一、写时复制技术
fork()生成子进程时,只是把虚拟地址拷贝给子进程,也就是父进程占有的内存的地址,而不是真的给子进程开闭新的内存空间;也就是刚fork()完的时候,父子进程是指向同一块内存的,而且是虚拟地址和物理地址的映射关系,也是拷贝的父进程的。
只有对于父/子进程内存的某些发生了修改的页,比如下图中的页Z,子进程修改了该页内存里的内容,那么就要给子进程分配新的一页Z’,它里面的内容就不再是父进程原先的内容而是保存了修改之后的内容,后面子进程就可以在这个内存页上写自己的内容。
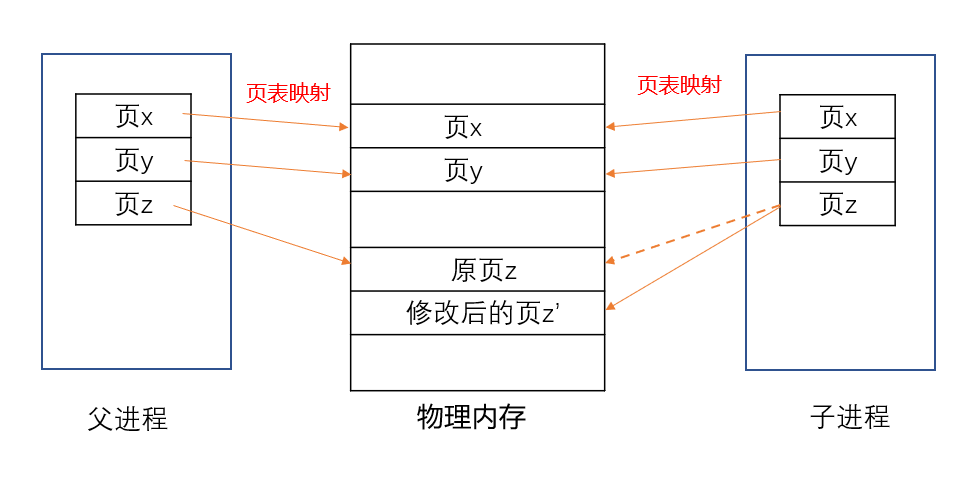
这个机制叫内核的“写时复制”
整个过程就是:
(1)创建子进程时,将父进程的 虚拟内存 与 物理内存 映射关系(即页表)复制到子进程中,并将内存设置为只读(设置为只读是为了当对内存进行写操作时触发 缺页异常)。缺页异常就是根据这个虚拟地址去找物理地址的时候发现该地址此时不在内存上,则需要从磁盘中将该页换入。
(2)当子进程或者父进程对内存数据进行修改(写操作)时,便会触发 写时复制 机制:将原来的内存页复制一份新的,并重新设置其内存映射关系,将父子进程的内存读写权限设置为可读写。
写时复制的优点:
由上面可以看出,创建子进程的时候,不需要把父进程的每一页都复制,都开辟内存给子进程,这样不仅是创建子进程的速度加快了,而且也减少了物理内存的浪费(因为子进程不一定要用父进程那么多内存呀)
vfork()和fork()
vfork()是fork()之后出现的,但是那会的fork()没有写时复制,也就是当时创建子进程时要把父进程拥有的内存都复制一份,开辟新内存保存这份数据,再给子进程映射起来,这样就很耗时而且浪费内存,于是有了vfork(),想着加速创建进程的过程。
vfork()创建子进程,不复制父进程的页表:
(1)直接让子进程完全就共享父进程的地址空间(像个进程中的进程),子进程运行在父进程的地址空间里,那么子进程对里面的数据的修改,也能被父进程看到;
(2)地址空间都共享,那堆栈也共享,这样是容易出问题的。子进程执行完一个函数,栈要弹出,那么父进程的栈也收到影响。或者说,整个子进程结束,这个栈是要释放的,那父进程的栈也被释放了,父进程还怎么正常执行相关函数调用。
(3)vfork()创建出子进程后,子进程会被确保首先执行,父进程被阻塞,直到子进程拥有了自己的地址空间(调用exec())或子进程退出了(exit())
后来fork()引入了写时复制技术,那么vfork()的优势就仅仅是不用复制父进程的页表了,速度上优势不大,反倒还容易产生很多问题,于是就很少用了。
二、fork()原理初步
由写时复制机制就可以看出,fork()创建子进程的实际开销就是:复制父进程的页表(虚拟地址和物理地址的映射关系) + 给子进程创建唯一的PCB(Linux里即是task_struct结构体)。其实还要给每个新进程开辟一个内核栈,后面会说到。这里就相当于把开辟内核栈的时间开销合起算在开辟PCB上,毕竟两个是一起创建的。
task_struct中有个指针会指向页表。
再理解下页表与多进程在内存中的图像
每个进程的页表都不一样,页表用于将虚拟地址映射到物理地址。不同的进程有不同的虚拟地址空间,因此它们的页表也不同。
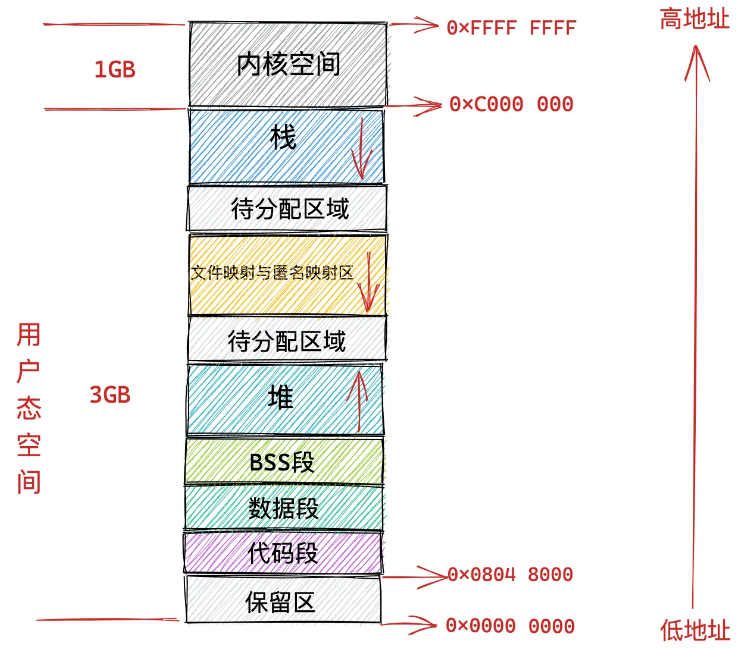
很容易理解:先不管共享的内核空间的话,因为每个进程都有独立的地址空间,那么每个进程的地址空间都是从低地址0x000 0000到栈底的0xc000 000,如果每个进程的页表都用同一个,那逻辑地址一样,物理地址不就也一样了吗,这样就冲突了。所以每个进程的页表肯定要不一样,这样才不会使得多个进程同时抢占物理内存的同个一区域。
而且实际上,每个进程看似自己占用了完整的地址空间(0x0000 0000 - 0xFFFF FFFF)或者说整个内存,其实他们往往只是占用了物理内存的一小部分,比如下面:
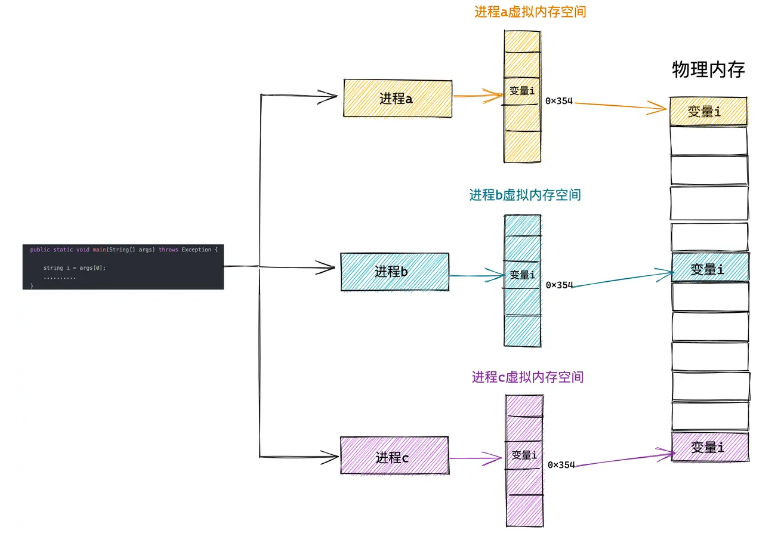
图源:小林coding
这利用的是局部性原理,即使进程a、b、c里定义了4GB的变量,这些变量又不会同时被使用,而且根据局部性原理,只有一小部分变量会经常被使用,比如上面的变量a_i,b_i,c_i,那么他们被使用的时候再换入内存中,这样只需要三块小的内存就能同时运行三个进程。如果每个进程的页表都一样,那么上图中就会使得a, b,c的变量i都存放在物理内存的同一块地方,造成冲突!
局部性原理的使用可以使得物理内存同时运行多个进程,但CPU对进程的切换调度才是进程真正在运行时的图像,即同一时刻CPU只能运行一个进程,进程运行时的状态或者说上下文,是记录在CPU的寄存器里的,当该进程被切换后,这些上下文就得从寄存器中复制到进程的PCB里的相应字段里,这个就是所谓的保存现场信息。
现在,我们知道tack_struct里除了有指向页表的指针,还有相应变量存储了进程在CPU中的现场信息。
此外,对于每个进程的虚拟地址空间,task_struct里面有一个结构体mm_struct专门指向虚拟地址空间的各个内存段:栈、映射区、堆、BBS段、数据段、代码段。下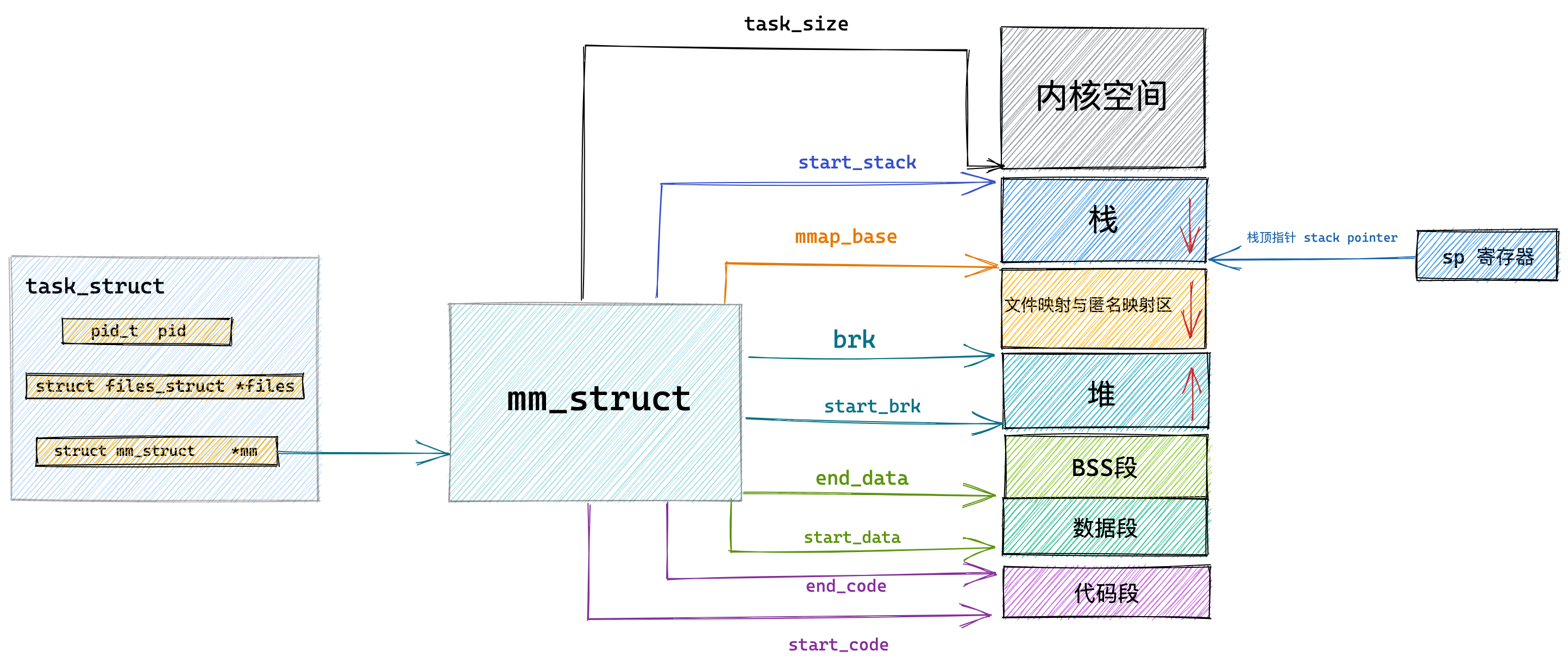
图源:小林coding
task_struct的字段除了上面所说的,还有下面一些:
(1)task_struct还得包括进程的pid吧,这样才能标识这个进程;而且线程既然也是用task_struct描述的话,那还得有个标识,这个就是tgid(tg是线程组thread group),那子进程和父进程pid不一样,子线程和主线程pid也不一样(并不是之前以为的pid一样,这个时候pid就理解为线程id了而不是进程id),但tgid是一样的,就是用tgid标记出这俩属于同一个进程的不同线程。那创建进程的时候,自然是pid和tgid都不一样。
这里顺便提下创建进程和创建线程的区别。
创建进程和创建线程的区别
其实这两下面是同一个系统调用:
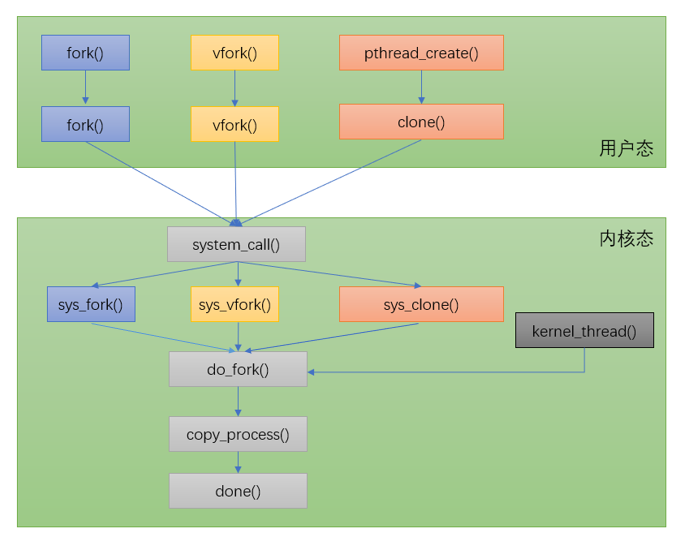
区分创建的是进程还是线程,可以重点关注上面所说的pid和tgid,以及一些资源的共享,见下图,图源见水印,忘了哪篇博客了:
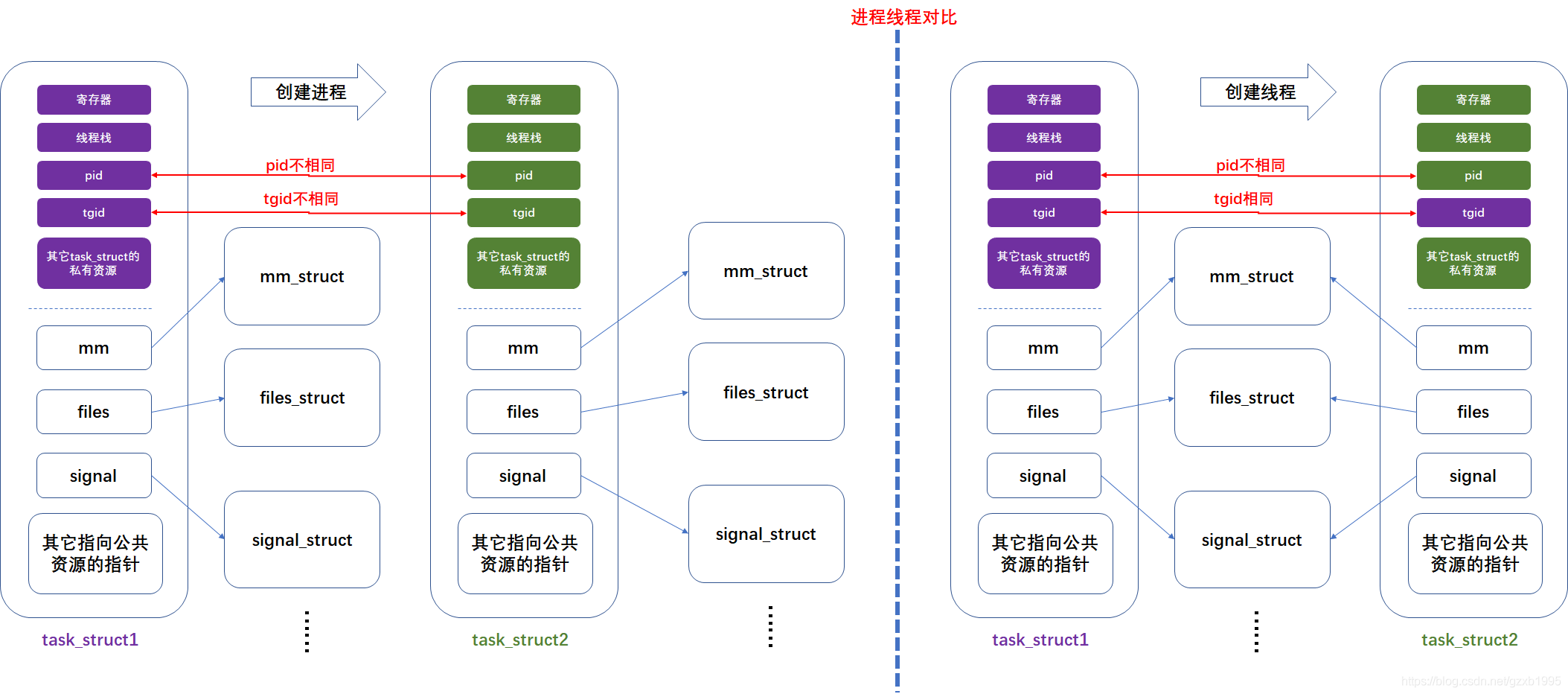
每个线程都有自己独特的pid。那内核通过什么来知道这个线程属于哪个进程呢?
答案就是tgid。是的,一个进程就是一个线程组,所以每个进程的所有线程都有着相同的tgid
简单点说:tgid用于标记某线程属于哪个进程
只有一个线程的进程,它的tgid就是进程id即pid;
当程序开始运行时,只有一个主线程,这个主线程的tgid就等于pid。而当其他线程被创建的时候,就继承了主线程的tgid;
但是进程的tgid并不是一定和pid相等,应该除了单个线程都是不相等的,而且用户用ps命令获取进程的id,其实获取的是tgid,而不是真正的进程id,但这个同样能区分不同进程,没有纠结的必要。
(2)还有进程打开了哪些文件,对应的文件描述符fd吧,比如创建了哪些套接字,监听套接字,连接套接字,他们被存储在进程里,进程默认的文件描述符数组大小为1024,也就是默认最多打开1024个文件,这个是可以修改的。
(3)打开的文件都标记了,那自然还得标记占用了哪些I/O设备,对CPU的平均占用率,对网络流量的使用情况
(4)还有当前进程的状态也肯定得记录(就绪、运行、创建等等)
task_struct是个相当庞大的结构体,这里把部分字段贴上,图源水印:

三、fork()的具体过程
接下来才是一步一步将fork()做的事情剖析出来。
前面说了,创建进程和创建线程实际上底层都是调用内核函数do_fork(),所以就干脆直接讲do_fork()。
其主要操作为:
(1)调用alloc_thread_info()函数获得8KB(两个页的大小)的union来存放新进程的thread_info和内核栈:
union thread_union {
struct thread_info thread_info; // thread_info
unsigned long stack[THREAD_SIZE/sizeof(long)]; //内核栈
};
(union的特点是,里面的变量地址一样,即都是union的首地址;此外,union的大小就是里面占用内存最大变量的大小)
对于每一个进程而言,内核为其单独分配了一个内存区域,这个区域存储的是内核栈和该进程所对应的一个小型进程描述符thread_info结构:
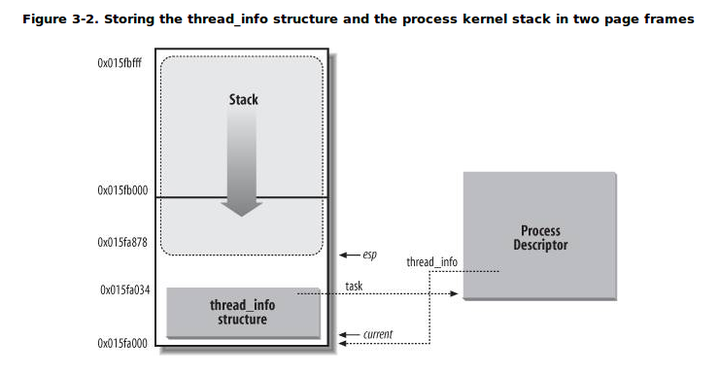
内核栈是从该内存区域的顶层向下(从高地址向低地址)增长的,而thread_info结构则是从该区域的开始处向上(从低地址到高地址)增长。内核栈的栈顶地址存储在esp寄存器中。所以,当进程从用户态切换到内核态后,esp寄存器指向这个区域的末端
上图中,最下方的是这块8KB内存的首地址处,而内核栈从高地址向低地址(首地址)处增长;而且可以看到,thread_info并不是PCB,其内部有一个struct task_struct *task指针,指向PCB。可以把thread_info理解为获取task_struct的入口,因此称其为小型的进程描述符。如果这里直接放task_struct,会非常占用空间,因为task_struct结构体很大,所以这也相当于是内核设计者的设计思路吧,不直接获取而是间接获取task_struct。
thread_info结构体代码如下:
struct thread_info {
struct task_struct *task; /* 主进程描述符 */
struct exec_domain *exec_domain; /* 执行域 */
__u32 flags; /* 低级别标志 */
__u32 status; /* 线程同步标志 */
__u32 cpu; /* 当前CPU */
int preempt_count; /* 0 => 可抢占, <0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* 先前栈的ESP,以防嵌入的(IRQ)栈 */
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
那为什么要将thread_info和内核栈放一起呢?
最主要的原因是,CPU中的esp寄存器保存了当前正在运行的进程的内核栈的栈顶,内核可以很容易的通过esp寄存器的值获得当前正在运行进程的thread_info结构的地址,进而获得当前进程描述符的地址,调用如下两个函数:
/* 从esp中获取当前栈指针 */
register unsigned long current_stack_pointer asm("esp") __used;
/* 获取当前线程信息结构 */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1)); // ~是按位取反
}
在上面的current_thread_info函数中,定义current_stack_pointer的这条内联汇编语句会从esp寄存器中获取内核栈顶地址,和~(THREAD_SIZE - 1)做与操作将屏蔽掉低13位(或12位,当THREAD_SIZE为4096时),此时所指的地址就是这片内存区域的起始地址,也就刚好是thread_info结构的地址,然后调用get_current()函数就能得到指向task_struct的指针task:
static inline struct task_struct *get_current(void)
{
return current_thread_info()->task;
}
(2)获取当前进程PCB的指针,将当前进程(父进程)的task_struct拷贝给刚分配的那块内存里新进程的task_struct。
这就是copy_process()里做的事,下面截取一段:
注意copy_process()没有把父进程的task_struct作为形参传入,而是在其里面调用函数获取父进程,然后赋值给子进程:
struct task_struct *p;
p = dup_task_struct(current);
这个dup_task_struct才是传入当前父进程的task_struct地址current,它接收一个指向原进程的 task_struct 结构体的指针,返回一个指向新进程的 task_struct 结构体的指针,完全拷贝父进程的PCB。
实际上上面第(1)部分说的alloc_task_info()就是在copy_process()里的dup_task_struct()里调用的,所以本文讲的do_fork()的顺序,并不是实际上各个函数的调用顺序,而是忽略底层实现后的一种逻辑上的顺序。
dup_task_struct()里有两指针,和对应的宏函数:
struct task_struct *tsk;
struct thread_info *ti;
然后,执行alloc_task_struct宏,该宏负责为子进程的进程描述符分配空间,将该片内存的首地址赋值给tsk,随后检查这片内存是否分配正确。执行alloc_thread_info宏,为子进程获取一块空闲的内存区,用来存放子进程的内核栈和thread_info结构,并将此会内存区的首地址赋值给ti变量,随后检查是否分配正确。
也就是说:
调用alloc_task_struct是分配结构体task_struct,
调用alloc__thread_info才是分配内核栈和thread_info,然后thread_info里面一个指针指向task_struct。
(3)拷贝之后,子进程和父进程一模一样。这个时候检查此时用户所拥有的进程数目是否超出资源限制(全局描述符表GDT就限制最大进程数是4090)
— — — — — — — — — — — — — — — — — — — — — — — — — — — —— — — — —
前面都是复制父进程的信息,后面开始要让这个新的子进程变得和父进程不一样。
— — — — — — — — — — — — — — — — — — — — — — — — — — — —— — — — —
(4)注意,一开始子进程状态是设置为task_uninterruptible,后面才变成task_running即就绪状态,有些资料说fork出来是task_running状态,其实是省略了中间过程的,不过fork完全执行后创建出的子进程,确实就是就绪状态即task_running。
TASK_UNINTERRUPTIBLE : 处于此状态,不能由外部信号唤醒,
只能由内核亲自唤醒。
经过前面的操作,此时的子进程还不完整呢,因此其状态设置为uninterruptible即不可中断的睡眠状态,这样可以保证这个不完整的子进程不会马上被投入运行。
(5)调用get_id()给新进程获取一个有效的PID
(6)更新子进程中的各种域,如描述亲属关系的域,但是很多域不能从父进程中继承而来,亲属关系是可以的。
进程所属的域(domain),通常用于实现安全策略,防止进程间的非法访问。说白了就是进程和进程间很多信息是不能共享的,即使是子进程在继承父进程时,也不能继承父进程中的某些变量或状态,比如:
文件描述符;(子进程会从父进程复制一份文件描述符表,但是这些描述符只是指向某同一文件,子进程关闭文件描述符时不会影响父进程的文件描述符)
信号处理器;(子进程不会继承父进程的信号处理函数,但是会继承信号的屏蔽状态)
环境变量;
已打开的文件列表;
…
这部分有点复杂,有的说法中,子进程不能继承父进程的是:
正文(text), 数据和其它锁定内存(memory locks) (译者注:锁定内存指被锁定的虚拟内存页,锁定后, 不允许内核将其在必要时换出(page out)
像内存的话,其实是和父进程共享的,只有子进程或父进程发生了写操作,才会分配新的,这个是写时复制里说了的。
这部分后序再补充,目前知道的是文件锁,内存锁,信号处理函数及计时器不继承。
(7)把新创建的进程PCB插入进程链表,以确保进程之间的亲属关系,比如兄弟链表。当然进程间的关系用树还是链表,得看一个父进程有几个子进程,一个就用进程链表,多个就用进程树
(8)还要把新的PCB插入pidhash哈希表。这个哈希表是加快搜索的,因为用链表的话查找还是比较慢,所以内核里还有这种哈希表,实际上有四个哈希表,对应进程的四种ID,除了pid,还有pgid,sid,参考文章
(9)把子进程的PCB状态设置为task_running,并调用wake_up_process()把子进程插入到就绪队列链表,等待被CPU调用。队列只是个历史称呼并不是真的是个queue!!!实际的实现数据结构可能是链表,也可能是红黑树
(10)让父进程和子进程平分剩余的时间片
(11)返回子进程的PID,后面还要返回用户态,这个PID最终在用户态下被父进程读取。