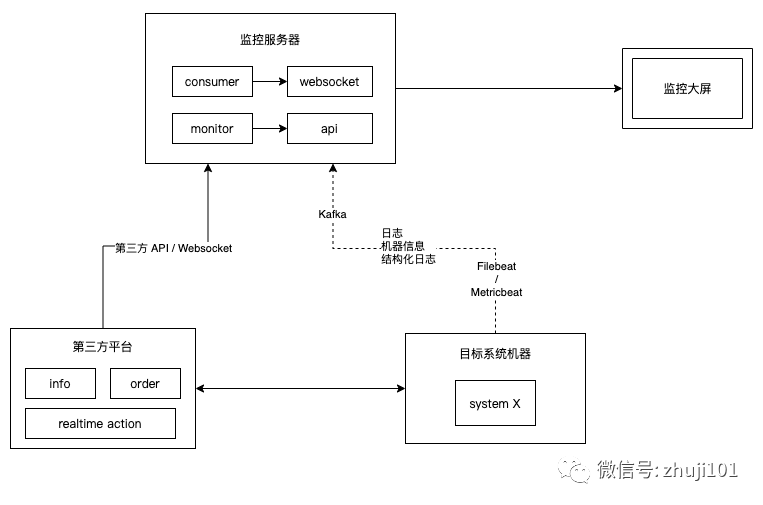
对系统的日志监控,通用做法是使用ELK(Elasticsearch、Logstash、Kibana)进行监控和搜索日志,这里给出另一种方案:通过Filebeat接收日志到Kafka,监控平台接收Kafka,并通过WebSocket实时展示。
这种方案还可以增加Metricbeat监控机器指标。另外,监控平台可以选择其他方式展示日志,灵活性大。
这种方案适合对系统进行实时监控、以及对系统CPU、内存进行实时监控的场景。
结构图:
流程图:
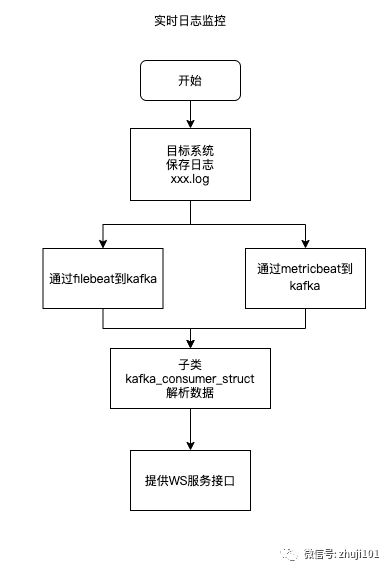
数据收集
数据收集组件包括filebeat和metricbeat,寻找一个合适的本地文件夹进行部署,无需su权限。
其中,filebeat用于日志收集和结构化数据收集,metricbeat用于系统信息收集。
filebeat安装与配置
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.2-linux-x86_64.tar.gz
tar zxf filebeat-7.16.2-linux-x86_64.tar.gz
cd filebeat-7.16.2-linux-x86_64
vi filebeat.yml(用实际日志文件名替换{FILE_PATH},如:/data/logs/systemx/abcd.log)
filebeat.inputs:
- type: filestream
enabled: true
paths:
- FILE_PATH
output.kafka:
enabled: true
hosts: ["kfk-01.example.com:9092","kfk-02.example.com:9092","kfk-03.example.com:9092"]
topic: system_x_journal启动filebeat
nohup ./filebeat -c filebeat-[STRATEGY_ID]-jnl.yml -path.data=$PWD/data_[STRATEGY_ID]_jnl/ > filebeat-[STRATEGY_ID]-jnl.log 2>&1 &
Or
nohup ./filebeat -c filebeat-[STRATEGY_ID]-stt.yml -path.data=$PWD/data-[STRATEGY_ID]-stt/ > filebeat-[STRATEGY_ID]-stt.log 2>&1 &
filebeat文档在这里:Filebeat Reference [7.16] | Elastic
metricbeat安装与配置
安装
wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-7.16.2-linux-x86_64.tar.gz
tar zxf metricbeat-7.16.2-linux-x86_64.tar.gz
cd metricbeat-7.16.2-linux-x86_64
vi metricbeat.yml配置
metricbeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
metricbeat.modules:
- module: system
metricsets: [core]
core.metrics: [percentages, ticks]
processors:
- add_host_metadata:
netinfo.enabled: true
output.kafka:
enabled: true
hosts: ["kfk-01.example.com:9092","kfk-02.example.com:9092","kfk-03.example.com:9092"]
topic: system_x_sysinfo启动
nohup ./metricbeat -c metricbeat.yml > metricbeat.log 2>&1 &对于多个系统部署在一台服务器上的情况,往往会共用一份机器信息,则将配置文件的topic改为:system_x_ID_sysinfo。
注意:
1.metricbeat默认不带IP,需要在配置文件添加add_host_metadata
2.metricbeat默认不带CPU所有内核的负载,需要扩展module: system
3.传递内容及数据格式在这里:System fields | Metricbeat Reference [8.9] | Elastic
Kafka数据查看
作为中间调试步骤,可以登录到测试服务器,查看Kafka输出
cd /usr/local/kafka/bin/
sh kafka-console-consumer.sh --bootstrap-server kfk-01.example.com:9092,kfk-02.example.com:9092,kfk-03.example.com:9092 --topic YOUR_TOPICPython(FastAPI)示例
在一个典型的Python FastAPI项目中,通过kafka consumer订阅对应策略的topic,持续消费kafka存储的日志数据,然后通过websocket服务,将日志推给连接的ws客户端。
KafkaConsumer
使用python的kafka包。
注意:安装kafka-python,不要kafka
使用 pip list | grep kafka查看是否有安装,如果已安装kafka,先卸载:
pip uninstall kafka
再安装
pip install kafka-python
FastAPI主程序示例
from web.monitors import loginfo, sysinfo
import asyncio
# 已声明 app = FastAPI()
@app.on_event("startup")
async def startup():
loop = asyncio.get_running_loop()
logging.info(loop)
journal.set_config(config, loop)
sysinfo.set_config(config)
app.mount("/loginfo", loginfo.router_loginfo)
app.mount("/sysinfo", sysinfo.router_sysinfo)
logging.info("config journal and sysinfo")附1:metricbeat机器信息返回字段
system_name:系统名称
app_cpu:系统应用占用的CPU(单位:百分比)
app_memory:系统应用占用的内存(单位:字节)
app_start_time:系统应用启动时间
app_pid:系统应用的进程ID
cpu_sys_usage:机器整体CPU系统使用(单位:百分比)
cpu_idle:机器整体CPU闲置(单位:百分比)
cpu_user_usage:机器整体CPU用户使用(单位:百分比)
cpu_cores:机器CPU内核数
cpu_cores_usage:列表,机器所有CPU核的负载(单位:百分比)
memory_usage:机器整体内存占用(单位:百分比)
memory_total:机器内存总和(单位:字节)
disk_usage:机器磁盘占用率(单位:百分比)
disk_total:机器磁盘空间总和(单位:字节)
host_name:主机名
os:主机操作系统
ip_addr:主机IP
附2:FastAPI+Websocket问题
基于解耦原则,日志的kafka消费、websocket服务模块需要放在单独的文件中,但是,通过app.include_router添加的ws路径不起作用,相关bugreport见这里。
目前的解决方案是:
在ws router服务模块中也声明app:
router_journal = FastAPI()
然后在主app文件中附加此router模块:
app.mount(router_journal)