12.0 序
函数是任何一门编程语言都具备的基本元素,它可以将多个动作组合起来,一个函数代表了一系列的动作。当然在调用函数时,会干什么来着。对,要在运行时栈中创建栈帧,用于函数的执行。
在python中,PyFrameObject对象就是一个对栈帧的模拟,所以我们即将也会看到,python虚拟机在执行函数调用时会动态地创建新的PyFrameObject对象。随着函数调用链的增长,这些PyFrameObject对象之间也会形成一条PyFrameObject对象链,这条链就是对象x86平台上运行时栈的模拟
12.1 PyFunctionObject对象
我们说过python中一切皆对象,函数也不例外。在python中,函数这种抽象机制是通过PyFunctionObject对象实现的
typedef struct {
PyObject_HEAD //头部信息,不用多说
PyObject *func_code; /* 对应的函数编译后的PyCodeObject对象 */
PyObject *func_globals; /* 函数运行时的global命名空间 */
PyObject *func_defaults; /* 默认参数,tuple或者NULL */
PyObject *func_kwdefaults; /* 关键字默认参数,dict或者NULL */
PyObject *func_closure; /* 用于实现闭包 */
PyObject *func_doc; /* 函数的文档,PyUnicodeObject对象 */
PyObject *func_name; /* 函数名,PyUnicodeObject对象 */
PyObject *func_dict; /* 属性字典,dict或者NULL */
PyObject *func_weakreflist; /* 弱引用列表 */
PyObject *func_module; /* 函数的模块 */
PyObject *func_annotations; /* 注解 */
PyObject *func_qualname; /* 和name类似 */
} PyFunctionObject;我们通过python来看看这些属性吧,首先这些属性都是func_xxx格式的,在python中可以通过__xxx__的形式获取
func_code:对应的字节码def foo(): pass print(foo.__code__) # <code object foo at 0x000001DE153DD3A0, file "C:/Users/satori/Desktop/love_minami/a.py", line 1>func_globals:global命名空间name = "xxx" def foo(): pass # __globals__其实就是外部的globals print(foo.__globals__["name"]) # xxx print(foo.__globals__ == globals()) # Truefunc_defaults:默认参数def foo(name="satori", age=16): pass print(foo.__defaults__) # ('satori', 16) def bar(): pass print(bar.__defaults__) # Nonefunc_kwdefaults:默认的关键字参数。怎么理解呢?意思就是这些参数不仅仅有默认值,而且还必须要通过关键字的方式传递
def foo(name="satori", age=16): pass # 打印是为None的,这是因为虽然有默认值,但是它并不要求必须通过关键字的方式传递 print(foo.__kwdefaults__) # None # 我在前面加上一个*,表示后面的参数就必须通过关键字的方式传递 # 因为如果不通过关键字的话,那么无论多少个位置参数都会被*给吸收掉 # 无论如何也是传递不到name,age的 # 我们经常会看到*args,这是因为我们需要这些参数,所以可以通过args来拿到这些参数 # 但是这里我们不需要,我们只是希望后面的参数必须通过关键字参数传递,因为前面写一个*即可 # 当然写*args或者其他的也可以,但是我们用不到,所以写一个*即可 def bar(*, name="satori", age=16): pass # 此时就打印了默认值,因为这是只能通过kw(关键字)传递的参数的默认值 print(bar.__kwdefaults__) # {'name': 'satori', 'age': 16}func_closure:闭包def foo(): x = 123 y = 456 def bar(): nonlocal x nonlocal y return bar # 查看的是闭包里面nonlocal的值 # 这里有两个nonlocal,所以foo().__closure__是一个有两个元素的元组 print(foo().__closure__) # (<cell at 0x000001DF68BE5BB0: int object at 0x00007FFE96C9A5E0>, <cell at 0x000001DF68BFFF10: int object at 0x000001DF68BF6C10>) print(foo().__closure__[0].cell_contents) # 123 print(foo().__closure__[1].cell_contents) # 456 # 注意:查看闭包属性我们使用的是内层函数,不是外层的foofunc_doc:函数的文档def foo(name, age): """ 接收一个name和age, 返回一句话 my name is $name, age is $age """ return f"my name is {name}, age is {age}" print(foo.__doc__) """ 接收一个name和age, 返回一句话 my name is $name, age is $age """func_name:函数名def foo(name, age): pass print(foo.__name__) # foofunc_dict:属性字典def foo(name, age): pass # 一般函数的属性字典都会空,属性字典基本上在类里面使用 print(foo.__dict__) # {}func_weakreflist:弱引用列表python无法获取这个属性,没有提供相应的接口
func_module:函数所在的模块def foo(name, age): pass print(foo.__module__) # __main__func_annotations:注解def foo(name: str, age: int): pass print(foo.__annotations__) # {'name': <class 'str'>, 'age': <class 'int'>}func_qualname:和func_name类似def foo(name: str, age: int): pass print(foo.__qualname__) # foo
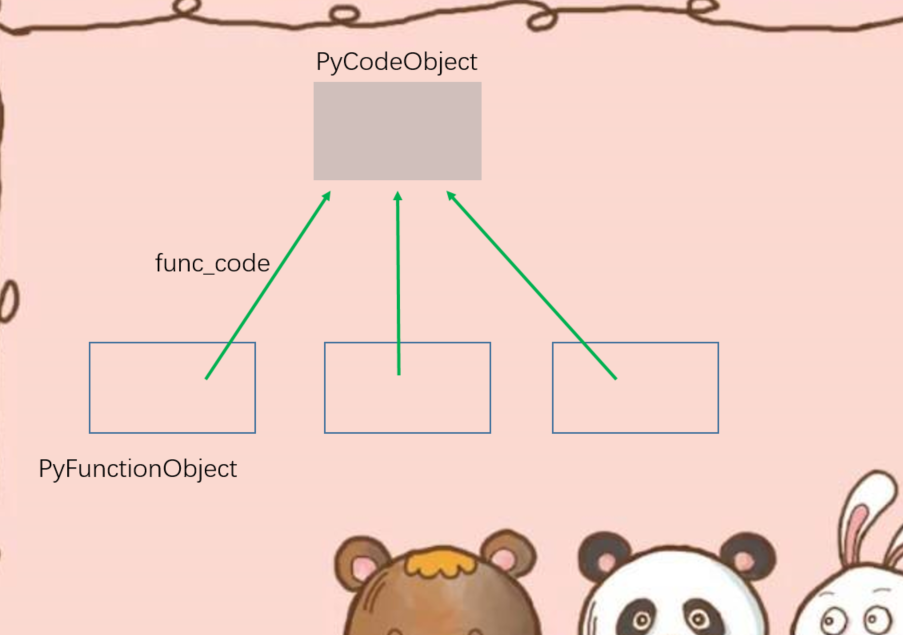
在PyFunctionObject对象中,我们看到了很多域。但是有两个域都和函数有关:PyCodeObject对象和PyFunctionObject对象,这两个对象非常重要。PyCodeObject对象是对一段代码的静态表示,python对源代码编译之后,会对每一个code block都生成一个、且唯一一个PyCodeObject,这个PyCodeObject对象中包含了这个code block中的一些静态信息,所谓静态信息是可以从源代码中看到的信息。比如code block中有一个a = 1这样的表达式,那么符号a和值1、以及它们之间的联系就是一种静态的信息,这些信息会分别存在PyCodeObject对象的常量池:co_consts、符号表:co_names、以及字节码序列:co_code中,这些信息是编译的时候就可以得到的,因此PyCodeObject对象是编译时候的结果。
而PyFunctionObject则不同,PyFunctionObject对象是python代码在运行时动态产生的,更准确的说,是在执行一个def语句的时候创建的。在PyFunctionObject对象中,也会包含这些函数的静态信息,这些信息存储在func_code中,实际上,func_code一定会指向与函数代码对应的PyCodeObject对象。除此之外,PyFunctionObject对象中还包含了一些函数在执行是所必须的动态信息,即上下文信息,比如func_globals,就是函数在执行时关联的global作用域(globals)。global作用域中的符号和值必须在运行时才能确定,所以这部分必须在运行时动态创建,无法存储在PyCodeObject中。
对于一段python代码,其对应的PyCodeObject对象只有一个,但是代码对应的PyFunctionObject对象却可以有多个,比如一个函数多次调用,python会在运行时创建多个PyFunctionObject对象,而每一个PyFunctionObject对象的func_code域都会关联到这个PyCodeObject
12.2 无参函数调用
12.2.1 函数对象的创建
我们先从无参的函数调用开始,因为这是最简单的。
a.py
def foo():
print("this is a function")
foo()b.py
import dis
code = compile(open("a.py", encoding="utf-8").read(), "a.py", "exec")
dis.dis(code)
"""
1 0 LOAD_CONST 0 (<code object foo at 0x000002807F87EF50, file "a.py", line 1>)
2 LOAD_CONST 1 ('foo')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (foo)
5 8 LOAD_NAME 0 (foo)
10 CALL_FUNCTION 0
12 POP_TOP
14 LOAD_CONST 2 (None)
16 RETURN_VALUE
Disassembly of <code object foo at 0x000002807F87EF50, file "a.py", line 1>:
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('this is a function')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
"""显然这个代码中出现了两个PyCodeObject对象,一个对应整个py文件,另一个则是对应函数foo。我们看到上面源代码的1和5行是py文件对应的PyCodeObject对象,而第2行则是对应函数foo的PyCodeObject对象
code = compile(open("a.py", encoding="utf-8").read(), "a.py", "exec")
print(type(code)) # <class 'code'>
print(type(code.co_consts[0])) # <class 'code'>
print(code.co_name) # <module>
print(code.co_consts[0].co_name) # foo可以看到,函数foo对应的PyCodeObject对象是a.py这个模块对应的PyCodeObject对象的常量池co_consts中的一个元素。因为在对a.py创建PyCodeObject对象的时候,发现了一个函数foo,那么会对函数foo继续创建一个PyCodeObject对象(每一个代码块都会对应一个PyCodeObject对象),而函数foo对应的PyCodeObject对象则是模块a.py对应的PyCodeObject对象的co_consts常量池当中的一个元素。我们可以看一个再复杂一点的例子
# a1.py
def foo():
def bar():
print("this is a function")
def foo1():
pass
foo()# 首先code是什么?显然是a1.py对应的PyCodeObject对象
code = compile(open("a1.py", encoding="utf-8").read(), "a.py", "exec")
# 而foo和foo1显然是模块级别的函数,那么这两位应该都是模块对应的PyCodeObject对象的常量池里面的元素
print(code.co_consts[0].co_name) # foo
print(code.co_consts[2].co_name) # foo1
# 至于索引、也就是在常量池中的位置,我们目前不需要关心,只要确定在常量池里面即可
# 而我们看到foo里面还嵌入了一个bar,这是一个闭包。
# 然而即便如此,它毕竟是在foo里面,那么按照之前的逻辑,显然bar对应的PyCodeObject对象也应该在foo对应的PyCodeObject对象的co_consts中
# code.con_consts[0]是foo对应的PyCodeObject对象,那么code.con_consts[0].co_consts[0]是不是就是bar对应的字节码对象呢
# 答案是猜对了一半,确实在里面,只不过索引不是0,而是1
print(code.co_consts[0].co_consts[1].co_name) # bar
# 还是那句话,我们只是确定位置,至于顺序,也就是这里的索引,我们暂时不追究通过以上例子,我们发现,字节码是嵌套的。在介绍字节码对象的时候,我们说了,每一个code block(函数、类等等)都会创建一个字节码对象。现在我们又看到了,根据层级来分的话,内层代码块对应的PyCodeObject对象是最近的外层代码块对应的PyCodeObject对象的常量池co_consts中的一个元素。而最外层则是模块对应的PyCodeObject对象,因此这就意味着我们通过最外层的PyCodeObject对象可以找到所有的PyCodeObject,显然这是毋庸置疑的。而这里和栈帧也是对应的,栈帧我们说过也是层层嵌套的。执行字节码的时候会创建对应的栈帧,而内层栈帧通过f_back可以找到外层、也就是调用者对应的栈帧,当然这里我们之前的章节已经说过了,这里再提一遍。
我们再来观察一下之前的a.py对应的字节码
1 0 LOAD_CONST 0 (<code object foo at 0x000002807F87EF50, file "a.py", line 1>)
2 LOAD_CONST 1 ('foo')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (foo)
5 8 LOAD_NAME 0 (foo)
10 CALL_FUNCTION 0
12 POP_TOP
14 LOAD_CONST 2 (None)
16 RETURN_VALUE
Disassembly of <code object foo at 0x000002807F87EF50, file "a.py", line 1>:
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('this is a function')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
我们发现之前看到源代码的行号都是从上往下、依次增大的,这很好理解,毕竟一条一条解释嘛。但是我们看到,这里对于函数来说,发生了变化,先执行了第五行,之后再执行第二行。如果是从python层面的函数调用来理解的话,很容易一句话就解释了,因为函数只有在调用的时候才会执行。但是从字节码的角度来理解的话,我们发现函数的声明和实现是分离的,是在不同的PyCodeObject对象中。确实如此,第一个行代码和第二行代码虽然是一个整体,但是python虚拟机在实现这个函数的时候,却在物理上将它们分离开了。第一行字节码指令序列必须在a.py对应的PyCodeObject对象中,这一点也很好理解。
因为我们之前说过,函数即变量。我们是可以把函数当成是普通的变量来处理的,函数名就相当于变量名,函数体就相当于是函数值。而foo函数显然是a.py的最外层中定义的一个函数,这就意味着我们可以通过a.foo找到它,那么foo是不是要出现在a.py对应的字节码(PyCodeObject)对象中符号表co_names里面呢?foo对应的PyCodeObject对象是不是要出现在a.py对应的字节码对象的常量池co_consts里面的。
code = compile(open("a1.py", encoding="utf-8").read(), "a.py", "exec")
print(code.co_names) # ('foo', 'foo1')所以我们大致能理清逻辑了,每一个代码块都会创建一个PyCodeObject对象,那么0 LOAD_CONST显然就是将函数foo对应字节码load进来,在2 LOAD_CONST将符号、或者说是变量名foo给load进来。然后调用4 MAKE_FUNCTION,这里的MAKE_FUNCTION我们暂时先不管,不过从名字也能看出来,这个之前的BUILD LIST比较类似,相当于使用字节码对象MAKE一个FUNCTION,然后6 STORE_NAME将"变量名->foo"和"变量值->FUNCTION"作为一个entry存储在命名空间中,这是显然是global命名空间。
然而这个函数是什么是构建的呢?显然是从def foo():这条代码处完成的。从语法上将这是函数的声明语句,但是从虚拟机的角度来看这其实是函数对象的创建语句。
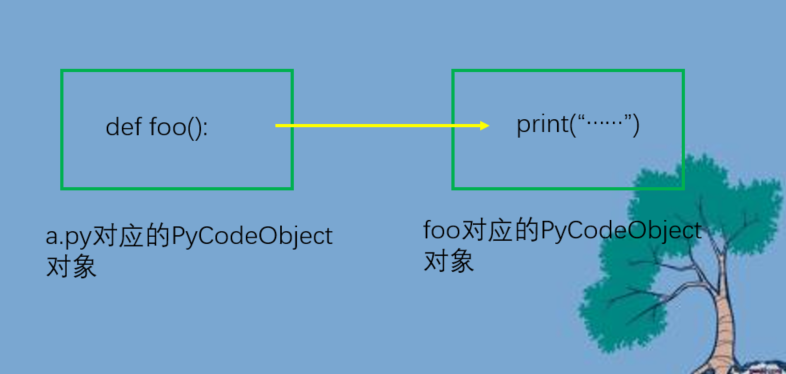
两者是分离的,a.py对应的字节码对象中的foo指向foo对应的字节码,两者是分离的,当然这里的分离指的是两个不同的字节码对象。
python虚拟机在执行def语句时,会动态地创建一个函数,即PyFunctionObject对象,显然这是靠我们之前说的MAKE FUNCTION指令完成的。
//ceval.c
TARGET(MAKE_FUNCTION) {
PyObject *qualname = POP(); //弹出符号表中的函数名
PyObject *codeobj = POP(); //弹出对应的字节码对象
//创建PyFunctionObject对象
PyFunctionObject *func = (PyFunctionObject *)
PyFunction_NewWithQualName(codeobj, f->f_globals, qualname);
Py_DECREF(codeobj);
Py_DECREF(qualname);
if (func == NULL) {
goto error;
}
//下面是设置闭包、注解等属性
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
func ->func_closure = POP();
}
if (oparg & 0x04) {
assert(PyDict_CheckExact(TOP()));
func->func_annotations = POP();
}
if (oparg & 0x02) {
assert(PyDict_CheckExact(TOP()));
func->func_kwdefaults = POP();
}
if (oparg & 0x01) {
assert(PyTuple_CheckExact(TOP()));
func->func_defaults = POP();
}
//压入栈中
PUSH((PyObject *)func);
DISPATCH();
}我们看到在MAKE FUNCTION之前,先进行了LOAD CONST,显然是将foo对应的字节码对象和符号foo压入到了栈中。所以在执行MAKE FUNCTION的时候,首先就是将这个字节码对象以及对应符号弹出栈,然后再加上当前PyFrameObject对象中维护的global命名空间f_globals对象为参数,三者作为参数传入PyFunction_NewWithQualName函数中,从而构建出相应的PyFunctionObject对象。而这个f_globals就是函数foo在运行时的global命名空间,而函数的global命名空间和模块级别的global是一样的,当然和模块级别的local命名空间也是一样的,因为对于模块来说,local和global是一样的。
def foo():
def bar():
return globals()
return bar
# 即使当中嵌入了一个闭包,我们的结论依旧是正确的
print(foo()() == globals() == locals()) # True下面我们来看看PyFunction_NewWithQualName是如何构造出一个函数的。
//Object/funcobject.c
PyObject *
PyFunction_NewWithQualName(PyObject *code, PyObject *globals, PyObject *qualname)
{
//要返回的PyFunctionObject,这里先声明一下
PyFunctionObject *op;
//doc、consts、module这些我们之前都见过的属性
PyObject *doc, *consts, *module;
//函数名
static PyObject *__name__ = NULL;
if (__name__ == NULL) {
__name__ = PyUnicode_InternFromString("__name__");
if (__name__ == NULL)
return NULL;
}
//为PyFunctionObject申请内存空间,类型为function
op = PyObject_GC_New(PyFunctionObject, &PyFunction_Type);
if (op == NULL)
return NULL;
//下面都是设置相关属性
op->func_weakreflist = NULL;
Py_INCREF(code);
op->func_code = code;
Py_INCREF(globals);
op->func_globals = globals;
op->func_name = ((PyCodeObject *)code)->co_name;
Py_INCREF(op->func_name);
op->func_defaults = NULL; /* No default arguments */
op->func_kwdefaults = NULL; /* No keyword only defaults */
op->func_closure = NULL;
consts = ((PyCodeObject *)code)->co_consts;
if (PyTuple_Size(consts) >= 1) {
doc = PyTuple_GetItem(consts, 0);
if (!PyUnicode_Check(doc))
doc = Py_None;
}
else
doc = Py_None;
Py_INCREF(doc);
op->func_doc = doc;
op->func_dict = NULL;
op->func_module = NULL;
op->func_annotations = NULL;
module = PyDict_GetItem(globals, __name__);
if (module) {
Py_INCREF(module);
op->func_module = module;
}
if (qualname)
op->func_qualname = qualname;
else
op->func_qualname = op->func_name;
Py_INCREF(op->func_qualname);
_PyObject_GC_TRACK(op);
return (PyObject *)op;
}在创建了PyFunctionObject对象之后,MAKE FUNCTION还会进行一些处理函数参数的动作,由于目前的foo是一个无参函数,所以这里暂时先略过。在MAKE FUNCTION之后,新建的PyFunctionObject对象就被会压入栈中,然后下面的6 STORE_NAME则显然是将foo和PyFunctionObject对象组合成一个entry存储在global命名空间中。
12.2.2 函数调用
下面我们来看函数是如何调用的。首先肯定要8 LOAD_NAME,把foo对应的value加载进来,然后就是我们熟悉的CALL_FUNCTION,之前在print的时候就已经遇见了,但只是随便提一下。
1 0 LOAD_CONST 0 (<code object foo at 0x000002807F87EF50, file "a.py", line 1>)
2 LOAD_CONST 1 ('foo')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (foo)
5 8 LOAD_NAME 0 (foo)
10 CALL_FUNCTION 0
12 POP_TOP
14 LOAD_CONST 2 (None)
16 RETURN_VALUE
Disassembly of <code object foo at 0x000002807F87EF50, file "a.py", line 1>:
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('this is a function')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
那么现在我们是时候该研究一下这个CALL_FUNCTION了,究竟生得哪般模样!
PREDICTED(CALL_FUNCTION);
TARGET(CALL_FUNCTION) {
PyObject **sp, *res;
//获取运行时栈栈顶指针
sp = stack_pointer;
//直接杀入call_function,我们看到sp是一个二级指针
//又传入了&sp,那么call_function的第一个参数应该是一个三级指针
res = call_function(&sp, oparg, NULL);
stack_pointer = sp;
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}
#define PyCFunction_Check(op) (Py_TYPE(op) == &PyCFunction_Type)
#define PyFunction_Check(op) (Py_TYPE(op) == &PyFunction_Type)
//ceval.c
Py_LOCAL_INLINE(PyObject *) _Py_HOT_FUNCTION
call_function(PyObject ***pp_stack, Py_ssize_t oparg, PyObject *kwnames)
{
//获取PyFunctionObject对象,因为pp_stack是在CALL_FUNCTION指令中传入的栈顶指针
//传入的oparg是0,kwnames是NULL,这里的pfunc就是MAKE_FUNCTION中创建的PyFunctionObject对象
PyObject **pfunc = (*pp_stack) - oparg - 1;
//因此这里的func和pfunc是一样的
PyObject *func = *pfunc;
PyObject *x, *w;
//处理参数,对于我们当前的函数来说,这里的nkwargs和nargs都是0
Py_ssize_t nkwargs = (kwnames == NULL) ? 0 : PyTuple_GET_SIZE(kwnames);
Py_ssize_t nargs = oparg - nkwargs;
PyObject **stack = (*pp_stack) - nargs - nkwargs;
/* Always dispatch PyCFunction first, because these are
presumed to be the most frequent callable object.
*/
//我们看到这里还有cfunction,这个cfunction是什么先不管
if (PyCFunction_Check(func)) {
PyThreadState *tstate = PyThreadState_GET();
C_TRACE(x, _PyCFunction_FastCallKeywords(func, stack, nargs, kwnames));
}
//这里的method这不需要关心
else if (Py_TYPE(func) == &PyMethodDescr_Type) {
PyThreadState *tstate = PyThreadState_GET();
if (nargs > 0 && tstate->use_tracing) {
PyObject *self = stack[0];
func = Py_TYPE(func)->tp_descr_get(func, self, (PyObject*)Py_TYPE(self));
if (func != NULL) {
C_TRACE(x, _PyCFunction_FastCallKeywords(func,
stack+1, nargs-1,
kwnames));
Py_DECREF(func);
}
else {
x = NULL;
}
}
else {
x = _PyMethodDescr_FastCallKeywords(func, stack, nargs, kwnames);
}
}
else {
if (PyMethod_Check(func) && PyMethod_GET_SELF(func) != NULL) {
PyObject *self = PyMethod_GET_SELF(func);
Py_INCREF(self);
func = PyMethod_GET_FUNCTION(func);
Py_INCREF(func);
Py_SETREF(*pfunc, self);
nargs++;
stack--;
}
else {
Py_INCREF(func);
}
//这里是关键,通过_PyFunction_FastCallKeywords对PyFunctionObject对象进行调用
//传入func, stack, nargs, kwnames,并把返回结果赋值给了PyObject *x
if (PyFunction_Check(func)) {
x = _PyFunction_FastCallKeywords(func, stack, nargs, kwnames);
}
else {
x = _PyObject_FastCallKeywords(func, stack, nargs, kwnames);
}
Py_DECREF(func);
}
assert((x != NULL) ^ (PyErr_Occurred() != NULL));
while ((*pp_stack) > pfunc) {
w = EXT_POP(*pp_stack);
Py_DECREF(w);
}
return x;
}python虚拟机通过PyFunction_Check进行检查之后,就会进入_PyFunction_FastCallKeywords。这里需要关注的是里面的第一个参数func,同时这个func也是需要被上面PyFunction_Check检查的对象,显然这个func,就是通过def foo:这个代码块对应的PyCodeObject创建的PyFunctionObject对象。
PyObject *
_PyFunction_FastCallKeywords(PyObject *func, PyObject *const *stack,
Py_ssize_t nargs, PyObject *kwnames)
{
//获取PyFunctionObject的字节码
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
//获取global命名空间
PyObject *globals = PyFunction_GET_GLOBALS(func);
//默认参数
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
//一些其他属性
PyObject *kwdefs, *closure, *name, *qualname;
PyObject **d;
Py_ssize_t nkwargs = (kwnames == NULL) ? 0 : PyTuple_GET_SIZE(kwnames);
Py_ssize_t nd;
//检测
assert(PyFunction_Check(func));
assert(nargs >= 0);
assert(kwnames == NULL || PyTuple_CheckExact(kwnames));
assert((nargs == 0 && nkwargs == 0) || stack != NULL);
//我们观察一下下面的return
//一个是function_code_fastcall,一个是最后的_PyEval_EvalCodeWithName
//由于我们的函数没有参数,因此这里走的是快速通道
//function_code_fastcall里面逻辑很简单,直接抽走当前PyFunctionObject里面PyCodeObject和函数运行时的global命名空间等信息
//根据PyCodeObject对象直接为其创建一个PyFrameObject对象,然后PyEval_EvalFrameEx执行栈帧
//也就是真正的进入了函数调用,执行函数里面的代码
if (co->co_kwonlyargcount == 0 && nkwargs == 0 &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
if (argdefs == NULL && co->co_argcount == nargs) {
return function_code_fastcall(co, stack, nargs, globals);
}
else if (nargs == 0 && argdefs != NULL
&& co->co_argcount == PyTuple_GET_SIZE(argdefs)) {
stack = &PyTuple_GET_ITEM(argdefs, 0);
return function_code_fastcall(co, stack, PyTuple_GET_SIZE(argdefs),
globals);
}
}
kwdefs = PyFunction_GET_KW_DEFAULTS(func);
closure = PyFunction_GET_CLOSURE(func);
name = ((PyFunctionObject *)func) -> func_name;
qualname = ((PyFunctionObject *)func) -> func_qualname;
if (argdefs != NULL) {
d = &PyTuple_GET_ITEM(argdefs, 0);
nd = PyTuple_GET_SIZE(argdefs);
}
else {
d = NULL;
nd = 0;
}
//如果有参数的话,现在会走这一步,逻辑会复杂一些,不过这些都是后话了。
//但是显然最终也会经过PyEval_EvalFrameEx
return _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
stack, nargs,
nkwargs ? &PyTuple_GET_ITEM(kwnames, 0) : NULL,
stack + nargs,
nkwargs, 1,
d, (int)nd, kwdefs,
closure, name, qualname);
}
因此我们看到,总共有两条路径,分别针对无参和有参,但是最终殊途同归、都会走到PyEval_EvalFrameEx那里。然后虚拟机在新的栈帧中执行新的PyCodeObject,而这个PyCodeObject就是函数对应的PyCodeObject,也就是函数foo里面的那条print语句对应的字节码
但是到这里恐怕就有人有疑问了,我们之前说过PyFrameObject是根据PyCodeObject创建的,而PyFunctionObject也是根据PyCodeObject创建的,那么PyFrameObject和PyFunctionObject之间有啥关系呢?如果把PyCodeObject比喻成"男人"的话,那么PyFunctionObject就是男人的"基友",PyFrameObject就是男人的"媳妇"。其实在PyEval_EvalFrameEx执行栈帧的时候,PyFunctionObject的影响就已经消失了,真正对栈帧产生影响的是PyFunctionObject里面的PyCodeObject对象和global命名空间。也就是说,PyFunctionObject辛苦一场,实际上是为别人做了嫁衣。PyFunctionObject主要是对字节码和global命名空间的一种打包和运输方式。
我们之前提到了快速通道,那么函数是通过什么来判断是否可以进入快速通道呢?答案是通过函数参数的形式来决定是否可以进入快速通道
12.3 函数执行时的命名空间
现在我们对函数调用机制有了一个大致的认识,另外我们发现在最终的函数调用时,有一个参数叫globals,这个globals最终成为和函数foo对应的PyFrameObject对应的global命名空间:f_globals
另外还记得当初对LOAD_NAME指令的分析吗?我们说过在执行该指令时,python会依次从:f_locals、f_globals、f_builtins中进行搜索。在function_code_fastcall中传入的globals将成为在新的栈帧中执行函数foo时候的global命名空间。而在执行MAKE_FUNCTION的指令代码中(对应函数),这个globals就是当前PyFrameObject对象(对应模块)中的f_globals。这就意味着,执行a.py字节码指令序列时对应的global命名空间和执行函数foo字节码指令序列时对应的global命名空间实际上是一个命名空间。实际上这个命名空间是通过PyFunctionObject对象的携带,和字节码指令序列对应的PyCodeObject对象一起被传入到新的栈帧当中的。
但是为什么要将globals传到新创建的栈帧当中呢?这不废话吗?只有传了globals,函数内部才能在找不到变量的时候去外部找啊,如果你globals都不传,那不就为空了吗?即便外面有,你也找不到啊。
另外,我们说创建变量,会把符号和值作为一个entry放到f_locals里面的,但是对于模块级别的函数来说,f_locals和f_globals指向的是一个东西,因为模块已经是最外层了,也就不会有什么更外层的作用域了。但是对于函数来说,它的locals和globals是不一样的。
并且我们还能看到一个有趣的现象,如果我们在foo下面再定义一个bar函数,那么在foo中是可以调用bar函数的,即使bar函数定义在foo的下面。因为在执行foo的时候,首先要执行模块,为模块创建一个栈帧,并且此时函数foo、bar都已经作为PyFunctionObject对象在模块对应的栈帧的f_locals(f_globals)里面了。而执行foo的时候,会抽出里面的PyCodeObject,然后创建栈帧。foo调用bar,但foo的f_locals里面没有bar,可f_globals里面是有的,因为这和模块的f_globals是一样的,所以是可以找到bar这个函数对应PyFunctionObject的,然后从里面抽出bar对应的PyCodeObject继续为其创建栈帧,执行。所以这和c语言有个很大的不同,c语言中函数是否可以调用是通过源代码中出现的位置定义的,而python则是基于运行时的命名空间决定的。而在执行foo之前,在为模块创建栈帧的时候,foo和bar都已经被包装成PyFunctionObject对象存在了模块的global(local)命名空间中了。
12.4 函数参数的实现
函数,最大的特点就是可以传入参数,否则就只能单纯的封装,这样未免太无趣了。对于python来说,参数会传什么对于函数来说是不知道的,函数体内部只是利用参数做一些事情,比如调用参数的get方法,但是到底能不能调用get方法,就取决于你给参数传的值到底是什么了。因此可以把参数看成是一个占位符,我们假设有这么个东西,直接把它当成已存在的变量或者常量去进行操作,然后调用的时候,将某个值传进去赋给相应的参数,然后参数对应着传入的具体的值将逻辑走一遍即可。
12.4.1 参数类别
在python中,函数的参数根据形式的不同可以分为四种类别
位置参数(positional argument):foo(a, b),a和b便是位置参数关键字参数(keyword argument):foo(a, b, name="satori"),name便是关键字参数扩展位置参数(excess positional argument):foo(*agrs)扩展关键字参数(excess keyword argument):foo(**kwargs)
我们下面来看一下python的call_function是如何处理函数信息的。
//ceval.c
Py_LOCAL_INLINE(PyObject *) _Py_HOT_FUNCTION
call_function(PyObject ***pp_stack, Py_ssize_t oparg, PyObject *kwnames)
{
//获取PyFunctionObject对象
PyObject **pfunc = (*pp_stack) - oparg - 1;
PyObject *func = *pfunc;
PyObject *x, *w;
/*当python虚拟机在开始执行MAKE_FUNCTION指令时,会先获取一个指令参数oparg
oparg里面记录函数的参数个数信息,包括位置参数和关键字参数的个数。
虽然扩展位置参数和扩展关键字参数是更高级的用法,但是本质上也是由多个位置参数、多个关键字参数组成的。
这就意味着,虽然python中存在四种参数,但是只要记录位置参数和关键字参数的个数,就能知道一共有多少个参数,进而知道一共需要多大的内存来维护参数。
而且python的每个指令都是两个字节,第一个字节存放指令序列本身,第二个字节存放参数个数,既然是一个字节,说明最多只允许有255个参数,不过这已经足够了。
*/
//nkwargs就是关键字参数的个数,nargs是位置参数的个数
Py_ssize_t nkwargs = (kwnames == NULL) ? 0 : PyTuple_GET_SIZE(kwnames);
Py_ssize_t nargs = oparg - nkwargs;
PyObject **stack = (*pp_stack) - nargs - nkwargs;
...
...
}
另外还有一个co_nlocals和co_argcount。注意:从名字也能看出来这个不是PyFunctionObject里面的,而是PyCodeObject里面的。co_nlocals,我们之前说过,这是函数内部局部变量的个数,co_argcount是参数的个数。实际上,函数参数和函数局部变量是非常密切的,某种意义上函数参数就是一种函数局部变量,它们在内存中是连续放置的。当python需要为函数申请局部变量的内存空间时,就需要通过co_nlocals知道局部变量的总数,既然如此那还要co_argcount干什么呢?别急,看个例子
def foo(a, b, c, d=1):
pass
print(foo.__code__.co_argcount) # 4
print(foo.__code__.co_nlocals) # 4
def foo(a, b, c, d=1):
a = 1
b = 1
print(foo.__code__.co_argcount) # 4
print(foo.__code__.co_nlocals) # 4
def foo(a, b, c, d=1):
aa = 1
print(foo.__code__.co_argcount) # 4
print(foo.__code__.co_nlocals) # 5函数的参数也是一个局部变量,因此co_nlocals是参数的个数加上函数体中新创建的局部变量的个数(注意是新创建的,比如参数有一个a,但是函数体里面的变量还是a,相当于重新赋值了,因此还是相当于一个参数),但是co_argcount则是存储记录参数的个数。因此一个很明显的结论:对于任意一个函数,co_nlocals至少是大于等于co_argcount的
def foo(a, b, c, d=1, *args, **kwargs):
pass
print(foo.__code__.co_argcount) # 4
print(foo.__code__.co_nlocals) # 6另外我们看到,对于扩展位置参数、扩展关键字参数来说,co_argcount是不算在内的,因为你完全可以不传递,因为直接当成0来算。而对于co_nlocals来说,我们在函数体内部肯定是拿到args和kwargs来说的,而这可以看成是两个参数。因此co_argcount是4,co_nlocals是6。其实所有的扩展位置参数是存在了一个PyTupleObject对象中的,所有的扩展关键字参数是存储在一个PyDictObject对象中的。而即使我们多传、或者不传,对于co_argcount和co_nlocals来说,都不会有任何改变了,因为这两者的值是在编译的时候就已经确定了的。
12.4.2 位置参数的传递
下面我们就来看看位置参数是如何传递的
a.py
def f(name, age):
age = age + 5
print(name, age)
age = 5
print(age)
f("satori", age)对应字节码如下,直接先解释一下,当然到现在,这已经是很简单的了,对于很多人来说
加载字节码,谁的字节吗?显然是函数f对应的代码块
1 0 LOAD_CONST 0 (<code object f at 0x0000024C189C1030, file "f", line 1>)
将f这个符号load进来
2 LOAD_CONST 1 ('f')
将f的字节码包装成一个PyFunctionObject对象
4 MAKE_FUNCTION 0
将符号f和PyFunctionObject组成一个entry放入f_locals(f_globals)对应的PyDictObject里面
6 STORE_NAME 0 (f)
此时跳到了第6行,load常量5,依旧是组成entry存储起来,由于这是在全局中,所以是STORE_NAME,而不是STORE_FAST
6 8 LOAD_CONST 2 (5)
10 STORE_NAME 1 (age)
此时调用函数,当然是print函数,由于都是在全局中,所以是LOAD_NAME
7 12 LOAD_NAME 2 (print)
14 LOAD_NAME 1 (age)
CALL_FUNCTION调用print
16 CALL_FUNCTION 1
从栈顶将元素弹出来,并打印
18 POP_TOP
此时开始了f函数的调用,调用之前肯定也要准备一下
于是从PyDictObject中将刚才存储的f对应的PyFunctionObject对象、以及"satori"这个字符串常量load进来
f和age是在全局变量中的,所以是LOAD_NAME,而"satori"字符串是一个常量,所以是LOAD_CONST
9 20 LOAD_NAME 0 (f)
22 LOAD_CONST 3 ('satori')
24 LOAD_NAME 1 (age)
调用函数,此时跳到了源代码的第2行,因为遇见函数调用就会创建新的栈帧,并把代码执行的控制权交给新创建的栈帧,执行完了在返回,类似于递归,一层一层创建、执行,然后一层一层返回
26 CALL_FUNCTION 2
下面三条字节码的逻辑就无需解释了
28 POP_TOP
30 LOAD_CONST 4 (None)
32 RETURN_VALUE
Disassembly of <code object f at 0x0000024C189C1030, file "f", line 1>:
我们说过参数age是一个局部变量,直接LOAD_FAST,5则是LOAD_CONST
2 0 LOAD_FAST 1 (age)
2 LOAD_CONST 1 (5)
加法运算
4 BINARY_ADD
此时的age函数体里面创建的局部变量,局部变量的存储是有优化的,所以是STORE_FAST
6 STORE_FAST 1 (age)
下面则是LOAD_GLOBAL,会判断函数里面有没有定义print,但是显然没有,于是前往global、builtin命名空间里面去找,所以是LOAD_GLOBAL,而如果是在外层的话,则是LOAD_NAME
至于有没有LOAD_BUILTIN,实际是没有的,因为builtin是在global里面,我们通过global这个PyDictObject的__bultin__属性是可以找到builtin命名空间的、或者说是builtin对应的PyDictObject
3 8 LOAD_GLOBAL 0 (print)
而name和age则是里面的常量,则是LOAD_FAST
10 LOAD_FAST 0 (name)
12 LOAD_FAST 1 (age)
调用函数
14 CALL_FUNCTION 2
从栈顶弹出元素,并打印
16 POP_TOP
返回默认为None,LOAD_CONST,向None、True、False这些关键字都是LOAD_CONST
18 LOAD_CONST 0 (None)
返回
20 RETURN_VALUE字节码虽然解释完了, 但是最重要的还是没有说。f(name, age),这里的name和age显然是外层定义的,但是外层定义的这两个变量是怎么传给函数f的。下面我们通过源码重新分析:
9 20 LOAD_NAME 0 (f)
22 LOAD_CONST 3 ('satori')
24 LOAD_NAME 1 (age)
26 CALL_FUNCTION 2我们注意到CALL_FUNCTION上面有三条指令,其实当这三条指令执行完毕之后,函数需要的参数已经被压入了运行时栈中。

通过_PyFunction_FastCallKeywords函数,然后执行function_code_fastcall
//call.c
static PyObject* _Py_HOT_FUNCTION
function_code_fastcall(PyCodeObject *co, PyObject *const *args, Py_ssize_t nargs,
PyObject *globals)
{
PyFrameObject *f;
PyThreadState *tstate = PyThreadState_GET();
PyObject **fastlocals;
Py_ssize_t i;
PyObject *result;
assert(globals != NULL);
assert(tstate != NULL);
//创建与函数对应的PyFrameObject,我们看到参数是co,所以是根据字节码指令来创建的
f = _PyFrame_New_NoTrack(tstate, co, globals, NULL);
if (f == NULL) {
return NULL;
}
//关键:拷贝函数参数,从运行时栈到PyFrameObject.f_localsplus
fastlocals = f->f_localsplus;
...
return result;
}从源码中我们看到通过_PyFrame_New_NoTrack创建了函数f对应的PyFrameObject对象,参数是f对应的PyFunctionObject对象中保存的PyCodeObject对象。随后,python虚拟机将参数逐个拷贝到新建的PyFrameObject对象的f_localsplus中。可在分析python虚拟机框架时,我们知道,这个f_localsplus所指向的内存块里面也存储了python虚拟机所使用的那个运行时栈。那么参数所占的内存和运行时栈所占的内存有什么关联呢?
//frameobject.c
//这个是_PyFrame_New_NoTrack,对外暴露的是PyFrame_New,但是本质上调用了这个
PyFrameObject* _Py_HOT_FUNCTION
_PyFrame_New_NoTrack(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
PyFrameObject *back = tstate->frame;
PyFrameObject *f;
PyObject *builtins;
Py_ssize_t i;
...
...
Py_ssize_t extras, ncells, nfrees;
ncells = PyTuple_GET_SIZE(code->co_cellvars);
nfrees = PyTuple_GET_SIZE(code->co_freevars);
extras = code->co_stacksize + code->co_nlocals + ncells +
nfrees;
if (free_list == NULL) {
//为f_localsplus申请extras的内存空间
f = PyObject_GC_NewVar(PyFrameObject, &PyFrame_Type,
extras);
...
...
f->f_code = code;
//获得f_localsplus中出去运行时栈,剩余的内存数
extras = code->co_nlocals + ncells + nfrees;
f->f_valuestack = f->f_localsplus + extras;
...
...
f->f_lasti = -1;
f->f_lineno = code->co_firstlineno;
f->f_iblock = 0;
f->f_executing = 0;
f->f_gen = NULL;
f->f_trace_opcodes = 0;
f->f_trace_lines = 1;
return f;
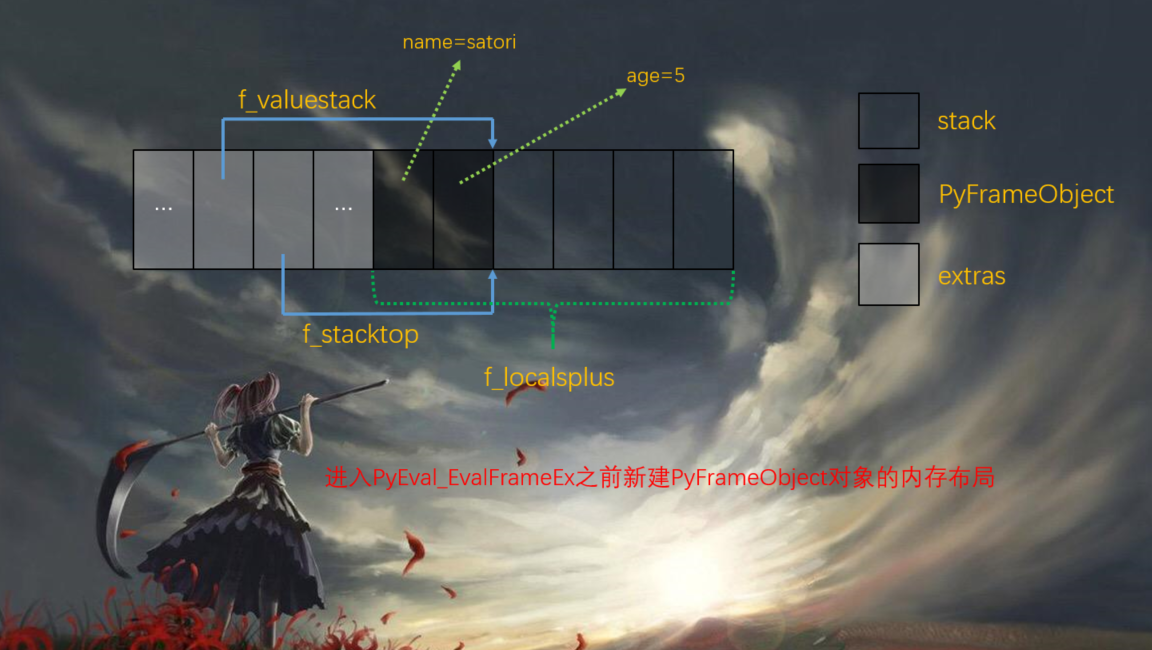
}前面提到,在函数对应的PyCodeObject对象的co_nlocals域中,包含着函数参数的个数,因为函数参数也是局部符号的一种。所以从f_localsplus开始,extras中一定有供函数参数使用的内存。或者说,函数的参数存放在运行时栈之前的那段内存中。
另外从_PyFrame_New_NoTrack当中我们可以看到,在f_localsplus中存储函数参数的空间和运行时栈的空间在逻辑上是分离的,并不是共享同一片内存,尽管它们是连续的。这两者是鸡犬相闻,但又泾渭分明、老死不相往来。
在处理完参数之后,还没有进入PyEval_EvalFrameEx,所以此时运行时栈是空的。但是函数的参数已经位于f_localsplus中了。所以这时新建PyFrameObject对象的f_localsplus就是这样:
12.4.3 位置参数的访问
当参数拷贝的动作完成之后,就会进入新的PyEval_EvalFrameEx,开始真正的f的调用动作。
2 0 LOAD_FAST 1 (age)
2 LOAD_CONST 1 (5)
4 BINARY_ADD
6 STORE_FAST 1 (age)梦回指令集
LOAD_FAST:在函数里面load一个局部变量
LOAD_GLOBAL:在函数里面load一个全局变量、或者内置变量
LOAD_NAME:在外层模块中load一个变量
LOAD_CONST:不限范围,只要load的内容是一个常量
STORE_FAST:在函数里面创建一个局部变量
STORE_NAME:在外层模块中创建一个全局变量
STORE_GLOBAL:在外层模块或者函数里面创建一个被global声明的变量
首先对参数的读写,肯定是通过LOAD_FAST,LOAD_CONST,STORE_FAST这几条指令集完成的
//ceval.c
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
...
...
fastlocals = f->f_localsplus;
...
}
#define GETLOCAL(i) (fastlocals[i])
[LOAD_FAST]
TARGET(LOAD_FAST) {
PyObject *value = GETLOCAL(oparg);
if (value == NULL) {
format_exc_check_arg(PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_varnames, oparg));
goto error;
}
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
[STORE_FAST]
PREDICTED(STORE_FAST);
TARGET(STORE_FAST) {
PyObject *value = POP();
SETLOCAL(oparg, value);
FAST_DISPATCH();
}所以我们发现,LOAD_FAST和STORE_FAST这一对指令是以f_localsplus这一片内存为操作目标的,指令0 LOAD_FAST 1 (age)的结果是将f_localsplus[1]对应的对象压入到运行时栈中,而我们刚才也看到f_localsplus[1]中存放的正是age。而在完成加法操作之后,又将结果通过STORE_FAST放入到f_localsplus[1]中,这样就实现了对a的更新,那么以后在print(a)的时候,得到的结果就是10了。
现在关于python的位置参数在函数调用时是如何传递的、在函数执行又是如何被访问,已经真相大白了。在调用函数时,python将函数参数的值从左至右依次压入到运行时栈中,而在call_function中通过调用_PyFunction_FastCallKeywords,进而调用function_code_fastcall,而在function_code_fastcall中,又将这些参数依次的拷贝到新建的与函数对应的PyFrameObject对象的f_localsplus中。最终的效果就是,python虚拟机将函数调用时使用的参数,从左至右依次地存放在新建的PyFrameObject对象的f_localsplus中。
因此在访问函数参数时,python虚拟机并没有按照通常访问符号的做法,去查什么命名空间,而是直接通过一个索引(偏移位置)来访问f_localsplus中存储的符号对应的值,是的,f_localsplus存储的是符号(变量名),并不是具体的值,所以python传参的方式都是引用传递,不会像golang一样,都是拷贝一份,否则那python效率就太低了,至于值是否改变,则取决于对应的值是可变对象还是不可变对象,而不是像其他编程语言那样通过传值或者传指针来决定是否改变。因此这种通过索引(偏移位置)来访问参数的方式也正是位置参数的由来。
12.4.4 位置参数的默认值
可能有人看到位置参数的默认值这几个字会感到懵逼,这难道不是关键字参数吗?其实位置参数、关键字参数一般是通过调用来体现的,而不是定义函数的时候。你在调用的时候,使用顺序将实参和形参进行对应的方式来传递参数时候,那么你传递的就是位置参数,如果是通过关键字的方式传递,那么传递的就是位置参数。比如:def foo(a, b=1),其中的a和b准确的说都是形参,或者说都是参数吧,但是由于b有了默认值,所以b也叫缺省参数或者默认参数。所以我们通过foo(2)调用时,并没有给b传值,但是定义的时候b=1,可以看做是默认给b传了一个1,即foo(2, 1),这个1就是默认值。所以位置参数、关键字参数是通过调用来体现的,而不是定义,也就是针对于实参的,是根据实参的传递方式来分类的,和形参是没有关系的。
下面就来考察一下默认值机制
a.py
def foo(a=1, b=2):
print(a + b)
foo()
foo(b=3)1 0 LOAD_CONST 7 ((1, 2))
2 LOAD_CONST 2 (<code object foo at 0x0000015C4C5610E0, file "f", line 1>)
4 LOAD_CONST 3 ('foo')
6 MAKE_FUNCTION 1 (defaults)
8 STORE_NAME 0 (foo)
5 10 LOAD_NAME 0 (foo)
12 CALL_FUNCTION 0
14 POP_TOP
6 16 LOAD_NAME 0 (foo)
18 LOAD_CONST 4 (3)
20 LOAD_CONST 5 (('b',))
22 CALL_FUNCTION_KW 1
24 POP_TOP
26 LOAD_CONST 6 (None)
28 RETURN_VALUE
Disassembly of <code object foo at 0x0000015C4C5610E0, file "f", line 1>:
2 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 LOAD_FAST 1 (b)
6 BINARY_ADD
8 CALL_FUNCTION 1
10 POP_TOP
12 LOAD_CONST 0 (None)
14 RETURN_VALUE
我们对比一下开始的没有默认参数的函数,会发现相比于无默认参数的函数,有默认参数的函数,除了load函数体对应的PyCodeObject、和foo这个符号之外,会先将默认参数的值给load进来,将这三者都压入运行时栈。但是我们发现这是默认参数是组合成一个元组的形式入栈的,而且我们再来观察一下MAKE_FUNCTION这个指令,我们发现后面的参数是1 (defaults),之前的都是0,那么这个1是什么呢?而且又提示了我们一个defaults,我们知道PyFunctionObject对象有一个func_defaults,这两者之间有关系吗?那么带着这些疑问再来看看MAKE_FUNCTION指令。
[MAKE_FUNCTION]
TARGET(MAKE_FUNCTION) {
//获取PyCodeObject、func_name,并创建PyFunctionObject
PyObject *qualname = POP();
PyObject *codeobj = POP();
PyFunctionObject *func = (PyFunctionObject *)
PyFunction_NewWithQualName(codeobj, f->f_globals, qualname);
Py_DECREF(codeobj);
Py_DECREF(qualname);
if (func == NULL) {
goto error;
}
//处理参数,这个是针对于闭包的
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
func ->func_closure = POP();
}
//注解
if (oparg & 0x04) {
assert(PyDict_CheckExact(TOP()));
func->func_annotations = POP();
}
//关键字默认参数,显然要定义在*后面的参数
if (oparg & 0x02) {
assert(PyDict_CheckExact(TOP()));
func->func_kwdefaults = POP();
}
//默认关键字参数,我们发现确实是存储在func_defaults里面
if (oparg & 0x01) {
assert(PyTuple_CheckExact(TOP()));
func->func_defaults = POP();
}
PUSH((PyObject *)func);
DISPATCH();
}
通过以上命令我们很容易看出,MAKE_FUNCTION指令除了创建PyFunctionObject对象,并且还会处理参数的默认值。MAKE_FUNCTION指令参数表示当前运行时栈中是存在默认值的,但是默认值具体多少个通过参数是看不到的,因为默认值都会按照顺序塞到一个PyTupleObject对象里面,所以整体相当于是一个。然后会调用PyFunction_SetDefaults将该PyTupleObject对象设置为PyFunctionObject.func_defaults的值,在python层面可以使用__defaults__访问。如此一来,函数参数的默认值也成为了PyFunctionObject对象的一部分,函数和其参数的默认值最终被python虚拟机捆绑在了一起,它和PyCodeObject、global命名空间一样,也被塞进了PyFunctionObject这个大包袱。所以说PyFunctionObject这个嫁衣做的是很彻底的,工具人PyFunctionObject对象,给个赞。
//functionobject.c
int
PyFunction_SetDefaults(PyObject *op, PyObject *defaults)
{
//两个参数,一个PyFunctionObject、一个PyTupleObject
//检测机制,不用管
if (!PyFunction_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
if (defaults == Py_None)
defaults = NULL;
else if (defaults && PyTuple_Check(defaults)) {
Py_INCREF(defaults);
}
else {
PyErr_SetString(PyExc_SystemError, "non-tuple default args");
return -1;
}
//设置
Py_XSETREF(((PyFunctionObject *)op)->func_defaults, defaults);
return 0;
}函数的第一次调用:foo()
//call.c
//这个是通过ceval.c里面的call_function调用的
PyObject *
_PyFunction_FastCallKeywords(PyObject *func, PyObject *const *stack,
Py_ssize_t nargs, PyObject *kwnames)
{
//获取PyFunctionObject的PyCodeObject
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
//获取PyFunctionObject的f_globals
PyObject *globals = PyFunction_GET_GLOBALS(func);
//看这里,这一步显然是获取PyFunctionObject里面的func_defaults
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
PyObject *kwdefs, *closure, *name, *qualname;
PyObject **d;
Py_ssize_t nkwargs = (kwnames == NULL) ? 0 : PyTuple_GET_SIZE(kwnames);
Py_ssize_t nd;
assert(PyFunction_Check(func));
assert(nargs >= 0);
assert(kwnames == NULL || PyTuple_CheckExact(kwnames));
assert((nargs == 0 && nkwargs == 0) || stack != NULL);
if (co->co_kwonlyargcount == 0 && nkwargs == 0 &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
//是否进入快速通道,首先要满足argdefs == NULL,但是我们发现*argdefs是有值的
//所以argdefs这个指针是不为NULL的,因此进入通道失败。所以函数如果有默认参数,是不会进入快速通道的。
if (argdefs == NULL && co->co_argcount == nargs) {
//另外我们发现即使函数定义的时候没有默认参数,但是我们调用的时候通过关键字参数传参话,也不会进入快速通道
//首先这里的nargs是通过call_function函数传递的,而这个nargs在call_function函数中是Py_ssize_t nargs = oparg - nkwargs;
//所以这里的nargs就是传递的参数个数减去通过关键字参数方式传递的参数个数
//而co_argcount是函数参数的总个数,所以一旦哪怕有一个参数使用了关键字参数的方式传递,都会造成两者不相等,从而无法进入快速通道
//因此在CPython中,一个函数若想进入快速通道,只要满足以下两点即可
/*
1.函数定义的时候不可以有默认参数
2.函数调用时,必须都通过位置参数指定。
*/
return function_code_fastcall(co, stack, nargs, globals);
}
//但是这样的条件毕竟太苛刻了,毕竟参数哪能没有默认值呢?所以python还提供了一种进入快速通道的方式
//我们发现在有默认的前提下,如果还能满足nargs==0 && co->co_argcount == PyTuple_GET_SIZE(argdefs)也能进入快速通道
//co->co_argcount == PyTuple_GET_SIZE(argdefs)是要求函数的参数个数必须等于默认参数的个数,也就是函数参数全是默认参数
//nargs==0则是需要传入的参数个数减去通过关键字参数传递的参数个数等于0,即要么不传参(都是用默认参数)、要么全部都通过关键字参数的方式传参。
//这种方式也可以进入快速通道
else if (nargs == 0 && argdefs != NULL
&& co->co_argcount == PyTuple_GET_SIZE(argdefs)) {
/* function called with no arguments, but all parameters have
a default value: use default values as arguments .*/
stack = &PyTuple_GET_ITEM(argdefs, 0);
return function_code_fastcall(co, stack, PyTuple_GET_SIZE(argdefs),
globals);
}
}
//如果以上两点都无法满足的话,那么就没办法了,只能走常规方法了
//这里是获取函数的一些属性,默认关键字参数、闭包等等
kwdefs = PyFunction_GET_KW_DEFAULTS(func);
closure = PyFunction_GET_CLOSURE(func);
name = ((PyFunctionObject *)func) -> func_name;
qualname = ((PyFunctionObject *)func) -> func_qualname;
//这里则是获取默认参数的值的地址和默认参数的个数
if (argdefs != NULL) {
d = &PyTuple_GET_ITEM(argdefs, 0);
nd = PyTuple_GET_SIZE(argdefs);
}
else {
d = NULL;
nd = 0;
}
return _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
stack, nargs, //位置参数信息
nkwargs ? &PyTuple_GET_ITEM(kwnames, 0) : NULL,
stack + nargs,
nkwargs, 1,//关键字参数信息
d, (int)nd, kwdefs,//默认参数信息
closure, name, qualname);
}_PyEval_EvalCodeWithName是一个非常重要的函数,在后面分析扩展位置参数和扩展关键字参数是还会遇到。
PyObject *
_PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, Py_ssize_t argcount, //位置参数的信息
PyObject *const *kwnames, PyObject *const *kwargs,//关键字参数的信息
Py_ssize_t kwcount, int kwstep,
PyObject *const *defs, Py_ssize_t defcount,//默认参数的信息
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
PyCodeObject* co = (PyCodeObject*)_co;
PyFrameObject *f;
PyObject *retval = NULL;
PyObject **fastlocals, **freevars;
PyThreadState *tstate;
PyObject *x, *u;
const Py_ssize_t total_args = co->co_argcount + co->co_kwonlyargcount;
Py_ssize_t i, n;
PyObject *kwdict;
...
...
//创建PyFrameObject对象
f = _PyFrame_New_NoTrack(tstate, co, globals, locals);
if (f == NULL) {
return NULL;
}
fastlocals = f->f_localsplus;
freevars = f->f_localsplus + co->co_nlocals;
...
...
/* Copy positional arguments into local variables */
//argcount是实际传来的位置参数的个数,co->co_argcount则是函数的参数个数
//如果argcount > co->co_argcount,证明有扩展参数,否则没有
if (argcount > co->co_argcount) {
n = co->co_argcount;
}
else {
n = argcount;
}
//所以我们仔细看一下这个n,假设我们定义了一个函数def foo(a, b, c=1,d=2, *args)
//如果argcount > co->co_argcount我们传递的位置参数的个数超过了4个,那么n就是4
//但是如果我们只传递了两个,比如foo('a', 'b'),那么n显然为2
//下面就是将已经传递的参数的值依次设置到f_localsplus里面去,这里的i就是索引,x就是值。
for (i = 0; i < n; i++) {
x = args[i];
Py_INCREF(x);
SETLOCAL(i, x);
}
/* Pack other positional arguments into the *args argument */
//下面显然是扩展位置参数参数的逻辑,我们暂时先跳过,后面会说
if (co->co_flags & CO_VARARGS) {
u = PyTuple_New(argcount - n);
if (u == NULL) {
goto fail;
}
SETLOCAL(total_args, u);
for (i = n; i < argcount; i++) {
x = args[i];
Py_INCREF(x);
PyTuple_SET_ITEM(u, i-n, x);
}
}
/* Handle keyword arguments passed as two strided arrays */
//扩展关键字参数,同样后面说
kwcount *= kwstep;
for (i = 0; i < kwcount; i += kwstep) {
PyObject **co_varnames;
PyObject *keyword = kwnames[i];
PyObject *value = kwargs[i];
Py_ssize_t j;
if (keyword == NULL || !PyUnicode_Check(keyword)) {
PyErr_Format(PyExc_TypeError,
"%U() keywords must be strings",
co->co_name);
goto fail;
}
/* Speed hack: do raw pointer compares. As names are
normally interned this should almost always hit. */
co_varnames = ((PyTupleObject *)(co->co_varnames))->ob_item;
for (j = 0; j < total_args; j++) {
PyObject *name = co_varnames[j];
if (name == keyword) {
goto kw_found;
}
}
/* Slow fallback, just in case */
for (j = 0; j < total_args; j++) {
PyObject *name = co_varnames[j];
int cmp = PyObject_RichCompareBool( keyword, name, Py_EQ);
if (cmp > 0) {
goto kw_found;
}
else if (cmp < 0) {
goto fail;
}
}
assert(j >= total_args);
if (kwdict == NULL) {
PyErr_Format(PyExc_TypeError,
"%U() got an unexpected keyword argument '%S'",
co->co_name, keyword);
goto fail;
}
if (PyDict_SetItem(kwdict, keyword, value) == -1) {
goto fail;
}
continue;
kw_found:
if (GETLOCAL(j) != NULL) {
PyErr_Format(PyExc_TypeError,
"%U() got multiple values for argument '%S'",
co->co_name, keyword);
goto fail;
}
Py_INCREF(value);
SETLOCAL(j, value);
}
/* Check the number of positional arguments */
//这里会再进行检测,argcount > co->co_argcount说明我们多传递了
//(co->co_flags & CO_VARARGS)是否存在扩展参数,如果为FALSE,那么加上!就是TRUE
//那么不好意思直接报错
if (argcount > co->co_argcount && !(co->co_flags & CO_VARARGS)) {
too_many_positional(co, argcount, defcount, fastlocals);
goto fail;
}
/* Add missing positional arguments (copy default values from defs) */
//如果传入的参数个数比函数定义的参数的个数少,那么证明有默认参数。
//defcount设置了默认参数的个数
if (argcount < co->co_argcount) {
//显然m = 参数总个数(不包括*args和**kwargs之外的所有形参的个数,不管有没有默认值) - 默认参数的个数
Py_ssize_t m = co->co_argcount - defcount;
Py_ssize_t missing = 0;
//因此m就是需要传递的没有默认值的参数的总个数
//而i=argcount则是我们调用函数时传递的位置参数的总个数
//比如一个函数接收6个参数,但是有两个是默认参数,因此这就意味着调用者通过位置参数的方式传递的话,需要至少传递4个,如过我们只传递了两个。那么此时m就是4,i就是2
for (i = argcount; i < m; i++) {
//不够的话,便将希望寄托于关键字参数身上,一旦找不到,missing:缺少的参数个数就会+1
if (GETLOCAL(i) == NULL) {
missing++;
}
}
//那么按照我们上面的逻辑,显然还有两个没传递,因此报错
if (missing) {
missing_arguments(co, missing, defcount, fastlocals);
goto fail;
}
//下面可能难理解,我们说这个m,是我们按照位置参数方式传递时,需要传递的参数个数
//而n是以位置参数的形式传递过来的参数的个数,如果比函数参数个数少,那么n就是传来的参数个数,如果比函数参数的个数大,那么n则是函数参数的个数。比如:
/*
def foo(a, b, c, d=1, e=2, f=3):
pass
这是一个有6个参数的函数,显然m是3,实际上函数定义好了,m就是一个不变的值了,就是没有默认参数的参数总个数
但是我们调用时可以是foo(1,2,3),也就是只传递3个,那么这里的n就是3,
foo(1, 2, 3, 4, 5),那么显然n=5,而m依旧是3
*/
if (n > m)
//因此现在这里的逻辑就很好理解了,假设调用时foo(1, 2, 3, 4, 5)
//由于有3个是默认参数,那么调用只传递3个就可以了,但是这里传递了5个,前3个是必传的
//至于后面两个,则说明我不想使用默认值,我想重新传递,而使用默认值的只有最后一个
//所以这个i就是明明可以使用默认值、但却没有使用的参数的个数
i = n - m;
else
//另外如果按照位置参数传递的话,程序能走到这一步,说明已经不存在少传的情况了,因此这个n至少是>=m的,因此如果n == m的话,那么n就是0
i = 0;
//另外我们看到,我们传递的参数在这之前就已经设置到f_localsplus里面去了
//但是如果传递的参数不够呢?那么显然要设置为默认值
//这里就是设置默认值的操作
for (; i < defcount; i++) {
//默认参数的值一开始就已经被压入栈中,整体作为一个PyTupleObject对象,被设置到了func_defaults这个域中
//但是对于函数的参数来讲,肯定还要设置到f_localsplus里面去,并且它只能是在后面。
//因为默认参数的顺序要在非默认参数之后
if (GETLOCAL(m+i) == NULL) {
//这里是把索引为i对应的值从func_defaults对应的PyTupleObject里面取出来
//这个i要么是n-m,要么是0。还按照之前的例子,函数接收6个参数,但是我们传了5个
//因此我们只需要将最后一个、也就是索引为2的元素拷贝到f_localsplus里面去即可。
//而n=5,m=3,显然i = 2
//那么如果我们传递了3个呢?显然i是0,因为此时n==m嘛,那么就意味着默认参数都使用默认值,既然这样,那就从头开始开始拷呗。
//同理传了4个参数,证明第一个默认参数的默认值是不需要的,那么就只需要再把后面两个拷过去就可以了,那么显然要从索引为1的位置拷到结束,而此时n-m、也就是i,正好为1
//所以,n-m就是"默认参数值组成的PyTupleObject对象中需要拷贝到f_localsplus中的第一个值的索引",然后i < defcount; i++,一直拷到结尾
PyObject *def = defs[i];
Py_INCREF(def);
//将值设置到f_localsplus里面,这里显然索引是m+i
//比如:def foo(a,b,c,d=1,e=2,f=3)
//foo(1, 2, 3, 4),显然d不会使用默认值,那么只需要把后两个默认值拷给e和f即可
//显然e和f根据顺序在f_localsplus中对应索引为4、5
//m是3,i是n-m等于4-3等于1,所以m+i正好是4,
//f_localsplus: [1, 2, 3, 4]
//PyTupleObject: (1, 2, 3)
//因此PyTupleObject中索引为i的元素,拷贝到f_localsplus中正好是对应m+i的位置
SETLOCAL(m+i, def);
}
}
}
...
...
return retval;
}因此通过以上我们就知道了位置参数的默认值是怎么一回事了
函数的第二次调用:foo(b=3)
在对foo进行第二次调用的时候,我们指定了b=3,但是调用方式本质是一样的。在CALL_FUNCTION之前,python虚拟机将PyUnicodeObject对象b和PyLongObject对象3压入了运行时栈。
//遍历关键字参数,确定函数的def语句中是否出现了关键字参数的名字
for (i = 0; i < kwcount; i += kwstep) {
PyObject **co_varnames;
PyObject *keyword = kwnames[i];
PyObject *value = kwargs[i];
Py_ssize_t j;
if (keyword == NULL || !PyUnicode_Check(keyword)) {
PyErr_Format(PyExc_TypeError,
"%U() keywords must be strings",
co->co_name);
goto fail;
}
co_varnames = ((PyTupleObject *)(co->co_varnames))->ob_item;
//在函数的符号表中寻找关键字参数
for (j = 0; j < total_args; j++) {
PyObject *name = co_varnames[j];
if (name == keyword) {
goto kw_found;
}
}
/* Slow fallback, just in case */
for (j = 0; j < total_args; j++) {
PyObject *name = co_varnames[j];
int cmp = PyObject_RichCompareBool( keyword, name, Py_EQ);
if (cmp > 0) {
goto kw_found;
}
else if (cmp < 0) {
goto fail;
}
}
assert(j >= total_args);
if (kwdict == NULL) {
PyErr_Format(PyExc_TypeError,
"%U() got an unexpected keyword argument '%S'",
co->co_name, keyword);
goto fail;
}
if (PyDict_SetItem(kwdict, keyword, value) == -1) {
goto fail;
}
continue;
kw_found:
if (GETLOCAL(j) != NULL) {
PyErr_Format(PyExc_TypeError,
"%U() got multiple values for argument '%S'",
co->co_name, keyword);
goto fail;
}
Py_INCREF(value);
SETLOCAL(j, value);
}
在编译时:python会将函数的def语句中出现的名称都记录在变量名表(co_varnames)里面。由于我们已经看到,在foo(b=3)的指令序列中,python虚拟机在执行CALL_FUNCTION指令之前会将关键字参数的名字都压入到运行时栈,那么在_PyEval_EvalCodeWithName中就能利用运行时栈中保存的关键字参数的名字在python编译时得到的co_varnames中进行查找。最妙的是,在co_varnames中定义的变量名的顺序和函数的def语句中的参数顺序是一致的。而且经过刚才的分析,我们也知道,在PyFrameObject对象的f_localsplus所维护的内存中,用于存储函数参数的内存也是按照def语句中出现的参数的顺序排列的。所以在co_varnames中搜索到关键字参数的参数名时,我们可以直接根据所得到的序号信息直接设置f_localsplus中的内存,这就为默认参数设置了函数调用者希望的值。
最后再来看看这段代码:
for (; i < defcount; i++) {
//我们说这个是设置默认值的逻辑,但是什么时候发生呢?
//(GETLOCAL(m+i) == NULL)的时候才会发生,但是在这之前我们已经设置了关键字参数
//并且这个设置,我们也说了是按照对应顺序设置的。
//比如foo(b=3),一旦设置b=3,那么此时GETLOCAL(m+i)不再为NULL,那么就不会再从func_defaults里面拷贝了,所以函数里面的b是我们设置的3,而不是默认值2
//再强调一遍,python虚拟机是先把所有默认值放到一个PyTupleObject对象里面
//当我们传的参数不够,那么会到func_default里面拷到f_localsplus里面
//但是如果通过位置参数传递了,就不会进入到此循环里面
//如果是通过关键字参数传递了,会进入循环,但是会由于GETLOCAL(m+i) == NULL这个条件得不到满足,从而依旧不会设置默认值。
if (GETLOCAL(m+i) == NULL) {
PyObject *def = defs[i];
Py_INCREF(def);
SETLOCAL(m+i, def);
}
}至此,python中函数的默认参数机制已经如"出水芙蓉的少女"般大白于天下。
因此我们可以再举个简单例子,总结一下。def foo(a, b, c, d=1,e=2, f=3),对于这样的一个函数。首先python虚拟机知道调用者至少要给a、b、c传递参数。如果是foo(1),那么1会传递给a,但是b和c是没有接受到值的,所以报错。但如果是foo(1, e=4, c=2, b=3),还是老规矩1传递给a,发现依旧不够,这时候会把希望寄托于关键字参数上。并且我们说过def参数的定义顺序、f_localsplus维护的内存中存储的参数的顺序、co_varnames中参数的顺序都是一致的。所以关键字参数是不讲究顺序的,当找到了e=4,那么python虚拟机通过co_varnames符号表,就知道把e设置为f_localsplus中索引为4的地方,c=2,设置为索引为2的地方,b=3,设置为索引为1的地方。那么当位置参数和关键字参数都是设置完毕之后,python虚拟机会检测需要传递的参数、也就是没有默认值的参数,调用者有没有全部传递。
但是这里再插一句,我们说关键字参数设置具体设置在f_localsplus中的哪一个地方,是通过将关键字参数名代入到co_varnames符号表里面查找所得到的的,但是如果这个关键字参数的参数名不在co_varnames里面,怎么办?另外在我们讲位置参数的时候,如果传递的位置参数,比co_argcount还要多,怎么办?对,聪明如你,肯定知道了,就是我们下面要介绍扩展关键字、扩展位置参数。
12.4.5 扩展位置参数和扩展关键字参数
之前我们看到了使用扩展位置参数和扩展关键字参数时指令参数个数的值,我们还是再看一遍吧
def foo(a, b, *args, **kwargs):
pass
print(foo.__code__.co_nlocals) # 4
print(foo.__code__.co_argcount) # 2我们看到对于co_nlocals来说是把*args和**kwargs各自当成了一个参数,所以是4个,但是对于co_argcount来说,也没有算在内,所以是两个。既然如此,那么也如我们之前所分析的,*args可以接收多个位置参数,但是最终这些参数都会放在args这个PyTupleObject对象里面,**kwargs可以接收多个关键字参数,但是这些关键字参数会组成一个PyDictObject对象放在kwargs里面,事实上也确实如此,即使不从源码的角度来分析,从python的实际使用中我们也能得出这个结论。
def foo(*args, **kwargs):
print(args)
print(kwargs)
foo(1, 2, 3, a=1, b=2, c=3)
"""
(1, 2, 3)
{'a': 1, 'b': 2, 'c': 3}
"""
foo(*(1, 2, 3), **{"a": 1, "b": 2, "c": 3})
"""
(1, 2, 3)
{'a': 1, 'b': 2, 'c': 3}
"""当然啦,在传递的时候如果对一个元组或者列表、甚至是字符串使用*,那么会将这个可迭代对象直接打散,相当于传递了多个位置参数。同理如果对一个字典使用**,那么相当于传递了多个关键字参数
下面我们就来看看扩展参数是如何实现的,首先还是进入到_PyEval_EvalCodeWithName这个函数里面来,当然这个函数应该很熟悉了,我们看看扩展参数的处理。
//ceval.c
PyObject *
_PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals,
//位置参数的相关信息
PyObject *const *args, Py_ssize_t argcount,
//关键字参数的相关信息
PyObject *const *kwnames, PyObject *const *kwargs,
Py_ssize_t kwcount, int kwstep, //关键字参数个数
//默认值信息
PyObject *const *defs, Py_ssize_t defcount,
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
//拿到PyFunctionObject的PyCodeObject
PyCodeObject* co = (PyCodeObject*)_co;
//声明一个PyFrameObject
PyFrameObject *f;
PyObject *retval = NULL;
PyObject **fastlocals, **freevars;
PyThreadState *tstate;
PyObject *x, *u;
//获取总参数的个数
const Py_ssize_t total_args = co->co_argcount + co->co_kwonlyargcount;
Py_ssize_t i, n;
//字典
PyObject *kwdict;
...
...
...
//创建一个PyFrameObject
f = _PyFrame_New_NoTrack(tstate, co, globals, locals);
if (f == NULL) {
return NULL;
}
//函数的所有参数
fastlocals = f->f_localsplus;
//加上内部的闭包
freevars = f->f_localsplus + co->co_nlocals;
//判断是否传递扩展关键字参数,CO_VARKEYWORDS和下面的CO_VARARGS都是标识符
//用于判断是否出现了扩展关键字参数和扩展位置参数
if (co->co_flags & CO_VARKEYWORDS) {
//创建一个字典
kwdict = PyDict_New();
if (kwdict == NULL)
goto fail;
//i是参数总个数,假设值foo(a, b, c, *args, **kwargs)
//那么i就是3,
i = total_args;
//如果还传递了扩展位置参数,那么i要加上1
//因为即使是扩展,关键字参数依旧要在位置参数后面
if (co->co_flags & CO_VARARGS) {
i++;
}
//如果没有扩展位置参数,那么kwdict要处于索引为3的位置
//有扩展位置参数,那么kwdit处于索引为4的位置,这显然是合理的
//然后放到f_localsplus
SETLOCAL(i, kwdict);
}
else {
//如果没有的话,那么为NULL
kwdict = NULL;
}
/* Copy positional arguments into local variables */
//这里我们之前介绍了,是将位置参数拷贝到本地(显然这里不包含扩展位置参数)
if (argcount > co->co_argcount) {
n = co->co_argcount;
}
else {
n = argcount;
}
for (i = 0; i < n; i++) {
x = args[i];
Py_INCREF(x);
SETLOCAL(i, x);
}
/* Pack other positional arguments into the *args argument */
//关键来了,将其他的位置参数拷贝到*args里面去
if (co->co_flags & CO_VARARGS) {
//申请一个argcount - n大小的元组
u = PyTuple_New(argcount - n);
if (u == NULL) {
goto fail;
}
SETLOCAL(total_args, u);
//将剩余的位置参数拷贝到PyTupleObject里面去
for (i = n; i < argcount; i++) {
x = args[i];
Py_INCREF(x);
PyTuple_SET_ITEM(u, i-n, x);
}
}
/* Handle keyword arguments passed as two strided arrays */
//下面就是拷贝扩展关键字参数,但是我们发现这里是从两个数组中分别得到符号和值的信息的
//因此再结合最上面的变量声明,我们就明白了,我们传递的关键字参数并不是上来就设置到字典里面
//而是将符号和值各自存储在对应的数组里面,显然就是下面的kwnames和kwargs
//然后使用索引遍历,按照顺序依次取出,通过比较传递的关键字参数的符号是否已经出现在函数定义的参数中,来判断传递的这个参数究竟是普通的关键字参数,还是扩展关键字参数
//比如:def foo(a, b, c, **kwargs),那么foo(1, 2, c=3, d=4)
//那么显然关键字参数有两个c=3和d=4,那么c已经出现在了函数定义的参数中,所以c就是一个普通的关键字参数,但是d没有,所有d同时也是扩展关键字参数,因此要设置到kwargs这个字典里面
kwcount *= kwstep;
//按照索引,依次遍历
for (i = 0; i < kwcount; i += kwstep) {
PyObject **co_varnames; //符号表
PyObject *keyword = kwnames[i]; //关键字参数的key
PyObject *value = kwargs[i]; //关键字参数的value
Py_ssize_t j;
if (keyword == NULL || !PyUnicode_Check(keyword)) {
PyErr_Format(PyExc_TypeError,
"%U() keywords must be strings",
co->co_name);
goto fail;
}
/* Speed hack: do raw pointer compares. As names are
normally interned this should almost always hit. */
//拿到符号表,得到所有的符号,这样就知道函数参数有哪些变量
co_varnames = ((PyTupleObject *)(co->co_varnames))->ob_item;
//我们看到内部又是一层for循环
//首先外层循环是遍历所有的关键字参数,也就是我们传递的参数
//而内层循环则是遍历符号表、也就是函数的所有参数
for (j = 0; j < total_args; j++) {
//将我们传来每一个关键字参数的符号都会和符号表中的所有符号进行比对
PyObject *name = co_varnames[j];
//如果相等,说明传递的是关键字参数,并不是扩展关键字参数
if (name == keyword) {
//进入kw_found
goto kw_found;
}
}
/* Slow fallback, just in case */
//这里富比较,逻辑和上面一样
for (j = 0; j < total_args; j++) {
PyObject *name = co_varnames[j];
int cmp = PyObject_RichCompareBool( keyword, name, Py_EQ);
if (cmp > 0) {
goto kw_found;
}
else if (cmp < 0) {
goto fail;
}
}
assert(j >= total_args);
//走到这里,说明肯定传入了符号不在符号表co_varnames里面的关键字参数
//如果kwdict是NULL,证明根本函数根本没定义扩展参数,那么就直接报错了
if (kwdict == NULL) {
//显示函数接收了一个不期望的关键字参数
PyErr_Format(PyExc_TypeError,
"%U() got an unexpected keyword argument '%S'",
co->co_name, keyword);
goto fail;
}
//这里将属于扩展关键字参数的keyword和value都设置到之前创建的字典里面去
//然后continue进入下一个关键字参数逻辑
if (PyDict_SetItem(kwdict, keyword, value) == -1) {
goto fail;
}
continue;
kw_found:
//之前我们说,如果不是扩展,而是普通关键字参数那么会走这一步
//获取对应的符号,但是发现不为NULL,说明已经通过位置参数传递了
if (GETLOCAL(j) != NULL) {
//那么这里就报出一个TypeError,表示某个参数接收了多个值
PyErr_Format(PyExc_TypeError,
"%U() got multiple values for argument '%S'",
co->co_name, keyword);
//比如说:def foo(a, b, c=1, d=2)
//如果这样传递的foo(1, 2, c=3),那么肯定没问题
/*
因为开始会把位置参数拷贝到f_localsplus里面,所以此时f_localsplus是[a, b, NULL, NULL]
然后设置关键字参数的时候,此时的j对应索引为2,那么GETLOCAL(j)是NULL,所以不会报错
*/
//但如果这样传递,foo(1, 2, 3, c=3)
//那么不好意思,此时f_localsplus则是[a, b, c, NULL],GETLOCAL(j)是c,不为NULL
//说明c这个位置已经有人传递了,那么关键字参数就不能传递了
//还是那句话f_localsplus存储的是符号,每一个符号都会对应相应的值,这些顺序都是一致的
goto fail;
}
Py_INCREF(value);
SETLOCAL(j, value);
}
/* Check the number of positional arguments */
//下面的逻辑,就是普通位置参数和关键字参数的传递、设置等等,已经说过了
...
...
...
}其实扩展关键字参数的传递机制和普通关键字参数的传递机制有很大的关系,我们之前分析函数参数的默认值机制已经看到了关键字参数的传递机制,这里我们再次看到了。对于关键字参数,不论是否扩展,都会把符号和值分别按照对应顺序放在两个数组里面。然后python会按照索引的顺序,遍历存放符号的数组,对每一个符号都会和符号表co_varnames里面的符号逐个进行比对,发现在符号表中找不到我们传递的关键字参数的符号,那么就说明这是一个扩展关键字参数。然后就是我们在源码中看到的那样,如果函数定义了**kwargs,那么kwdict就不为空,会把扩展关键字参数直接设置进去,否则就报错了,提示接收到了一个不期待的关键字参数。
而且python虚拟机也确实把该PyDictObject(kwargs)放到了f_localsplus中,这个f_localsplus里面包含了所有的参数,不管是什么参数,都会在里面。但是kwargs一定是在最后面,至于*args理论上是没有顺序的,你是可以这么定义的:def foo(a, *args, b),这样定义是完全没有问题的,只是此时的b就必须要通过关键字参数来传递了,因为如果不通过关键字参数的方式,那么无论多少个位置参数,都会止步于*args。之前也介绍过,假设只需要name,age, gender这三个参数,并且gender必须要通过关键字参数指定的话,那么就可以这么设计:def foo(name, age, *, gender),我们看到连args都省去了,只保留一个*,这是因为我们定义了args也用不到,我们只是保证后面的gender必须通过关键字方式传递,所以只需要一个*就ok了。另外在python3.8中,注意只有python3.8开始才支持,可以强制使用位置参数,语法是通过/。至于具体怎么样就不介绍了,我们这是源码剖析,而且python版本是3.7,想看用法的话可以参考我的这一篇博客:https://www.cnblogs.com/traditional/p/11300448.html
当然访问传递过来的扩展位置参数和扩展关键字参数就通过args对应的PyTupleObject和kwargs对应的PyDictObject操作就可以了。
12.5 函数中局部变量的访问
在完成了对函数参数的解析之后,我们来看一看,在python中,函数局部变量是如何实现的。前面提到过,函数参数实际上也是一种局部变量。
x = 123
def foo():
global x
a = 1
b = 2
# a和b是局部变量,x是全局变量,因此是2
print(foo.__code__.co_nlocals) # 2
def bar(a, b):
pass
print(bar.__code__.co_nlocals) # 2
def bar2(a, b):
a = 1
b = 2
c = 3
print(bar2.__code__.co_nlocals) # 3因此我们看到,无论是参数还是内部新创建的变量,本质上都是局部变量。并且我们发现如果函数内部定义的变量如果和函数参数一致,那么个数仍然是1,很好理解,因为本质上就相当于重新赋值罢了,此时外面无论给a和b传递什么,最终都会变成1和2。所以其实局部变量的实现机制和函数参数的实现机制是一致的。
按照我们的理解,当访问一个全局变量的时候,会去访问global命名空间,而这也确实如此。但是当访问函数内的局部变量的时候,是不是访问其内部的local命名空间呢?估计有人觉得答案肯定是啊, 之前不是说了吗?python变量的访问是有规则的,按照本地、闭包、全局、内置的顺序去查找,所以首当其冲当然去local命名空间去查找啊。可不幸的是,在调用函数期间,python通过_PyFrame_New_NoTrack创建PyFrameObject对象时,这个至关重要的local命名空间并没有被创建。
//frameobject.c
PyFrameObject* _Py_HOT_FUNCTION
_PyFrame_New_NoTrack(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
...
...
f->f_locals = NULL;
f->f_trace = NULL;
...
...
}在前面对函数调用时的global命名空间的解析中,我们看到,当python虚拟机执行xxx.py的时候,f_locals和f_globals指向的是同一个PyDictObject对象,然而现在在函数里面f_locals则变成了NULL,那么的话,那些重要的符号到底存储在什么地方呢?别急,我们先来看看使用局部变量的函数。
def foo(a, b):
c = a + b
print(c)
foo(1, 2)1 0 LOAD_CONST 0 (<code object foo at 0x000001D5CCF93030, file "a.py", line 1>)
2 LOAD_CONST 1 ('foo')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (foo)
6 8 LOAD_NAME 0 (foo)
10 LOAD_CONST 2 (1)
12 LOAD_CONST 3 (2)
14 CALL_FUNCTION 2
16 POP_TOP
18 LOAD_CONST 4 (None)
20 RETURN_VALUE
Disassembly of <code object foo at 0x000001D5CCF93030, file "a.py", line 1>:
重点看这里,a和b都是局部变量所以是LOAD_FAST
但是c也是STORE_FAST和LOAD_FAST,说明局部变量和函数参数的本质上是一样的。
都是在f_localsplus中运行是栈前面的那段内存空间中。
2 0 LOAD_FAST 0 (a)
2 LOAD_FAST 1 (b)
4 BINARY_ADD
6 STORE_FAST 2 (c)
3 8 LOAD_GLOBAL 0 (print)
10 LOAD_FAST 2 (c)
12 CALL_FUNCTION 1
14 POP_TOP
16 LOAD_CONST 0 (None)
18 RETURN_VALUE
此时我们对局部变量c的藏身之处已经了然于心。但是为什么在函数的实现中没有使用local命名空间呢?其实函数内部的局部变量有多少,在编译的时候就已经确定了,个数是不会变的。因此编译时就能确定局部变量使用的内存空间位置,也能确定访问局部变量的字节码指令应该如何访问内存。有了这些信息,python就能使用静态的方法来实现局部变量,而不需要借助于动态的查找PyDictObject对象的技术,尽管PyDictObject也是被高度优化的,但肯定没有静态的方法快啊,而且python里面函数是对象,也是一等公民,并且函数使用的太普遍了。至于在后面的类的剖析中,由于类的特殊性,无论是类的实例对象、还是类对象本身,都是可以在运行时动态修改属性的,那么我们知道显然python就不会再对类使用静态方法了。
并且我们还可以从python的层面验证这个结论
x = 1
def foo():
globals()["x"] = 2
foo()
print(x) # 2我们在函数内部访问了global命名空间,而global显然是全局唯一的,在python层面上就是一个dict对象,那么我们修改x,在外部再打印x肯定会变。但是,我要说但是了。
def foo():
x = 1
locals()["x"] = 2
print(x)
foo()
"""
1
"""我们按照相同的套路,却并没有成功,这是为什么?原因就是我们刚才解释的那样,函数内部的局部变量在编译时就已经确定好了,已经放在f_localsplus的运行时栈前面的那一段内存里面了(f_localsplus前面说了,指向的内存分为四部分,我们后面在闭包中还会谈到,其中一部分叫做运行时栈,运行时栈前面的内存就是用来存放局部变量的),至于locals(),只不过是拿到了那些内存里面的值,或者说我们调用的locals()只是我们访问那段内存的一个接口而已。而不像globals(),globals()虽然和locals()都是一个PyDictObject对象,但是全局变量的访问都是从globals()这个字典里面访问的,并且全局唯一,我们调用globals()就直接访问到了存放全局变量的字典,一旦做了更改,肯定会影响外面的全局变量。但是locals则不会,因为它本来就是我们访问f_localsplus前面的那段内存的一个接口。
def foo(a, b):
x = 1
locals()["x"] = 2
print(locals())
print(x)
foo(1, 2)
"""
{'a': 1, 'b': 2, 'x': 1}
1
"""并且此时又出现了一个情况,第二次打印locals()的时候,x也没有变。这是因为每次访问locals()的时候,都会根据f_localsplus前面的那段内存里面维护的值创建一个新的字典,而内存里面的值是不变的,所以每次打印locals()的值也是不变的。这就好比,你通过电脑查看你的支付宝余额,但是通过页面审查元素,把金额给改了,然鹅当你一刷新页面金额又变回原来的了。一个道理,因为页面显示的真实金额最终取决于你在支付宝后台数据库里面存储的金额。
再看一个例子
def foo():
locals()["x"] = 1
print(x)
foo()此时会得到什么结果估计不用我说了。因为外部没有全局变量x,显然builtin里面也没有,只能从内部找,但是内部也没有,因为f_localsplus前面的那段内存里面没有x这个符号。在编译的时候,没有找到类似于x = 1这样字眼,因此尽管在locals()里面,但是也说了,这只是一个拷贝,而f_localsplus前面的那段内存里面是没有的,所以报错。
x = 123
def foo():
locals()["x"] = 1
print(x)
foo() # 123原因不再废话了,一句话:foo函数里面没有x这个变量,所以打印的是全局变量,因此输出123
12.6 嵌套函数、闭包与decorator
我们之前一直反复提到了四个字,命名空间。一段代码执行的结果不光取决于代码中的符号,更多取决于代码中符号的语义,而这个运行时的语义正是由命名空间决定的。命名空间是在运行时由python虚拟机动态维护的,但是有时我们希望将命名空间静态化。换句话说,我们希望有的代码不受命名空间变换带来的影响,始终保持一致的功能该怎么办呢?
比如看下面的例子
def index(name, password, nickname):
if not (name == "satori" and password == "123"):
return "拜拜"
else:
return f"欢迎:{nickname}"
print(index("satori", "123", "hanser")) # 欢迎:hanser
print(index("satori", "123", "yousa")) # 欢迎:yousa我们注意到每次都需要输入username和password,于是我们可以只设置一次基准值,通过使用嵌套函数来实现
def wrap(name, password):
def index(nickname):
if not (name == "satori" and password == "123"):
return "拜拜"
else:
return f"欢迎:{nickname}"
return index
index = wrap("satori", "123")
print(index("hanser")) # 欢迎:hanser
print(index("yousa")) # 欢迎:yousa尽管我们调用index的时候,local命名空间(对应那片内存)里面没有name和password,但是warp里面有。也就是说,index函数作为wrap函数的返回值被传递的时候,有一个命名空间(wrap的local命名空间)就已经和index紧紧地绑定在一起了,在执行内层函数index的时候,在自己的local命名空间找不到,就会从和自己绑定的local命名空间里面去找,这就是一种命名空间静态化的方法。这个命名空间和内层函数捆绑之后的结果我们就称之为闭包(closure)
在前面我们也知道了,PyFunctionObject是python虚拟机专门为字节码指令准备的大包袱,global命名空间,默认参数都能在PyFunctionObject中与字节码指令捆绑在一起,同样的,PyFunctionObject就是python中闭包的具体体现了。
def wrap(name, password):
# 内层函数也定义了一个password
def index(nickname, password=password):
if not (name == "satori" and password == "123"):
return "拜拜"
else:
return f"欢迎:{nickname}"
return index
index = wrap("satori", "123")
print(index("hanser")) # 欢迎:hanser
print(index("yousa")) # 欢迎:yousa
print(index("yousa", "321")) # 拜拜首先index里面password肯定用的是index参数里面的password,但是我们发现利用函数的默认参数实现了闭包的效果,但是我们指定了参数就不一样了。可能有人发现了这有点像默认参数啊,这不就相当于把外层的wrap拿走,然后index加一个参数name、和password="123"吗(不考虑顺序的话)?实际上确实比较类似,但肯定实现的机制不一样,如果一样的话,那么python就没有必要实现闭包了。那python的闭包到底如何实现的,我们先放一放,先来看看PyCodeObject、PyFunctionObject、PyFrameObject这些我们已经很熟悉的对象中,与闭包相关的属性。
12.6.1 实现闭包的基石
闭包的创建通常是利用嵌套的函数来完成的,在PyCodeObject中,与嵌套函数相关的属性是co_cellvars和co_freevars,两者的具体含义如下:
co_cellvars:通常是一个tuple,保存了嵌套的作用域中使用的变量名的集合
co_freevars:通常是一个tuple,保存了使用了的外层作用域中的变量名集合。
光看概念的话比较抽象,实际演示一下:
def foo():
name = "mashiro"
age = 16
gender = "female"
def bar():
nonlocal name
nonlocal age
xx = "123"
return bar
print(foo.__code__.co_cellvars) # ('age', 'name')
print(foo().__code__.co_freevars) # ('age', 'name')
print(foo.__code__.co_freevars) # ()
print(foo().__code__.co_cellvars) # ()我们发现无论是外层函数还是内层函数都有co_cellvars和co_freevars,但是无论是co_cellvars还是co_freevars,得到结果是一样的,都是内层函数使用nonlocal声明的变量(以及被内层函数使用的外层函数的变量)。只不过外层函数需要使用co_cellvars获取,内层函数需要使用co_freevars获取。如果使用外层函数获取co_freevars的话,那么得到的结果显然就是个空元组的,除非foo作为某个函数的内层函数,并且内部有nonlocal声明,同理内层也是一样的道理。
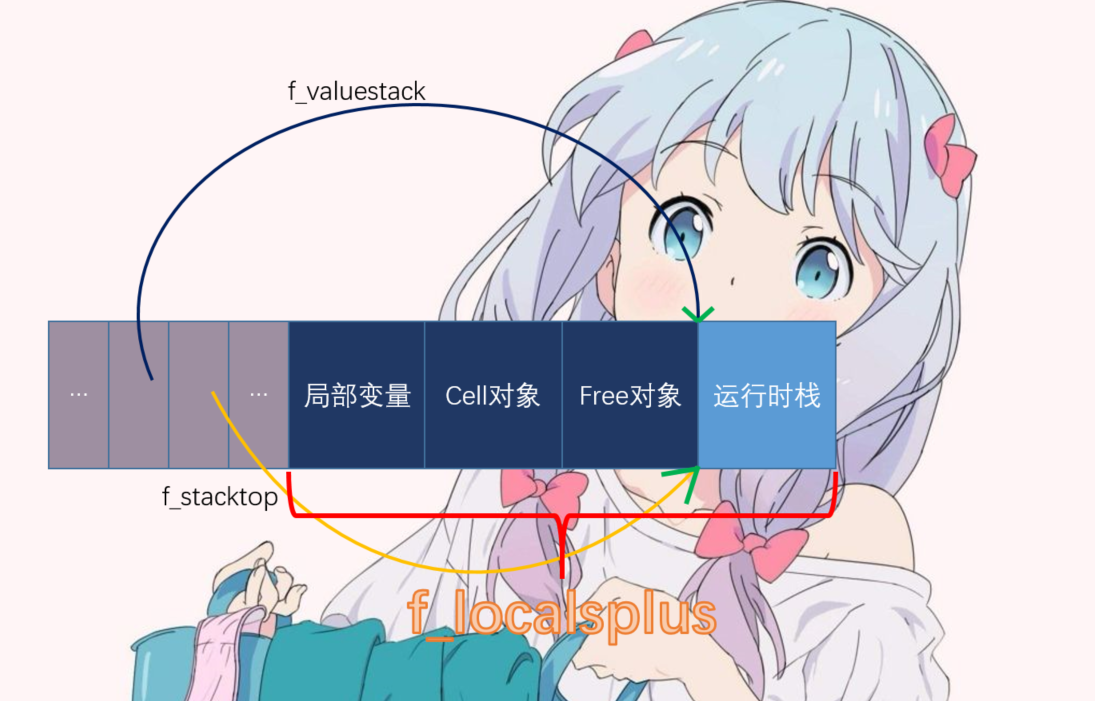
在PyFrameObject对象中,也有一个属性和闭包的实现相关,这个属性就是f_localsplus,这样一说,是不是有些隐隐约约察觉到了呢?其实在_PyFrame_New_NoTrack就有一行代码泄漏了天机
//frameobject.c
PyFrameObject* _Py_HOT_FUNCTION
_PyFrame_New_NoTrack(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
...
...
Py_ssize_t extras, ncells, nfrees;
ncells = PyTuple_GET_SIZE(code->co_cellvars);
nfrees = PyTuple_GET_SIZE(code->co_freevars);
//玄机在这里,extras正是f_localsplus指向的那片内存的大小,这里已经清晰的说明了
//这片内存是属于四个老铁的:运行时栈,局部变量,cell对象(对应co_cellvars),free对象(对应co_freevars),但是各自的顺序不是按照这个顺序来的
extras = code->co_stacksize + code->co_nlocals + ncells +
nfrees;
...
...到此为止,f_localsplus的面纱终于被彻底的揭开。
当然在PyFunctionObject中,还有一个和闭包实现相关的属性。我们在下一个小节介绍,毕竟PyFunctionObject是PyCodeObject的一个大包袱嘛,当然要着重介绍了。
12.6.2 闭包的实现
在介绍了实现闭包的基石之后,我们可以开始追踪闭包的具体实现过程了,当然还是要先看一下闭包对应的字节码,老规矩嘛。
def get_func():
value = "inner"
def func():
print(value)
return func
show_value = get_func()
show_value()首先这个py文件执行之后,肯定会打印出"inner"这个字符串,下面让我们来看看它的字节码
LOAD_CONST字节码,
1 0 LOAD_CONST 0 (<code object get_func at 0x0000024D979032F0, file "a.py", line 1>)
LOAD_CONST符号名,get_func
2 LOAD_CONST 1 ('get_func')
MAKE_FUNCTION将字节码包装成函数
4 MAKE_FUNCTION 0
STORE_NAME将get_func和PyFunctionObject组合成一个entry存储起来
6 STORE_NAME 0 (get_func)
执行函数,先LOAD_NAME,找到符号get_func对应的函数
10 8 LOAD_NAME 0 (get_func)
CALL_FUNCTION调用函数
10 CALL_FUNCTION 0
show_value = get_func(),相当于执行完毕之后, 直接把show_value和返回值组合成一个entry存储起来
12 STORE_NAME 1 (show_value)
LOAD_NAME得到符号show_value对应的值
11 14 LOAD_NAME 1 (show_value)
继续CALL_FUNCTION调用函数
16 CALL_FUNCTION 0
从栈顶打印元素
18 POP_TOP
LOAD_CONST将None值load进来
20 LOAD_CONST 2 (None)
然后返回,注意此时是py文件对应的字节码的执行过程,函数是一带而过的,下面看函数
22 RETURN_VALUE
Disassembly of <code object get_func at 0x0000024D979032F0, file "a.py", line 1>:
我们发现很多之前没有看过的
LOAD_CONST是把字符串'inner'这个常量load进来
2 0 LOAD_CONST 1 ('inner')
但是下面的STORE_DEREF是什么鬼?从功能来看应该类似于STORE_FAST,具体是啥暂时不用管
2 STORE_DEREF 0 (value)
然后又是一条未见过的指令,不过这个我们从名字上可以看出来是load一个闭包
4 4 LOAD_CLOSURE 0 (value)
BUILD一个TUPLE
6 BUILD_TUPLE 1
LOAD字节码,显然是内层函数func的字节码
8 LOAD_CONST 2 (<code object func at 0x0000024D97903240, file "a.py", line 4>)
又是一个LOAD_CONST,我们按照之前的分析,这次LOAD的应该是外层的local命名空间
10 LOAD_CONST 3 ('get_func.<locals>.func')
又是MAKE_FUNCTION,我们注意到参数是8,代表这个指令需要8个参数,鬼鬼~~~,而且括号里面写着closure,表示这是个闭包
12 MAKE_FUNCTION 8 (closure)
调用STORE_FAST,将符号func和之前的PyFunctionObject组合成entry存储起来
14 STORE_FAST 0 (func)
因为我们返回了func,所以LOAD_CONST的参数是func
7 16 LOAD_FAST 0 (func)
将符号func对应的值返回
18 RETURN_VALUE
Disassembly of <code object func at 0x0000024D97903240, file "a.py", line 4>:
最后则是调用闭包的逻辑,闭包逻辑很简单就一行print,但是有一条指令我们没见过
首先是LOAD_GLOBAL得到print函数,这不需要多说
5 0 LOAD_GLOBAL 0 (print)
关键是这条LOAD_DEREF指令,显然和上面的STORE_DEREF是一组,关系应该是类似于LOAD_FAST和STORE_FAST之间的关系那样
2 LOAD_DEREF 0 (value)
调用函数
4 CALL_FUNCTION 1
从栈顶弹出并打印元素
6 POP_TOP
LOAD_CONST得到None
8 LOAD_CONST 0 (None)
返回
10 RETURN_VALUE
我们看到了几个不认识的指令,不过不用慌,我们下面会顺藤摸瓜,沿着那美丽动人的曲线慢慢地、逐一探索。目前只需要知道,在python虚拟机执行8 LOAD_CONST指令的时候,就已经开始为closure的实现悄悄地添砖加瓦了。
创建closure
我们前面介绍了,虚拟机在执行CALL_FUNCTION指令时,会进入_PyFunction_FastCallKeywords。
if (co->co_kwonlyargcount == 0 && nkwargs == 0 &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))而在_PyFunction_FastCallKeywords中,由于当前的PyCodeObject为函数get_func对应的PyCodeObject。对于有闭包的函数来说,显然这个条件是不满足的,因此不会进入快速通道,而是会进入_PyEval_EvalCodeWithName。而且当前的这个PyCodeObject的co_cellvars是有东西,可能这里有人奇怪了,我们没看到代码里面使用nonlocal声明啊,其实之前说了,还有内层函数使用的外层函数的变量
def get_func():
value1 = "inner"
value2 = "inner"
def func():
value2 = ""
print(value1)
print(value2)
return func
print(get_func.__code__.co_cellvars) # ('value1',)
print(get_func().__code__.co_freevars) # ('value1',)我们发现了内层函数自己定义了value2,所以它不再co_cellvars中,但是value1在内层函数中没有,而是使用的外层函数内部的value1变量,所以它也在co_cellvars中。因此除了那些被nonlocal关键字声明的变量之外,还有被内层函数使用的外层函数的变量
因此在_PyEval_EvalCodeWithName中,python虚拟机会如同处理默认参数一样,将co_cellvars中的东西拷贝到新创建的PyFrameObject的f_localsplus中
PyObject *
_PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, Py_ssize_t argcount,
PyObject *const *kwnames, PyObject *const *kwargs,
Py_ssize_t kwcount, int kwstep,
PyObject *const *defs, Py_ssize_t defcount,
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
/* Allocate and initialize storage for cell vars, and copy free
vars into frame. */
for (i = 0; i < PyTuple_GET_SIZE(co->co_cellvars); ++i) {
//声明闭包对象,对的,闭包也是一个对象
PyObject *c;
Py_ssize_t arg;
/* Possibly account for the cell variable being an argument. */
//处理被嵌套函数共享的外层函数的局部变量
if (co->co_cell2arg != NULL &&
(arg = co->co_cell2arg[i]) != CO_CELL_NOT_AN_ARG) {
c = PyCell_New(GETLOCAL(arg));
/* Clear the local copy. */
SETLOCAL(arg, NULL);
}
else {
c = PyCell_New(NULL);
}
if (c == NULL)
goto fail;
SETLOCAL(co->co_nlocals + i, c);
}
嵌套函数有时候很复杂,如果嵌套的层数比较多的话
def foo1():
def foo2():
x = 1
def foo3():
x = 2
def foo4():
print(x)
return foo4
return foo3
return foo2
foo1()()()()
"""
2
"""但是无论多少层,我们之前说的结论是不会变的。之前我们提到了,闭包在python底层也是一个对象,那它必然也是一个PyObject *类型
//cellobject.h
typedef struct {
PyObject_HEAD
PyObject *ob_ref; /* Content of the cell or NULL when empty */
} PyCellObject;闭包这个对象似乎出乎意料的简单,仅仅维护了一个PyObject_HEAD,和一个ob_ref(指向某个对象的指针)
//cellobject.c
PyObject *
PyCell_New(PyObject *obj)
{
//声明一个PyCellObject对象
PyCellObject *op;
//为这个PyCellObject申请空间,类型是PyCell_Type
op = (PyCellObject *)PyObject_GC_New(PyCellObject, &PyCell_Type);
if (op == NULL)
return NULL;
//这里的obj是什么呢?显然是上面_PyEval_EvalCodeWithName里面的GETLOCAL(arg)或者NULL
//说白了,就是我们之前说的那些被内层函数引用的外层函数的局部变量,或者NULL,如果没人引用的话就是NULL
op->ob_ref = obj;
Py_XINCREF(obj);
_PyObject_GC_TRACK(op);
return (PyObject *)op;
}但是实际上一开始是不知道这个ob_ref指向的是谁的,什么时候才知道呢?是在我们一开始的闭包代码中,那句value = 'inner'指令指令的时候,才会真正知道ob_ref指向的是谁。随后这个cell对象被拷贝到了新创建的PyFrameObject对象的f_localsplus中,并且位置是co->co_nlocals+i,说明在f_localsplus中,cell对象的位置是在局部变量之后的,这完全符合我们刚才图中的布局。
但是我们发现了一个奇怪的地方,那就是我们发现这个cell对象(value)好像没有设置名字诶。实际上这个和我们之前提到的python虚拟机将对局部变量符号的访问方式从PyDictObject的查找变成了对PyListObject的索引是一个道理。在get_func这个函数执行的过程中,对value这个cell对象是通过基于索引访问在f_localsplus中完成,因此完全不需要知道cell对象的名字。这个cell对象的名字实际上是在处理被内层函数引用外层函数的默认参数是产生的。我们说参数和内部的创建的变量都是局部变量,在处理默认参数的时候,就把value这个cell对象一并处理了。
在处理了cell对象之后,python虚拟机将正式进入PyEval_EvalFrameEx,从而正式开始对函数get_func的调用过程。再看一下字节码:
Disassembly of <code object get_func at 0x0000024D979032F0, file "a.py", line 1>:
2 0 LOAD_CONST 1 ('inner')
2 STORE_DEREF 0 (value)
4 4 LOAD_CLOSURE 0 (value)
6 BUILD_TUPLE 1
8 LOAD_CONST 2 (<code object func at 0x0000024D97903240, file "a.py", line 4>)
10 LOAD_CONST 3 ('get_func.<locals>.func')
12 MAKE_FUNCTION 8 (closure)
14 STORE_FAST 0 (func)
18 RETURN_VALUE
Disassembly of <code object func at 0x0000024D97903240, file "a.py", line 4>:
5 0 LOAD_GLOBAL 0 (print)
2 LOAD_DEREF 0 (value)
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE我们看到执行0 LOAD_CONST 1 ('inner')之后,会将PyUnicodeObject对象'inner'压入到运行时栈,紧接着便执行一条我们从未见过的全新的字节码指令--STORE_DEREF
[_PyEval_EvalFrameDefault]
freevars = f->f_localsplus + co->co_nlocals;
[STORE_DEREF]
TARGET(STORE_DEREF) {
//这里pop弹出的显然是运行时栈的PyUnicodeObject对象'inner'
PyObject *v = POP();
//获取cell,也就是闭包
//注意:这里要和之前说的cell对象区分一下,之前的cell对象是变量
//这里的cell则是闭包(内层函数+外层函数的局部作用域)
PyObject *cell = freevars[oparg];
//获取老的cell对象
PyObject *oldobj = PyCell_GET(cell);
//我们看到了一个PyCell_SET,那么玄机肯定就在这里面了
PyCell_SET(cell, v);
Py_XDECREF(oldobj);
DISPATCH();
}因此我们发现,ob_ref指向的对象似乎就是通过PyCell_SET设置的,没错,这家伙就是干这个勾当的。
//cellobject.h
PyAPI_FUNC(int) PyCell_Set(PyObject *, PyObject *);
//cellobject.c
int
PyCell_Set(PyObject *op, PyObject *obj)
{
PyObject* oldobj;
if (!PyCell_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
oldobj = PyCell_GET(op);
Py_XINCREF(obj);
PyCell_SET(op, obj);
Py_XDECREF(oldobj);
return 0;
}
如此一来,f_localsplus就发生了变化。
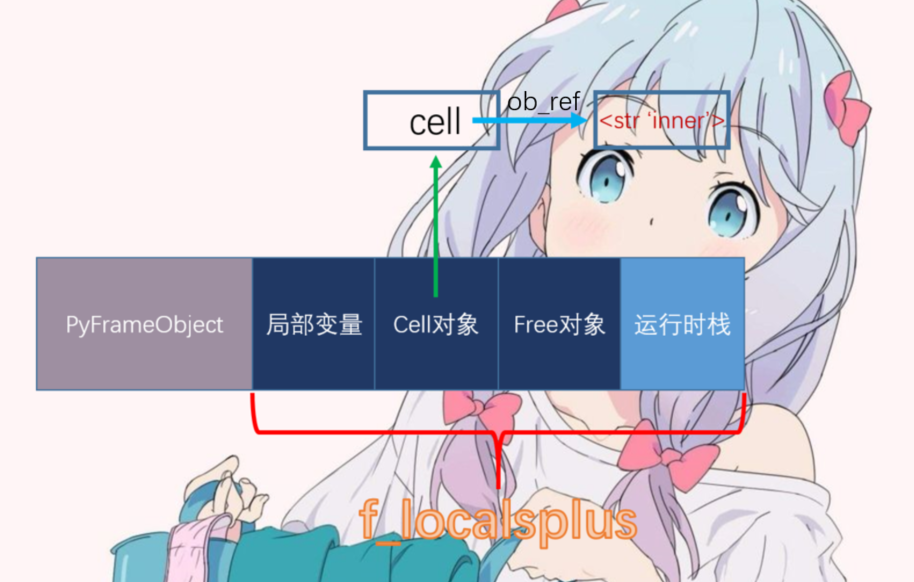
现在在get_func的环境中我们知道了value符号对应着一个PyUnicodeObject对象,但是closure是要将这个约束进行冻结,是的在嵌套函数func中被调用的时候还可以使用这个约束。这一次,我们的工具人PyFunctionObject就又登场了,在执行接下来的def func()表达式对应的字节码时,python虚拟机就会将(value, 'inner')这个约束塞到PyFunctionObject中。
//ceval.c
//向PyEval、以及字节码指令都在ceval.c中
TARGET(LOAD_CLOSURE) {
PyObject *cell = freevars[oparg];
Py_INCREF(cell);
PUSH(cell);
DISPATCH();
}4 LOAD_CLOSURE会将刚刚放置好的PyCellObject对象取出,并压入运行时栈,紧接着6 BUILD_TUPLE指令将PyCellObject对象打包进一个PyTupleObject对象,显然这个PyTupleObject对象中可以存放多个PyCellObject对象,只不过我们的例子中只有一个PyCellObject。
随后python虚拟机通过8 LOAD_CONST和10 LOAD_CONST将内层函数func对应PyCodeObject和符号LOAD进来,压入运行时栈,紧接着以一个12 MAKE_FUNCTION 8指令完成约束和PyCodeObject之间的绑定,注意这里的字节码指令依旧是MAKE_FUNCTION,但是参数是8,我们再次看看MAKE_FUNCTION这个指令,还记得这个指令在哪里吗?没错,之前说了只要是字节码指令,都在ceval.c中
TARGET(MAKE_FUNCTION) {
//弹出名字
PyObject *qualname = POP();
//弹出PyCodeObject
PyObject *codeobj = POP();
//根据PyCodeObject对象、global命名空间、名字构造出PyFunctionObject
PyFunctionObject *func = (PyFunctionObject *)
PyFunction_NewWithQualName(codeobj, f->f_globals, qualname);
Py_DECREF(codeobj);
Py_DECREF(qualname);
if (func == NULL) {
goto error;
}
//我们看到参数是8,因此这个条件是成立的
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
//弹出闭包需要使用的变量信息,将该信息写入到func_closure中
func ->func_closure = POP();
}
//这是处理注解的:只在python3.6+中存在
if (oparg & 0x04) {
assert(PyDict_CheckExact(TOP()));
func->func_annotations = POP();
}
//处理关键字参数
if (oparg & 0x02) {
assert(PyDict_CheckExact(TOP()));
func->func_kwdefaults = POP();
}
//处理默认参数
if (oparg & 0x01) {
assert(PyTuple_CheckExact(TOP()));
func->func_defaults = POP();
}
//压入运行时栈
PUSH((PyObject *)func);
DISPATCH();
}
此时便将约束(内层函数需要使用的作用域信息)和内层函数绑定在了一起。然后执行14 STORE_FAST将新创建的PyFunctionObject对象放置到了f_localsplus当中。这样的话,f_localsplus就又发生了变化
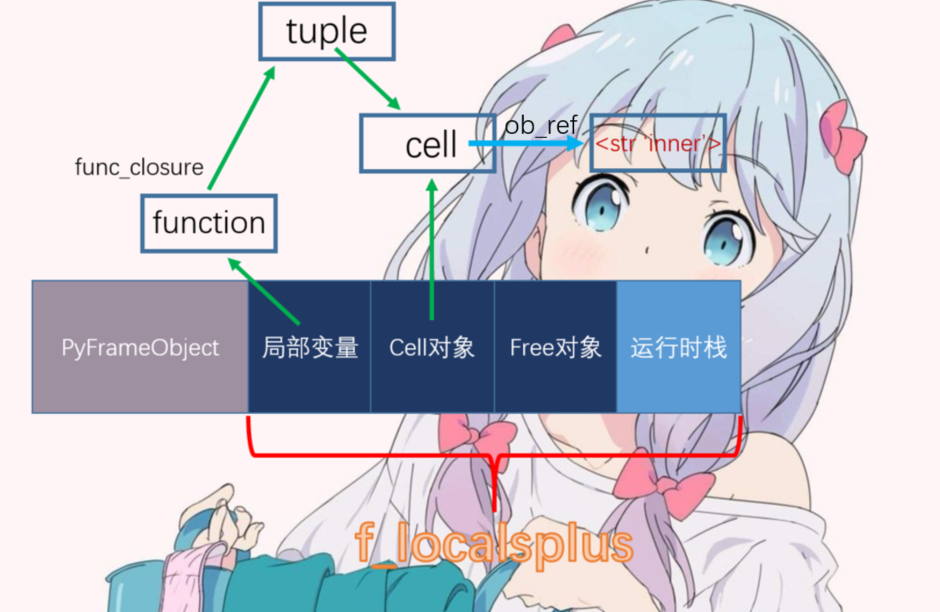
从图上我们发现内层函数居然在get_func的局部变量里面,是的没有错。其实按照我们之前说的,函数即变量,所以函数和普通变量一样,都是在上一级栈帧的f_localsplus里面的。最后这个新建的PyFunctionObject对象被压入到了上一级栈帧的运行时栈中,并且被作为上一个栈帧的返回值返回了。显然有人就能猜到下一步要介绍什么了,既然拿到了闭包、或者说内层函数对应的PyFunctionObject,那么肯定要使用啊。而且估计有人猜到了,当外面拿到闭包的时候,调用,显然会找到对应的闭包(PyFunctionObject),然后抽出里面的PyCodeObject对象继续创建栈帧。
使用闭包
closure是在get_func函数中被创建的,而对closure的使用,则是在inner_func中。在执行show_value()对应的CALL_FUNCTION指令时,和func对应的PyCodeObject对象的co_flags域中包含了CO_NESTED,因此在_PyFunction_FastCallKeywords函数中不会进入快速通道function_code_fastcall,而是会进入_PyEval_EvalCodeWithName、PyEval_EvalFrameEx、继而进入_PyEval_EvalFrameDefault。不过问题是,你怎么知道co_flags域中包含了CO_NESTED呢?
def get_func():
value = "inner"
def func():
print(value)
return func
show_value = get_func()
print(show_value.__code__.co_flags) # 19我们看到func函数的字节码的co_flags是19,那么这个值是什么计算出来的呢?还是记得我们在介绍PyCodeObject对象和pyc文件那一章中,当时我说,co_flags这个域主要用于mask,暂时没什么用,现在有用了。
//code.h
/* Masks for co_flags above */
#define CO_OPTIMIZED 0x0001
#define CO_NEWLOCALS 0x0002
#define CO_VARARGS 0x0004
#define CO_VARKEYWORDS 0x0008
#define CO_NESTED 0x0010
#define CO_GENERATOR 0x0020
/* The CO_NOFREE flag is set if there are no free or cell variables.
This information is redundant, but it allows a single flag test
to determine whether there is any extra work to be done when the
call frame it setup.
*/
#define CO_NOFREE 0x0040
/* The CO_COROUTINE flag is set for coroutine functions (defined with
``async def`` keywords) */
#define CO_COROUTINE 0x0080
#define CO_ITERABLE_COROUTINE 0x0100
#define CO_ASYNC_GENERATOR 0x0200函数没有参数,显然CO_VARARGS和CO_VARKEYWORDS是不存在的
print(0x0001 | 0x0002 | 0x0010) # 19
# 因此闭包是包含CO_NESTED这个域的根据之前说了,对于闭包来说,func对应的PyCodeObject中的co_freevars里面有引用了外层作用域中的符号名,在_PyEval_EvalCodeWithName中就会对这个co_freevars进行处理。
//ceval.c
PyObject *
_PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, Py_ssize_t argcount,
PyObject *const *kwnames, PyObject *const *kwargs,
Py_ssize_t kwcount, int kwstep,
PyObject *const *defs, Py_ssize_t defcount,
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
Py_ssize_t i, n;
/* Copy closure variables to free variables */
for (i = 0; i < PyTuple_GET_SIZE(co->co_freevars); ++i) {
PyObject *o = PyTuple_GET_ITEM(closure, i);
Py_INCREF(o);
freevars[PyTuple_GET_SIZE(co->co_cellvars) + i] = o;
}
...
...
...
}其中的closure变量是作为倒数第三个参数传递进来的,我们可以看看到底传递了什么
//funcobject.h
#define PyFunction_GET_CLOSURE(func) \
(((PyFunctionObject *)func) -> func_closure)
//funcobject.c
PyObject *
_PyFunction_FastCallKeywords(PyObject *func, PyObject *const *stack,
Py_ssize_t nargs, PyObject *kwnames)
{
...
...
...
closure = PyFunction_GET_CLOSURE(func);
...
...
...
return _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
stack, nargs,
nkwargs ? &PyTuple_GET_ITEM(kwnames, 0) : NULL,
stack + nargs,
nkwargs, 1,
d, (int)nd, kwdefs,
closure, name, qualname);
}我们看到了,是把PyFunctionObject对象的func_closure拿出来了,这个func_closure是啥还记得吗?之前说得,不记得了再看一下。
TARGET(MAKE_FUNCTION) {
...
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
//弹出闭包需要使用的变量信息,将该信息写入到func_closure中
func ->func_closure = POP();
}
...
}
显然这个func_closure就是PyFunctionObject对象中的、我们之前说得那个与对应PyCodeObject绑定的、装满了PyCellObject对象的PyTupleObject。所以在_PyEval_EvalCodeWithName中,进行的动作就是将这个PyTupleObject里面的PyCellObject对象一个一个的放到f_localsplus中相应的位置。在处理完之后,func对应的PyFrameObject中f_localsplus就变成了这样。
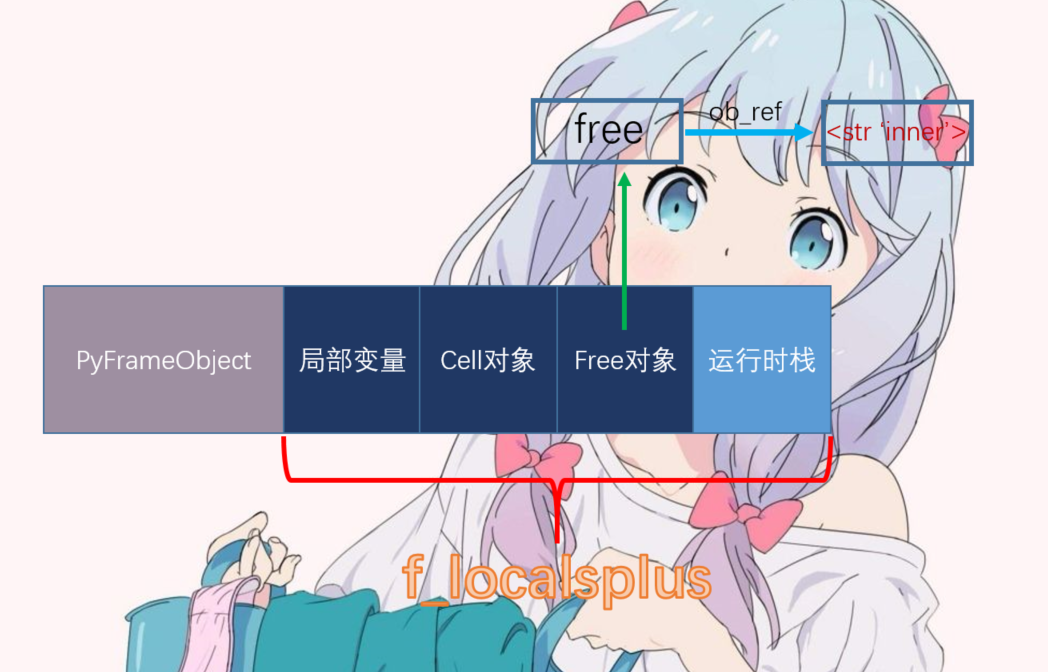
这里的动作和调用get_func时一致的,所以我们猜测,在func调用的过程中,当引用外层作用域的符号时,一定是到f_localsplus里面的free变量区域去获取对应PyCellObject,通过内部的ob_ref进而获取符号对应的值。这正是func函数中'print(value)'表达式对应的第一条字节码指令0 LOAD_DEREF 0的意义。
TARGET(LOAD_DEREF) {
//获取PyCellObject对象
PyObject *cell = freevars[oparg];
//获取PyCellObject对象的ob_ref指向的对象
PyObject *value = PyCell_GET(cell);
if (value == NULL) {
format_exc_unbound(co, oparg);
goto error;
}
Py_INCREF(value);
//压入运行时栈
PUSH(value);
DISPATCH();
}到了此刻我们就已经看完了closure从创建、传递到使用的全过程,相信对闭包已经有了一个全面的认识了。那么下面问题来了,我如何在python的层面上访问闭包呢?
def foo():
value1 = 1
value2 = 2
def bar():
nonlocal value1, value2
return bar
# 既然是闭包显然是针对内层函数的
# 通过调用__closure__可以拿到闭包
print(foo().__closure__) # (<cell at 0x000001A367075BB0: int object at 0x00007FFB012296A0>, <cell at 0x000001A36708FF10: int object at 0x00007FFB012296C0>)
# 显然和我们分析的一样,是一个PyTupleObject对象
closure = foo().__closure__
# 获取每一个内容,调用cell_contents拿到每一个PyCellObject的ob_ref域所指向的内存维护的值
for _ in range(len(closure)):
print(closure[_].cell_contents)
"""
1
2
"""12.6.3 装饰器
python基于闭包实现了装饰器,装饰器的本质就是高阶函数加上闭包。至于为什么要有装饰器,我觉得有句话说的非常好,装饰器存在的最大意义就是可以在不改动原函数的代码和调用方式的情况下,为函数增加一些新的功能。
# deco1.py
def deco(func):
print("都闪开,我要开始装饰了")
def inner(*args, **kwargs):
print("开始了")
ret = func(*args, **kwargs)
print("结束")
return ret
return inner
@deco # 这一步就等价于foo = deco(foo)
def foo(a, b):
print(a, b)
# 因此上来就会打印deco里面的print
print("---------")
# 此时再调用foo,已经不再是原来的foo了,而是deco里面的闭包inner
foo(1, 2)
"""
都闪开,我要开始装饰了
---------
开始了
1 2
结束
"""
# 根据输出的---------,我们知道deco里面的print是在装饰的时候就已经打印了我们可以使用之前的方式
def deco(func):
print("都闪开,我要开始装饰了")
def inner(*args, **kwargs):
print("开始了")
ret = func(*args, **kwargs)
print("结束")
return ret
return inner
def foo(a, b):
print(a, b)
# 其实@deco的方式就是一个语法糖,它本质上就是
foo = deco(foo)
print("-------")
foo(1, 2)
"""
都闪开,我要开始装饰了
-------
开始了
1 2
结束
"""所以这个现象告诉我们,装饰器只是对foo = deco(foo)的一层包装罢了
装饰器本质上就是使用了闭包,两者的字节码很类似,这里就不再看了。还是那句话,@只是个语法糖,它和我们直接调用foo = deco(foo)是一样的,所以理解装饰器closure的关键就在于理解闭包(closure)。
下面就和源码分析无关了,我主要是想问问,如果有多个装饰器,那么它们是怎么装饰的呢?
def deco1(func):
def inner():
return f"<deco1>{func()}</deco1>"
return inner
def deco2(func):
def inner():
return f"<deco2>{func()}</deco2>"
return inner
def deco3(func):
def inner():
return f"<deco3>{func()}</deco3>"
return inner
@deco1
@deco2
@deco3
def foo():
return "hanser"
print(foo())请问它的输出结果是什么呢?
可以先分析,解释器还是从上到下解释,但是发现了@deco1的时候,肯定要装饰了,但是发现在它下面的哥们不是函数也是一个装饰器,于是说:要不哥们,你先装饰。然后@deco2发现它下面还是一个装饰器,于是重复了刚才的话,但是当@deco3的时候,发现下面终于是一个普通的函数了。于是装饰了,当deco3装饰完毕之后,foo = deco3(foo),然后deco2发现deco3已经装饰完毕了,然后对deco3装饰的结果再进行装饰,此时foo = deco2(deco3(foo)),同理再经过deco1的装饰,得到了foo = deco1(deco2(deco3(foo)))
当执行foo()括号的时候:相当于调用deco1里面的inner,此时func就是deco2(deco3(foo))
return f"<deco1>{deco2(deco3(foo))()}</deco1>"但是里面又是一个调用,相当于执行deco2里面的inner,此时func就是deco3(foo)
# deco2(deco3(foo))() 等价如下
return f"<deco2>{deco3(foo)()}</deco2>"然后这又是一个调用,相当于执行deco3里面的inner,此时func就是foo
# deco3(foo)()等价如下
return f"<deco3>{func()}</deco3>"因此最终deco1(deco2(deco3(foo)))这一大长串就等于<deco1><deco2><deco3>func()</deco3></deco2></deco1>
print(foo()) # <deco1><deco2><deco3>hanser</deco3></deco2></deco1>输出结果也是一样的,总结一下顺序就是:
解释器从上往下解释:执行@deco1,@deco2,@deco3
装饰器从下往上装饰:deco3先装饰、再是deco2、deco1
函数从上往下执行:先执行deco1、再是deco2、deco3,以及被装饰的函数
从下往上返回:被装饰的函数先返回、再是deco3、deco2、deco1。尽管deco1最先return,但是并不代表它先返回,因为它依赖于其他函数的返回值。事实上,不用我说也知道,return语句是分为两步的,第一步是把要return的值load进来,然后执行RETURN_VALUE指令,然而还没执行到这条指令,就在load的时候跳到其他函数去执行了。
def foo():
return bar()
def bar():
return 123
foo()
"""
只看调用bar的字节码
可以看到在把bar这个符号对应的值load进来之后,直接CALL_FUNCTION了,都还没有执行RETURN_VALUE呢
所以return xxx,并不是一步的,而是分为两条指令。
2 0 LOAD_GLOBAL 0 (bar)
2 CALL_FUNCTION 0
4 RETURN_VALUE
"""以上就是python虚拟机的函数机制,就到这里啦。
