————————————每一个不曾起舞的日子都是对生命的辜负。

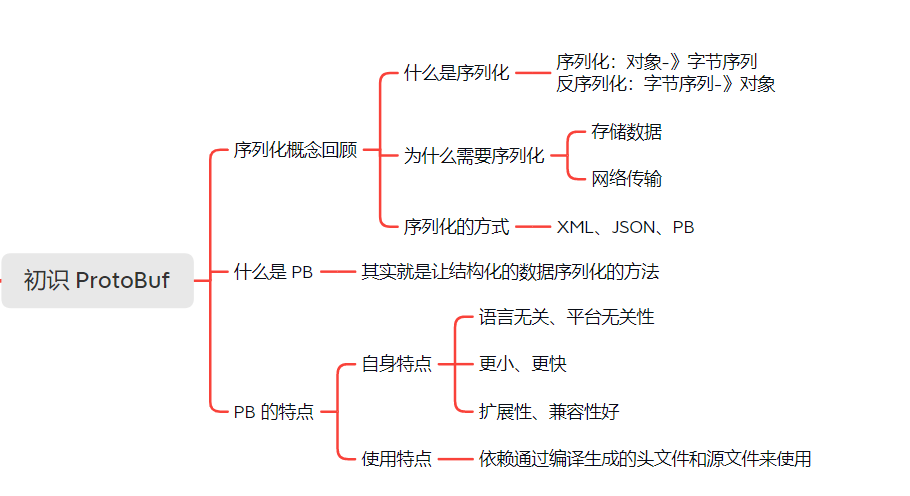
一. 序列化概念
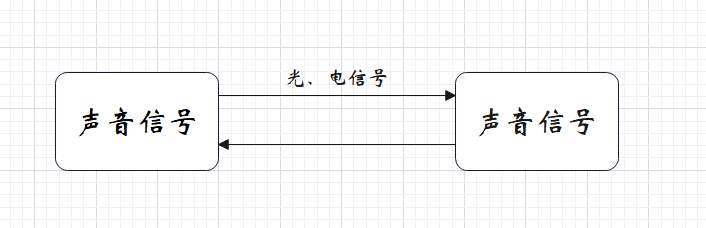
日常生活中,手机上收到的语音消息在网络中不能直接进行传输,而是通过一系列的信号,比如网络中二进制序列的转换,在传出时将语音消息转化成二进制序列进行网络传输,收到消息时再将二进制序列转化成语音消息,这种过程实际上就是序列化。
我们写的代码同样如此,网络中传输的也一定不是直接创建的对象,而是通过对象转换的二进制序列进行传输。将对象转化为二进制序列的过程称为序列化过程,最后将二进制序列恢复为对象的过程称为反序列过程。

由此可见,上述所说的都是在网络传输中使用。而在本地中,内存中的结构化数据也就是对象只有序列化才能放到文件里面去,这个过程同样需要序列化。此外,数据库、缓存等传入传出同样涉及序列化。
- 所以什么是序列化和反序列化?
序列化: 把对象转换为字节序列的过程,称为对象的序列化。
反序列化: 把字节序列恢复为对象的过程?称为对象的反序列化。
- 如何实现序列化?
通过Json、XML、ProtoBuf可以实现序列化。(本文讲的就是ProtoBuf)
二. ProtoBuf
1. 什么是ProtoBuf
ProtoBuf概念:将结构化数据进行序列化的一种方式。
2. ProtoBuf的特点
简单来讲,ProtoBuf(全称为Protocol Buffer)是让结构数据序列化的⽅法。
一. 本身特点:
- 语⾔⽆关、平台⽆关:即ProtoBuf⽀持Java、C++、Python等多种语⾔,⽀持多个平台。
- ⾼效:即⽐XML和Json更⼩、更快、更为简单。
- 扩展性、兼容性好:你可以更新数据结构,⽽不影响和破坏原有的旧程序。
二. 使用特点: ProtoBuf是需要依赖 通过编译生成的头文件和源文件 来使用的。(针对C++来说)
在定义类时,需要进行三件事情:
- 定义一系列属性字段。
- 处理字段的方法:如get、set。
- 处理类的方法:序列化和反序列化(还有其他方法不一一列举)
对于开发者来说,定义属性字段比较简单;而另外两种方法的编写,都属于费力不讨好的活,比较耗时)
3. ProtoBuf进行序列化反序列化的流程
在ProtoBuf中,将类(class)称之为消息(message)

依赖通过编译生成的头文件和源文件实际上就是通过message XXX生成class XXX,并且class XXX在生成时会被打散,生成源文件和头文件。
具体逻辑:
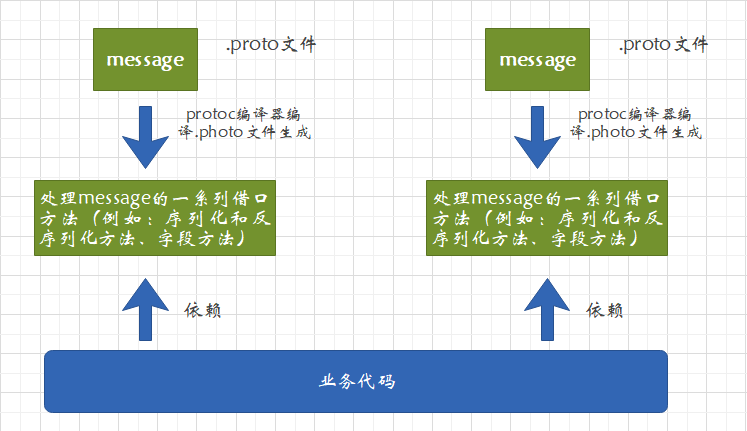
- 编写.proto文件,目的是为了定义结构对象(message)及属性内容。
- 使用photoc编译器编译.proto文件,生成一系列接口代码,才能放在新生成头文件和源文件中。
- 依赖生成的接口,将编译生成的头文件包含进我们的代码中,实现对.proto文件中定义的字段进行设置和获取,和对message对象进行序列化和反序列化。
总的来说:ProtoBuf是需要依赖通过编译⽣成的头⽂件和源⽂件来使⽤的。有了这种代码⽣成机制,开发⼈员再也不⽤吭哧吭哧地编写那些协议解析的代码了(⼲这种活是典型的吃⼒不讨好)。
三. 本章总结