中的first_name


RIGHT函数它能返回从最右边开始指定长度的字符串。同理LEFT函数就是返回从最左边开始的指定长度字符串
按照dept_no进行汇总


聚合函数group_concat(X,Y),其中X是要连接的字段,Y是连接时用的符号,可省略,默认为逗号。此函数必须与GROUP BY配合使用。
此题以dept_no作为分组,将每个分组中不同的emp_no用逗号连接起来(即可省略Y)
平均工资
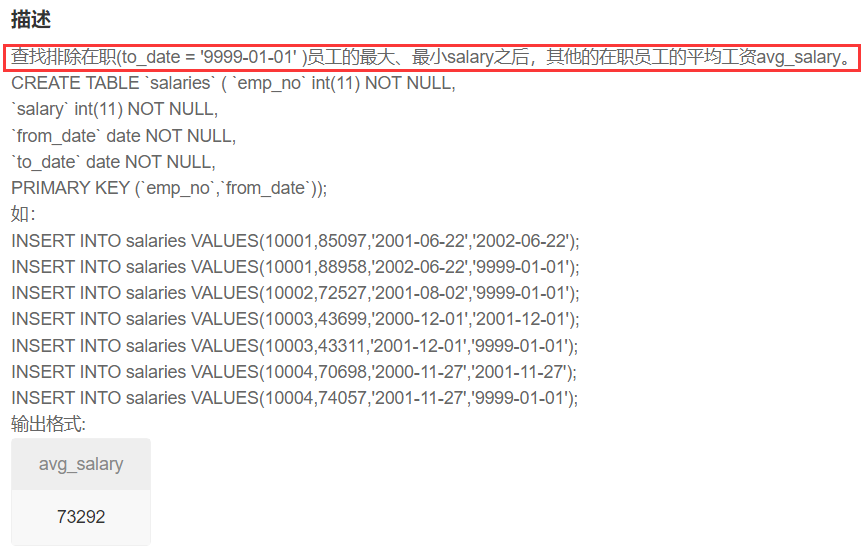
使用聚合函数,不用子查询,COUNT(1) 代表所有数据长度, -2 代表减去最大最小值的两个长

出现三次以上相同积分的情况

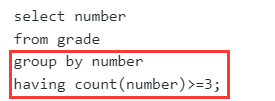
刷题通过的题目排名


找到每个人的任务


老是左右连接不知道用哪个,主要是没有彻底弄懂,A表左连接B表那么B表独有的字段可能会为null,A表右连接B表那么A表独有的字段可能会为null
牛客每个人最近的登录日期(二)


牛客每个人最近的登录日期(四)