爬虫基本步骤
对于一般的爬虫而言,其基本步骤:
- 找到需要爬取内容的网页URL;
- 打开该网页的检查页面,即F12查看HTML代码;
- 在HTML中挑选你想提取的数据;
- 通过代码进行网页请求(将html文件下载到本地)、解析(从html中自动解析出你想要的数据)
- 存储数据。
爬虫是典型的入门门槛低,但进阶难度高,进阶的反反爬虫的难度能玩死人。
爬虫有哪些工具呢?或者说有哪些框架呢?
很多。
比如说:
Scrapy框架,这是一个比较成熟的python爬虫框架,可以高效爬取各种web页面并提取结构化信息;
同样的还有Crawley框架、据说是可以允许没有编程基础的用户可视化爬取网页的Portia框架、专门用来提取新闻和文章以及内容分析的newspaper框架等等等。
其中最流行的框架,莫过于Scrapy框架,建议的确有爬虫想法的同学可以试着学习这个。
但是这里我们不讲,因为入门只需要一个requests+bs4就可以。requests库对新手真的是很友好,可以供新手做一些简单的任务,但是真正的大批量的爬虫,这个可能就不合适了。最大的原因是,requests是同步,而非异步,所以它在http请求的时候,IO会卡住,直到网站返回,所以会让整体的爬取速度变慢。
那有没有支持异步的类requests库呢?
有的。
比如说纯异步框架aiohttp、asks库、vibora等。
不过这里为了讲解的方便,以及节省其他的学习成本,下面我们以传统的requests+bs库来做爬虫的爬取和解析。
如何发起网页请求
最常用的是requests库,一个非常流行的http请求库。这里请求的是网页的html信息。
服务器收到请求后,会返回相应的网页对象。
requests的安装
首先我们需要安装requests库:
pip install requests
requests的使用
然后我们来简单使用一下,访问一个网址,并拿回它响应的html文件,即结构化数据。
import requests
# 设置请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
r = requests.get(
url='https://www.taikang.com/',
headers=headers
)
# 设置编码格式
r.encoding='utf8'
# 输出响应内容
print(r.text)
如何解析拿到的HTML
再上一步中,我们已经通过requests,拿到了响应的HTML文档,我们需要的信息都在这个HTML文档里。
那如何从这里抽取出我们需要的信息呢?
你需要一个XML文档的解析包,python中有很多这种库包,比如说xpath,比如说beautifulsoup4。
没有比较过这些解析包的优劣,我很早之前学爬虫的时候,选择的是beautifulsoup4,即bs4。
pip install beautifulsoup4
bs4的完整使用,可以见参考文献3中的bs4官方文档,这里只介绍简单的使用。
以上一步中拿到的html为例,假设我想得到网站中的下面数据:

当然,首先我需要在html中定位,看这几个数字位于html哪个标签下,经过探查,发现是在这里:
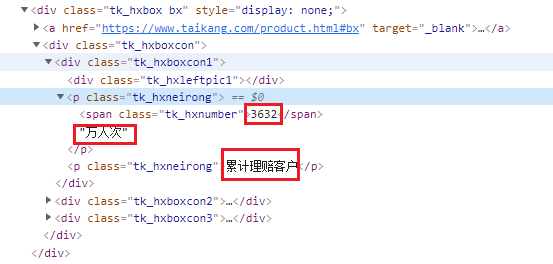
好的,接下来就是一级一级解析了,我需要从body标签一级一级往下,一层一层的剥开div,找到这个数字。
话不多少,以下是代码:
import re
import requests
from bs4 import BeautifulSoup
# 设置请求头信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36'}
r = requests.get(
url='https://www.taikang.com/',
headers=headers
)
# 设置编码格式
r.encoding='utf8'
# 输出响应内容
# print(r.text)
# 开始解析HTML
soup = BeautifulSoup(r.text, 'lxml')
# bs的标签过滤器
# res = soup.find_all('p', class_='tk_hxneirong')
# res = soup.find_all('div', class_='tk_hxboxcon1')
res = soup.find_all('div', class_=re.compile('tk_hxboxcon[0-9]')) # 模糊匹配
for r in res:
print('-----')
# print(r)
if len(r.get_text()) > 0: # get_text拿到tag以及子孙tag中的文本内容
# print(r.get_text().strip('\r\n'))
print(r.get_text().replace('\n', '').replace('\r', '')) # 删掉回车和换行,win下用\r\n换行,linux用\n
# print(res)

上面是结果,预期目标成功完成。
反爬虫与反反爬虫机制
网站为了防止自身的数据被随意抓取,造成信息泄露或者服务器无用压力,会进行一系列的措施来使得本身数据不易被别的程序爬取,这些措施就是反爬虫。
比如检测IP访问频率、监控资源访问速度、请求的链接是否带有关键参数、验证码检测、ajax混淆、js加密等等。
对于目前市场上的反爬虫,爬虫工程师常用的反反爬虫方案主要有:
- 不断试探目标底线,试出单IP下最优的访问频率(有的网站,对于单位时间内访问量超过阈值的IP,是直接做封禁处理的);
- 构建自己的IP代理池;
- 维护一份自己常用的UA库;
- 针对目标网页的Cookie池;
- 需要JS渲染的网页使用无头浏览器进行代码渲染再抓取;
- 一套破解验证码程序;
- 扎实的JS知识来破解混淆函数
爬虫和反爬虫永远处于一个此起彼伏此消彼长的博弈状态:
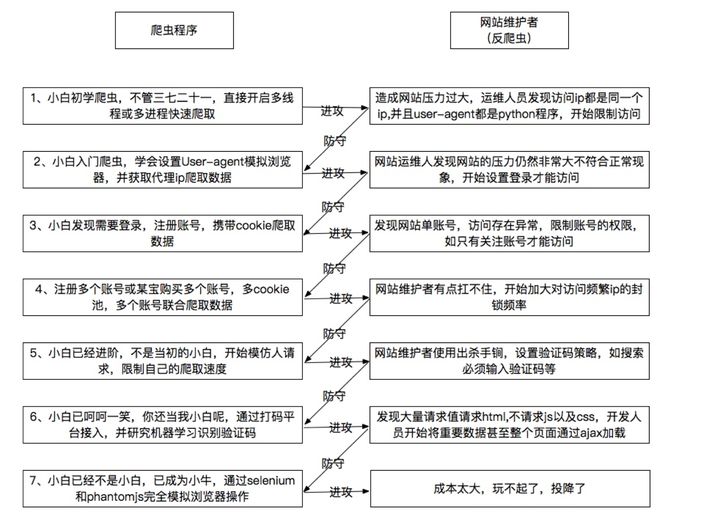
(上图忘记是从哪儿下的了)
通过User-Agent来控制访问
无论是浏览器还是爬虫程序,在向服务器发起网络请求的时候,都会发过一个请求头文件,来表明自己的身份。
一个请求头由很多元素组成,最重要的就是User-Agent。
很多网站都会建立自己的User-Agent白名单,只有属于正常范围的user-agent才能进入访问。
通过JS脚本加密来防止爬虫
原理是什么呢?
举个例子,在发起请求之前,网站会通过js代码生成一大堆随机的数字,然后要求浏览器通过js的运算得到这一串数字的和,再返回给服务器。
解决方法:使用PhantomJS
* PhantomJS是一个Python包,他可以在没有图形界面的情况下,完全模拟一个”浏览器“,js脚本验证什么的再也不是问题了。
不过好像PhantomJS现在已经停止更新了
通过IP限制来反爬虫
如果一个固定的ip在短暂的时间内,快速大量的访问一个网站,那自然会引起注意,管理员可以通过一些手段把这个ip给封了,爬虫程序自然也就做不了什么了。
解决方法:
比较成熟的方式是:IP代理池
简单的说,就是通过ip代理,从不同的ip进行访问,这样就不会被封掉ip了。不过IP代理的获取比较麻烦,网上倒是有免费渠道,但是质量都不咋地。
通过单位时间内访问次数来反爬虫
有规律的sleep进程就可以。
比如随机1-3秒爬一次,爬10次修复10s,且每天只在8-12和18-20点之间爬,隔几天还休息一下,旨在尽力混淆人和爬虫。
对付这种爬虫,稍微有点麻烦,可以采用时间窗口+阈值的方式来反爬虫,比如说3个小时内总请求次数超过50次就禁止该IP的访问,或者是弹出验证码之类的。
验证码机制来反爬虫
比如说之前说的12306的图片验证码机制,不过现在的打码平台+机器学习已经很成熟了,这种方式也不保险了。
或者是干脆使用带验证码登录的cookie来绕过登录,直接在web上登陆之后取下cookie并保存然后带上cookie做爬虫,但这不是长久的方法,因为cookie隔一段时间会失效。
所以,反爬虫的结论是:在爬虫与反爬虫的对弈中,爬虫一定会胜利。因为只要人类能够正常访问的网页,爬虫在具备同种资源的情况下就一定可以抓取到(比如说基于selenium)。
进阶
http请求头
什么是http请求头?
当你使用http或者https协议请求一个网站的时候,你的浏览器会向对方的服务器发送一个http请求报文,这个请求报文由三部分组成:
请求行 + 请求头 + 请求体
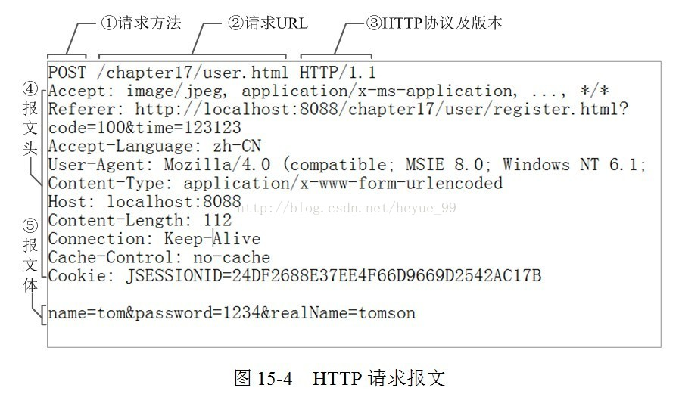
下面是一个请求头的详细介绍
需要注意的是,不同网页的请求头参数数量是不一样的。
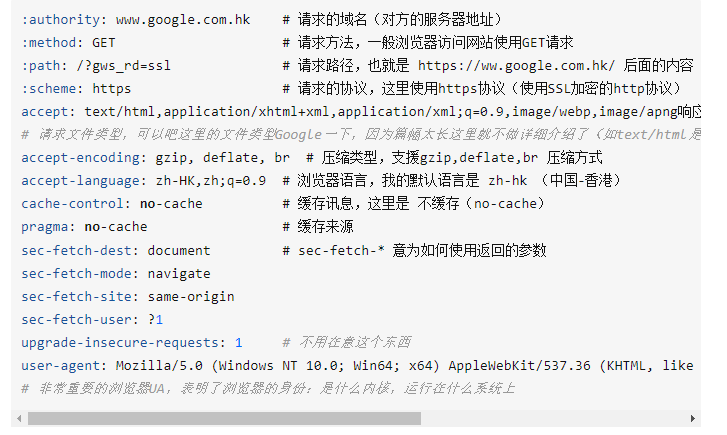
上图出处忘了。。
User-Agent
user-agent是做什么的呢?
user-agent会告诉网站服务器,访问者是通过什么工具来请求的,是爬虫还是用户浏览器。有的网站会直接拒绝爬虫请求,而只应答用户浏览器请求。所以我们在写爬虫的时候,需要伪造一个请求头来欺骗网站。
在requests中,如果不显式构造请求头的话,那我们写的爬虫请求会老老实实的告诉服务器:我是一个python爬虫请求。
import requests
r = requests.get(
url='https://www.taikang.com/'
)
# 输出默认的请求头
print(r.request.headers)
输出:
{
'User-Agent': 'python-requests/2.27.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
所以,我们最好伪装出一个请求头。
如何查看自己浏览器的请求头呢?
很简单。
- 打开要爬虫的网页;
- F12打开开发者界面;
- 按F5刷新网页;
- 点击Network,随意点击一个requests;
- 点击Headers,查看Request Headers的User-Agent字段,直接复制
- 将刚才复制的User-Agent字段构造成字典形式。
于是一个请求头构造完毕。
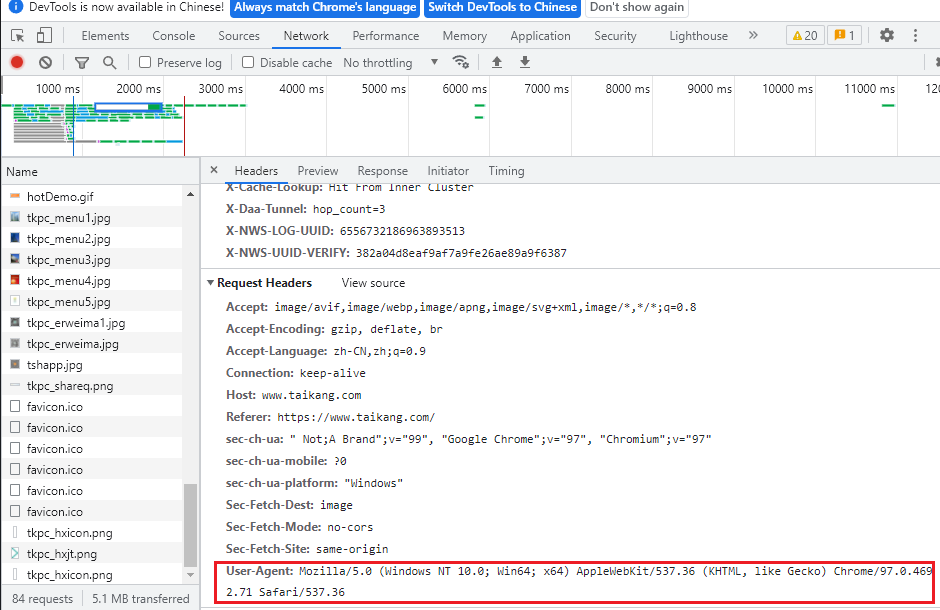
User-Agent各部分代表了什么意思呢?
简单的讲,
Mozilla/5.0 (平台) 引擎版本 浏览器版本号
第一部分的Mozilla,是历史遗留问题。由于历史上的浏览器大战,当时想获得图文并茂的网页,就必须宣称自己是 Mozilla 浏览器。此事导致如今User-Agent里通常都带有Mozilla字样,出于对历史的尊重,大家都会默认填写该部分。
第二部分表示平台。
这部分由多个字符串组成,用英文半角分号分开。
Windows NT 10.0表示使用的操作系统版本,Win64;x64表示操作系统是64位的。
Windows NT 5.0 // 如 Windows 2000
Windows NT 5.1 // 如 Windows XP
Windows NT 6.0 // 如 Windows Vista
Windows NT 6.1 // 如 Windows 7
Windows NT 6.2 // 如 Windows 8
Windows NT 6.3 // 如 Windows 8.1
Windows NT 10.0 // 如 Windows 10
Win64; x64 // Win64 on x64
WOW64 // Win32 on x64
Linux系统下:
X11; Linux i686; // Linux 桌面,i686 版本
X11; Linux x86_64; // Linux 桌面,x86_64 版本
X11; Linux i686 on x86_64 // Linux 桌面,运行在 x86_64 的 i686 版本
macos下:
Macintosh; Intel Mac OS X 10_9_0 // Intel x86 或者 x86_64
Macintosh; PPC Mac OS X 10_9_0 // PowerPC
Macintosh; Intel Mac OS X 10.12; // 不用下划线,用点
第三部分表示引擎版本
AppleWebKit/537.36 (KHTML, like Gecko)…Safari/537.36
为什么写成这样,原因很复杂。
历史上,苹果依靠webkit内核开发出了Safari浏览器,WebKit内核包含了WebCore引擎,而WebCore引擎又是从KHTML衍生而来。
同时由于历史原因,KHTML引擎在使用的时候,必须声明自己是类似 Gecko的,因此写成了“like Gecko”。
再后来,Google开发Chrome也使用了WebKit内核,于是也跟着这么写了。
再再后来,Chrome希望自己能得到为Safari编写的网页,于是决定装成Safari,这就是为什么引擎版本里有Safari的版本。
一句话来讲,Chrome伪装成Safari,而Safari使用了WebKit渲染引擎,而WebKit是从KHTML引擎衍生而来的,而KHTML引擎必须声明自己是like Gecko 引擎。同时,所有的浏览器必须宣称自己是Mozilla。
不过,后来Chrome 28某个版本改用了blink内核,但还是保留了这些字符串。而且,最近的几十个版本中,这部分已经固定,没再变过。
第四部分是浏览器版本。
这个没什么好讲的,我用的就是chrome嘛。
最后,竟然有大佬已经封装了不同操作系统不同浏览器的User-Agent,见参考文献2。
from fake_useragent import UserAgent
ua = UserAgent()
ua.ie
# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua.msie
# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
ua['Internet Explorer']
# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
ua.opera
# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
ua.chrome
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua.google
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua['google chrome']
# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua.firefox
# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua.ff
# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua.safari
# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25
# and the best one, random via real world browser usage statistic
ua.random
参考文献
- HTTP请求头之User-Agent 写的非常棒
- github-fake-useragent 竟然已经有大佬把请求头给封装了
- Beautiful Soup 4.4.0 中文文档
- 如何应对网站反爬虫策略?如何高效地爬大量数据? - fireling的回答 - 知乎
- [Python有哪些常见的、好用的爬虫框架? - 麻瓜编程的回答 - 知乎][https://www.zhihu.com/question/60280580/answer/617068010]
- Python有哪些常见的、好用的爬虫框架? - 小小造数君的回答 - 知乎 介绍了常见的python爬虫框架,并做了使用上的简单介绍。
- 超详细教程:什么是HTTP请求头/响应头 对请求头和响应头描述的比较详细,可能开头写的不是很好,对请求报文的理解,推荐看下一篇
- HTTP请求报文(请求行、请求头、请求体)