前言
1.Hash取模算法常被用于分布式缓存集群系统,一般分三种,普通hash取模,一致性hash,Hash槽。
2.使用场景:假设现在有一个用户注册系统,用户数量会不断的增大,需要几个服务器共同存储。
一、普通Hash取模
1.先创建4个服务器(canister),然后对注册的用户id hash之后取模,例如果用户的id是"matt",先对“matt”做hash计算,假设得到值是17,拿这个hash对canister 个数进行取模:17 % 4 = 1,那么这个“matt”的用户就被分配到canister 1进行储存。再来一个用户,重复上一步骤,hash后得到23,那么取模后,分配到canister 3上,访问时也一样,先hash后求余数,再去对应的canister里面读取数据。

2.使用这种hash取模数算法有一个问题是,当4个canister都满了,如果想增加多一台canister,那么之前的关系就会被全部打乱,就代表着,存储过的数据通过hash索引就找不着位置了。只能全部迁移数据,重新建立关系。

二.Hash ring
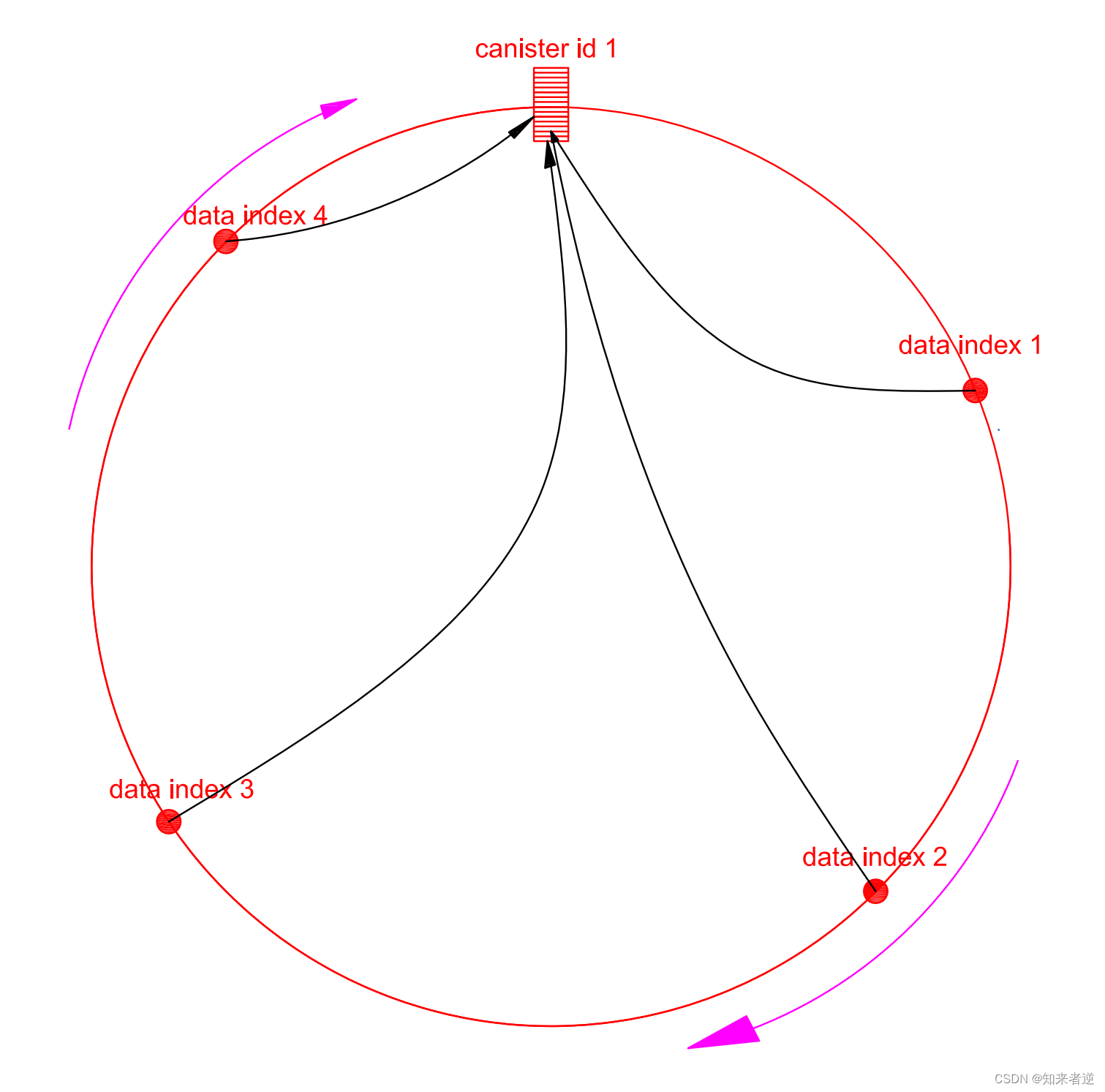
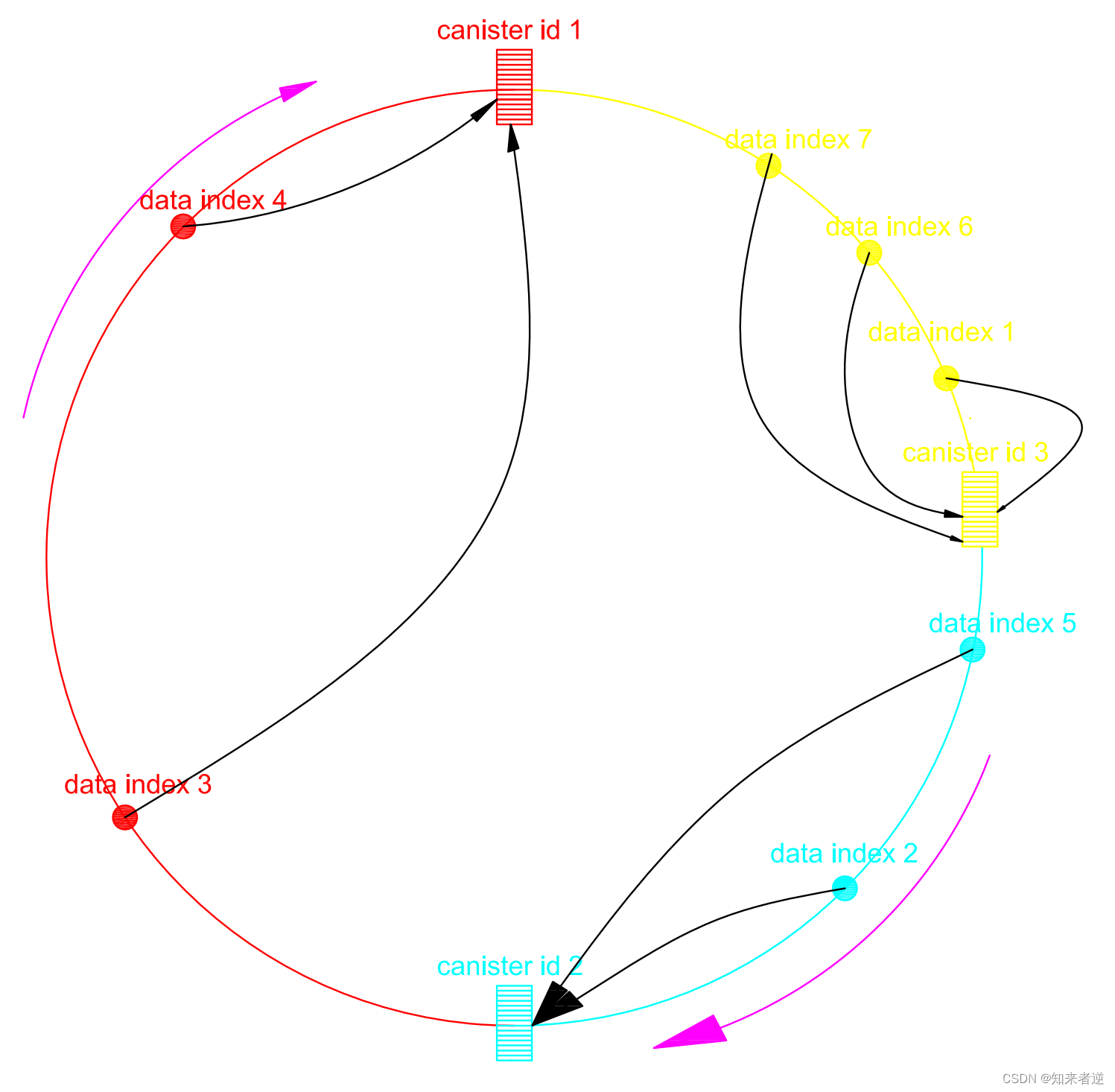
1.Hash 环可以解决动态扩容的问题,首先,在初始化的时候创建一个用户Canister,把Canister id 映射到Hash环上(Canister id Hash对2的32次方取余),然后把当前用户的ID的也映射到这个Hsah 环上(ID Hash 后对2的32次方取余)。当前只有一个Canister 1,那么所有Hash 环上映射的用户顺时针都找到该Canister里面。
如下图:
2.当Canister 1储存达到额定的容量的时候,动态创建一个Canister 2,也把Canister 2的ID hash后也映射到Hash环上,这时,Hash环上顺时针存储规则就要重新定义。
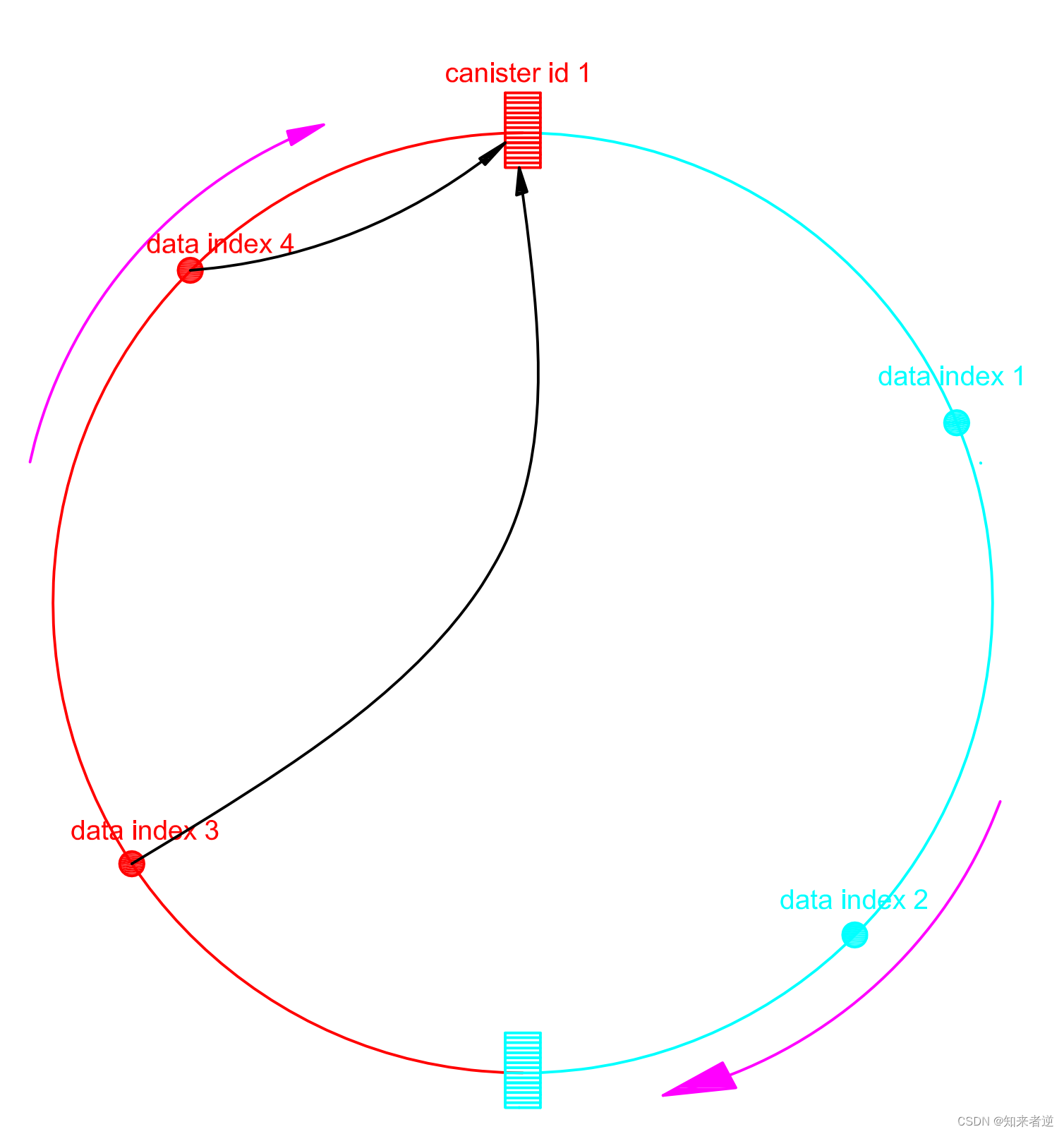
3. 这时要对所有存储的ID 进行计算,每个ID在计算Hash后会顺时针找到临接的存储节点存放。
这里会引起数据迁移,当只有一个Canister的时候,ID Hash 后顺时针所有临接点都是Canister 1,现在插入了Canister 2,那么原本存储在Canister 1里面的data index 1和data index 2就要迁移到Canister 2里面,这样在查询ID才能找到对应的Canister。
在查询数据时,也是按照PID hash后顺时针去找到临接的Caniste。
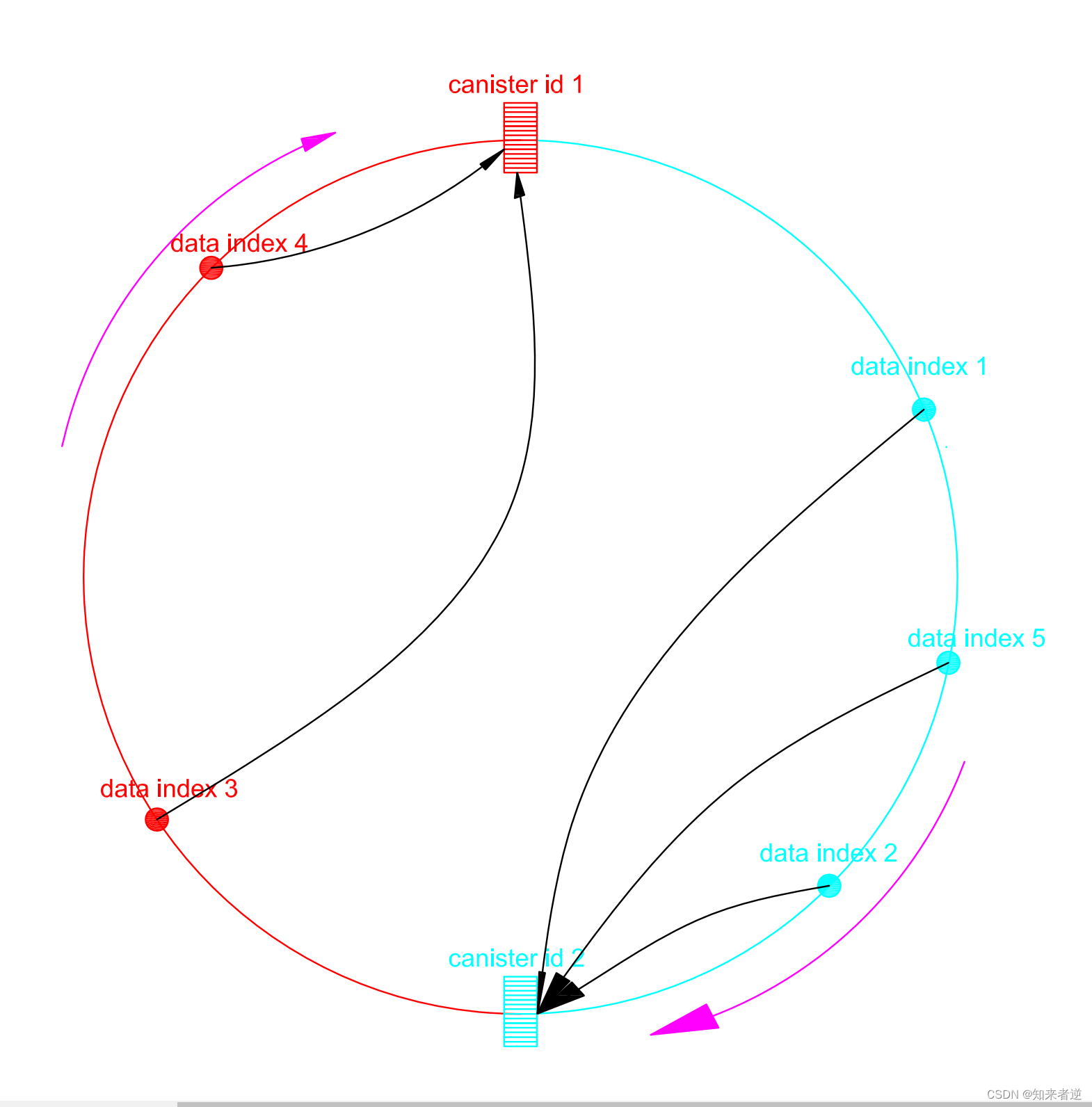
3.当Canister 2达到额定的容量时,再动态创建Canister 3,映射到Hash环上,重复上面的步骤对数据进行迁移。这样,每次在新增一个Canister之后,只会引起小量的数据迁移。如果下图,当增加了Canister后,把原本属于Canister 2的data index 1迁移到新新创建的Canister 3上,就能保证Hash环的插入和查找不会错乱。
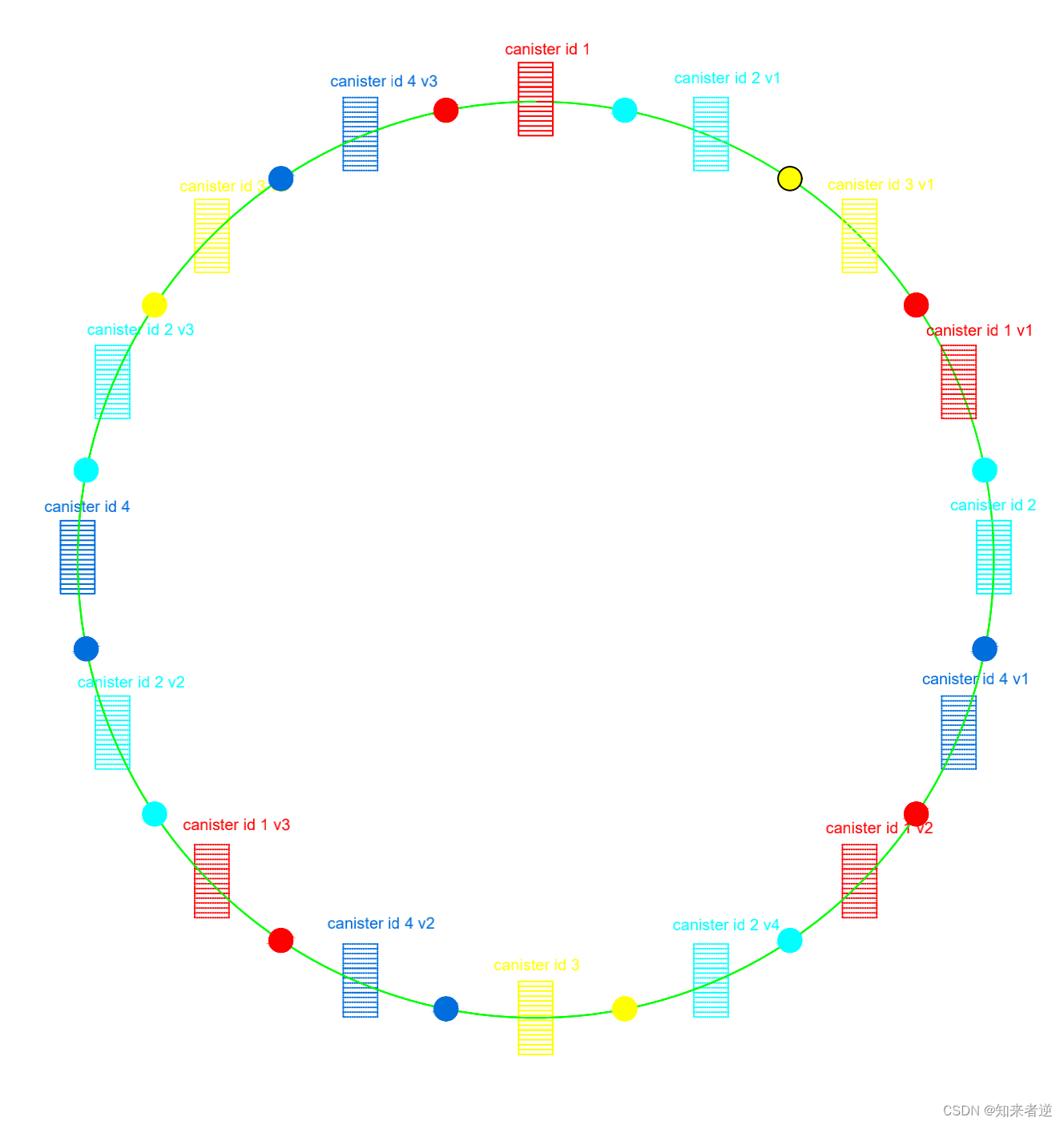
4.hash ring会出现一个问题是,hash倾斜,就是某个canister获取的顺时针很大,某个却佷小,就会出现,有的canister 存了很多数据,有的却没有存到多少数据,为了避免这个问题,就要建立很多个虚拟节点,来均分hash环的空间,虚拟节点所对应的数据再映射到真实节点上,以达到均分的效果。
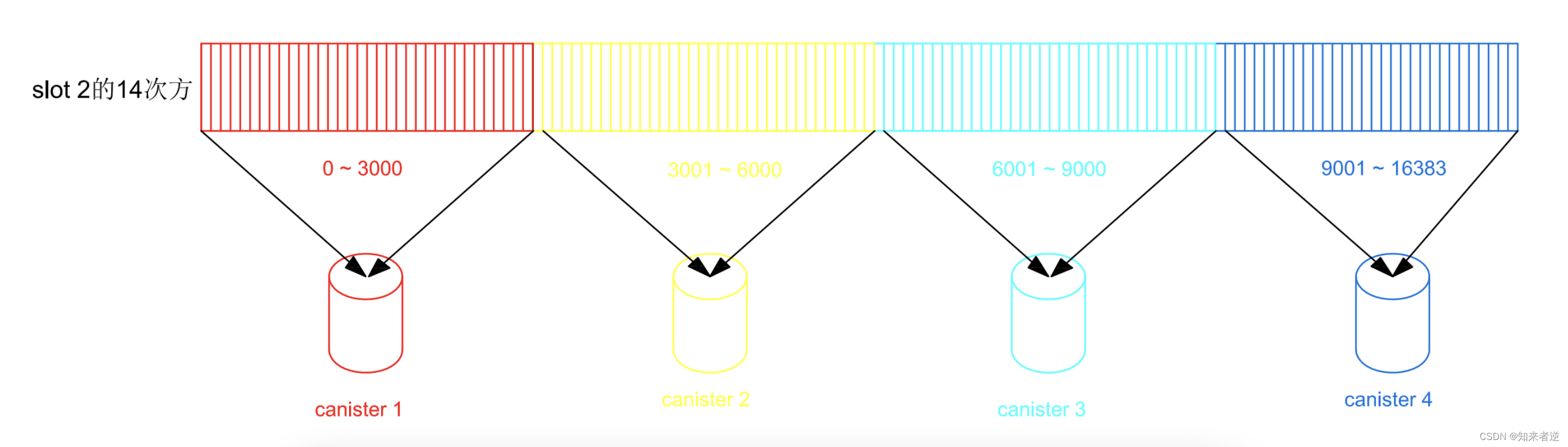
三、Hash slot
1.hash 槽的原理跟hash ring差不多,只是hash 槽在初始状态下就确定了映射,Hash 槽计算方式:crc16(ID)% 16383 ,然后对应hash槽上的映射关系存储数据,当取模的值小于3000的时候,ID存储在canister 1上,当值大于30001并小于60000的时候,存储在canister 2上,以类推。
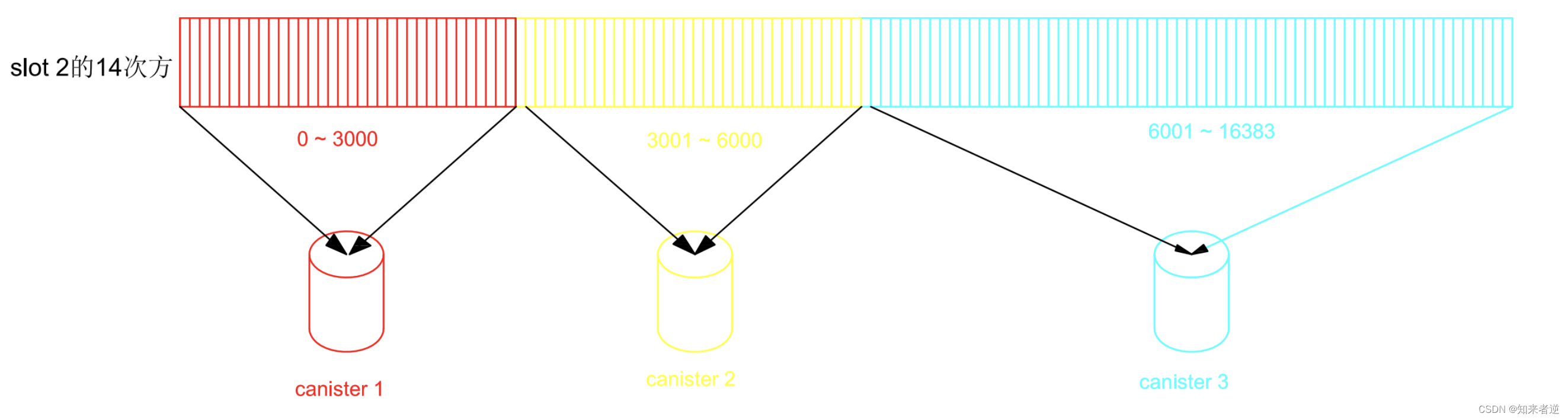
2.新增canister 时,重新调整映射表,然后把数据迁移到对应的canister 上就可以了,hash slot 理论上出现hash倾斜的概率要小于hash ring.