文章目录
软件复杂性是层次化的,首先是来自 Data-Set、 Data-Relation、Algorithm 、 Procedure的困难,他们是Software Entities中必不可少的部分。
《人月神话》中对于核心的10%做了论述——“天生就没有银弹… 复杂度、一致性、可变性和 不可见性,这些在现代软件系统中无法规避。”
剩下的90%则来自于组织结构上的混乱:“(程序员)试图为这些现实建模,建立同等复杂的程序, 实际上是隐藏, 而不是解决这些杂乱无章的情况”。
那么90%的银弹又在哪里呢?
inherit(继承)是银弹吗?然而《The Java Programming Language, Second Edition》中指出:“该语言不会阻止您深入嵌套(继承)类,但良好的品味应该如此…嵌套超过两个级别会导致可读性灾难,可能永远不应该尝试嵌套。”由此可知,继承是anti-pattern;
OO就是银弹吗?但是OO的复杂度将会随规模指数级别上升,而且OO不符合代换模型,况且并非所有实体都需要唯一的身份(例如数据库中的元组等结构化实体是通过其内容而不是名称来标识的);
时刻保有Stateful的ADT是银弹吗?然而纯粹的有状态变成会让对象的语义分布在时间和空间上,导致极其难以理解和推理;
永远都使用Supply-driven(eager execution)是银弹吗?然而输入可能是无限增长的流(streams);
必须使用原子操作(simple/reentrant lock、monitor、transaction、ACID)来保持线程安全是银弹吗?然而使用dataflow execution和lazy execution我们总是能做到implict synchronization,而不用处理各种复杂的并发问题。
《Concepts, Techniques, and Models of Computer Programming》给出了这个问题的答案,那就是最小表达式原则:
当对组件进行编程时,正确的组件计算模型是产生自然程序的表达力最低的模型。
Rule of least expressiveness When programming a component, the right
computation model for the component is the least expressive model that
results in a natural program.
从Declarative Model开始
所谓Declarative,就是通过定义什么(我们想要实现的结果)而不解释如何实现(算法等,需要实现结果)来编程的。
声明式编程的主要优点是它大大简化了系统构建。声明性组件可以彼此独立地构建和调试。而系统的复杂性此时是其组件复杂性的总和。
Iterative 、Recursive 、 higher-order programming
实现Declarative的技术有Iterative 、Recursive 、 higher-order programming等等。
其中递归无需赘述,Iterative则可以通过一个schema来实现:
fun {Iterate Si}
if {IsDone Si} then Si
else Si+1 in
Si+1={Transform Si}
{Iterate Si+1}
end
end
这种方式强大之处在于可以将常规控制流和特定的用途分开。
除此之外,declarative iterative和Imperative loop(即命令式语言中的循环,如C或Java)之间有一个根本的区别。在Imperative loop中,循环计数器是一个可赋值的变量,在每次迭代中被分配不同的值。Imperative loop则截然不同:在每次迭代中,它都声明一个新变量。所有这些变量都由相同的标识符引用。根本没有破坏性的赋值(destructive assignment )。
这种差异可能会产生重大后果(那就是副作用)。
higher-order programming
学过fp的朋友都应该知道,我们一般将更高阶的抽象/procedure叫做first/higher,比如Higher kinded type、first class function等等。
higher order programming有四个基本操作:
- 过程抽象:将任何语句转换为过程值的能力。
- 通用性:将过程值作为参数传递给过程调用的能力。
- 实例化:从过程调用中返回过程值的能力。
- 嵌入:将过程值放入数据结构的能力。包括:explicit lazy evaluation 、modules(将一组操作放在一起)、Software component(接受一组modules作为参数并且返回新的modules)
借助于这些能力,我们因此能够编码declarative ADT:比如stack,dictionary等等。
控制访问
既然declarative 没有状态,那么就不能如同OO中定义private/public/protected,那它如何进行访问控制?
答案是read-only view和Capabilities,我们可以使用Wrap/Unwrap在atd传出/传入时加密/解密。比如在E语言中,就有sealer/unsealer 的概念,sealer/unsealer 通过非对称算法进行这个过程。
Capabilities的概念则指的是一种不可伪造的语言实体,它赋予其所有者执行一组给定动作的权利。
“connectivity begets connectivity”
获得新功能的唯一方法是通过现有功能显式地传递它。
Declarative Concurrency Model
Declarative Concurrency
严格来讲,Declarative Concurrency并不是 Declarative ,因为Declarative programming的基本原则是,声明式程序的输出应该是其输入的数学函数。然而,程序的输入可能是个流!比如:
fun {Double Xs}
case Xs of X|Xr then 2*X|{Double Xr} end
end
Ys={Double Xs}
这个程序就是Partial termination(部分终止)的,如果继续有XS输入,那么这个程序将能够继续计算。
那么什么是Declarative Concurrency呢?下面是一个比较形式化的定义:
如果以下内容适用于所有可能的输入,则并发程序是声明性的。具有给定输入集的所有执行都有两个结果之一:(1)它们都不终止,或(2)它们都最终部分终止,并给出逻辑等效的结果。(不同的执行可能会引入新变量;我们假设相应位置的新变量相等。)
所谓的逻辑等效,指的是:
对于每个variable x和constraint c,我们将值(x,c)定义为x可以拥有的所有可能值的集合,前提是c保持不变。然后我们定义:
两个constraint c1和c2在逻辑上等价,如果:(1)它们包含相同的变量,(2)对于每个变量x,values(x,c1)=values(x,c2)。
例如:x = foo(y w) ∧ y = z 逻辑等价于 x = foo(z w) ∧ y = z
Streams、Transducers和bounded buffer
Declarative Concurrency中并发编程最有用的技术是使用streams在线程之间通信。流是一个潜在的无限消息列表,也就是说,它是一个其尾部为无限数据流变量的列表。
通过将流扩展为一个元素来发送消息:将尾部绑定到包含消息和新的未绑定尾部的列表对。接收消息就是读取流元素。通过流进行通信的线程是一种“活动对象”,我们将其称为流对象。由于每个变量仅由一个线程绑定,因此不需要锁定或互斥。
流编程是一种非常通用的方法,可以应用于许多领域。这是Unix管道的基本概念。Morrison 在Unix中使用它取得了很好的效果,他称之为“基于流的编程”。
最简单的示例是这样的:
fun {Generate N Limit}
if N<Limit then
N|{Generate N+1 Limit}
else nil end
end
fun {Sum Xs A}
case Xs
of X|Xr then {Sum Xr A+X}
[] nil then A
end
end
local Xs S in
thread Xs={Generate 0 150000} end % Producer thread
thread S={Sum Xs 0} end % Consumer thread
{Browse S}
end
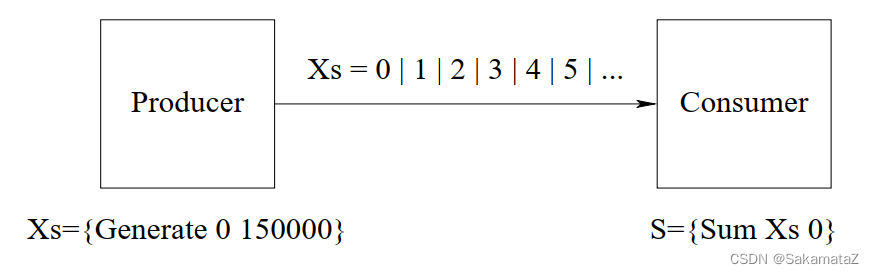
它由最简单的producer/consumer 构成。
我们可以通过Transducers 进行流的过滤,这时候两端则被称为stream-source和stream-sink。
比如:
fun {Sieve Xs}
case Xs
of nil then nil
[] X|Xr then Ys in
thread Ys={Filter Xr fun {$ Y} Y mod X \= 0 end} end
X|{Sieve Ys}
end
end
local Xs Ys in
thread Xs={Generate 2 100000} end
thread Ys={Sieve Xs} end
{Browse Ys}
end
如果想要达到lazy evaluation的效果,我们可以再加一个buffer:
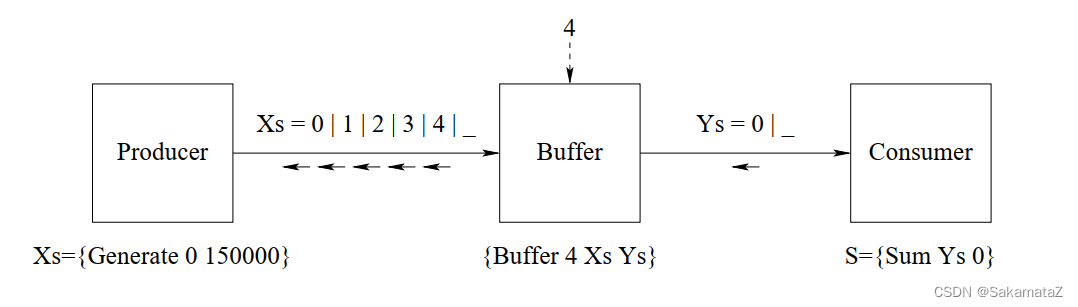
在eager execution 中,producer是完全自由的:它可以超越consumer的程度没有任何限制。在lazy execution中,producer 受到了完全的约束:如果没有consumer 的明确请求,它就不能生成任何内容。这两种技术都有问题。我们可以使用bounded buffer 来克服两者的问题,这个技术比较普遍,因此在此不表。
Demand-Driven
从lazy exection中受到启发,我们发现:
构建应用程序的最佳方法通常是围绕需求驱动的核心以数据驱动的方式构建它。
这也就是常说的demand-driven。
demand-driven可以通过称为trigger的技术实现,trigger遵循by-need protocol ,在变量被constraint时解除。
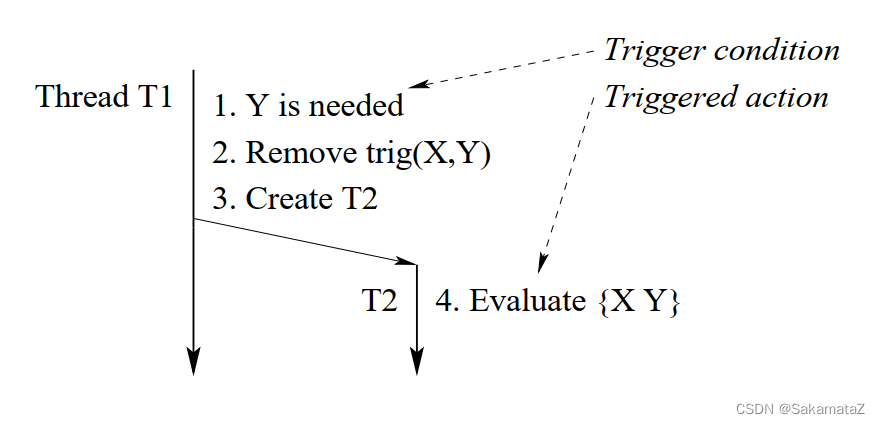
其中,变量必须具有monotonic的属性:在unbound+needed时才能被赋值,从而变成Determined+needed状态。
Declarative计算模型和其表达能力
根据eager/lazy计算和sequential/values/dataflow可以将Declarative计算模型分为六种

所谓的dataflow variables指的是还没有绑定值的变量。
其中:
- 在eager+sequential中,变量的声明、赋值和计算是一起的过程
- 在eager+sequential/concurrent+dataflow variables中,变量的声明是单独的,而赋值和计算在一起
- 在lazy+sequential/concurrent+values+dataflow variables中,声明、赋值和计算都是分开的过程
理解这些的关键在于表达能力。lazy允许使用潜在的无限列表进行声明性计算。lazy可以像显式状态一样高效地实现许多数据结构,但仍然是声明性的。dataflow variables允许编写仍然是声明性的并发程序。同时使用两者可以编写由通过潜在无限流通信的流对象组成的并发程序。
实际上,dataflow variables和lazy给模型添加一种弱形式的state。我们限制了这种state,因此可以确保模型仍然是Declarative的。
Declarative的缺点
如果程序的性能与汇编语言程序解决相同问题的性能相差一个常数,那么程序就是有效的。如果处理与手头问题无关的技术原因,只需要很少的代码,那么程序就是自然的。让我们分别考虑效率和自然问题。有三个自然性问题:模块化、不确定性和与现实世界的接口。
除非自然性的问题或者性能的问题很严重,否则Declarative model总是好的。(虽然Declarative model总不是即自然又高效的)
使用阻抗匹配
阻抗匹配,就是在有状态/无状态的模型中内嵌一个无状态/有状态模型。
例如:
•在并发模型中使用顺序组件。例如,抽象可以是接受并发请求、按顺序传递请求并正确返回响应的序列化程序。
•在有状态模型中使用声明性组件。例如,抽象可以是一个存储管理器,它将其内容传递给声明性程序,并将结果存储为其新内容。
阻抗匹配在爱立信的Erlang项目中得到了广泛应用,它采用用函数语言编写的声明性程序,并使其同时具有状态、并发和容错性。
进行同步
在declarative中,同步可以通过以下方式进行:

Message Passing Concurrency Model
NewPort和Send
streams既是声明性的,也是并发的。但它有一个局限性,即它不能处理可观测的不确定性。
我们可以通过使用asynchronous communication channel扩展模型来消除此限制。然后,任何客户端都可以向通道发送消息,服务器可以从通道读取消息。我们使用一种简单的通道,称为具有关联streams的端口。向端口发送消息会导致消息出现在端口的streams中。
扩展模型称为Message-Passing Concurrency 模型。由于这个模型是不确定性的,它不再是声明性的。客户端/服务器程序可以在不同的执行中给出不同的结果,因为客户端发送的顺序尚未确定。
此模型的一种有用的编程样式是将端口关联到每个流对象。该对象从端口读取其所有消息,并通过其端口将消息发送给其他流对象。这种风格保留了声明式模型的大部分优点。每个流对象都由一个声明性的递归过程定义。
另一种编程风格是直接使用模型,使用端口、数据流变量、线程和过程进行编程。这种风格对于构建并发抽象很有用,但不推荐用于大型程序,因为它很难推理。
通过在Declarative中增添NewPort和Send就可以实现一个Message-Passing Concurrency 。
{NewPort S P} 通过Stream S和入口P创建一个Port,{Send P X} 则将X附加到Port P对应的Stream中。
通过增加这两个原语,我们可以将map映射到每一个每一个组件,并且收集其结果。
AL={Map PL fun {$ P} Ans in {Send P query(foo Ans)} Ans end}
Concurrent Component Programming
设计并发应用程序,第一步是将其建模为一组以定义良好的方式交互的并发活动。每个并发活动都由一个并发组件建模。组件可以是Declarative的(没有内部状态)或具有内部状态。使用组件编程的科学有时被称为多代理系统,通常缩写为MAS。
模型具有基本组件和多种方法用来组合组件。基本组件用于创建端口对象。
并发组件通过接口进行通信,接口由一对输入和输出组成,它们统称为wires,wires将输入和输出连接。
组件编程有四种基本的操作:
- instantiation。用于创建组件的实例。
- composition。将其他组件组合成新的组件。
- linking。通过链接输入和输出来组合组件。
- Restriction。将组件的输入和输出可见性限制在一组组件内。
Stateful Model
Explicit State
什么是显式状态?
显式状态就是在多个procedure的生命周期中存在,但是不作为参数的状态。
通过在Declarative中增添NewCell和Exchange就可以实现一个Stateful Model。
NewCell语义在于创建一个用于存储值的单元格,而Exchange则可以改变这个单元格的存储状态。
The principle of abstraction
抽象原则是对于人类等思维能力有限的智能体来说,最成功的系统构建原则。
它将所有系统分解为两个部分:规范和实现。区别规范/实现的是,规范通常比实现更容易理解。
系统应该具有哪些属性才能最好地支持抽象原则?
- Encapsulation 封装。封装应该可以隐藏零件的内部。
- Compositionality 组合性。应该可以组合部件来制造新部件。
- Instantiation/invocation 实例化/调用。可以基于单个定义创建零件的多个实例。这些实例在创建时“插入”到它们的环境中。
这三个属性定义了基于组件的编程。
Component-based programming
封装、组合和实例化的三个属性定义了基于组件的编程。组件指定了一个具有内部和外部的程序片段,也就是接口。
组件通过三种形式存在:
- Procedural abstraction 我们已经看到声明性计算模型中的第一个组件示例。该组件称为过程定义,其实例称为过程调用。过程抽象是后来出现的更高级组件模型的基础。
- Functor(编译单元) 一种特别有用的组件是编译单元,即它可以独立于其他组件进行编译。在本书中,我们将此类组件称为Functor函子及其实例模块。
- Concurrent components 一个具有独立、交互实体的系统可以看作是一个并发组件的图形,这些组件相互发送消息。
是的,和你想的一样,
Procedural abstraction+Functor+Concurrent components=Object-based programming
而 Object-based programming + Inheritance = Object-oriented programming
ADT的类型
按照ADT的安全性(open/secure)、状态性(declarative/stateful)、是否和数据捆绑在一起可以分为八类ADT,而常用的则是以下五类:
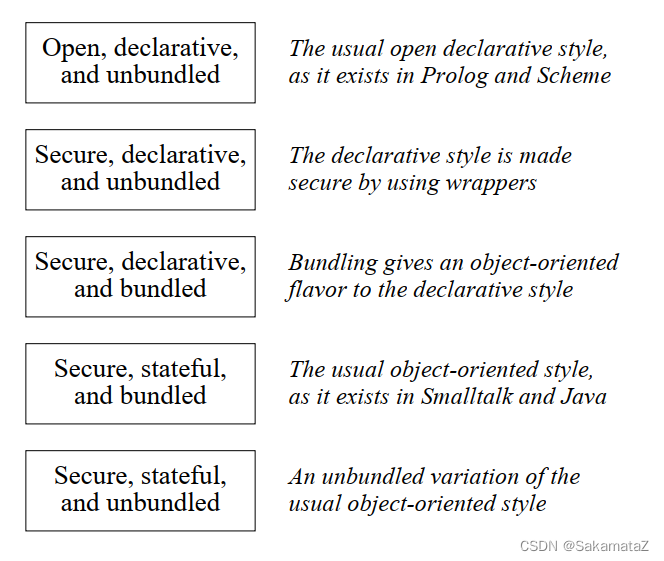
使用无状态创建的ADT不能修改其实例。
这样做的好处是当将ADT实例传递给过程时,可以确切地确定传递的是什么值。一旦创建,实例就不会更改。从而保证了透明性,有利于程序推理。另一方面,这会导致难以管理的实例激增。该程序的模块化程度也较低,因为实例必须显式传递,即使是通过可能不需要实例本身的部分。
有状态ADT在内部使用显式状态。有状态ADT的示例是组件和对象,它们通常是有状态的。使用这种方法,ADT实例可以随着时间而变化。如果不知道接口自创建以来所有过程调用的历史,就无法确定实例中封装了什么值。这使得程序更简洁。该程序也可能更模块化,因为不需要实例的部分不需要提及它。
捆绑数据的ADT则更重,操作它们将花费更多时间。
Shared-State Concurrency Model
Shared-State Concurrency
通过在Declarative Concurrency中增添NewCell和Exchange就可以实现一个
Shared-State Concurrency Model。
为什么不坚持Declarative concurrency
鉴于共享状态并发模型中编程的固有困难,一个明显的问题是为什么不坚持第4章中的声明式并发模型?它比共享状态并发模型更容易编程。推理几乎与声明式模型一样容易,声明式模型是顺序的。
让我们简单地检查一下为什么声明式并发模型如此简单。这是因为数据流变量是单调的:它们只能绑定到一个值。
一旦绑定,该值就不会更改。因此,共享数据流变量(例如流)的线程可以使用流进行计算,就像它是一个简单的值一样。
这与非单调的细胞相反:它们可以被赋予任意次数的相互无关的值。共享单元格的线程不能对其内容做出任何假设:在任何时候,内容都可能与以前的任何内容完全不同。
声明式并发模型的问题是线程必须以一种“锁步”或“收缩”方式进行通信。与第三个线程通信的两个线程不能独立执行;他们必须相互协调。这是由于模型仍然是声明性的,因此是确定性的。
我们希望允许两个线程完全独立,但与同一第三个线程通信。例如,我们希望客户机对公共服务器进行独立查询,或独立增加共享状态。为了表达这一点,我们必须离开声明性模型的领域。
这是因为与第三方通信的两个独立实体引入了可观察到的不确定性。解决此问题的一个简单方法是向模型中添加显式状态。端口和单元是添加显式状态的两种重要方式。
Concurrent programming Model
总的来说,并发模型可以分为以下四类:

值得注意的是协程,coroutining通过显式的控制权交接,因此实际上是顺序模型。
message-passing和shared-state模型在表现力上是等价的。这是因为Port可以与Cell一起实现,反之亦然。实际上两者的编程理念是完全不同的:message-passing是将程序作为相互协调的活动实体。shared-state是将程序作为被动数据存储库,以一致的方式进行修改。
如何决定并发风格?
- 坚持使用适合程序的最小并发模型 例如,如果使用并发并不能简化程序的体系结构,那么就坚持使用顺序模型。如果程序没有任何可观察到的不确定性,例如与服务器交互的独立客户机,那么就坚持使用声明性并发模型。
- 在有状态和并发时,优先使用消息传递或共享状态方法 消息传递方法通常是多代理程序的最佳方法,即由相互通信的自治实体(“代理”)组成的程序。共享状态方法通常是最适合以数据为中心的程序的,也就是说,由一个大型数据存储库(“数据库”)组成的程序可以并发地访问和更新。这两种方法可以用于同一应用程序的不同部分。
- 将程序模块化,并将并发性方面集中在尽可能少的地方 大多数时候,程序的大部分可以是顺序的,或者使用声明性并发性。也可以使用抗阻匹配做到这一点。
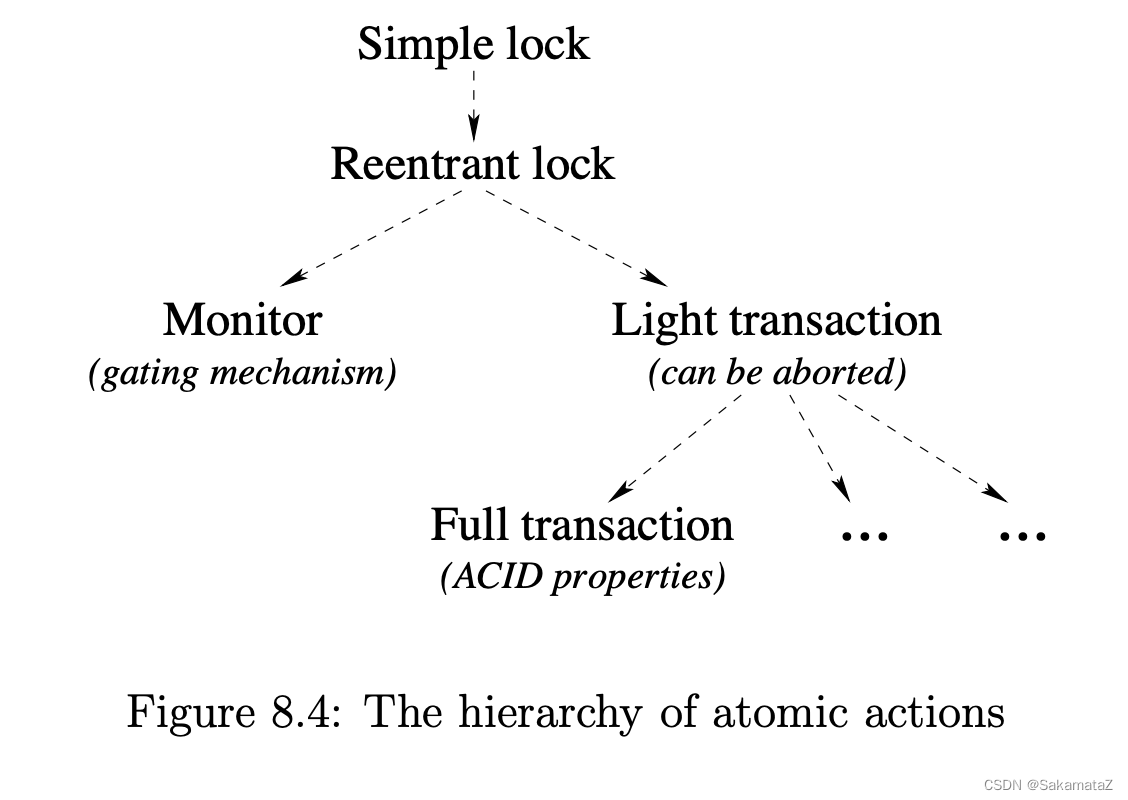
使用atomic actions
引入Shared-State Concurrency就必须使用Atomic actions
常用的Atomic actions如下所示,Atomic actions因为在OO中经常碰到,就不在此赘述了。