本篇文章将介绍一个新的工具——jsoup,使用它,我们可以解析网页,按照我们的想法,从网页中提取出有用的数据。配合之前介绍的httpclient,也就可以满足一个最基本爬虫的功能了。
首先,应该把获取到的网页信息转化成jsoup认识的数据结构,jsoup提供了如下的api,其返回的对象为Document:
static Document parse(File in, String charsetName) static Document parse(File in, String charsetName, String baseUri) static Document parse(InputStream in, String charsetName, String baseUri) static Document parse(String html) static Document parse(String html, String baseUri) static Document parse(URL url, int timeoutMillis)
可见,jsoup可以从文件中、字符串、url中解析html。
当jsoup将html转成Document之后,就可以做进一步的解析了,这次先总体介绍一些方法,详细及进阶使用将在之后做介绍。
1.通过选择器解析html:
jsoup提供了类似css、jquery的元素选择器,可以通过select()方法来解析,其返回对象为Elements,例如,以下代码可以获取class为“listContent”的ul标签下的所有li标签的元素:
Elements elements = doc.select("ul.listContent li");
2.通过api解析html:
jsoup也提供了java api,举例如下,注意返回对象的不同,有Element和Elements之分:
Element ele = getElementById(String id) //根据id来获取元素 Elements eles = getElementsByTag(String tagName) //根据tag名称来获取元素 Elements eles = getElementsByClass(String className) //根据class名称来获取元素
至此,通过jsoup已经解析到了所需的元素了,但是我们最终需要的是元素中的数据,这在jsoup中也提供了获取方法,举例如下:
.attr(String key) //获得元素的数据 .attributes() //获得所有属性 .id(), .className() .classNames() //获得id class的值 .text() //获得文本值 .html() //获取html .tagName() //获得tagname
掌握了以上jsoup的基本操作之后,可以来小试牛刀一下了,还是以百度首页为例,结合上一篇文章中封装好的方法,来获取以下数据:
- 百度logo点击进去的网页地址
- 右上角的导航栏文字及其对应的网址

首先F12打开开发者工具,在百度logo上右键-检查,可以看到logo所在位置的层级结构,经过分析,可以尝试使用css选择器来获取到它,其选择器对应的代码为:
#lg map area
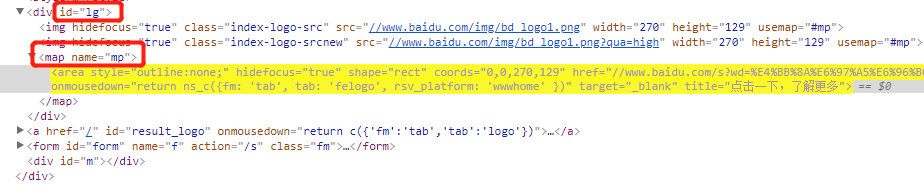
再来看右上角导航栏的层级结构,分析得出,它们在id为“u1”的ul标签下,所有的a标签,这次我们尝试使用jsoup的api来获取:

分析完成之后,可以开始写代码了,完整代码如下所示:
public static void main(String[] args) throws Exception {
//需要获取数据的url
String url = "https://www.baidu.com";
//指定编码
String charset = "utf-8";
//设置请求头
Map<String, String> headers = new HashMap<>();
headers.put("Host", "www.baidu.com");
headers.put("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " +
"Chrome/66.0.3359.181 Safari/537.36");
//调用封装好的方法,请求网页
String html = MyHttpClient.get(url, charset, headers);
//使用jsoup将网页html转成Document对象
Document doc = Jsoup.parse(html);
//通过css选择器获取logo元素
Element logoEle = doc.select("#lg map area").first();
//获取logo元素的href属性,其值为点击logo后跳转到的网页地址
String logoUrl = logoEle.attr("href");
System.out.println("logo地址:" + logoUrl);
//通过jsoup api获取导航栏元素
Elements navBarEles = doc.getElementById("u1").getElementsByTag("a");
for (Element element : navBarEles) {
//获取每个元素中的文本
System.out.println("key:" + element.text());
//获取每个元素对应的url
System.out.println("value:" + element.attr("href"));
System.out.println("=================");
}
}
这样,一个最基本的爬虫雏形已经完成了!使用自己封装好的请求网页的方法,代码很简洁,可以完全把精力放在解析网页上。之后,我们将拿一个复杂一些的网站来练练手,编写一个有点用处的爬虫,嘿嘿。