引言
众所周知在计算机的编程语言中主要分为编译型语言和解释型语言两个大类.
所谓的编译型语言就是先将程序的源代码编译成计算机可执行的字节码,由这些字节码汇聚而成最后的可执行文件. 而由于是直接执行字节码,所以在运行效率和速度上,编译型语言通常是远胜于解释型语言的.编译型语言的代表主要有:C/C++,C#以及现在比较火的Rust和Golang等等.
解释型语言通常都是先运行一个解释器,这个解释器会一行一行的运行源代码.当然,由于计算机本身只能运行字节码,所以解释器也是会先将源代码转换为字节码,然后再执行字节码.解释型语言的主要代表就是:Python,JavaScript等等.
既然都是运行字节码,那为什么解释型语言非得一条一条编译字节码,而不像编译器一样一口气将所有的源代码编译呢?其实这恰好是解释型语言的优势所在,由于解释器是一条一条编译执行代码的,而正因为是一条一条的执行,所以解释型语言才得以不用过多的考虑上下文环境,也就使得Python这类语言可以不必在乎运行过程中的变量类型.
所以,在日常生活中,也有很多人会将编译型语言成为静态类型语言,而解释型语言成为动态类型语言.
Python程序的组成
Python作为典型的解释型语言,也是通过解释器来执行的.
当你执行一个Python文件时,会先将Python的解释器加载到系统内存中.而这个解释器会根据指定的py文件路径,将找到的代码文件按照从上到下从左到右的顺序编译执行.
当然,这个所谓的编译过程跟静态语言的编译肯定是有点区别的.
首先,是解析程序代码的经典环境,词法分析和语法分析.通过这一步骤,解释器可以得到要执行的代码的抽象语法生成树,也就是所谓的AST.因此,解释器也就大概理解了实际要做一个什么事,先做什么后做什么怎么做.随后会将这些代码转换为指定的,Python可执行的,运行对象.既Code Object.
Python是一门面向对象编程的语言,也就是说万物皆为对象.而这个对象就是这个code Object.在Python里,所有的函数,类,变量,等可操作的东西,从Python设计的角度讲,都是code object.
那这个Code Object是直接就在解释器中运行的嘛?其实也不是.
我们在写代码的时候都知道,函数之间是可以相互调用的,并且诸如函数,变量,常量这些东西都是有自己的作用域(执行空间)的.通常情况下,不在自己作用域内的东西是不能对进行操作的.
而要实现这一点,就需要解释器将不同的作用域隔开.而在Python中,用来隔开的不同作用域的东西就是Frame.
Python中的Frame
在Python中每次进出函数都伴随着一次frame的操作.Python的解释器维护着一个调用栈,与传统的堆栈结构一样,你可以将其近似的理解为一个LIFO(Last In First Out)的队列.每当调用一个函数时,会创建一个frame,并将其压入调用栈中.每当从一个函数中return出来,就会从调用栈中弹出一个frame.
我们在调试Python程序时,当程序断下后,看到的函数调用关系其实就是Python的调用栈.
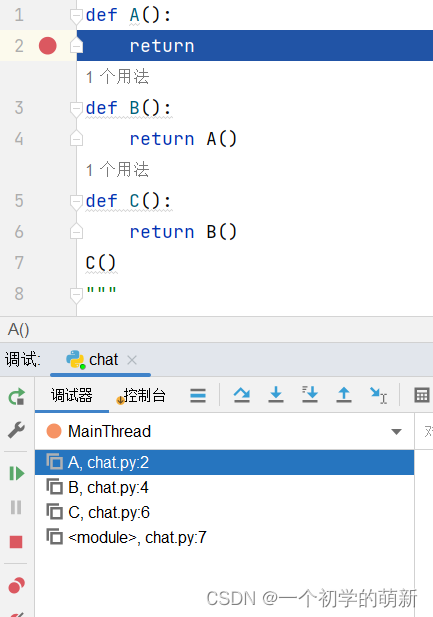
在调试器中的每一个层级都代表着一个frame.
下面是Python官方对frame的定义
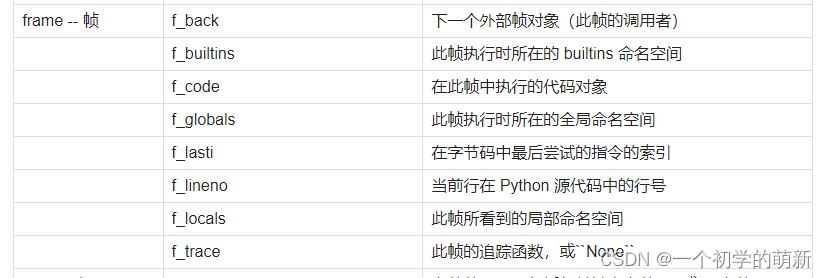
可以看出,frame本身就想是容器一样装载着当前的运行环境
我们利用如下代码来查看一这些属性
import inspect
def A():
frame = inspect.currentframe()
print(f"""
f_back: {
frame.f_back}
f_builtins: {
frame.f_builtins}
f_code: {
frame.f_code}
f_globals: {
frame.f_globals}
f_lasti: {
frame.f_lasti}
f_lineno: {
frame.f_lineno}
f_locals: {
frame.f_locals}
f_trace: {
frame.f_trace}
""")
return
def B():
return A()
def C():
return B()
C()
运行结果如下:
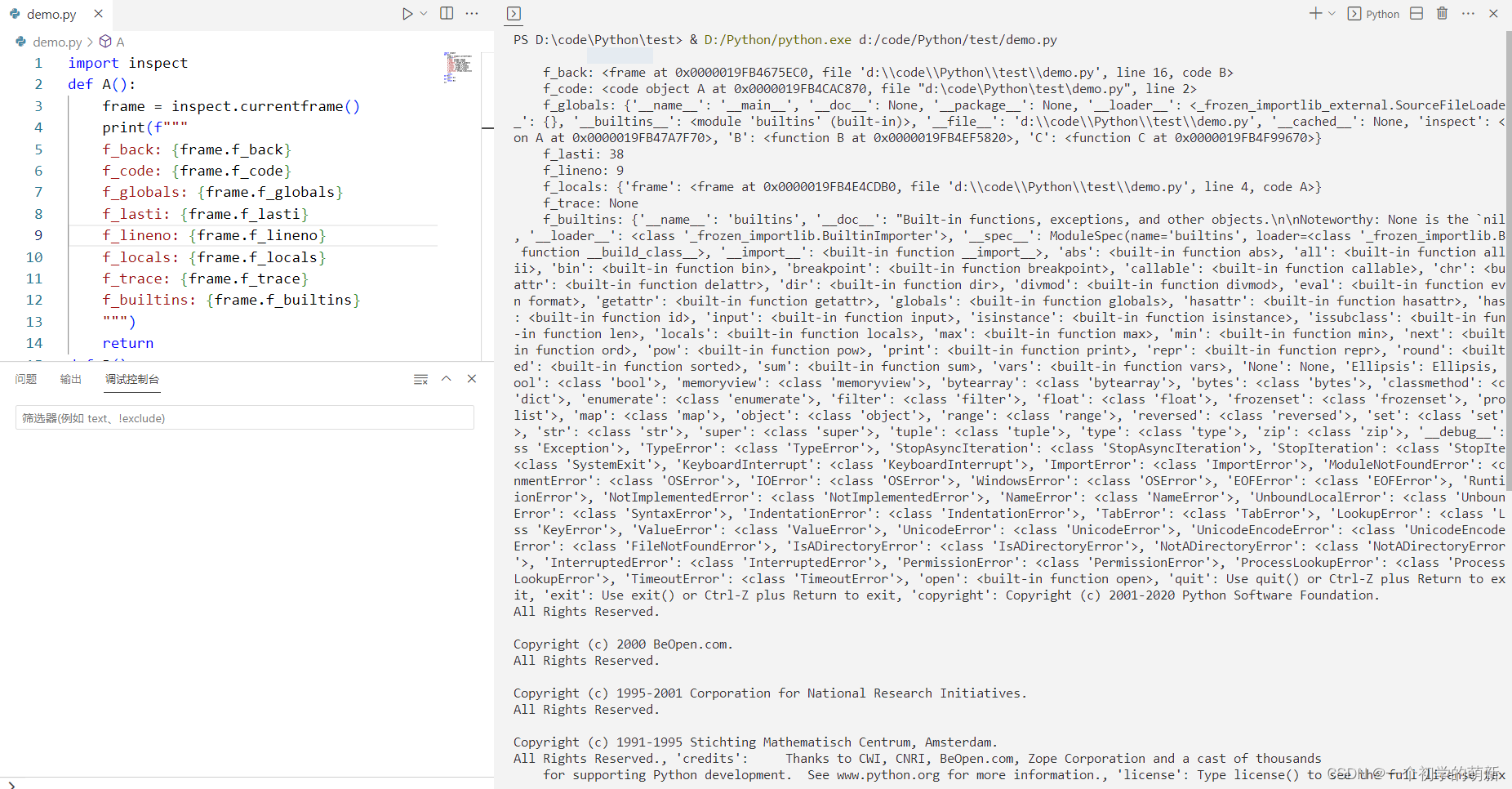
可以看到,在调用A函数的时候,A函数的frame里面记录了当前frame的前一个frame,也就是说在A的函数作用域里面,我们可以通过当前的frame知道上一个frame,也就是哪一个函数调用了A.同时呢,frame中也记载了一些当的运行信息,比如现在代码执行到了第几号,现在执行的代码处在哪一个文件中.
在这其中比较有意思的就是f_trace属性,这个属性指定了frame的跟踪函数.
下面是一个设置跟踪函数的示例
import sys
def trace_func(frame, event, arg):
print(f"跟随事件 {
event} 目前正处于 {
frame.f_code.co_name} 函数 参数为:{
arg}")
return trace_func
def add(a,b):
print(f"进入add函数,运算结果为:{
a+b}")
return a+b
# 设置跟踪函数
sys.settrace(trace_func)
# 执行函数
add(1,2)
# 取消跟踪函数
sys.settrace(None)
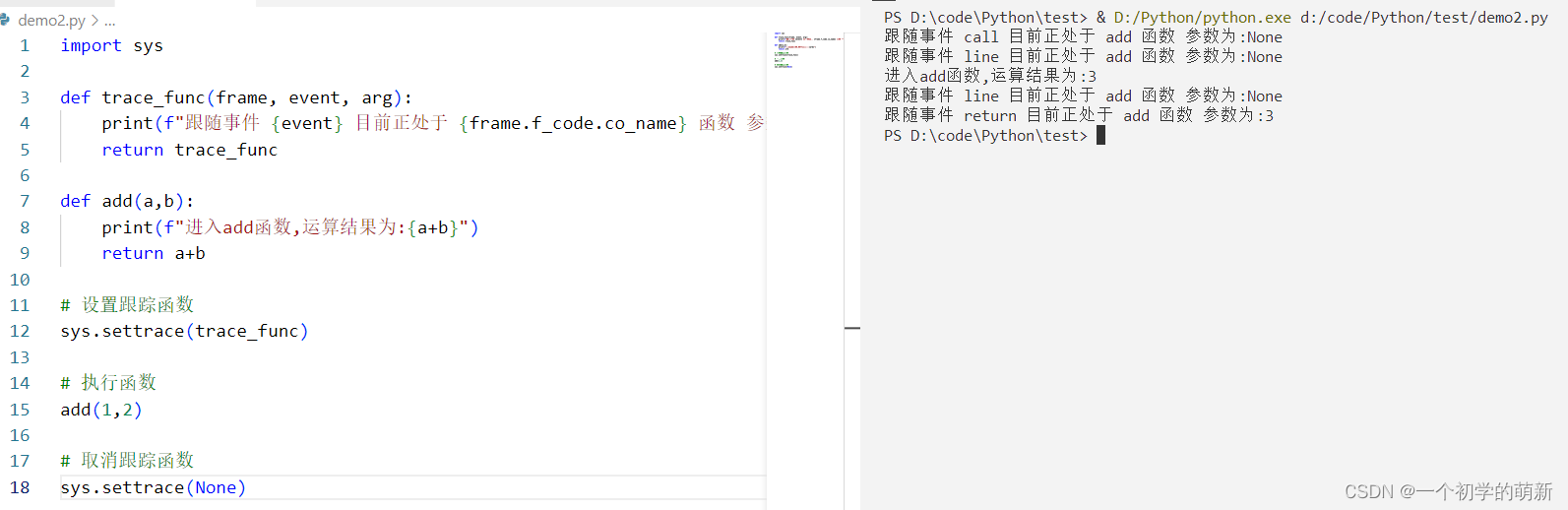
从图中可以看出,跟踪函数的触发事件一共有三个,在调用函数(call)时触发了一次,执行函数(line)时触发了两次,退出函数(return)时触发了一次.并且在函数真正返回之前,先一步拿到了add函数的返回值3.
利用跟踪函数的这一特性,可以让我们在调试程序的时候非常方便的了解到程序运行的状况.很多调试器的原理其实也都是这个.
从f_builtins中我们可以看到很多熟悉的名称,如len,id,print,max等等.这也解释了为什么,我们可以在任何地方调用这些内置函数.
因为在程序运行的frame中,有一个专门的空间f_builtins存在,来存储这些内置函数.
如果仔细观察的话还可以发现,在f_globals中还有很多熟悉的字眼.比如__name__的值是__main__.并且里面还有A,B,C这三个键,值都是code object.其实这个属性主要存放的就是当前frame的全局命名空间.也就是存放全局变量属性函数的地方.如果你经常使用闭包之类的技巧的话应该知道Python里面有个关键字叫global,使用global定义的变量都会存放到f_globals中进而变成全局变量.
有了全局作用域自然也会有本地作用域,f_locals干的就是这样一件事,所有的局部变量属性等等都会存放在这个f_locals中.当然,经过前面的铺垫,可以看出这个局部变量和全局变量在Python设计的底层也是一个君子协议.虽然在不同的frame中有不同的f_locals.对于普通的Python开发者而言,确实实现了作用域隔离的作用.但是,实际上咱们是可以利用trace函数,或者其他的办法,获取到想要的frame在从里面得到自己想要的东西.
也就是说,在Python中,只要你想,你可以在任何时候任何函数内获取到其他函数或方法中的变量值,运行情况,以及运行结果.
最后一个比较有意思的就是 f_code了,这个里面存放的是,当前frame中的执行对象,也就是前文所提到的,解释器在编译时生成的code object.
Code Object
关于code object的官方定义如下

Code Object你可以不太准确的理解为Python解释器的运行单元.每当Python你的解释器想要做执行代码,运行函数,创建类等操作时,都会找到对应的code object,然后再执行这个code object.
下面我们通过一个具体的例子,来查看一下这些属性所代表的意义.
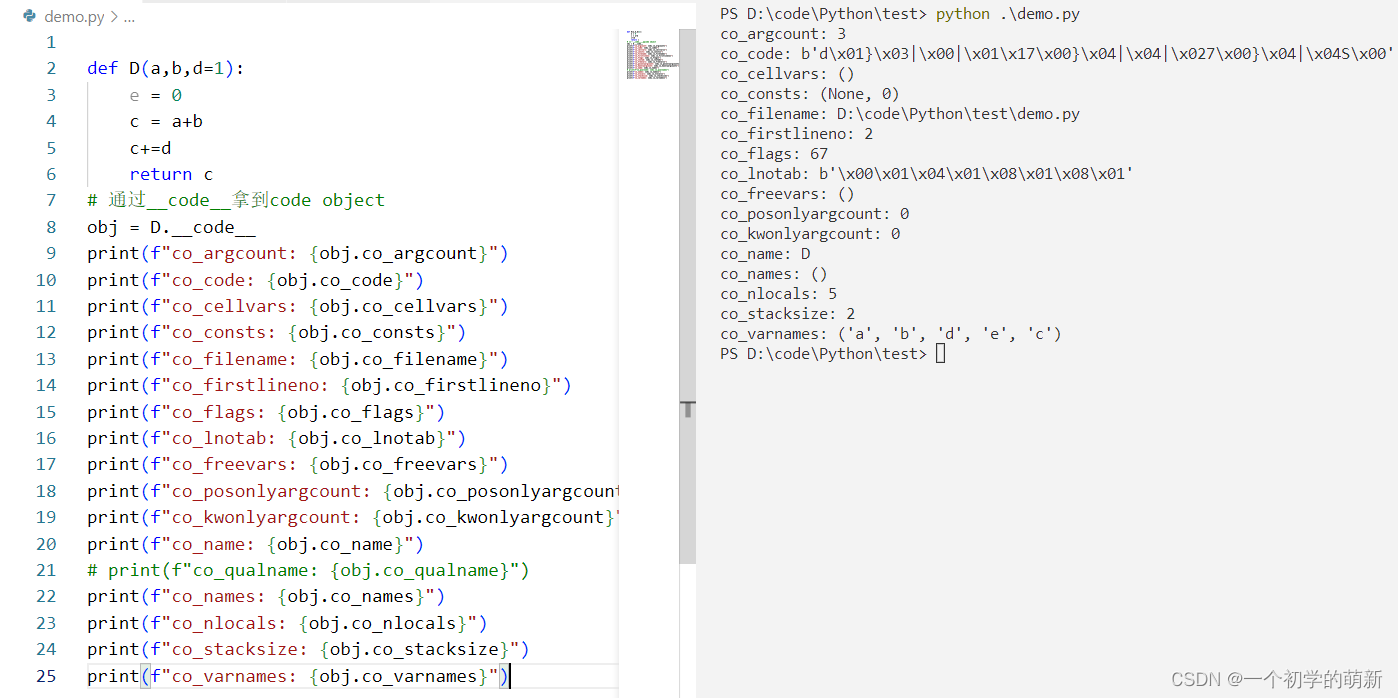
从运行结果中,我们可以非常明显的看到,在Python运行时,我们也能够知道函数D一共拥有3个参数,并且这个函数中有两个常量值存在,一个是None一个是0,注意这里的None是默认存在的.通过co_filename,co_firstlineno,co_name这三个属性.我们可以知道在代码中要运行的函数D所在的py文件的具体位置,以及这个文件中的第一行代码的位置是这个py文件的第二行,并且当前要运行的函数的函数名称是D.
这时候看co_flags的值是67,但是在官方文档中的定义里,它应该是作为标志位存在的,为什么此处却是一个整数呢.
就像计算机的CPU中存在的专用标志位寄存器一样,此处的co_flags也是一个按位标志的字段.此处的67是为了方便显示才转换成十进制的形式.它的本质其实是二进制的1000011,从左边的第0位到右边的第6位共计7个标志.
关于标志位的描述如下:

比如最后两位分别代表这这个函数是否为一个生成器函数或者一个协程.而倒数第三个则代表这该函数是否为一个闭包函数.
第一位如果是1,证明该这个代码对象会已经被优化,在实际执行bytecode(字节码)时会使用快速存储(Load_Fast)
此处的bytecode(字节码)指的就是code object 中的co_code了.当然直接print出来看肯定是不行的.关于字节码,Python官方有一个dis模块可以很方便的进行查看.
还是刚才的D函数,现在我们用dis模块来查看一下它的字节码

这里的字节码本质上是和源码中的代码是一一对应的关系.
首先,Load_const 0 将常量0压入栈中,Store_Fast将栈顶的0保存起来并取名为e存入co_varnames中.
随后,使用Load_Fast从变量栈中取出a和b这两个变量,使用Binary_Add对两个变量进行相加的操作,并用Store_Fast将相加的结果存入变量栈中取名为c.再从变量栈中读取c和d,利用Inplace_Add计算出计运算结果,并将结果存为c.最后从变量栈中取出c的值使用Return_Value将c返回给上层调用的函数.
从上面的字节码流程中,可以看出,看似简单的几行代码,其中包含着很多的进出栈的操作.比如Binary_Add这个作为加法操作,但是这个bytecode本身却没有任何操作数,这是因为他实际上是对栈顶上的两个元素进行了相加操作.所以不需要指定具体是哪一个变量,提前用Load_Fast将变量压入栈顶,随后直接进行相加的操作即可.
如果想要了解更多的Python字节码,可以查看Python的官方文档给出的定义

https://docs.python.org/zh-cn/3/library/dis.html?highlight=dis#python-bytecode-instructions
总结
经过上面的介绍,到现在其实已经可以汇总出一个Python程序的运行流程.
- 启动Python的解释器,初始化自己的运行环境
- 读取要运行的py文件,通过语法,词法分析将人类可读的源代码转换为code object
- 按顺序执行code object并运行其中的bytecode
- 将运行结果返回