Aligot: Cryptographic Function Identification in Obfuscated Binary Programs
Joan Calvet Université de Lorraine, LORIA Nancy, France
José M. Fernandez École Polytechnique Montréal, Canada
Jean-Yves Marion Université de Lorraine, LORIA Nancy, France
分析加密实现具有重要的应用, 特别是对于恶意软件分析, 它们是恶意软件有效负载和解密该有效负载的解压代码的组成部分. 这些实现通常基于众所周知的加密函数, 其描述是公开的. 虽然对恶意软件分析可能非常有用, 但由于这些密码原语通常是混淆的, 因此很难识别它们. 静态分析通常是无效的, 然而密码函数的实现通常会保留原函数输入/输出的关系. 在本文中, 作者提出了一种工具, 利用这一事实来识别模糊程序中的加密函数, 通过以一种与实现无关的方式检索它们的I/O参数, 并将它们与已知的加密函数进行比较.
在实验评估中, 作者成功地在商业级封装器(AsProtect)保护的合成示例和几个混淆的恶意软件样本(Sality, Waledac, Storm Worm和SilentBanker)中识别了TEA, RC4, AES和MD5加密函数. 此外, 我们的工具能够识别非对称密码(如RSA)中的基本操作.
一句话: 根据函数的I/O关系在混淆的二进制程序中识别密码原语.
导论
大多数现有的二进制程序中用于密码函数识别的工具,如KANAL [33], DRACA[15]或Signsrch[4],都是基于静态分析对代码特征的识别,例如特定的常量值或机器语言指令,这些特征通常出现在已识别原语的正常实现中。然而,这些工具在混淆程序上大多是无效的,这些程序被故意设计得难以分析,因此隐藏了可能暴露已知加密函数存在的静态符号。因此,对密码函数进行简单的静态分析识别不适用于此类程序。
与此方法相反,我们在这里提出了一种称为Aligot的方法和工具,用于识别密码函数并检索它们的参数,其方式基本上独立于实际实现。我们的解决方案利用了加密函数的特定输入-输出(I/O)关系。一般地, F 1 ( K , C ) = C ′ \mathcal{F}_1(K, C)=C^{\prime} F1(K,C)=C′表示加密函数 F 1 \mathcal{F}_1 F1在输入秘钥 K K K和密文 C C C后得到明文 C ′ C' C′, 那么可以用 ( ( K , C ) , C ′ ) ((K, C), C') ((K,C),C′)来识别 F 1 \mathcal{F}_1 F1.
因此,如果我们在程序 P P P的特定执行过程中观察到值 K K K和 C C C被用来产生值 C ′ C' C′,那么我们可以得出结论, P P P在这个特定执行过程中实现了 F 1 \mathcal{F}_1 F1。当然,并非P的所有执行路径都可以实现 F 1 \mathcal{F}_1 F1,但识别哪些潜在路径为相关的是一个单独的逆向工程问题。
Aligot与其他加密检测工具进行了构建和测试,这些工具具有TEA, RC4, AES, MD5和RSA加密功能的模糊实现。测试用例包括自制的混淆程序(用于基准测试),使用商业打包器混淆的程序(AsProtect),以及现有的恶意软件(Storm, SilentBanker, Sality, Waledac)。Aligot在所有测试的加密函数和样本(合成和恶意软件)上的表现明显优于所有其他工具。
方案概括
一个I/O对就足以识别大多数加密函数。我们利用这一观察结果,通过以下三步过程在混淆的程序中识别它们:
(1) 收集目标程序的执行跟踪。我们的识别技术需要程序在执行过程中操作的准确值。动态分析因此特别适合,执行轨迹因此构成问题输入。
(2) 从执行跟踪中提取带有I/O参数的加密代码。我们使用循环的特定定义来构建适合于模糊程序中加密代码检测的抽象。其次,我们分析了循环之间的数据流,以便对参与同一加密实现的数据进行分组,因为存在多循环加密函数。
(3) 与已知密码函数的比较。每个提取的循环数据流都与一组加密参考实现进行比较。如果在相同的输入上执行时,其中一个实现产生的输出与循环数据流相同,那么可以得出它们实现同一密码函数的结论。
执行跟踪收集
在这项工作中,我们只关注Windows/x86平台。在这种环境下所有可用的跟踪工具中,我们选择了Pin,这是Intel[17]支持的动态二进制检测框架,主要是因为它易于使用,并且能够处理自修改代码,这是模糊程序中的一种常见技术。虽然我们不会描述跟踪器实现,但我们确实需要引入一个正式的执行跟踪概念,作为关于循环的其余推理的基础。执行跟踪直观地表示程序在系统上运行期间所做的一系列操作。在每一步中,我们收集我们称之为动态指令的东西。动态指令D是一个元组,由以下元素组成:
- 内存地址 A[D]
- 在 A[D] 执行的机器指令 I[D]
- I[D] 的内存读写地址 R A [ D ] R_A[D] RA[D], W A [ D ] W_A[D] WA[D]
- I[D] 的寄存器读写地址 R R [ D ] R_R[D] RR[D], W R [ D ] W_R[D] WR[D]
执行轨迹 T T T是动态指令的有限序列 D 1 D_1 D1; … ; D n D_n Dn。在本文的其余部分,我们将把机器指令集表示为 X 86 X86 X86,把执行轨迹集表示为TRACE。并且,给定T ∈ \in ∈ TRACE,定义 T / I n s T_{/Ins} T/Ins为机器指令序列,即 T / I n s = I 1 ; . . . ; I n T_{/Ins} = I_1; ...; I_n T/Ins=I1;...;In其中 ∀ k ∈ [ 1 , n ] \forall k \in [1, n] ∀k∈[1,n], I [ D k ] = I k I[D_k] = I_k I[Dk]=Ik。在实践中,我们还收集动态指令(在内存或寄存器中)进行的每次数据访问的确切值。
循环提取
在分析二进制程序时,通常可以将代码划分为函数。但是这个函数的概念只是一种基于编译器特性的启发式方法(调用约定、序言和尾声代码等),使得它在混淆程序中不可靠。于是我们在基于循环的混淆程序中为加密代码建立一个特定的抽象。下面先介绍一些现有的循环定义,接着给出我们的定义并描述相关的识别算法。
密码函数通常以迭代的方式对一组数据应用相同的处理,使循环成为其实现中非常频繁的结构。正是在这些循环中发生了核心加密操作,并操纵加密的I/O参数。另一方面,循环存在于许多不同类型的算法中,而不仅仅是加密算法。因此,我们需要一个专注于加密代码的精炼循环概念。这两考虑两个具体问题:
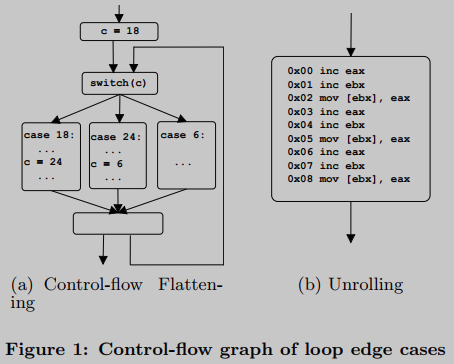
例如,图1(a)展示了一种名为控制流扁平化的混淆技术。顺序代码转换为循环,在每次迭代中实现原始代码的一部分。因此,每次执行不同的逻辑: 在密码学上下文中,它应该被视为一个循环吗?
其次,图1(b)展示了一种称为展开的经典编译器优化技术,它也可以用作混淆的一种手段。一种三条指令序列重复了三次,没有任何后继: 在密码学上下文中,它应该被认为是一个循环吗?
三个已有的循环定义:
(1) 自然循环:静态程序分析中常用的定义。回边(back-edge) 在程序的控制流图(CFG)中定义为一个节点和它的一个支配点(dominant)之间的边。因此,一个环路是由一个回边识别的,在CFG上应用这个定义会识别图1(a)为循环,而图1(b)则不行。
(2) 地址中心化循环:循环由一个特定的内存地址(称为目标地址)来标识,其中跳转一组反向分支指令。换句话说,几个回边可以对应同一个循环,然后由目标地址标识。然而,该定义也将图1(a)视为循环,图1(b)不会。
(3) 指令中心化循环:Kobayashi将执行轨迹上的循环定义为机器指令序列[14]的重复。根据这个简单的定义,图1(a)不被视为一个循环,而图1(b)则被视为一个循环。
我们将重点放在循环上,因为密码代码通常使用它们对I/O参数应用相同的处理。按照这个想法,图1(a)不应该被认为是一个循环,因为在每个迭代中执行的是不同的逻辑,相反,图1(b)应该是。因此,我们选择Kobayashi方法作为我们的起点:我们通过一个重复的机器指令序列来识别一个循环,称为它的主体(body)。因此,图1(b)循环的主体由三个指令inc eax, inc ebx和mov [ebx],eax组成。在执行过程中,同一个循环可以运行几次,每次重复的主体次数不同。我们将特定的运行称为循环的实例。我们还考虑到最后一次迭代可能是不完整的:循环实例不一定在其体的确切末尾终止。

按形式化语言来定义循环实例,循环实例就是n个 α \alpha α接一个 β \beta β(即 α \alpha α的前缀序列), 其中n>=2, α \alpha α是 X 86 \mathcal{X}86 X86指令集的指令序列。
我们还需要考虑嵌套循环。图2(a)是一种常见情况。块B构成了内部循环的主体,对于每个外部循环迭代的迭代次数不同(参见图2(B))。因此,如果我们直接在执行跟踪上应用定义1,外部循环将不会被识别为循环。尽管如此,它仍然符合我们的循环原则:重复应用相同的处理方法。
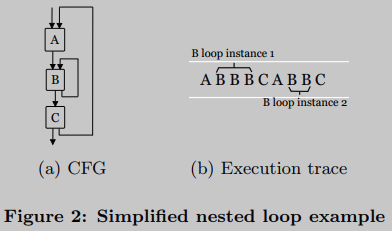
实际上,抽象每个循环实例并递归应用定义1来解决这个问题就足够了。每次检测到循环实例时,我们将其代码替换为执行跟踪中的循环标识符。这个标识符表示与实例关联的循环。换句话说,我们用相同的标识符替换同一个循环的每个实例。

L \mathcal{L} L是循环的一个实例, BODY[ L \mathcal{L} L]是循环的主体, 循环的实例就可以形式化表示为n个 X 86 \mathcal{X}86 X86指令集和循环标识符 L I D \mathcal{L}_{ID} LID的序列 α \alpha α, 接上部分 α \alpha α的前缀, 即 β \beta β.
基于上面的两个定义, 可以构造循环检测算法, 时间复杂度为O( m 2 m^2 m2), m是执行跟踪的大小.

LOOP识别算法一个接一个地处理来自执行跟踪的机器指令,并将它们存储在一个名为history的类列表结构的末尾。常见情况如图3(A)所示:指令 I 1 ; I 2 ; I 1 ; I 3 I_1;I_2;I_1;I_3 I1;I2;I1;I3已记录到历史,目前处理的机器指令为 I 1 I_1 I1。因此这条指令在历史上出现了两次。历史记录中 I 1 I_1 I1的每次出现都对应一个可能的循环实例开始。在第一种情况下,主体是 α = I 1 ; I 2 ; I 1 ; I 3 α = I_1;I_2;I_1;I_3 α=I1;I2;I1;I3,而第二个是 α = I 1 ; I 3 α = I_1;I_3 α=I1;I3。因此,该算法创建了两个循环实例,分别命名为 L 1 \mathcal{L}_1 L1和 L 2 \mathcal{L}_2 L2,每个循环实例都有一个指针指向预期的下一条指令, L 1 \mathcal{L}_1 L1为 I 2 I_2 I2, L 2 \mathcal{L}_2 L2为 I 3 I_3 I3(参见图3(b))。
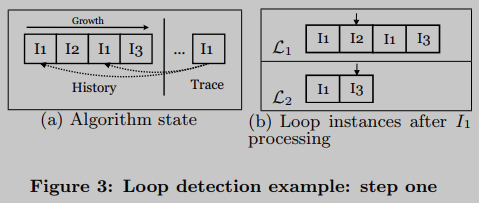
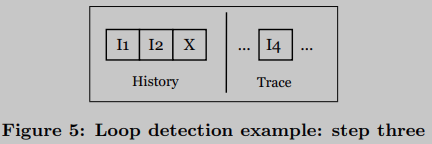
假设下一条机器指令是 I 4 I_4 I4。然后,从正在运行的循环实例中删除等待 I 1 I_1 I1的 L 2 \mathcal{L}_2 L2并进行注册(循环标识符)。用它的循环标识符 X \mathcal{X} X替换它的代码,这样做允许检测到一个外部循环,L2迭代次数独立于每个外部循环迭代的。
循环输入输出参数
循环允许从执行跟踪中提取可能的密码代码,但我们的最终目标是收集密码参数。在本节中,我们将介绍一个循环实例参数的概念和从执行跟踪中提取这些参数的算法。
循环实例参数是高级实现参数的低级对应(在本文的其余部分称为高级参数)。在执行跟踪中读取或写入的字节构成了我们的起点,对于循环实例L,我们通过组合以下三个必要条件来定义它的参数:
- 属于同一个L的参数的字节要么在内存中相邻,要么同时在同一个寄存器中。(仅这个条件就会倾向于将多个高级参数分组在同一个参数中。实际上,不同的高级参数可以在内存中相邻,这在堆栈中经常是这样的情况。但这种过度近似会使最后的比较阶段变得非常复杂;因此需要引入以下条件。
- 属于L的相同参数的字节被BODY [L]中的相同指令以相同的方式(读或写)操作。(实际上,BODY [L]中的特定指令可以在每次迭代中操作不同的字节,但这些数据往往具有相同的作用(特别是因为我们严格的循环定义)。
- 最后,属于L输入参数的字节已经被读取,而之前没有被L的代码写入,而属于L输出参数的字节已经被L的代码写入。
为了收集这些参数,我们将具体变量定义为从特定内存地址开始的简单字节数组。为了简洁起见,现在只给出参数收集算法的概述。
该算法首先使用前两个必要条件将字节分组为具体的变量。然后,通过应用第三个条件,我们将具体变量分为两组,输入和输出参数(相同的具体变量可以在两组中)。
在第二步中,算法将一个固定值与每个先前定义的具体变量相关联。跟踪引擎为每次数据访问收集值。我们使用以下两个规则来设置参数值:(1)第一次读取输入参数时提供它的值,(2)最后一次写入输出参数时提供它的值。
最后,对于每个循环实例 L L L,算法返回: I N M ( L ) IN_M(L) INM(L)和 I N R ( L ) IN_R(L) INR(L)分别包含内存和寄存器中的输入参数, O U T M ( L ) OUT_M(L) OUTM(L)和 O U T R ( L ) OUT_R(L) OUTR(L)则包含输出参数。
算法执行复杂度O(m),m为跟踪大小。(具体算法实现参考论文源码
为了便于理解前面的定义,我们在这里给出一个简单的人工示例。图6展示了一次性填充密码的汇编语言实现, 在输入文本和相同长度的键之间按位异或操作。

为了解密8字节文本0xCAFEBABECAFEBABE,我们将这段代码应用到一个程序P中,该程序使用8字节密钥0xDEADBEEFDEADBEEF。为了用本文提出的方法识别P中的密码函数,我们需要收集两个输入值以及相关的输出结果,假设是0x1453045114530451。通过上述算法提取环路参数,我们将其表示为如图7所示的参数图。密码参数已成功提取:402000:8和402008:8作为输入,402000:8作为输出。另一方面,我们还收集了与这个特定实现相关联的值的参数:(i) eax:4, ebx:4, esp:4,包含内存地址,(ii) ecx:4,包含计数器值,(iii) 12FFC0:4,对应于在循环(SIZETODECRYPT)之前初始化的局部变量,以及(iv) edx:4,一个中间存储。

循环数据流
到目前为止,我们认为每个可能的加密实现都包含一个循环。然而,加密函数实际上可以由几个非嵌套循环组成,例如RC4。因此,循环抽象本身不足以完全捕获它们。为了解决这个问题,我们使用数据流对参与相同加密实现的循环实例进行分组。
我们以类似于def-use链的方式定义循环实例之间的数据流:如果L1产生一个输出参数,L2将其用作输入参数,则连接两个循环实例L1和L2。为了简单起见,只考虑内存参数,因为寄存器参数需要在循环实例之间的顺序代码中进行精确的污染跟踪。实际的假设是,对内存中输入和输出的所有处理都是通过循环处理的。(这个假设有点严格了

通俗来说,就是如果 L i ⊴ L j \mathcal{L}_i \unlhd \mathcal{L}_j Li⊴Lj则表示循环 L i L_i Li的输出会作为 L j L_j Lj的(部分)输入。
这些连通片中的每一个都代表一个抽象,类似于普通二进制程序中的函数。因此,每个 G k G_k Gk都是一个候选加密函数实现,然后将根据已知实现对其进行测试。采用标准图算法重构环路数据流图,对检测到的每对环路 L i L_i Li和 L j L_j Lj测试二元关系,并检测其连通分量。在本文的其余部分中,循环数据流图的连通片将简单地称为循环数据流。
在不同密码函数之间组合的情况下,即一个函数输出用作另一个函数的输入,它们将被分组到相同的循环数据流中。一种解决方案是考虑循环数据流图中的每个可能的子图。比如 ( { L 1 , L 2 , L 3 } , ⊴ ) (\{L_1,L_2,L_3\}, \unlhd) ({
L1,L2,L3},⊴)的图 G G G,算法会分别检测 { L 1 , L 2 , L 3 } \{L_1,L_2,L_3\} {
L1,L2,L3}, { L 1 , L 2 } \{L_1,L_2\} {
L1,L2}, { L 2 , L 3 } \{L_2,L_3\} {
L2,L3}, { L 1 } \{L_1\} {
L1}, { L 2 } \{L_2\} {
L2}, { L 3 } \{L_3\} {
L3},即每个循环的组合。
循环数据流构成了我们的密码实现模型,我们的最终目标是提取密码参数。我们将循环数据流参数定义为不用于内部数据流的内存循环实例参数。关于寄存器参数,为了简单起见,我们取根循环实例的输入寄存器和叶循环实例的输出寄存器。这些参数的值是在循环实例参数提取过程中收集的。现在有了一个从执行跟踪中提取可能的加密实现并收集其参数的模型。我们现在可以识别密码函数了。
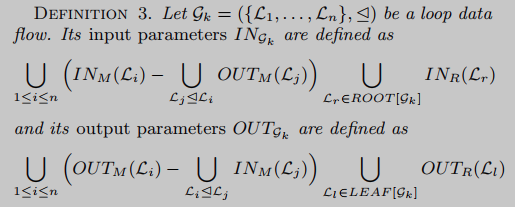
比较
识别技术的最后一步是将循环数据流与加密参考实现进行比较。我们考虑两种不同的输入:

比较算法的任务就是去检查 I N G k IN_{G_k} INGk和 O U T G k OUT_{G_k} OUTGk的关系是否在密码函数实例 P F P_{\mathcal{F}} PF也能维持不变。在介绍算法之前,需要声明一下设计该算法时遇到的困难。作者这里使用公开可用的源代码作为参考实现。因此,从执行跟踪中提取的参数与在高级源代码中定义的参数之间的抽象级别是不同的。
(1)参数类型。因为我们用循环数据流提取的是低级参数,即连续的内存地址和寄存器,所以如何将它们转换回函数引用实现的高级类型并不明显。事实上,这可能会导致比较中的人为错配,即相同的值以不同的方式表示。这就是为什么我们选择在尽可能最低的抽象级别(即原始值)上使用参数的引用实现。
(2)参数的顺序。高级实现以特定顺序声明参数,但循环数据流参数没有顺序。因此,我们必须测试所有可能的顺序。
(3)参数分段。相同的高级参数可以分为几个循环数据流参数,例如,当它被寄存器传递但不能只适合其中一个时。因此,必须组合循环数据流参数值来构建高级参数值。换句话说,循环数据流参数与其高级对应参数之间的映射不是1对1,而是n对1。
(4)参数数量。循环数据流参数不仅捕获加密参数,还捕获与实现相关的参数。因此,一些循环数据流参数将没有匹配的高级参数。
算法实现
(1)Generation of all possible I/O values:生成所有可能长度的所有组合。
(2)Input parameter mapping:对于每个密码参考实现 P F P_F PF,算法为每个高级参数在前一步生成的参数中选择其可能的值。特别是,对于固定长度的参数,只选择具有正确长度的值。
(3)Comparison:程序 P F P_F PF在其所选输入值的每个可能组合上执行。如果在某一时刻,生成的值在步骤1中生成的可能输出值的集合中,那么它就是成功的。如果不是这样,算法就会迭代,直到测试完所有组合为止。
实验
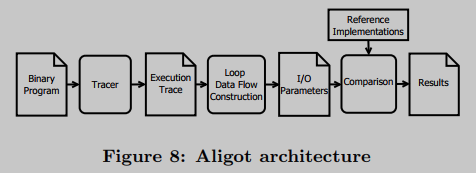
作者构建了一个名为Aligot的工具集,它实现了整个识别过程,如图8所示。该工具由大约2000行Python代码和600行用于跟踪引擎的c++代码组成。
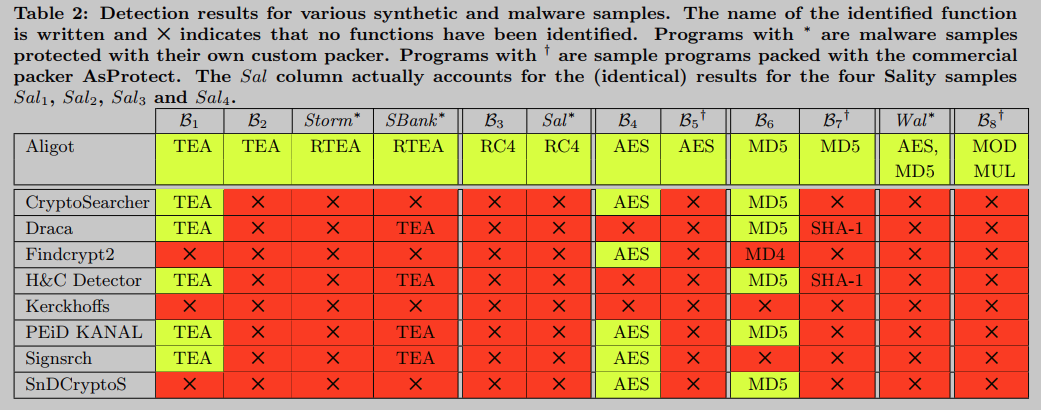
值得一提,我们考虑了使用固定常数的加密算法的某些实现可能会使用这些常数的不同值(而不影响其安全性)以避免被检测的可能性。为了探索这种可能性,我们用修改后的delta常量值对Aligot的TEA实现进行了测试。由于使用了参数化的参考实现TEA,其中delta常数成为输入参数,Aligot仍然能够检测这些修改后的TEA实现。所有其他工具都未能做到这一点,这似乎证实了他们对TEA的检测仅仅基于对标准delta常数值的识别。

Aligot的实现只是证明方法的可行性,性能上有待优化。
(其他详细实验说明看paper
限制
(1)首先,和其他动态分析工具一样,Aligot只能识别在运行时实际执行的代码。确定哪些潜在路径与分析相关,并应该“提供给”这样的工具是一个单独的研究问题。
(2)其次,Aligot的识别能力仅限于我们拥有参考实现的那些函数。
(3)尽管本文给出了实验结果,但论文并没有声称循环数据流模型捕获了每一个可能的加密函数模糊实现。事实上,计算机程序分析本质上是不可确定的,正如Rice的定理[13]所述,这种理论上的不可能性在混淆的对抗性游戏中特别相关。在所给例子中,恶意软件作者可以简单地用不符合我们定义的循环实现加密函数。
总结
Related Works
[4] L. Auriemma. Signsrch tool. http://aluigi.altervista.org/mytoolz.htm.
[13] J. Hopcroft, R. Motwani, and J. Ullman. Introduction to automata theory, languages, and computation. Addison-Wesley, 2007.
[15] I. O. Levin. Draft crypto analyzer (draca). http://www.literatecode.com/draca.
[17] C. Luk, R. Cohn, R. Muth, H. Patil, A. Klauser, G. Lowney, S. Wallace, V. Reddi, and K. Hazelwood. Pin: building customized program analysis tools with dynamic instrumentation. ACM SIGPLAN Notices, 40:190-200, 2005.
[33] PEiD Krypto Analyzer (kanal). http://www.peid.info.
Insights
(1) 考虑所有的参数组合,这里因为抽象层次不一致,所以循环的参数可以采用爆破的方法验证。
(2) 本质上本文方法是停留在考虑输入输出关系的程度,算是很Naive的想法。而且所做的假设是默认加密函数的核心功能都是由循环完成的,对一般化的函数检测帮助不大,而且不能抗混淆。
(3) 使用history或者trace或者执行状态信息来支撑函数检测任务。