目录
一、requests模块发送post请求
1.实现方法:requests.post(url, data) data是一个字典
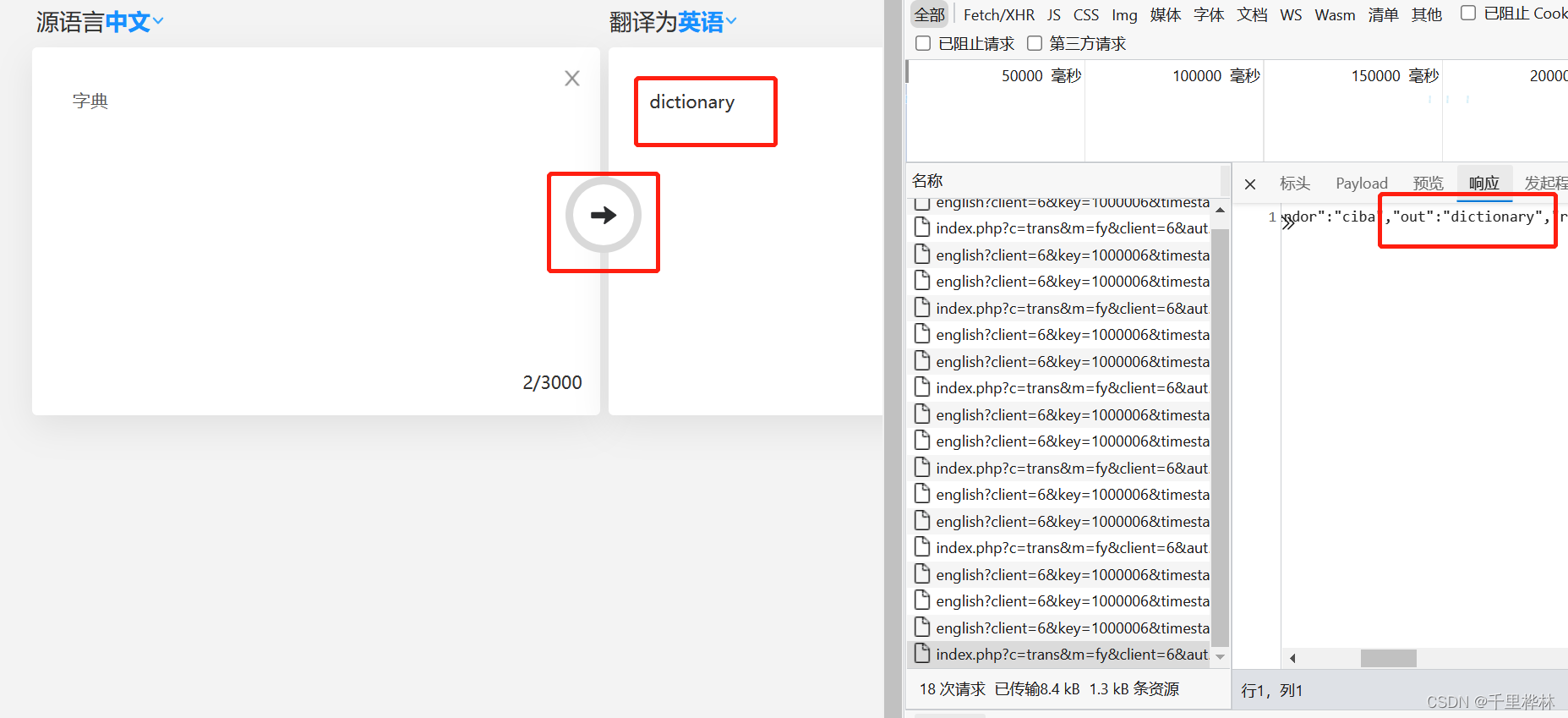
2.使用金山词霸网页作为例子。
输入“字典”二字,会翻译出dictionary,在检查页面的响应里面也可以看到“out”:dictionary。
 3.再使用json解析网页(json.cn)
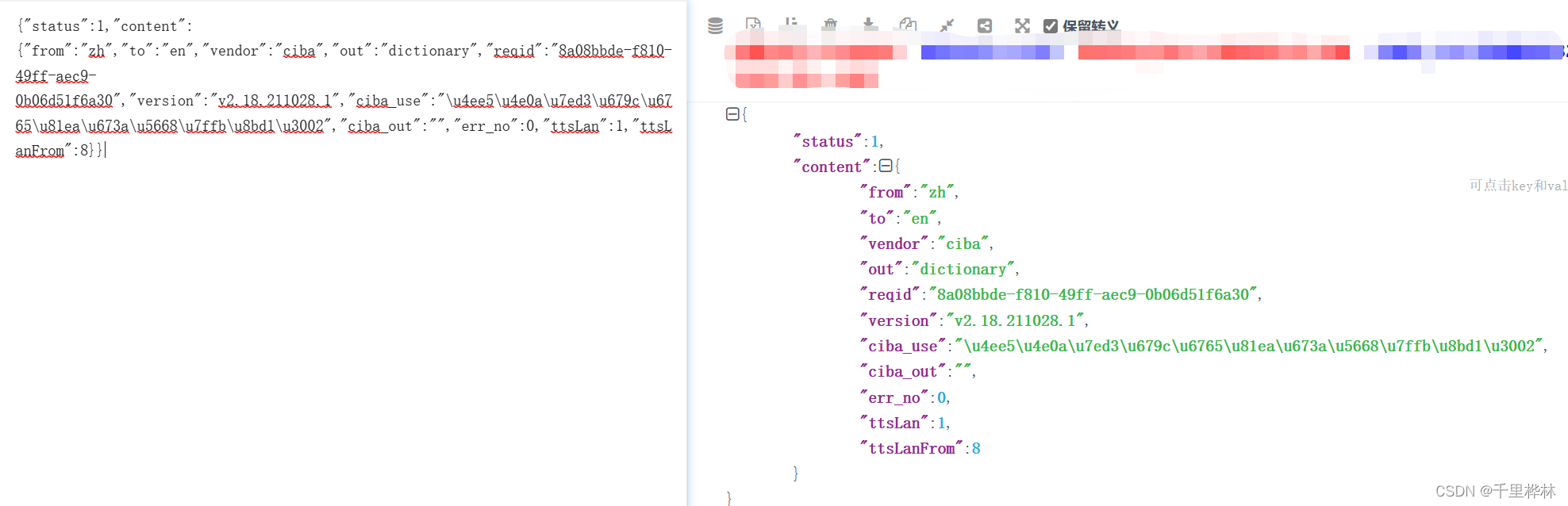
3.再使用json解析网页(json.cn)
将刚才看到的响应里面的句子粘贴到 json解析网页,‘content’里面的“out”对应的就是我们要的dictionary
二、post数据来源
1.固定值 抓包不变值
2.输入值 抓包比较根据自身变化值
3.预设值——静态文件 需要提前从静态html中获取
4.预设值——发请求 需要对指定地址发送请求获取数据
5.在客户端(浏览器)生成的 分析js,模拟生成数据
三、request模块——session(利用session进行状态保持)
session类能自动发送请求获取响应过程中产生的cookie,进而保持状态。
1.session的作用及应用场景
作用:自动处理cookie:下一期的请求会带上前一次的cookie
应用场景:自动处理连续的多次请求过程中产生的cookie
2.session使用方法
session = requests.session()
response = session.get(url, headers, …)
response = session.post(url, data, …)
session对象直接发送get和post请求的参数,与requests模块发送请求的参数一致。
四、数据提取——响应内容的分类
1.结构化的响应内容:找到url,在网页中直接搜索就可以拿到数据了。
(1)json数据(高频出现,数据承载量大一些):json模块、re模块、jsonpath模块
(2)xml数据:re模块、lxml模块
2.非结构化的响应内容:每篇文章结构变化(比如段落数不一样等)
(1)html(最常用):re模块、lxml模块
五、xml和html
1. xml
可扩展标记语言。
与html区别:
(1)功能专注于传输和存储数据。
(2)标签可以自行定义。
2. html
超文本标识语言。
功能:显示数据及如何更好地显示数据。
六、遇到的问题/tips
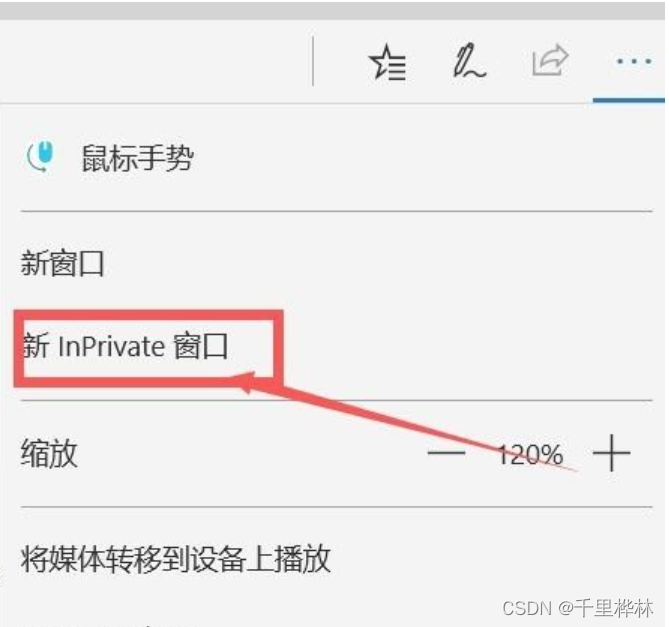
1.如何进入无痕模式
2.在检查页面查找Ajax数据
