NLP学习笔记十一-skip-gram模型求解
上一篇文章,我们见到了skip-gram模型的原理,这里我们在陈述一下skip-gram模型其实是基于分布相似性原理来设计的,在skip-gram模型中,他认为一个词的内涵可以由他的上下文文本信息来概括,,那么基于这个原理,skip-gram模型设计了两个矩阵,一个是词向量表征矩阵,也就是这个向量中每一行代表了一个词的嵌入向量,也就是表征信息,又设计了一个表示词语在上下问中做背景词是的表征矩阵,在这个矩阵中每一行,表示一个词语做上下问词语时自己的表征信息。当一个词作为中心词,在乘以背景词表征矩阵,经过softmax处理,会得到一个向量,这个向量元素之和为1,向量长度为词语集合类别数,每个元素的值代表一个词语被选择的概率。当我们输入一个词语序列,我们会根据该词语序列计算2m次概率向量,因为窗口大小为m,也就是输入了2m个上下文词语,此时我们需要做的就是对两个矩阵进行更新,假设输入中心词的表征向量为 w I w_I wI,输入上下文文本词语的表征向量为 w O , 1 , w O , 2 , w O , 3 , , , , , , w O , C w_{O,1},w_{O,2},w_{O,3},,,,,,w_{O,C} wO,1,wO,2,wO,3,,,,,,wO,C。
C=2m
那么此时损失函数如下:
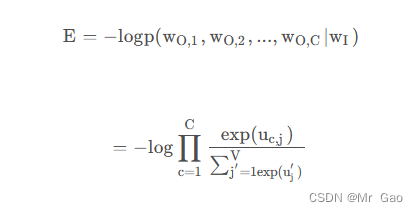
这里很多人可能会疑惑,为什么是这样的所示函数,这里大家要注意啊,skip-gram模型是忽略位置信息影响的,也就是说skip-gram模型,他认为上下文中出现的词语,都是同等的概率出现的,也就是说,出现一个中心词,那么它可能对应出现的其实不是上下文文本信息,而是一个上下文词语集合,且集合中的词语没有相关性,那么就会得到上面一个公式,因为上下文词语没有位置顺序,没有相关性,那么
联合和概率就可以直接拆分:
如下:
P(a,b|c)=P(a|c)*P(b|c)
就是上面这个公式体现的原理。
然后就是使用BP算法求导更新中心词的表征向量为 w I w_I wI,和上下文文本词语的表征向量为 w O , 1 , w O , 2 , w O , 3 , , , , , , w O , C w_{O,1},w_{O,2},w_{O,3},,,,,,w_{O,C} wO,1,wO,2,wO,3,,,,,,wO,C。
下面我们开始推到,并介绍相关概念:
首先看下面一个图片,下面图片其实就是得到中心词语的表征向量h,注h就是中心词的表征向量,大家要记住哈。后面还要用到。

再看下面一张图片: s j s_j sj就是中心词的表征向量h乘以背景词的表征向量 v w j v_{w_j} vwj得到的值,经过softmax转化就会变成对应背景词可能被选择的概率。
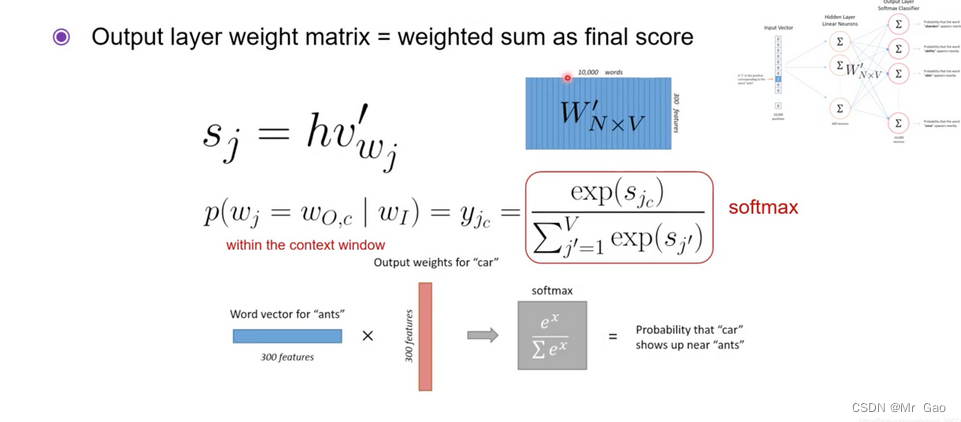
那么根据之前所说损失函数则就是下面这个表达式:

背景矩阵和中心词矩阵更新公式如下:


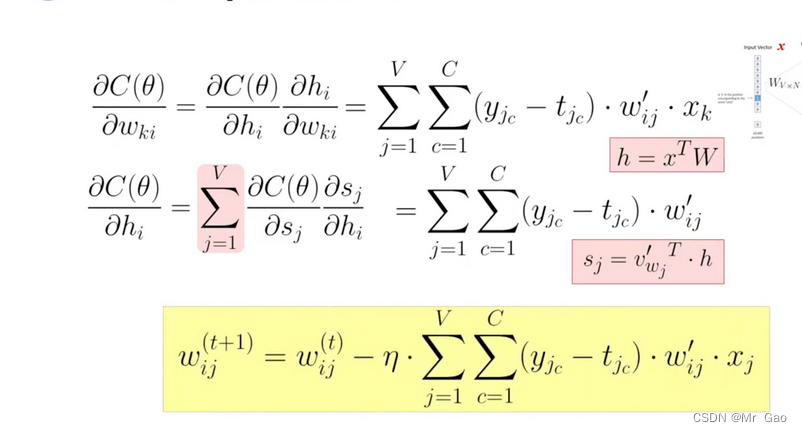
上面两个公式博主也推到了一下,确实是这样哈,就是正常推到就可以了。