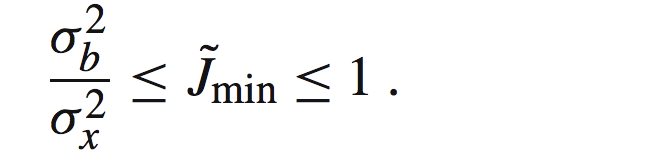昨天讲了关于信号模型的,其作为维纳滤波器的铺垫。今天正式开始维纳滤波器的讲解,今天的讲解我会按照《Springer-handbook-of-speech-processing》中的来进行。这本书是我目前见到的市面上对于语音处理方面讲解最全面的,我推荐大家去看一看。直奔主题:
1 维纳滤波器
为了方便起见,这里我们使用SISO模型,同时我们给出一个重要的假设:观测信号x(k)和随机噪声b(k)(与源信号相互独立)是零均值的并且是稳态的(关于稳态可以查看随机过程进行了解)。那么接下来进入我们的维纳滤波器的推导环节,通过我在第一节讲的内容,我们知道如下的SISO模型公式:
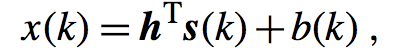
也就是说如果我们通过估计h,一般采用取均值的方式,而b是零均值的,所以我们估计出来的x中只包含后面的第一项。那么实际得到的观测信号与我们估计出来的估计信号的差就是其中的误差,其式子如下:
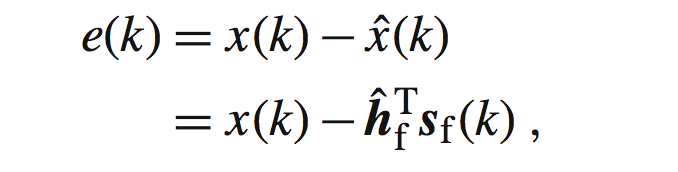
其中:
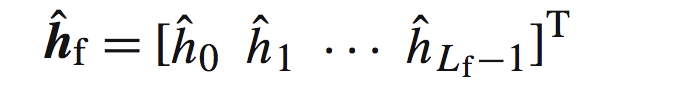
他是估计出来的长度为Lf的h,并且:
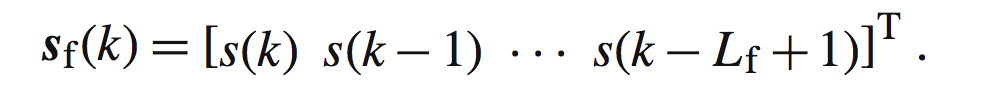
那么接下来我们需要找到一个代价函数,使之最小化来得到最优的滤波器,也就是最接近真实h的h估计。很明显让估计误差e最小化能达到我们的要求,那么我们要根据e设计代价函数。一般这种情况下我们需要使用一种准则,基于这种准则来进行优化。常见的有:MMSE,MSE,最大信噪比,最大似然等等。你可以把准则理解为一种运算规则,按照这种规则进行接下来的计算。我们这里使用MSE(mean square error均方误差)。代价函数如下:
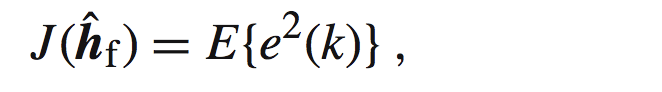
这里的E是求期望的意思(不明白期望的去看概率论,大学应该学过)。这里注意,如果J看成是一个函数,他的自变量是h估计(以后称之为h_hat),当h_hat变动的时候,会产生一个e,然后得到一个J的值,以此来评判我们的J的值在如何变化,理想情况当然是J=0(自己想为什么).如果大家对于梯度有所了解的话,可以想到,最有维纳滤波器是通过如下得到的:
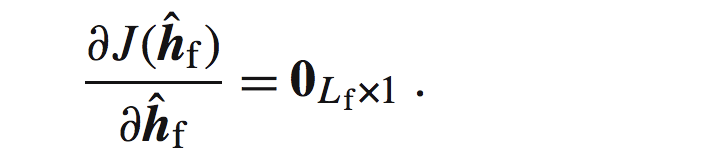
把式子左边部分进行展开:
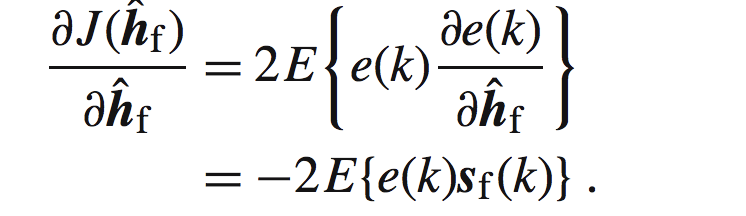
那么可以得到后半部分为0,即:
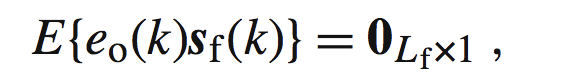
我们知道e的表达式如下:
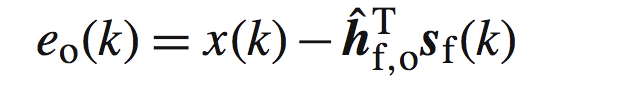
同时我们假设最优的观测信号估计为:
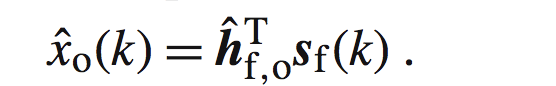
那么通过带入我们可以得到:
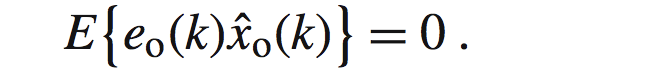
以上的就叫做:正交准则推论。很简单,因为不相关,在向量意义上的表现就是相互垂直。
接下来,我们把e0的表达式带入推导出的式子,得到wiener-Hopf方程:

其中:
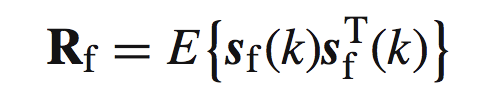
注意这里用的R,表示relation,这个表达式是关于sf的相关矩阵(这里容易与协方差矩阵搞混,记住,在零均值情况下,协方差矩阵和相关矩阵是相同的)。而pf:
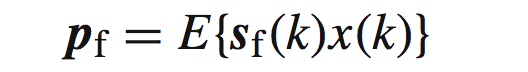
这个就是传说中的互相关矩阵。接下来我们给出Rf的矩阵形式:
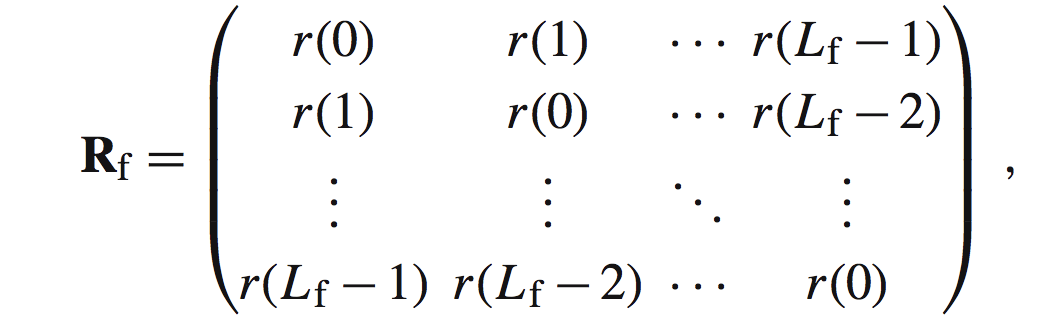
其中:
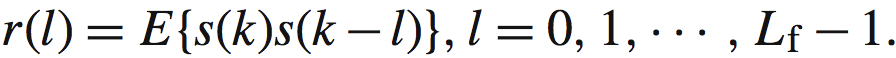
仔细看Rf,有很多矩阵上的特点,包括Toeplitz矩阵等等,不一一说明(此处用处不大)。原文指出:即使对于次稳态的语音信号(我了解的其他资料都称语音为非稳态),矩阵也常常是正定的。当然也有出现误差的情况出现。
有人问了,你费半天劲讨论正定有啥用处,同学你很上路,正定->非奇异->可逆,所以我们能够对上面的式子进行左乘Rf^-1,也就是Rf的逆。得到如下:
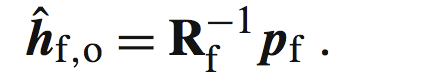
我们把误差e的表达式带入得到:
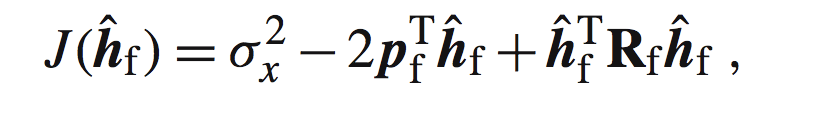
其中等号右边的第一个表示协方差,当均值为0的时候,也就是E{x(k)^2}。通过维纳滤波器的思想,我们这里使用MMSE准则,来获取最优维纳滤波器。也就是当我们的hf为hf,0的时候,如下:
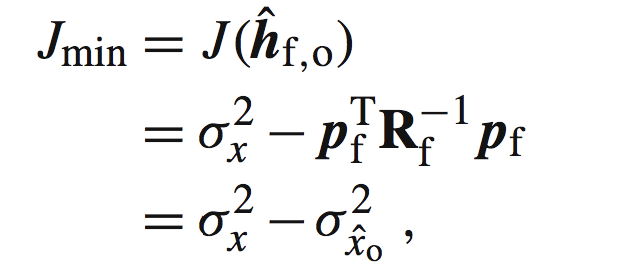
其中:
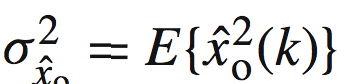
他是最优维纳滤波器的输出。
把x的生成模型带入:
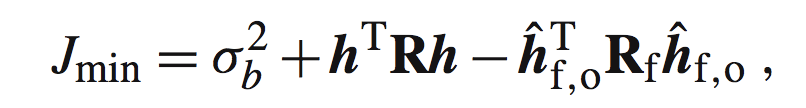
其中:

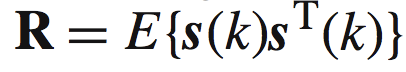
这里我们的代价函数是有边界的:
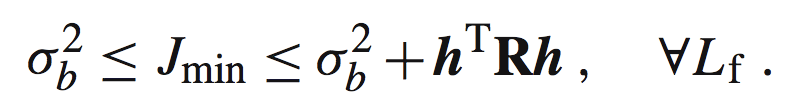
基于上面,我们可以得到NMMSE(normalized MMSE)如下:
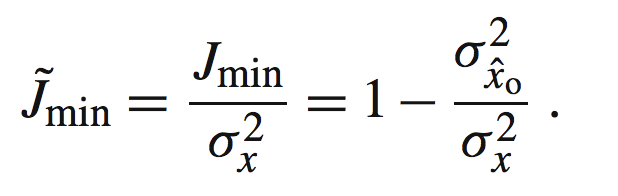
一个归一化的过程。同时边界为: