中文评测基准
Awesome-Chinese-LLM:https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
该项目收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个!
C-Eval
C-EVAL: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models
论文地址:https://arxiv.org/pdf/2305.08322v1.pdf
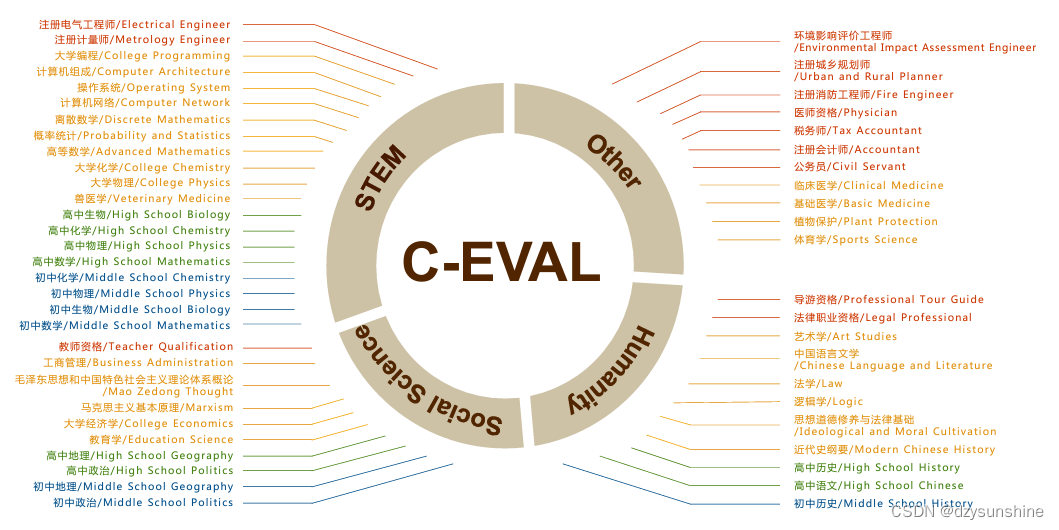
不同颜色的主体表示四个难度等级:初中、高中、大学和专业。
github地址:https://github.com/SJTU-LIT/ceval
C-Eval榜单是一个全面的中文基础模型评估套件(多层次、多学科的语文评价基础模型套件)。它由13948个选择题组成 问题跨越52个不同的学科和四个难度级别,测试集用于模型评估(简单来说就是针对中文模型的综合测试机)
C-Eval榜单地址:https://cevalbenchmark.com/static/leaderboard.html
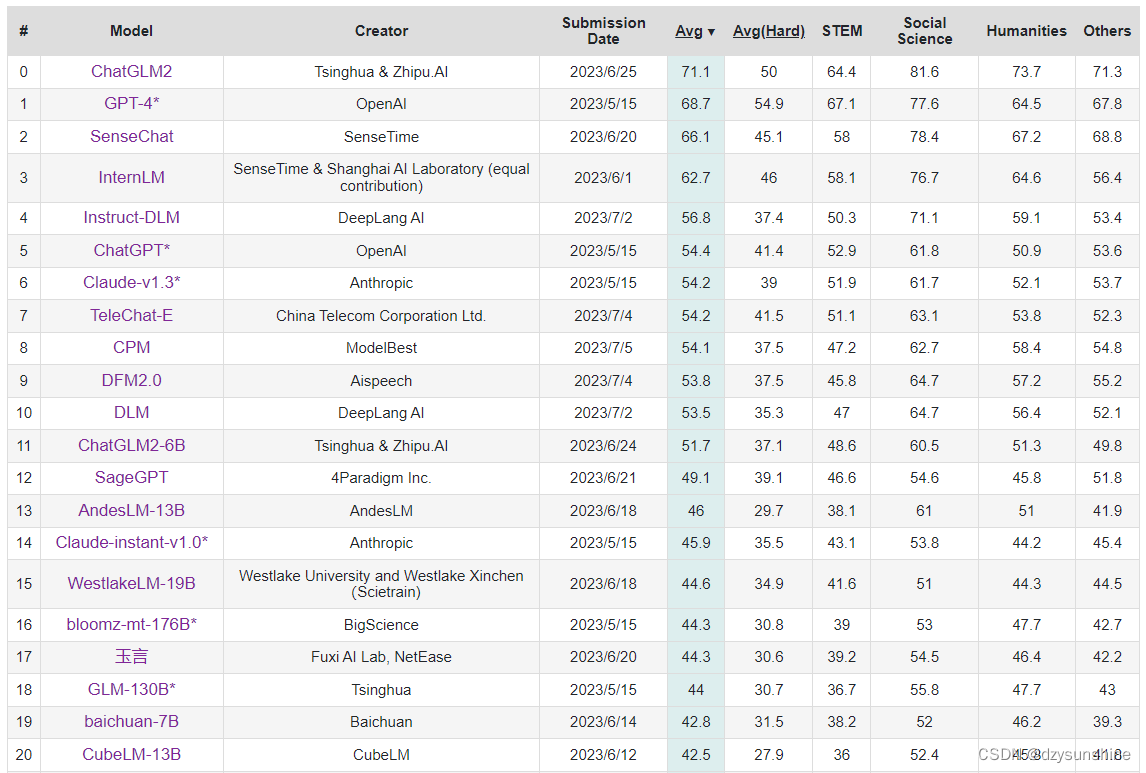
榜单是会实时发生变化的。
数据集地址:https://huggingface.co/datasets/ceval/ceval-exam
Gaokao
Evaluating the Performance of Large Language Models on GAOKAO Benchmark
论文地址:https://arxiv.org/abs/2305.12474
Gaokao 是由复旦大学研究团队构建的基于中国高考题目的综合性考试评测集,包含了中国高考的各个科目,以及选择、填空、问答等多种题型。
GAOKAO-bench是一个以中国高考题目为数据集,旨在提供和人类对齐的,直观,高效地测评大模型语言理解能力、逻辑推理能力的测评框架。
GAOKAO-bench收集了2010-2022年全国高考卷的题目,其中包括1781道客观题和1030道主观题,评测分为两部分,自动化评测的客观题部分和依赖于专家打分的主观题部分,这两部分结果构成了最终的分数。
github地址:https://github.com/OpenLMLab/GAOKAO-Bench
数据集
| 题目类型 | 题目数量 | 数量占比 |
|---|---|---|
| 选择题 | 1781 | 63.36% |
| 填空题 | 218 | 7.76% |
| 解答题 | 812 | 28.89% |
| 题目总数 | 2811 | 100% |
数据集包含以下字段
| 字段 | 说明 |
|---|---|
| keywords | 题目年份,科目等信息 |
| example | 题目列表,包含题目具体信息 |
| example/year | 题目所在高考卷年份 |
| example/category | 题目所在高考卷类型 |
| example/question | 题目题干 |
| example/answer | 题目答案 |
| example/analysis | 题目解析 |
| example/index | 题目序号 |
| example/score | 题目分值 |
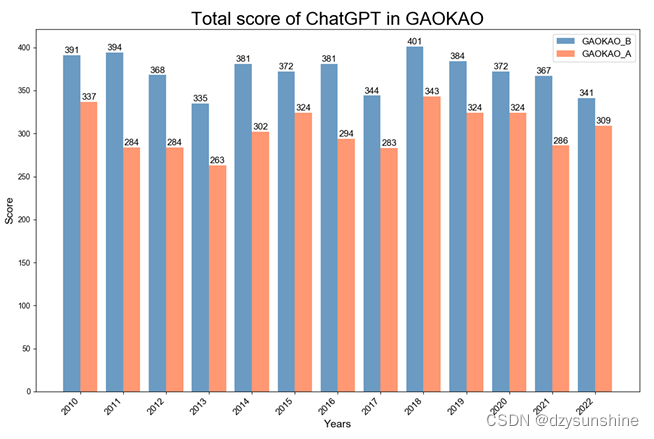
下图是gpt-3.5-turbo历年的高考得分,其中GAOKAO-A代表理科科目,GAOKAO-B代表文科科目。
AGIEval
AGIEval:AHuman-CentricBenchmarkfor EvaluatingFoundationModels
论文地址:https://arxiv.org/pdf/2304.06364.pdf
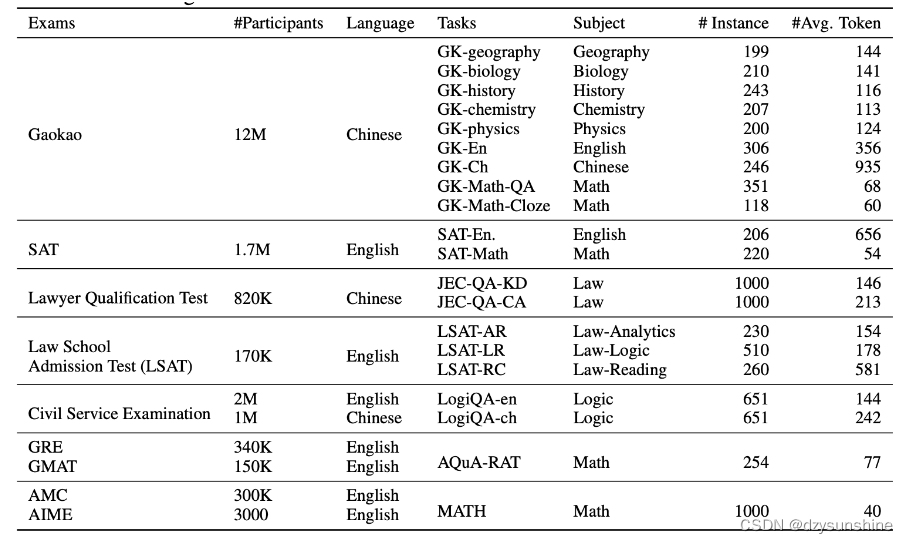
AGIEval 是一个以人为中心的基准,专门设计用于评估基础模型在与人类认知和解决问题相关的任务中的一般能力。该基准源自 20 项面向普通考生的官方、公开、高标准的入学和资格考试,例如普通大学入学考试(例如中国高考和美国 SAT)、法学院入学考试考试、数学竞赛、律师资格考试、国家公务员考试。
AGIEval v1.0包含20个任务,其中包括两个完形填空任务(高考-数学-完形填空和数学)和18个多项选择题回答任务(其余)。多项选择题回答任务中,高考物理和JEC-QA有一个或多个答案,其他任务只有一个答案。您可以在下表中找到完整的任务列表。
PromptCBLUE
PromptCBLUE: 中文医疗场景的LLM评测基准
github地址:https://github.com/michael-wzhu/PromptCBLUE
为推动LLM在医疗领域的发展和落地,华东师范大学王晓玲教授团队联合阿里巴巴天池平台,复旦大学附属华山医院,东北大学,哈尔滨工业大学(深圳),鹏城实验室与同济大学推出PromptCBLUE评测基准, 对CBLUE基准进行二次开发,将16种不同的医疗场景NLP任务全部转化为基于提示的语言生成任务,形成首个中文医疗场景的LLM评测基准。PromptCBLUE作为CCKS-2023的评测任务之一,已在阿里巴巴天池大赛平台上线进行开放评测。
英文评测基准
MMLU
Measuring Massive Multitask Language Understanding
论文地址:https://arxiv.org/abs/2009.03300
MMLU 是包含 57 个多选任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,是目前主流的LLM评测数据集。
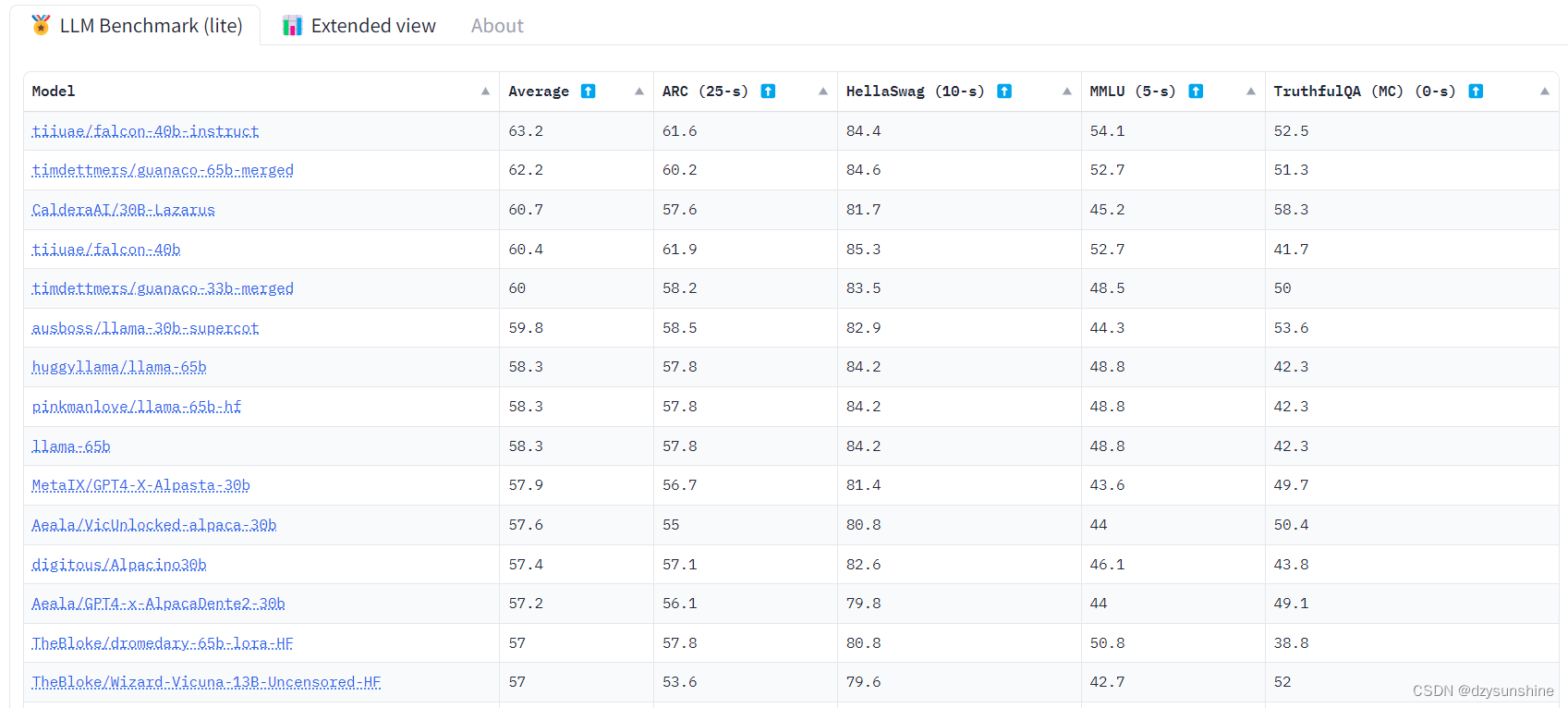
Open LLM Leaderboard
Open LLM Leaderboard是由HuggingFace组织的一个LLM评测榜单,目前已评估了较多主流的开源LLM模型。评估主要包括AI2 Reasoning Challenge, HellaSwag, MMLU, TruthfulQA四个数据集上的表现,主要以英文为主。
榜单地址:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard