“ 一个基于VITS的简单易用的语音转换(变声器)框架。”
配置要求
1 win10或win11系统,老显卡驱动要更新到最新版本
2 显卡750TI以上,如需训练音源,需RTX以上显卡,显存越大越好
3 CPU支持AVX2指令集,性能越高越推理延迟越低,建议十代酷睿或三代锐龙以上
4 清晰干净的麦克风,声卡麦克风最优
界面预览
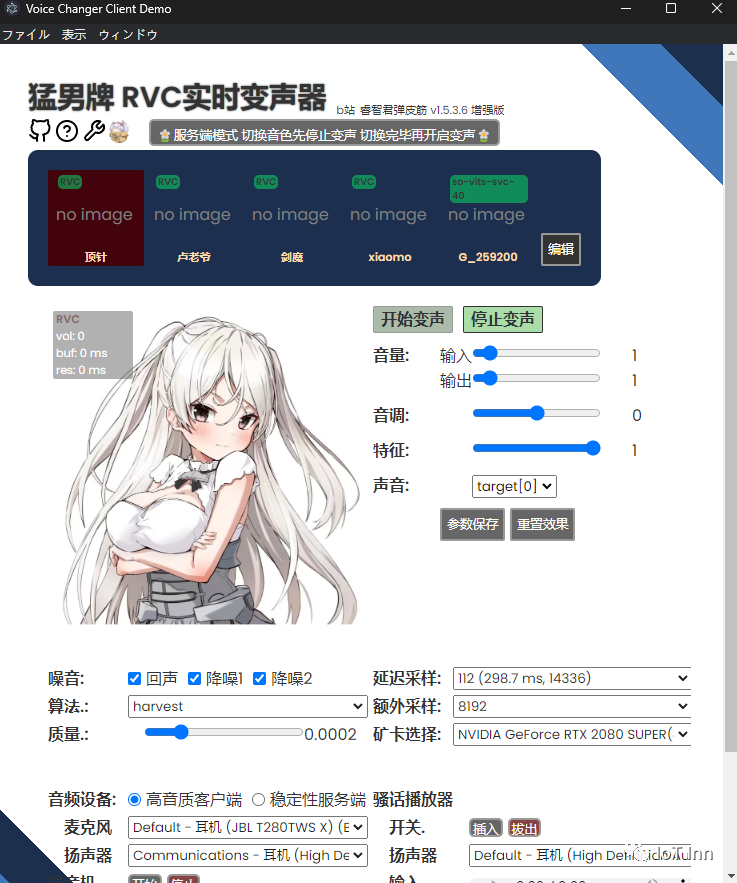
测试效果如下:
测试下来对麦克风的要求很高,我用的蓝牙耳机,导致噪音比较大,声音也不是很清晰,如果声音出现断续的情况,可以更改延迟采样的时间。
1 AI变声不吃个人声线,只需要清晰的说化即可,传统变声器只能根据个人声线进行变化
2 可以训练模型,加载各种声线,语气声线多样化
相比于传统变声器缺点
1 延迟太高,通常都是1-5秒以上,传统变声器最低可以无延迟
2 咬字不清晰,气息非常奇怪,感情波动就会失真,非常吃模型的音源
3 吃配置较高,需要CPU和GPU双重占用,配置低就无法使用,大多目前只能兼容N卡
4 兼容性还是太差了,AI变声目前还不成熟,闪退稳定性有待优化
想尝试的朋友可以点下关注,后台回复RVC获取下载链接