@[TOC]电子产品销售数据分析目录
数据参数的介绍
数据库的导入
缺失值重复值的处理
计算每月消费总金额
每月消费总金额
用户分析
品牌销售额
用户消费行为可视化
数据参数介绍
event_time -购买时间
order_id -订单编号
product_id -产品编号
category_id -产品的类别ID
category_code -产品的类别分类法(代码名称)
brand -品牌名称
price -产品价格
user_id -用户ID
数据库的导入
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import datetime as datetime
import math
plt.rcParams['font.sans-serif'] = ['SimHei'] #设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False #正常显示负号
pd.set_option('display.float_format',lambda x : '%.2f' % x)#pandas禁用科学计数法
读取数据
data = pd.read_csv('F:/数据集/kz.csv')
data.head()
data.info()

数据预处理
data.isnull().sum()
# 删除所有有缺失值的行
data = data.dropna()
# 将时间列更改为时间类型
data['event_time'] = pd.to_datetime(data['event_time'])
按月份分析用户的消费趋势
# 去掉category_id、user_id的小数
data['category_id'] = data['category_id'].astype(np.int64,errors='ignore')
# data.info()
data['category_id'].dtype
计算每月消费总金额
# 解释:消费金额以用户Id来分组并求和
# 先计算出每个id同一产品的消费次数,增加购买数量和购买总价的列
# 购买数量的列
buy_cnt = data.groupby(['order_id','product_id']).agg(buy_cnt=('user_id','count'))
data = pd.merge(data,buy_cnt,on=['order_id','product_id'],how='inner')
data = data.drop_duplicates().reset_index(drop=True)
# 购买总价列
data['buy_amount']=data['buy_cnt']*data['price']
# 每月消费总金额
# 计算Gmv是商品交易总额
data['day'] = data['event_time'].apply(lambda x:x.day)
# 计算每月的GMV
GMV_month = data.groupby(data['month']).agg(GMV=('buy_amount','sum'))
GMV_month.sort_values(by='GMV',ascending=False)
# 8月是商品交易总额最大的时候,从6月开始增加,从8月开始减小
销售总额可视化
plt.plot(GMV_month.index,GMV_month['GMV'])
plt.title('每月销售总额')
plt.show()
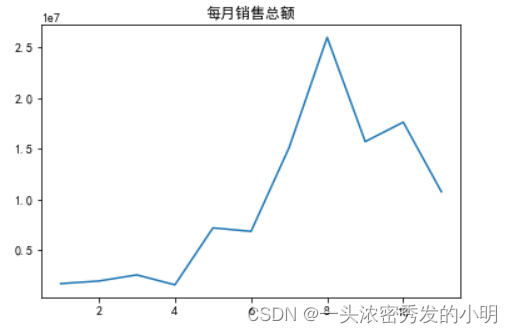
8月的时候销售总额达到最高值,6月开始到8月销售额快速上升
用户分析
每月消费人数
data[‘user_id’].sort_values().unique()
# 用户消费次数
num_cnt = data.groupby([‘user_id’,‘month’])[‘price’].count()
num_cnt
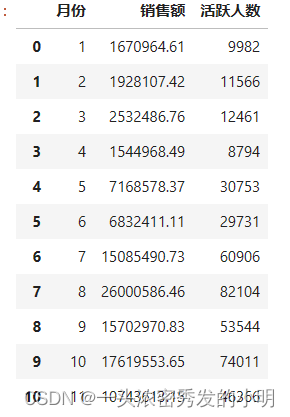
# 按月统计活跃人数
month_num_count = data.groupby([‘month’])[‘price’].agg([‘sum’,‘count’]).reset_index().rename(columns={‘sum’:‘销售额’,‘month’:‘月份’,‘count’:‘活跃人数’})
month_num_count
用户消费可视化
plt.plot(month_num_count.index,month_num_count['活跃人数'])
plt.title('每月消费人数')
plt.xlabel('消费月份')
plt.ylabel('活跃人数')
plt.legend('人数')
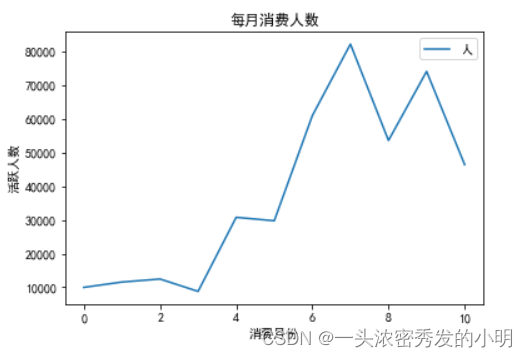
从三月开始有上升,四月下降之后,开始急速上升直到7月
7月到10月是消费高峰期,其他月份的消费额和活跃人数相对较少
品牌销售额分析
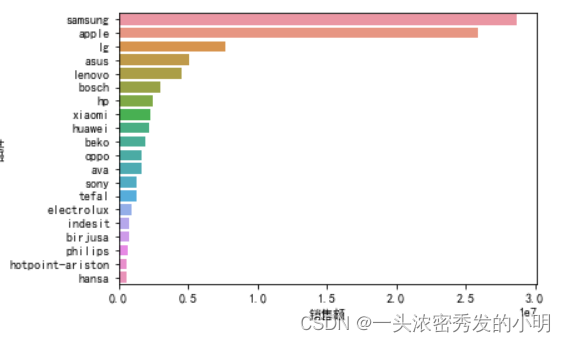
groud_sum = data.groupby('brand')['price'].agg('sum').reset_index().rename(columns={'brand':'品牌','price':'销售额'})
groud_sum20 = groud_sum.sort_values(by='销售额',ascending=False)[:20]
groud_sum20
# 列举出前二十名
sns.barplot(x='销售额',y='品牌',data=groud_sum20)
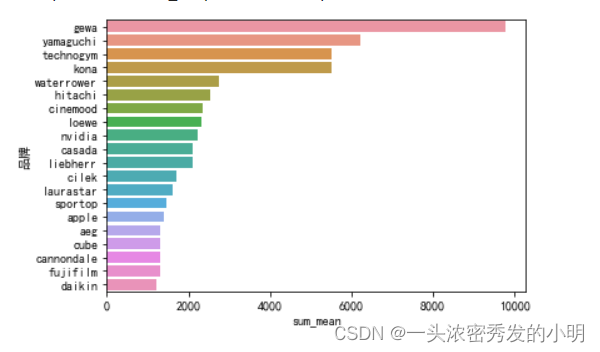
人均销售额可视化
brand_cnt['sum_mean'] = groud_sum['销售额']/brand_cnt['用户数量']
sns.barplot(x='sum_mean',y='品牌',data=brand_cnt.sort_values('sum_mean',ascending=False)[:20])
用户消费行为可视化分析
num_cnt_sum= data.groupby('user_id'['price','order_id'].agg({'price':'sum','order_id':'count'}).rename(columns={'price':'消费金额','order_id':'消费次数'})
num_cnt_sum
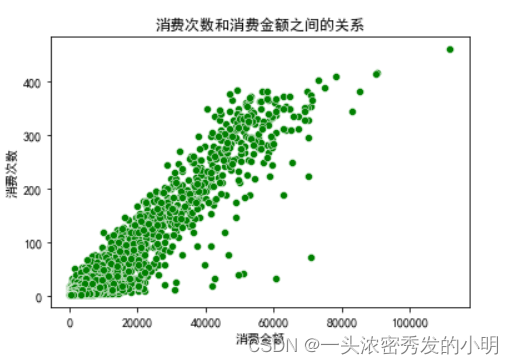
# 绘制消费次数和消费金额之间的关系
sns.scatterplot(x='消费金额',y='消费次数',data=num_cnt_sum,color='g')
plt.title('消费次数和消费金额之间的关系')
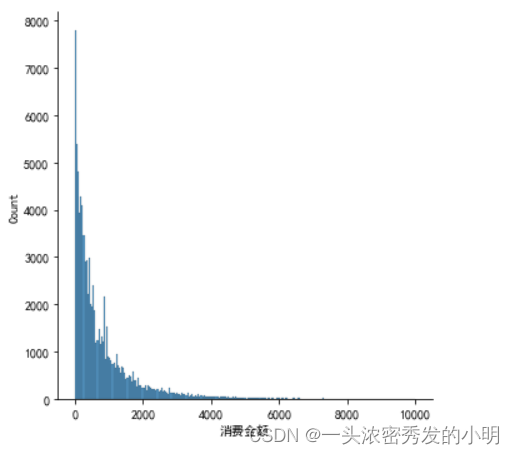
sns.displot(data=num_cnt_sum.query('消费金额<10000'),x='消费金额')
用户消费行为
# 查看新增人数
# 查看最小的消费时间
data.loc[data.year ==2020].groupby('user_id')['event_time'].min().value_counts().plot()
#顾客最后一次购买时间
last_buy = data.loc[data.year==2020].groupby('user_id')['event_time'].max().reset_index()
last_buy
# 第一次购买
first_mon_buy = data.groupby('user_id')['event_time'].min().apply(lambda x:x.month).value_counts().sort_values(ascending=False)
first_mon_buy.plot(kind='bar')
first_mon_buy.to_frame().reset_index().rename(columns={'index':'月份','event_time':'第一次购买人数'})
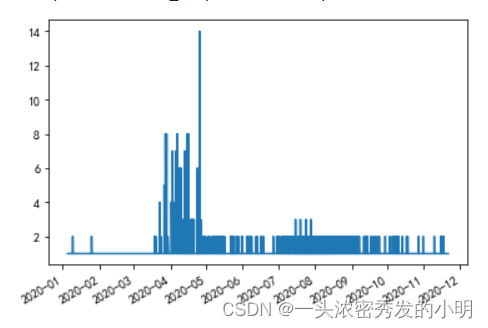 #我们可以看出第一次购买和最后一次购买的时间相差不大,所以可以判定用户基本是指购买了一次
#我们可以看出第一次购买和最后一次购买的时间相差不大,所以可以判定用户基本是指购买了一次
统计新老顾客
# 统计新老顾客
new_old = data.groupby('user_id')['event_time'].agg(['min','max'])
new_old
new_old['is_new']=(new_old['min']==new_old['max'])
new_old.head()
#最大值和最小值一样的,是新客户,反之是老客户
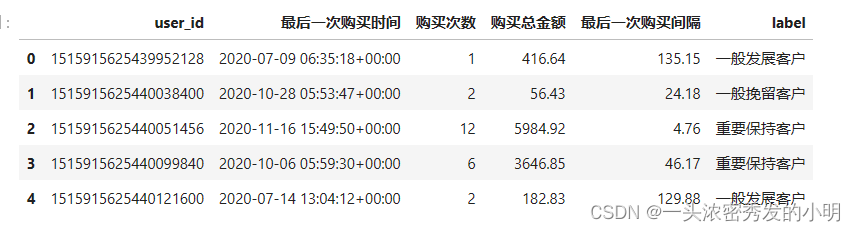
建立用户数据透视表,对用户分层管理
# 创建透视表
rfm =data.pivot_table(index='user_id',
values={'event_time','price','order_id'},
aggfunc={
'event_time':'max',
'price':'sum',
'order_id':'count'
}).reset_index().rename(columns={'order_id':'购买次数','event_time':'最后一次购买时间','price':'购买总金额'})
rfm
通过FRM方法判定用户种类
def rfm_func(x):
level = x.apply(lambda x: '1' if x>=0 else '0')
label = level['最后一次购买间隔']+level['购买次数']+level['购买总金额']
d = {
'111' : '重要价值客户'
,'011': '重要保持客户'
,'101': '重要发展客户'
,'001': '重要挽留客户'
,'110': '一般价值客户'
,'010': '一般保持客户'
,'100': '一般发展客户'
,'000': '一般挽留客户'
}
result = d[label]
return result
rfm['label']=rfm[['最后一次购买间隔','购买次数','购买总金额']].apply(lambda x:x -x.mean()).apply(rfm_func,axis=1)
rfm.head()
用户分层可视化
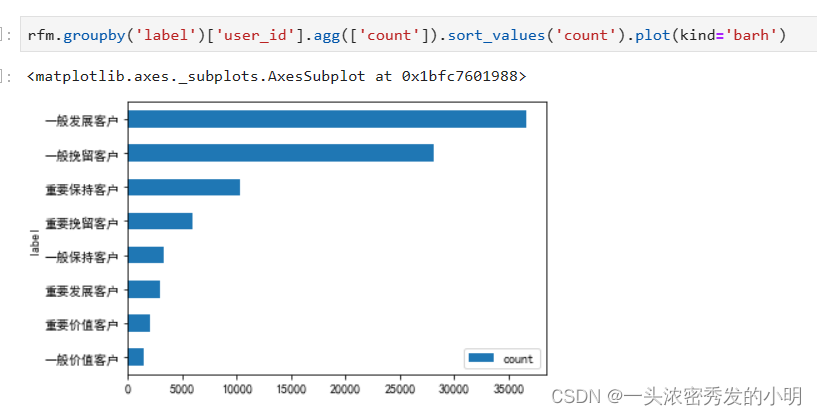
能够看出一般发展客户和一般挽留客户是占大多数的,而重要客户实际上只占一小部分