Enhancing DNN-Based Binary Code Function Search With Low-Cost Equivalence Checking [TSE 2023]
Huaijin Wang, Pingchuan Ma, Yuanyuan Yuan, Zhibo Liu, Shuai Wang Department of Computer Science and Engineering, HKUST, Clear Water Bay, Kowloon, Hong Kong.
Qiyi Tang, Sen Nie, and Shi Wu Tencent Security Keen Lab
二进制代码函数搜索是各种安全和软件工程应用的核心基础, 包括恶意样本分类, 克隆代码检测, 漏洞审计等. 识别逻辑相似的汇编函数依然是一个挑战. 许多二进制代码搜索工具依赖于程序的结构信息, 比如用程序分析技术或者深度神经网络提取的控制流图, 数据流图. 然而, 基于dnn的技术捕获二进制代码的词汇、控制结构或数据流级别的信息用于表示学习, 这些信息通常过于粗糙, 不能准确地表示程序功能. 此外, 它可能对各种具有挑战性的设置(如编译器优化和混淆)表现出较低的健壮性. 本文提出了一种提高基于dnn的二进制代码函数搜索中top-k排序候选的通用解决方案. 关键思想是设计一个低成本和全面的等价性检查, 快速暴露目标函数和它的前k个匹配函数之间的功能偏差. 没有通过这种等价性检查的函数可以从前k名列表中删除, 通过检查的函数可以重新访问, 以便以一种有意的方式在排名前k的候选函数上前进. 作者设计了一个实用而高效的等价性检查, 命名为BinUSE, 使用了受约束符号执行(under-constrained
symbolic execution, USE). USE是符号执行的一种变体, 它通过直接从函数入口点启动符号执行并放松对函数参数的约束来提高可伸缩性. 它消除了由路径爆炸和开销约束引起的负担. BinUSE旨在提供汇编函数级的等价性检查, 通过以较低的代价减少误报来增强基于dnn的二进制代码搜索. 评估表明, 当面临不同编译器、优化、混淆和架构带来的挑战时, BinUSE可以普遍有效地增强四种最先进的基于dnn的二进制代码搜索工具.
一句话: BinUSE使用欠约束符号执行, 对DNN搜索的二进制函数进行等价性检查, 减少误报以增强搜索效果.
导论
随着机器学习技术的蓬勃发展及其在软件嵌入[6]、[7]等下游任务中的广泛应用, 当代大多数二进制代码搜索工具都旨在训练一个机器学习模型来捕获二进制代码相似度[8]、[9]、[10]、[11]. 特别是, 深度神经网络(DNN)和表示法学习的最新进展使训练DNN模型学习最优代码表示法成为可能, 该方法能够区分相似的汇编函数 [12], [13], [14], [15], [16], [17]. 为了学习代码表示, DNN模型使用(轻量级)词汇、控制结构或数据流级特征进行训练. 这样的表示尽管很容易提取, 但可能无法在很大程度上保留程序语义. 轻量级特性对于诸如编译器优化或混淆之类的挑战通常不健壮, 这使得语义上相似的汇编代码看起来有很大的不同. 因此, DNN模型可能表现出较低的可辨性和较低的鲁棒性, 导致在其检索的top-k候选中出现大量的误报.
本文旨在以一种有原则和高效的方法来增强二进制代码函数搜索. 给定目标函数 f t f_t ft和函数库RP, 采用低成本的等价性检查快速识别RP中与 f t f_t ft语义偏离的函数, 从而从检索到的top-k排序候选函数中去除. 因此, 可以重新考虑是否将通过检查的函数包含在检索出的前k个候选函数中. 对基于dnn的二进制函数搜索工具进行加权的主要结果如表1所示.
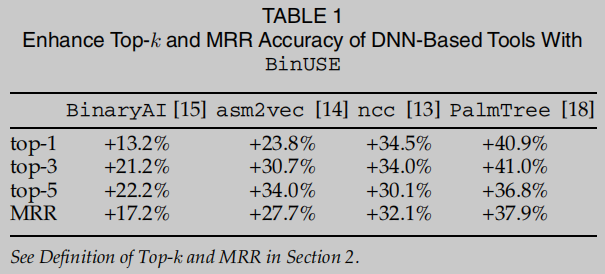
本工作对4个SOTA的DNN工具提供了有效的增强, 即使这些工具使用的神经网络模型和学习手段不尽相同. 为了设计一种低成本、实用的汇编函数等价性检验方法, 本文采用约束求解和欠约束符号执行技术[19]来构建和检验汇编函数的输入输出关系. 与标准符号执行相比, USE旨在直接从函数入口点进行灵活、快速的符号推理, 跳过了从主函数到目标函数的代价高昂的路径前缀. 优化了标准使用方案BinUSE作为实用工具, 特别是对汇编函数的等价性检查. BinUSE从函数入口点启动USE遍历, 遍历每一条路径, 直到到达第一个外部函数调用点, 表示CFG上的一个信息丰富且关键的节点. 然后, BinUSE利用外部调用点输入的符号公式形成每条路径上的符号约束, 并从每个函数的每条路径上收集匹配的符号约束来匹配两个函数.
Contributions
(1) 在概念层面, 提出了一个新的侧重点来增强目前准确率较低的基于dnn的二进制代码函数搜索. 本文没有设计新的dnn(原则上难以精确捕获语义), 而是设计了一个低成本的等价性检查, 以标记和删除在语义上偏离目标函数的组装函数
(2) 在技术层面, 通过优化标准使用方案, 提出了一种等价性检验方法, 进一步降低了其成本. 这种等价性检查是专门为汇编函数设计的, 考虑了各种技术挑战和优化机会, 例如收集函数入口点可访问的外部调用点上的符号约束, 以降低复杂性
(3) 实验结果表明, 所设计的等价性检验具有通用性和有效性, 能够以较低的代价增强基于dnn的二进制函数搜索工具. 在各种具有挑战性的条件下, 包括通用等价函数匹配和CVE搜索, 等价性检测表现出优异的性能
预备知识
Formulation and Metrics
现有的语义感知的函数搜索工作, 是给定目标汇编函数 f t f_t ft, 和一个函数库 R P RP RP, 搜索引擎会获取语义相似度最高的k个函数作为 f t f_t ft 的识别结果, 即为Top-k. 衡量top-K准确率的指标由以下公式计算:
1 N × ∑ i = 1 n p k ( f i ) \frac{1}{N} \times \sum_{i=1}^n p_k\left(f_i\right) N1×i=1∑npk(fi)
其中N是程序中函数的总数. 简单理解这个公式的意义, 迭代地将二进制 B i n 1 Bin_1 Bin1中的函数 f i f_i fi作为目标函数, 去查询以 B i n 2 Bin_2 Bin2中所有函数构成的函数集 R P RP RP, 设正确匹配 f i f_i fi的函数为 f i ′ f_i' fi′, 当 f i ′ f_i' fi′在top-k的候选中时 p k ( f i ) = 1 p_k(f_i) = 1 pk(fi)=1, 否则为0.
另一个常用指标, 称为平均倒数排名分数(mean reciprocal rank score, MMR)
M R R = 1 ∣ Q ∣ ∑ i = 1 ∣ Q ∣ 1 rank i \mathrm{MRR}=\frac{1}{|Q|} \sum_{i=1}^{|Q|} \frac{1}{\operatorname{rank}_i} MRR=∣Q∣1i=1∑∣Q∣ranki1
其中 ∣ Q ∣ |Q| ∣Q∣是查询总次数, r a n k i rank_i ranki是一次查询中正确结果在top-k个候选中的序号, 比如正确结果在top-k中排第4, 则 r a n k i = 4 rank_i = 4 ranki=4, MMR指标是越大效果越好.
Equivalence Checking
除了基于流行的dnn的表示学习之外, 另一个研究方向是执行代码等价性检查, 使用通过符号执行获得的程序输入输出关系. 给定表示二进制码输入输出关系的符号公式, 然后使用约束求解器检查符号公式的等价性. 等价性检查对具有挑战性的设置(如编译器优化和混淆)具有很强的弹性, 因为这些设置不应该改变程序的输入-输出关系. 一个例子

上两个代码片段可以等价于下两个语句, 那么等价性检查可以去检查 a = m ∧ p ≠ s a=m \wedge p \neq s a=m∧p=s 约束在输入域内是否满足, 如果全部输入都不满足这个约束条件, 那么称这两个代码片段是严格等价的.
局限性 所提出的技术给出了程序等价性的严格证明. 然而, 由于路径爆炸、推理复杂约束和二进制分析领域特定的挑战, 符号执行和约束求解的可伸缩性较低. 到目前为止, 基于等价性检查的方法主要用于基本块或执行跟踪比较.
二进制分类 等价性检查的两种标准错误: false positive (FP) 和 false negative (FN), 前者是不同功能函数被视为等价的, 后者是等价的函数被视为不等价的. 虽然等价性检查不能直接用于计算top-k精度, 但可以使用USE启用的等价性检查来消除DNN模型产生的假警报.
Under-Constrained Symbolic Execution
欠约束符号执行被提出以执行任意代码片段的检查, 从原理和系统上降低符号执行的复杂度. 为了说明SE和USE之间的高级技术差异(在路径覆盖方面), 图2a给出了一个分析消息解码程序的案例, 并识别了decoing_msg中的一个错误. main函数使用receive_msg接收编码后的消息, 并在循环语句中执行解码过程. 然后, 解码后的消息被传递给函数decoding_msg, 其中一个bug(在图2a中的第15行标记为bug)隐藏在if分支中. 由于高计算资源使用和冗长的约束, SE在分析这个简单的情况时可能会受到阻碍. USE以一种有原则的方式降低了复杂性. 为了达到bug, USE直接分析decoding_msg. 结果路径如图2c所示, 对解码后的消息 m s g 22 msg_{22} msg22没有施加复杂的约束, 并且可能引入更容易解决的约束. 更昂贵的整个程序分析可以推迟到需要的时候.
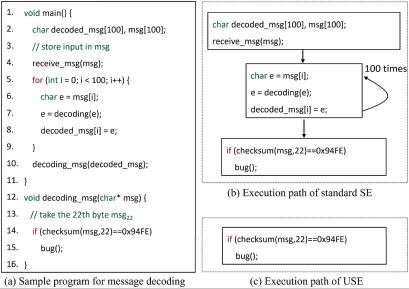
局限性 USE通过放松对输入的限制, 可以找到令人满意的解决方案, 当考虑到从main到目标代码片段的路径前缀时, 这些解决方案实际上是无效的. 同样, 成功地找到一个可满足的解决方案意味着两个代码片段没有通过等价性检查. 总的来说, USE在原则上提供一个完整、有效但不健全的等效性检查, 可能会导致通常不希望出现的假阴性.
动机
基于dnn的方法从词汇、控制结构或数据流事实中学习代码表示, 一个训练良好的DNN模型将输入二进制样本(或机器指令)转换为数值向量, 其中两个相似的程序应该有更近的余弦距离. 基于dnn的方法主要学习“模糊”和轻量级的数据和控制特征, 具有较高的灵活性和可扩展性, 促进了大规模二进制样本的分析. 然而, 学习到的词汇、控制或数据特征并不一定精确地表示功能. 总之, 我们认为习得的嵌入表示主要存在以下两个缺陷: (1) 低的辨别力: DNN模型可以将逻辑上不同的函数视为相似的. 因此低鉴别性导致报告的FP匹配结果较多; (2) 低鲁棒性: 鲁棒性指的是运行软件或算法时在各种不完美条件下的阻力. 低鲁棒性意味着DNN模型可能会难以匹配共享相同逻辑但在语法上不同的函数. 一般来说, 低鲁棒性会导致报告较多的FN匹配结果.
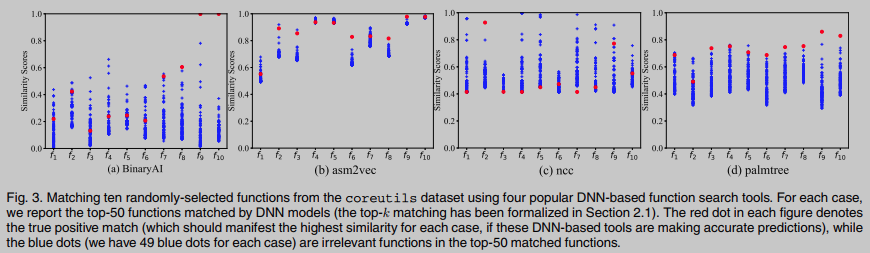
图3为对比结果, 其中红点表示由同一源函数编译而成的汇编函数之间的相似性得分, 蓝点表示其他函数之间的相似性得分. 理想情况下, 红点的高相似性分数表明DNN模型对编译器优化的鲁棒性: 从同一源函数编译的汇编函数, 尽管表现出不同的语法形式, 但具有相同的语义. 因此当蓝点被很好地分开时, 就体现出了可分辨性, 这意味着从不同源函数编译的汇编函数在DNN模型的视图中表现出了巨大的差异.
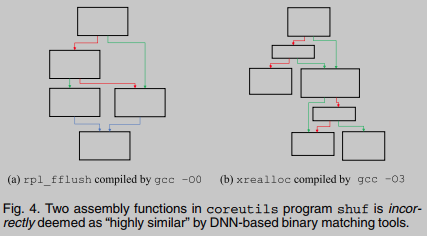
图4给出了一个错误的预测: 从不同源代码编译的两个程序集函数被错误地认为是“相似的”. 这可能是由于ncc提取的“上下文流图”具有相似性, 不能反映功能偏差.
方案概述
现代基于dnn的二进制代码搜索从粗粒度特征中学习代码表示, 具有较低的可辨性和较低的鲁棒性. 因此, 通常top-k匹配的函数具有相近的相似性分数, 而ground truth匹配可能由于具有挑战性的设置(如编译器优化或混淆)而没有足够高的相似性. 我们的初步研究手动检查了这些DNN模型的top-k匹配结果, 我们怀疑一个简单的等价性检查可以有效地降低FPs. 例如, 我们可以给目标函数 F t F_t Ft和top-k中的函数提供相同的输入, 并比较它们的输出, 看看它们是否不同.
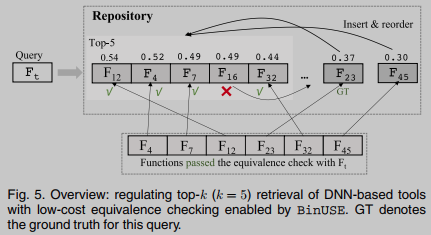
图5描述了我们增强基于dnn的工具的top-k检索的工作流程概述. 简而言之, 这项研究旨在提供一种低成本的等价性检查, 对两个汇编函数是否相同做出真/假判断. 这样, 我们可以通过减少top-k检索中的FPs来调节基于dnn的工具的搜索结果. 例如, 激励示例(图3)中的许多“蓝点”可以通过简单地执行带有输入的两个函数并比较其输出的等效性来确定为与目标函数不同. 通过这种低成本的等价性检查, 可以很容易地将这些FPs从top-k检索中去除.
检查软件的等价性总体上是昂贵的, 因此作为一种实际的权衡, 我们接受相对较低精度的等价性检查, 在某种意义上, 通过检查的两个函数仍然可能是不同的. 这样, 通过在基于dnn的二进制代码搜索中增加低成本的等价性检查, 可以实现实际的协同效应, 从而实现更快的服务和更高的精度.
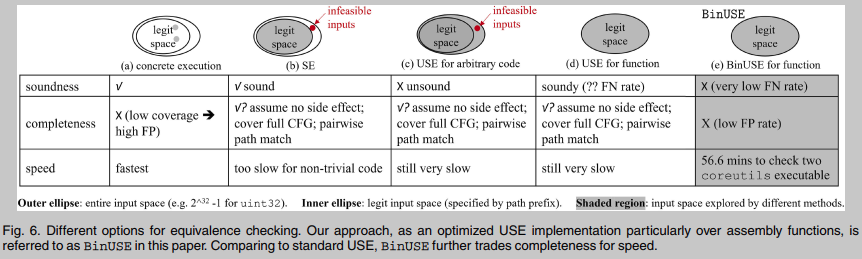
1 基于具体执行的等价性检查 使用随机抽样的值作为输入, 并比较具体的执行输出. 这种方法可能只覆盖很小的输入空间, 通过将不同的函数视为等效, 可能会导致高FPs. 并且直接执行汇编代码时设置合适的执行上下文是一个很有挑战的问题.
2 基于符号执行的等价性检验 精确地对输入约束建模, 并在合法的输入空间内构造等价性检查. 因此, 它应该是准确. 然而, SE的可伸缩性较低, 其执行很难到达隐藏在调用链中的函数.
3 基于欠约束符号执行的等价性检查 USE可以在任意程序点启动符号推理, 它通过跳过昂贵的路径前缀来改进标准SE. 然后忽略路径前缀, 表示USE不能对目标代码片段的输入建模约束. 因此, USE过度地探索了完整的输入空间. USE可以进行完备但不可靠的等价性检查, 因为它可能会在合法输入空间之外找到反例, 从而违反等价性检查约束.
4 基于欠约束符号执行的函数等价性检查 尽管解决不可靠的问题普遍存在困难, 但我们对现实世界软件的观察在本研究中得出了一个关键假设: 实际程序中的函数遵循防御性编程原则[35], [36], [37], 该原则规定任何特定函数都不应对其输入进行假设(例如, 调用方传递的指针可能是无效的). 也就是说, 函数的输入可以是输入空间中的任何值. 这个假设提供了一个独特的机会来提供一个“可靠的”等价性检查, 特别是对于函数, 因为当在真实的软件中分析函数时, 合法的输入空间应该与USE可以探索的完整输入空间对齐. 另外, 这一原则被流行程序套件(如coreutils、binutils)和复杂的现实世界软件(如OpenSSL和Wireshark)的程序员所遵循.
5 基于BinUSE的函数等价性检查 用完备性换取速度进一步优化标准USE方法. BinUSE计算外部调用点输入的符号公式, 形成每条路径的符号约束. 为了匹配两个函数, BinUSE探索从每个函数中的每个路径收集的匹配符号约束. BinUSE不完备. 然而根据实证结果, 平均FN率非常低. 此外BinUSE可以在各种具有挑战性的设置下(例如,跨架构)进行低成本检查. BinUSE可以在56.6 CPU分钟内完成检查两个coreutils可执行文件(平均每对函数25秒), 包括所有符号执行和约束求解任务.
BinUSE设计
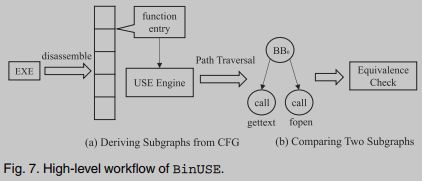
给定一个输入可执行文件,BinUSE首先执行逆向工程以恢复程序集功能信息. 然后, 它从每个汇编函数的入口点开始, 逐个路径启动USE, 其中每个路径遍历在到达第一个外部调用点时停止. 结果将生成一个子图, 其中每个叶节点对应一个外部调用点. 为了比较两个汇编函数, 我们通过启动约束求解来交叉检查外部调用点输入和路径约束的语义等价性, 以比较它们的派生子图(详见以下).
逆向假设 分析是在函数级, 它不假设程序符号或调试信息的存在. 只要确定了要使用的函数, 就可以毫无困难地处理剥离的二进制文件. 我们的分析也是平台中立的; 我们评估了x86 64位、x86 32位和ARM架构的三种跨架构设置. 还评估了不同的编译器(gcc和clang)、优化级别和常用的混淆方法.
Baseline
基线方法是从函数的入口点开始执行标准的过程内分析, 并迭代每个执行路径. 每当从未知数据(包括函数参数、全局数据和其他内存区域)加载时, 就会创建自由符号. 然后, 我们在路径的出口点收集CPU寄存器和内存的输出符号公式, 以构建输入-输出关系.
Generating Subgraphs From CFG
考虑到完全探索函数的CFG的难度, 我们首先提取一个子图. 该子图应保留相应CFG的代表性特征, 并合理降低分析复杂度. BinUSE被设计为遍历从每个程序集函数的入口点开始的每个执行路径. 当遇到一个循环时, 作为一种常见的解决方案, 我们展开循环. 当分析一个执行路径时, BinUSE递归内联路径上的每个callsite. BinUSE在遇到第一个外部调用点时停止. 与标准SE一致, 我们创建自由符号来表示存储在寄存器或内存单元中的值. 当我们遇到外部调用点时, 我们为每个函数调用的输入收集符号公式, 以形成该路径的“输出”. 我们还记录路径约束作为到达外部调用点的先决条件.
Comparing Two Subgraphs

上图显示了比较两个汇编函数 f t , f s f_t, f_s ft,fs的子图 G t , G s G_t, G_s Gt,Gs的过程. 迭代地比较每个调用点, 直到我们发现使 G t G_t Gt中的外部调用点与 G s G_s Gs中的外部调用点成对等价的排列(permutation). 注意只允许 G t G_t Gt中的一个调用点子集与 G s G_s Gs中的另一个调用点子集匹配. 原因是编译器优化有时可以消除C库函数调用, 因此允许一个库调用子集匹配另一个库调用子集不会阻碍 G t G_t Gt与高度优化的 G s G_s Gs匹配. 相反, 如果没有发现排列, 则认为两个函数是相等的. 虽然在 G t G_t Gt和 G s G_s Gs中两两比较callsite可以引入很多排列, 但只有当两个callsite指向相同的外部函数时, 才会进行重量级等效性检查.
C库调用替换 当C库调用的某些输入参数为常量时, 编译器可能会将此C库调用替换为其他. 此外编译器可能偶尔会用更安全的版本替换公共C库调用. 例如通过用__printf_chk替换printf, 在计算结果之前就会检测到堆栈溢出.
库callsites匹配被认为是等价性检查的关键步骤, 为此我们手动收集了以下列表. BinUSE将每个列表中的库调用视为相同的. 例如, 除了比较两个printf callsite之外, 我们认为printf callsite和__printf_chk是相同的. 这个列表包含了在我们的测试用例中发现的所有可能的C库替换, 其中包括Linux coreutils和binutils测试套件, 以及一个CVE数据库, 其中包括来自OpenSSL、Wireshark、bash和ffmpeg等复杂软件的脆弱函数.

计算定量匹配分数 假设 G t G_t Gt中有n条路径(每条路径都在外部调用点中结束), 并且确定了p条路径其外部调用点在 G s G_s Gs中具有语义等效的调用点, 表示将汇编函数 f t f_t ft和 f s f_s fs视为等效的置信度的分数s计算为p/n. 该置信度评分将在校准DNN模型的结果时使用. 在分析coreutils可执行文件时, 87.9%的案例的置信度评分为1.0, 这表明在大多数情况下, G f G_f Gf上的所有路径都与 G s G_s Gs匹配.
Comparison of Two Callsites
虽然先前的研究已经证明了IDA-Pro对函数信息恢复[43]的支持不足, 但在IDA-Pro的FLIRT数据库[44]中, 标准C库函数信息得到了很好的维护. 因此使用IDA-Pro (version 7.3)在很大程度上保证了分析外部调用点的可信度. 尽管如此, 如果可执行文件包含一些用户定义的(或第三方定义的)库调用, 则FLIRT无法处理它们. 恢复这样的信息需要推断函数参数的数量; 函数原型信息恢复的最新进展可参考[43], [45], [46]. 给定一个包含N个参数的调用点, 我们根据相应架构上的调用约定提取N个符号公式.
调用参数排列 为了检查两个调用点, 我们搜索函数参数成对匹配的排列. 不是单纯比较两个调用点的第i个参数, 而是采取更保守的设计, 比较参数之间的匹配排列. 比如下图中, f i l e n a m e t filename_t filenamet 可以和 f i l e n a m e s filename_s filenames 匹配, 也可以和 m o d e s mode_s modes; m o d e t mode_t modet可以和 f i l e n a m e s filename_s filenames匹配, 也可以和 m o d e s mode_s modes匹配. 这种设计使等价性检查更加保守, 对编译器优化和潜在的混淆具有健壮性, 但可能会引入FPs.

另外不同参数数目的函数也有可能是等价的, 比如gettext和dgettext当后者的domainname是常值时, 两者等价.

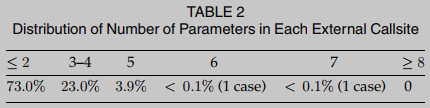
为了解决这种阻碍, BinUSE的设计要对现实世界的各种软件鲁棒. 经验观察表明, 这种排列方法不会带来过多的开销, 因为几乎所有常用的软件都有有限数量的函数参数. 为了进一步证明这一设计决策, 我们给出了表2中测试用例中遇到的所有外部调用点的参数数量分布. 从这些经验结果中可以观察到, 大多数外部调用点具有少于或等于2个参数, 几乎所有外部调用点具有少于或等于5个参数. 因此, 我们认为我们的参数排列的设计决策并没有增加显著的成本, 但可以帮助BinUSE的整体设计更加保守和稳健.
参数等价性检查 设 P C t , P C s PC_t, PC_s PCt,PCs分别是目标汇编函数的入口点到调用点的路径约束, A r g t i , A r g s j Arg^i_t, Arg^j_s Argti,Argsj分别是函数t的第i个参数和函数s的第j个参数. 形式化地, 检查
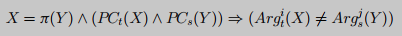
其中 X = [ x 0 , x 1 , . . . , x m ] X = [x_0, x_1, ..., x_m] X=[x0,x1,...,xm]表示函数t的参数和路径约束所使用的的符号列表, Y = [ y 0 , y 1 , . . . , y n ] Y = [y_0, y_1, ..., y_n] Y=[y0,y1,...,yn]是函数s的参数和路径约束所使用的的符号列表. 下图则是检查是否有排序 π ( Y ) \pi(Y) π(Y)在 P C t ( X ) ∧ P C s ( Y ) PC_t(X) \wedge PC_s(Y) PCt(X)∧PCs(Y)的条件下匹配X使得上述约束不可满足. 如果没有这样的排列, 那么 A r g t i , A r g s j Arg^i_t, Arg^j_s Argti,Argsj为等价的.

这种设计让BinUSE即使面对跨架构, 跨编译器, 混淆等, 也更加鲁棒和更可靠(less FNs). 虽然这种实际会增加FPs, 但是可以当做提升FP/FN比率的权衡. 除了排列之外, 在这一步中, 还将符号公式中表示内存地址的常数归一化. 我们采用一种直接的方法来确定表示内存地址的常数. 首先, 在逐个路径执行USE时, 只要观察到一个常量被用来构造代码指针的基址, 我们就将它标记为内存地址. 其次, 我们做了一个许多高级静态反汇编程序[47], [48], [49]所共享的假设, 这样一个常量将被视为内存地址, 如果它指向ELF格式可执行文件的数据或文本部分.
检查上述约束时, 我们将所使用的求解器Z3[50]的超时设置为N秒. 如果SMT求解器产生一个unsat, 或者它不能在N秒内找到一个sat解, 则两个函数调用参数被认为是等效的. 对于我们当前的实现, N被设置为15秒. 设置超时可能会导致不相等的参数被视为等效(即FPs). 然而, 设置超时并没有引入FN, 可以加速大规模二进制样本的分析.
Optimization
虽然本节中介绍的遍历策略可以包含大多数实际情况, 但可能存在一些极端情况来阻碍我们的分析. 特别是, 在执行路径上可能没有外部调用点. 在这种情况下, 我们不是简单地跳过这个路径分析, 而是从函数入口点收集路径约束PC, 直到到达执行路径末尾的返回指令(ret). 但是, 如果在遍历这条路径时不能构造任何路径条件, 则跳过比较这条路径. 从整体来看, 每个返回指令ret将被视为一个不带参数的特殊“外部调用点”, 为了确定是否可以匹配两条没有外部调用点的路径, 我们使用以下约束来检查它们相关的路径约束 P C t PC_t PCt和 P C s PC_s PCs.
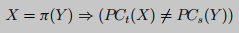
这种优化将用额外的节点扩展符号遍历期间生成的子图, 表示从没有外部调用点的执行路径收集的路径约束. 然后, 为了比较由汇编函数 f t f_t ft和 f s f_s fs导出的两个形成的子图 G t G_t Gt和 G s G_s Gs, 我们仍然交叉比较 G t G_t Gt和 G s G_s Gs上表示外部调用点的节点, 也交叉比较 G t G_t Gt和 G s G_s Gs上表示没有外部调用点的路径的节点.
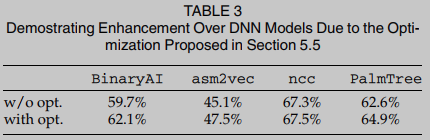
在表3中比较了四个评估DNN模型增强的top-1精度. 使用本节提出的优化后, BinUSE可以进一步提高DNN模型的精度, 平均提高约2.45%.
BOOSTING DNN-BASED TOOLS
简单来说, 当BinUSE 和 DNN-based models 达成共识时: f s ∈ P d n n ∧ f s ∈ P u s e f_s \in P_{d n n} \wedge f_s \in P_{u s e} fs∈Pdnn∧fs∈Puse, 则认为 f s f_s fs与目标函数相似. 算法1给出增强算法, P是最终预测结果, 元素是由两元组构成, 第一个是BinUSE的置信度分数, 第二个是DNN的置信度分数, 排序按照BinUSE高权重降序排列. 最后返回top-k的函数搜索结果.

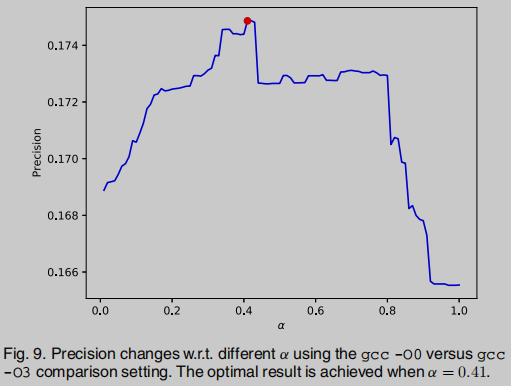
其中阈值 α \alpha α由实验选定, α \alpha α选择太高会过分相信BinUSE导致更多FPs, 太低则优化效果不足, 在0.41时效果最优, 因此选择 α = 0.41 \alpha = 0.41 α=0.41

实验
Implementation
我们在二进制分析框架angr[51]的基础上, 用大约5500行Python代码实现了BinUSE. 通过与流行的angr生态系统连接, 将汇编代码提升到平台中立的VEX中间语言, BinUSE可以处理来自不同架构的可执行文件. 更重要的是, angr中已经提供了一组丰富的分析工具(例如,符号执行), 因此可以节省从头开始构建它的工作.
Evaluation Setup
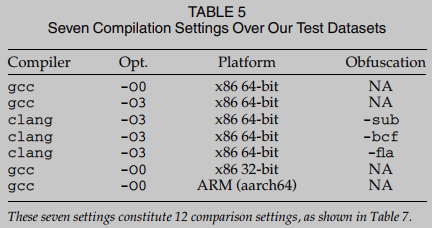
数据集和编译设置 使用Linux coreutils数据集评估BinUSE. Coreutils数据集包含106个程序. 用七种不同的设置来编译程序(见表5). 我们使用gcc 7.5.0和clang 4.0.1来编译程序. 我们编译没有优化(-O0)和最高优化(-O3)的程序. 为了便于跨架构比较, 我们在三个不同的架构上编译二进制代码, 32位x86、64位x86和ARM. 报告了每个用-O3选项编译的coreutils可执行文件平均有103.7个函数. 换句话说给定一对coreutils可执行文件, BinUSE需要交叉比较103.7 * 103.7的汇编函数. 此外使用Linux binutils数据集对BinUSE进行基准测试. Binutils数据集包含112个程序. 每个binutils可执行文件平均有1765.0个函数.
我们使用BinUSE增强了四个前沿的基于dna的二进制代码函数搜索工具:BinaryAI [15], asm2vec [14], PalmTree[18]和ncc[13]。
关于训练数据集选择的说明. 我们使用普通二进制代码来训练这些DNN模型, 而训练后的DNN模型则根据其在交叉编译器、交叉优化、交叉架构和混淆设置中的鲁棒性进行评估.
BinUSE Performance
表7报告了BinUSE在coreutils数据集上总共12个比较设置的性能. 大多数比较需要具有挑战性的交叉编译器、交叉优化和跨体系结构设置. 例如, 表7中的最后一个比较表明了一个非常困难的设置, 它是跨架构(ARM与x86 64位)、交叉编译器(gcc与clang)、交叉优化(-O0与-O3),还应用了控制流平坦化混淆(-fla),它广泛地改变了控制流结构.
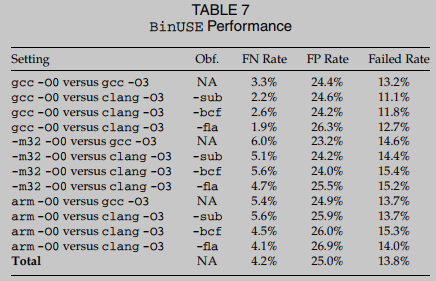
表7显示BinUSE在更多用控制流扁平化混淆-fla编译的函数检测时失败. 这种混淆将CFG转换为C switch语句, 并将基本块与调度节点拼接在一起. 代码指针经常在分派器节点中用于指导控制传输, 这在具体化符号代码指针时导致更高的失败几率.
Processing Time
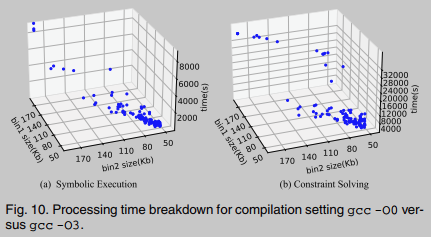
图10显示了gcc -O0与gcc -O3比较的处理时间分解. 我们分别在图10a和10b中报告了执行符号执行和求解约束的处理时间. 总的来说, 我们发现处理时间与可执行文件的大小成线性关系. 这是直观的:大的可执行文件有更多的功能, 从而延长了BinUSE的符号执行时间. 类似地, 大型可执行文件可能包含更复杂的符号约束, 从而延长了解决符号约束所需的时间. 然而, 可以看到大多数二进制代码样本可以在2000 CPU秒内分析符号执行, 4000 CPU秒内分析约束求解.
DNN Model Comparison
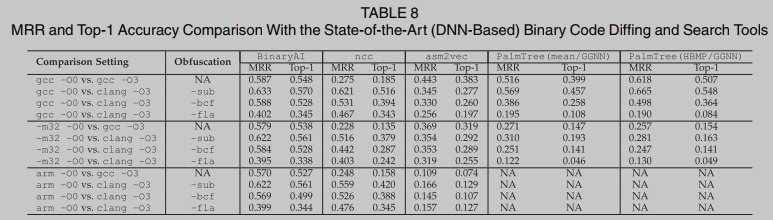
在12个比较设置上运行四个基于dnn的二进制函数搜索工具BinaryAI、asm2vec、ncc和PalmTree. PalmTree不能在ARM平台上处理可执行文件; 因此, 我们跳过了相应的计算. 表8总结了性能结果. BinaryAI在所有不同设置下的表现都优于所有模型. 虽然跨架构设置带来了重大挑战, 但BinaryAI似乎对跨架构更改更加健壮, 因为它从IDA-Pro[15]提升的平台中立微代码中学习. 混淆, 特别是控制流扁平化(-fla), 主要且持续地破坏了top-1的准确性. 当将二进制代码提升为LLVM IR作为ncc的输入时, 我们遇到了大量的逆向工程错误. 二进制提升器RetDec在处理某些二进制代码时抛出异常. 对于这种情况, 只测量成功处理的二进制代码的top-1(使用clang -O3编译的二进制代码大约有40%的剩余情况). 我们无法恢复asm2vec论文中报道的高精度:我们强调软件工程和安全社区都指出了类似的问题. 我们的评估显示asm2vec的top-1准确率为38.3%, 虽然低于其论文报道的准确率, 但与近期研究[16],[68],[69]的结果高度一致.
DNN Model Enhancement
为了衡量使用BinUSE对基于dnn的方法的增强, 我们尝试回答两个问题:1)RQ1: BinUSE能增强不同的基于dnn的二进制代码函数搜索工具吗? 和 2)RQ2: BinUSE能增强不同设置的BinaryAI吗? 对于RQ2, 我们将BinaryAI作为目标, 因为它的性能明显优于其他三个模型. 此外, 除了增强基于dnn的方法外, 我们还探索了RQ3: BinUSE是否足够通用, 可以增强基于程序结构级信息的常规二进制差分工具? 对于RQ3, 我们测试了一个流行的二进制差分工具FuncSimSearch[70], 该工具由谷歌Project Zero开发和维护.
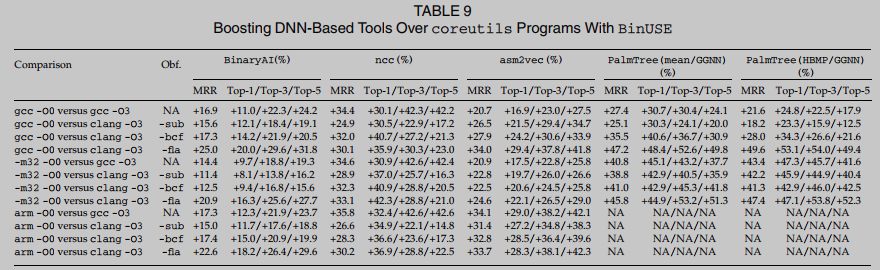
RQ1. 表9给出了不同设置下的评估结果. 我们一致地衡量前1、前3和前5的增强. 表9显示, 使用BinUSE可以显著改善所有基于dnn的方法. DNN模型通常从粗粒度的代码特征中学习, 这些代码特征对各种具有挑战性的设置没有弹性, 因此会产生非常高的假警报. BinUSE旨在以一致的方式解决它们的关键限制.
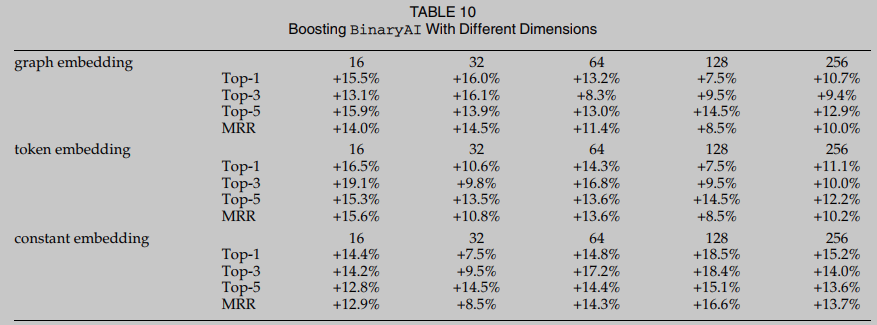
RQ2. 为了回答RQ2, 我们研究了与嵌入向量维度相关的表示学习的三个关键超参数. 一般来说, 不同的维度主要影响模型的准确性:较长的嵌入可以传递输入数据的微妙信息, 而较小的嵌入可能不能很好地表示语义. 然而, 较长的向量意味着模型训练面临更多的挑战, 并可能潜在地破坏模型的鲁棒性. BinaryAI包含三个与嵌入维数相关的超参数, 分别是令牌嵌入维数、常数嵌入维数和图嵌入维数. 表10报告了对于所有超参数, 尽管嵌入维度不同, BinUSE一致地提高了精度. 总的来说, 这个评估揭示了一个直观的观察结果:尽管模型设置发生了变化, 等价性检查始终能够解决高虚警, 从另一个重要方面表明BinUSE的泛化性.
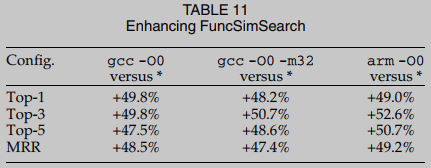
RQ3. 本研究主要关注基于dnn的二进制代码函数搜索, 因为基于dnn的方法表现出很高的准确性, 并且在很大程度上优于传统的基于程序结构的算法, 如图同构[71]. 然而, 很容易看出BinUSE不仅限于增强基于dnn的方法. 原则上, 我们认为基于程序结构的二进制差分通常会产生低可辩性和低鲁棒性的预测. 通过使用BinUSE来提升一种最先进的二进制差分工具FuncSimSearch, 从经验上验证了我们的论点, 该工具在控制流图上计算Simhash分数, 以有效地确定装配函数的距离. 评估结果如表11所示. 与当代基于dnn的方法相比, FuncSimSearch的结果要差得多. 因此, BinUSE可以在很大程度上提高所有评估设置的准确性. 在asm2vec论文中也指出了FuncSimSearch相对较低的精度.
总体而言, 本节中的评估一致表明, BinUSE可以以通用、高效和独特的方式增强流行的基于结构(DNN)工具产生的高虚假警报. 因此, 我们提倡将二进制代码搜索与BinUSE结合起来, 在生产使用中实现协同效应.
Vulnerable Function Searching
通过应用BinUSE将漏洞搜索任务扩展到公共漏洞数据集, 启动了一个案例研究. 这个应用程序模拟了一个常见的安全使用场景: 给定一个来自可疑可执行文件片段的程序集函数f, 我们根据具有已知漏洞的函数数据库D进行搜索, 并确定f是否可以与D中的任何函数匹配. 在这一步, 我们分别使用-sub、-bcf、-fla和-hybrid四个混淆设置, 将D中的示例编译到汇编函数的数据库Dasm中. 注意, 混合设置(称为-hybrid)在编译期间将所有三种混淆方法结合在一起. 我们还在编译每个示例程序和目标函数时启用完全优化-O3。简而言之, 给定一个具有已知漏洞的高度优化(-O3)汇编函数, 我们从Dasm检索其匹配的函数, 并检查其正确匹配, 具有相同漏洞的函数是否存在于排名前1的候选函数中.
在这一步, 我们测量asm2vec、BinaryAI和两个版本的PalmTree. 我们忽略了评估ncc, 因为我们发现它采用的二进制提升器在处理这些现实世界复杂软件时失败了太多情况. 我们在表12、13、14和15中报告每种设置的评估结果. asm2vec似乎很难与OpenSSL和Wireshark抗衡, 因为这两个程序都非常复杂. 对于OpenSSL和Wireshark的三个版本, asm2vec对真实匹配的排名要低得多. 例如, asm2vec对OpenSSL (ver)中的Heartbleed漏洞进行了真实匹配排名. 这意味着用户可能需要手动比较Dasm中至少17个程序副本, 以确认可疑输入中存在Heartbleed漏洞. 相比之下, BinUSE可以成功地将可疑输入与Dasm中top- 1的Heartbleed漏洞匹配. 在分析另一个臭名昭著的CVE ws-snmp时, asm2vec的准确性也低得多. 我们发现该漏洞包含一个很大的CFG, 这可能阻碍了asm2vec基于随机游走的图级嵌入计算. 综上所述, 在BinUSE的帮助下, asm2vec可以将真正的脆弱函数放在top-1.
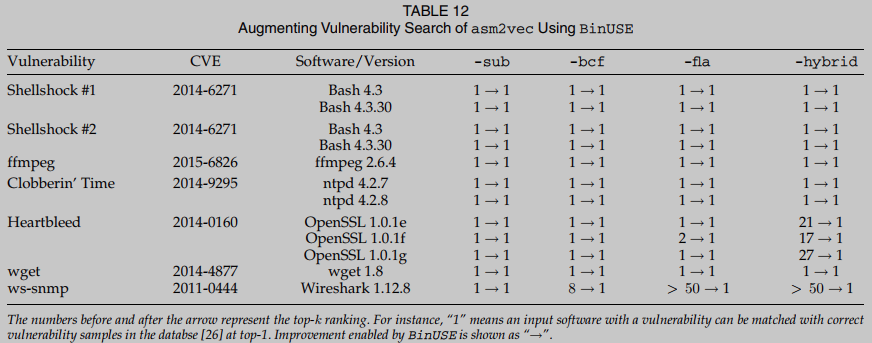
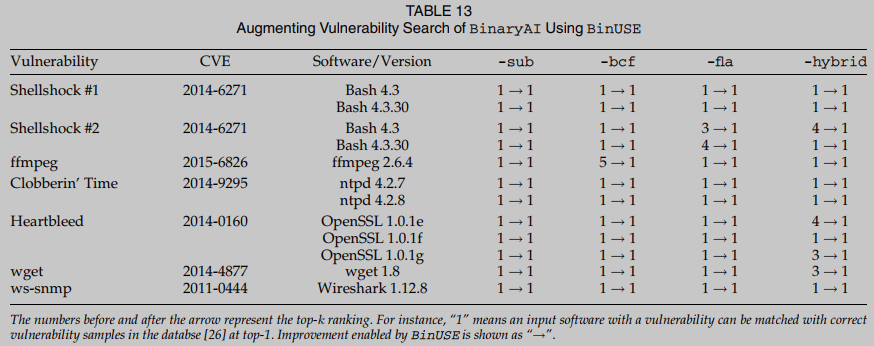

简而言之, 本节中的评估揭示了在使用BinUSE分析真实应用程序以实现安全目的时非常令人鼓舞的结果. 本节中的计算证明了在执行函数匹配时考虑细粒度调用点信息的必要性.
Extension of BinUSE
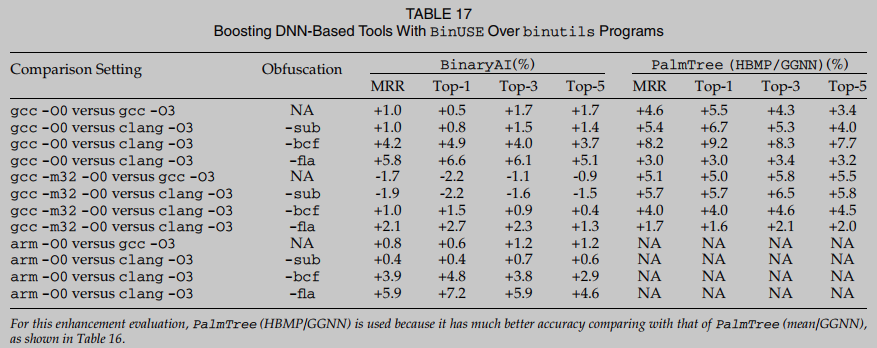
将 f t f_t ft与每个函数 f ∈ R P f \in RP f∈RP进行比较仍然是昂贵的. 在本节中, 我们将研究BinUSE的可能扩展; 我们的目标是通过优先比较DNN模型返回的前top-k个函数来降低成本.比如k=100, 一旦DNN模型确定了与目标函数 f t f_t ft匹配的前100个函数, BinUSE将这100个排名函数与 f t f_t ft进行比较, 重新排序调整它们的排名. 通过这种方式, BinUSE的比较从RP的大小减少到仅100, 降低了分析双utils程序时的成本. 然而, 由于BinUSE只访问和重新排序DNN模型排名的前100个装配函数, 增强的top-k精度(其中k=100)受DNN模型的前100个精度的限制. 换句话说, 如果目标DNN模型精度较低, 即使是top-100, 增强的机会也很小.
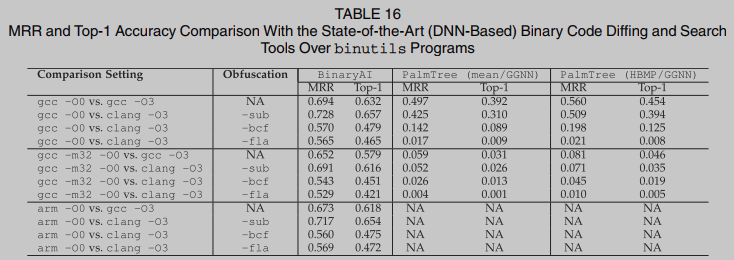
表17中报告了对BinaryAI和PalmTree的增强. 在这个表中, 我们评估了12个比较设置. 与BinaryAI相比, BinUSE对PalmTree的增强程度更高. 这主要是由于PalmTree在双utils测试用例上的准确性相对较低, 留下了更多增强的机会. 另一方面, 与coreutils数据集上的评估相比, BinUSE的增强效果较低. 除了分析binutils函数的一般困难之外, 对于这次评估, BinUSE只分析基于dnn的工具返回的前100个函数. 根据我们的观察, 一些真正的匹配甚至不在前100个函数之内. 为了进一步探索更高程度的准确性增强, 用户可以考虑利用基于dnn的工具返回的top-150或top-200函数.
总结
References
[6] U. Alon, M. Zilberstein, O. Levy, and E. Yahav, “Code2Vec: Learning distributed representations of code,” in Proc. ACM Program. Lang., 2019, pp. 1–29.
[7] U. Alon, S. Brody, O. Levy, and E. Yahav, “code2seq: Generating sequences from structured representations of code,” 2018, arXiv:1808.01400.
[8] F. Zuo, X. Li, P. Young, L. Luo, Q. Zeng, and Z. Zhang, “Neural machine translation inspired binary code similarity comparison beyond function pairs,” in Proc. Netw. Distrib. Syst. Secur. Symp., 2019.
[9] S. Eschweiler, K. Yakdan, and E. Gerhards-Padilla , “discovRE: Efficient cross-architecture identification of bugs in binary code,” in Netw. Distrib. Syst. Secur. Symp., 2016.
[10] J. Gao, X. Yang, Y. Fu, Y. Jiang, and J. Sun, “VulSeeker: A semantic learning based vulnerability seeker for cross-platform binary,” in Proc. 33rd ACM/IEEE Int. Conf. Automated Softw. Eng., 2018, pp. 896–899.
[11] S. Luan, D. Yang, K. Sen, and S. Chandra, “Aroma: Code recommendation via structural code search,” , 2018. [Online]. Available: http://arxiv.org/abs/1812.01158
[12] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection,” in Proc. ACM SIGSAC Conf. Comput. Commun. Secur., 2017, pp. 363–376.
[13] T. Ben-Nun , A. S. Jakobovits, and T. Hoefler, “Neural code comprehension: A learnable representation of code semantics,” in Proc. 32nd Int. Conf. Neural Inf. Process. Syst., 2018, pp. 3589–3601.
[14] S. H. H. Ding, B. C. M. Fung, and P. Charland, “Asm2Vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization,” in Proc. IEEE Symp. Secur. Privacy, 2019, pp. 472–489.
[15] Z. Yu, R. Cao, Q. Tang, S. Nie, J. Huang, and S. Wu, “Order matters: Semantic-aware neural networks for binary code similarity detection,” in Proc. AAAI Conf. Artif. Intell., 2020, pp. 1145–1152.
[16] Y. Duan, X. Li, J. Wang, and H. Yin, “DEEPBINDIFF: Learning program-wide code representations for binary diffing,” in Proc. 27th Annu. Netw. Distrib. Syst. Secur. Symp., 2020.
[17] B. Liu et al., “diff: Cross-version binary code similarity detection with DNN,” in Proc. 33rd IEEE/ACM Int. Conf. Automated Softw. Eng., 2018, pp. 667–678.
[18] X. Li, Q. Yu, and H. Yin, “PalmTree: Learning an assembly language model for instruction embedding,” in Proc. ACM SIGSAC Conf. Comput. Commun. Secur., 2021, pp. 3236–3251
[35] C. A. R. Hoare, “How did software get so reliable without proof?,” in Proc. Int. Symp. Formal Methods Eur., 1996, pp. 1–17.
[36] E. Gunnerson, “Defensive programming,” in A Programmer’s Introduction to C#, New York, NY, USA: Apress, 2001.
[37] M. Stueben, “Defensive programming,” in Good Habits for Great Coding, New York, NY, USA: Apress, 2018.
[43] T. Bao, J. Burket, M. Woo, R. Turner, and D. Brumley, “ByteWeight: Learning to recognize functions in binary code,” in Proc. 23rd USENIX Secur. Symp., 2014, pp. 845–860.
[44] Fast Library Identification and Recognition Technology, 2021. [Online]. Available: https://www.hex-rays.com/products/ida/tech/flirt/
[45] E. C. R. Shin, D. Song, and R. Moazzezi, “Recognizing functions in binaries with neural networks,” in Proc. 24th USENIX Conf. Secur. Symp., 2015, pp. 611–626.
[46] Y. Lin and D. Gao, “When function signature recovery meets compiler optimization,” in Proc. IEEE Symp. Secur. Privacy, 2021, pp. 36–52.
[51] Y. Shoshitaishvili et al., “SOK: (State of) the art of war: Offensive techniques in binary analysis,” in Proc. IEEE Symp. Secur. Privacy, 2016, pp. 138–157.
[68] Y. Hu, H. Wang, Y. Zhang, B. Li, and D. Gu, “A semantics-based hybrid approach on binary code similarity comparison,” IEEE Trans. Softw. Eng., vol. 47, no. 6, pp. 1241–1258, Jun. 2021.
[69] J. Jiang et al., “Similarity of binaries across optimization levels and obfuscation,” in Proc. Eur. Symp. Res. Comput. Secur., 2020, pp. 295–315.
[70] FunctionSimSearch, 2021. [Online]. Available: https://github.com/googleprojectzero/functionsimsearch
[71] H. Flake, “Structural comparison of executable objects,” in Proc. Int. GI Workshop Detection Intrusions Malware Vulnerability Assessment, 2004, pp. 161–174.
Insights
Authors
(1) 通过不同优化选项和混淆的二进制程序增强DNN模型的训练效果 (类似unleashing power那篇论文
(2) ncc 的复现效果远比论文的低
(3) 执行函数匹配时应该考虑细粒度调用点信息
(4) 可解释人工智能(XAI)技术的最新进展已经能够识别DNN模型决策方面最具影响力的代码. 因此使用XAI技术标记有影响的代码片段c1和c2, 这主要负责DNN模型匹配汇编函数f1和f2的决定. 然后可以对标记的c1和c2启动BinUSE, 以检查它们的语义等价性, 具有影响力的代码片段可以减少检查成本, 不过挑战在于如何区分影响力代码片段的边界以及维护代码片段的路径约束.
Mine
(1) 单架构的工作实验时, 可以放弃跨架构测试, 比如palmtree只在x86上进行实验
(2) retdec提升失败的例子可以抛弃, 只保留成功的样本进行实验
(3) 使用自注意力机制识别高影响力代码片段自动调整代码嵌入的计算权重?