最近发现自己对 GNU GCC 和 Clang 的区别不太清楚,影响到一些实现和学习,所以趁这两天有空好好研究了一下。
在这个研究过程中,我发现很多问题其实源自于语言(不是指编程语言,而是中文和英文翻译的失真)和概念理解不严谨。
如果你上网去查clang,有些人会告诉你这是一个前端(frontend),然后从书上摘抄一些编译器的介绍,然后列出了一堆表格进行对比,并没有对原理和机制进行详尽的解释和介绍。所以这时候会有更多的问题冒出来:
- 为什么
clang是一个前端?难道它不是完整的编译器吗?如果clang是完整的编译器的话,那么为什么叫前端呢?如果它不是完整的,那么后端是什么呢? - 编译器的定义到底是什么?感觉书上编译器的定义和实际的
gcc有所不同。
这里说明一下:这里的gcc指的是你在 Ubuntu 等 Linux 发行版里可以直接使用的命令(来自于 GNU 软件组),如果是指项目则会写作“GNU GCC”。如果是指llvm-gcc,则不会简写成gcc。
本文将会逐步解答这一系列的问题,在这个过程中,不光会让你搞明白clang到底是什么,也会让你对编译过程、编译器和gcc,以及 LLVM 更加了解。
像gcc这种现代叫做“编译器”的程序是一个工具集合
需要先理解一件事,也算是上面绝大部分问题的答案或者误解源头:像gcc这种现代“编译器”是一个工具集合,包含了预处理器、编译器,而且会自己调用汇编器、连接器或加载器等多种工具,而不是单单的一个编译器(话说这种术语和名词的冲突也是误导的重要原因之一)。
先说出答案是为了让读者带着答案去看解释,这样能理解的更好。
编译器到底是什么(或者说编译流程是什么)
上文提到,“编译器”是一个时常表达有冲突的术语:在很多言论、博客、教科书和专业书中,编译器被描述成“将源代码转换成可执行程序的程序”(比如gcc这个“编译器”就可以直接将源代码编程可执行程序)。这句话简洁、准确地描述了使用gcc命令会发生什么,但是这并不是编译器的定义。
我们来看看最经典的编译相关的著作《编译原理》(也就是龙书)里对于编译器的介绍,这也算是编译器最经典的含义:
简单来说,编译器就是一个程序能读取某种语言的一个程序(这个语言是源语言),然后将其翻译转换成另一种语言的等价程序(这个语言被称为目标语言)。编译器最重要的一个规定就是报告在翻译过程中发现“源”程序的错误。
如果这个目标程序是机器语言,那么这个目标程序就是可执行程序。
那么回到《编译原理》中的定义,其实就是:我们写的源代码经过编译器转换之后得到了另一种语言的代码,而转换之后的代码如果是机器语言,那么这个目标代码就是可执行程序。但是如果多源代码文件或者有外连接的库,那么可能是共享对象(shared object)。
“code”在英语中是指一堆数字、字母、符号,中文翻译成“代码”或“码”
应用程序本质就是一堆机器语言拼成的二进制文件。
也就是说,编译器实际上是将一种语言转换成另一种语言的程序。
不过按照近几十年的标准编译流程来说,编译器指的是从将.c等文件转换成.s文件的程序。为了方便解释,除非特地说明,下文中的“编译器”都是按这个定义。
在这个定义下,编译器内部的工作流程大致如下:
编译器可以生成指定平台的汇编代码。然后再由汇编器来将汇编代码转成机器语言,最后由连接器连接成可执行程序。
此外有几点需要补充一下:
- 这里的各种语言代码是经过预处理过的;
- 某语言的前端一般指词汇解析器(Lexer)和语法分析程序(Parser),前端会将源代码一步一步(从高级到低级)转换成优化器需要的中间表达(IR),这是多个分析器实现的的。
- 一般在优化器前面会单独列出一个“AST(Abstract Syntax Trees)”,这是一个层级很高的中间表达,基本上就是源代码的重组。
- 优化器(Optimizer)有时也被称为中端(Middle end),优化器不仅提升性能,而且作为中端可以让前后端分离的更好,增加了交叉编译的可能性。
从源代码到高级中间表达,再从中级到低级的流程大致如下:
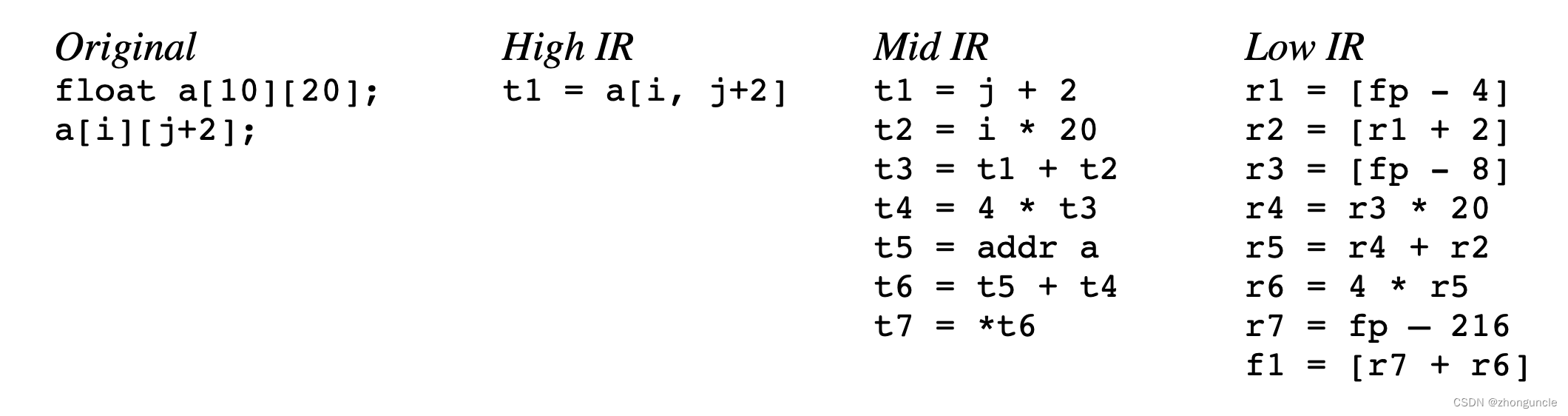
这里有篇文章做了更详细的介绍:《Intermediate Representation》
从源代码转换成可执行程序的过程
从源代码转换成可执行程序的完整过程,也就是我们平时所说的“编译过程”。在过去的几十年里,这个标准流程大致如下(圆角矩形表示代码,矩形表示各种处理器):
可以看到从源代码到可执行程序要经过预处理器(preprocessor)、编译器(compiler)、汇编器(assembler)和连接器(linker)或加载器(loader),而编译器只是负责将源代码转换成对应的汇编代码的功能。
过程展示:gcc和配套的cpp、as、ld处理转换程序
上文提到的的几种处理转换程序除了编译器和汇编器,其他三个估计都很很少听到。下面就用最经典的 C 语言和gcc来介绍这个过程,gcc包含的预处理器为cpp,还会调用汇编器as、连接器ld。
关于三者的介绍,以及编译过程中,每一步时如何进行的详细过程,可以看看我的另一篇文章《使用gcc展示完整的编译过程》,这篇文章也通过实际操作,介绍了一些gcc操作方法。这篇文章非常建议读到这里就看一看,不然可能只理解字面的内容,文章内容原本是打算放在这里的,但是会让字数到 2 万字,这样阅读时间太长了。
gcc内部工作流程
gcc内部工作流程如下,这里忽略了预处理过程:
Clang内部的工作流程
随着时代的发展和进步,老式的编译流程以及不够用了:
- 性能优化需要的人力、物力过大(现在的汇编语言要比以前的复杂太多了,经典的 PDP-11 手册里关于指令的只有 30 页不到,但是现在 Intel X86 指令手册就 2500 页);
- 针对每种机器的开发消耗多(比如说在 ARM 和 X86 编译同一个程序);
- 编译器的“插件”不够(有时候需要新的优化或者处理)。
看到这里你便明白,这里的前端是指整个 C 语言家族的编译流程的前端,而不是一个编译器的前端。所以 clang 是一个完整的编译器,可以将.c转换成.s文件,但是可以调用汇编器和编译器生成最终的可执行文件。
clang 作为编译器可以将你写的 C 家族的语言转换成 LLVM IR(一种低级语言),然后转换输出一个.s文件,然后调用 LLVM 项目中的汇编器(或者其他汇编器)将其汇编成一个.o对象文件(也就是前文中提到的“汇编阶段”),最后调用连接器进行连接,输出一个可执行程序。
也就是之前描述的编译器内部流程变成如下流程,同样这里的省略了预处理过程:
而clang后面使用的的汇编器和连接器,既可以使用 LLVM 集成,也可以使用 GNU 的,比如连接器可以使用 LLVM 集成的的lld,也可以使用 GNU 的ld或gold,以及 MSVC的link.exe。不过默认情况下是使用 LLVM 集成的。
如果你好奇更详细 Clang 工作流程,和每一步的操作,比如说什么选项对应的是编译过程的某一步,可以看看这篇文档《An Overview of Clang》,我就不单独写博客了。
这种编译方式对于适配不同平台来说非常方便。当出现一个新的平台,只要将指令与 LLVM IR 对应即可,完全不用开发者去写一个全新的优化器和代码生成器去将源代码转换成汇编代码,省时省力。
为什么clang是一个前端?难道它不是完整的编译器吗?如果clang是完整的编译器的话,那么为什么叫前端呢?如果它不是完整的,那么后端是什么呢?
Clang 是一个完整的编译器,也是一个前端。不过是将源代码转换成可执行程序流程的前端,而不是编译器的前端。如果说是编译器的前端,那是预处理器、词义分析器(Lexer)和语法分析器(Parser)等部分构成的。
和clang对应的后端指的是 LLVM 内含的,或者 GNU 等软件组的连接器、编译器等工具,这些工具负责将汇编代码汇编、连接成最后的可执行文件。
编译器的定义到底是什么?感觉书上编译器的定义和实际的gcc有所不同
关于编译器的定义前文有详细的解释,现在一般情况下“编译器”指的是从将.c等文件转换成.s文件的程序。
实际上编译器,比如gcc包含了一些工具(比如预处理器),也会去调用其他的工具(汇编器和连接器),所以与定义有所不同。
LLVM 项目是干什么项目?
前文提到,很多编译器是需要多个中间表达(IR)的,这些中间表达可能是词汇分析器生成的,也可能是语义分析器生成的,就很不统一,这就导致更新指令和优化性能随着数量的大幅提升成为了一件很困难的事情。
LLVM 全名“Low-Level Virtual Machine”,是一架构和中间表达的实现。而 LLVM 项目最初是一套围绕着 LLVM 代码的工具,C 语言和对应的 LLVM 代码如下(源自Chris Lattner 的《Architecture for a Next-Generation GCC》):

LLVM 代码有三种用途:
- 编译器的中间表达;
- 存放在硬盘里的位码(bitcode);
- 人类可读的汇编语言表达
这三种用途实际上都是等价的,要么能共用,要么有工具可以很轻松的转换,这点就让 LLVM 兼容新的机器、优化性能、开发新的语言,甚至是反汇编都是很容易的。
整个项目最核心内容其实就是 LLVM IR。LLVM IR 旨在成为某种“通用IR”,希望足够低级,可以将高级代码干净地映射到 LLVM IR(类似于处理器使用的指令是“通用IR”,允许将许多种不同的语言映射到这些汇编语言)。这给使用 LLVM IR 的编译器带来了性能很不错提升。
关于 LLVM 设计更详细的介绍还是请看文档:《LLVM Language Reference Manual》。
关于 LLVM 带来的性能提升可以看 Intel 的这篇文章:《Intel® C/C++ Compilers Complete Adoption of LLVM》
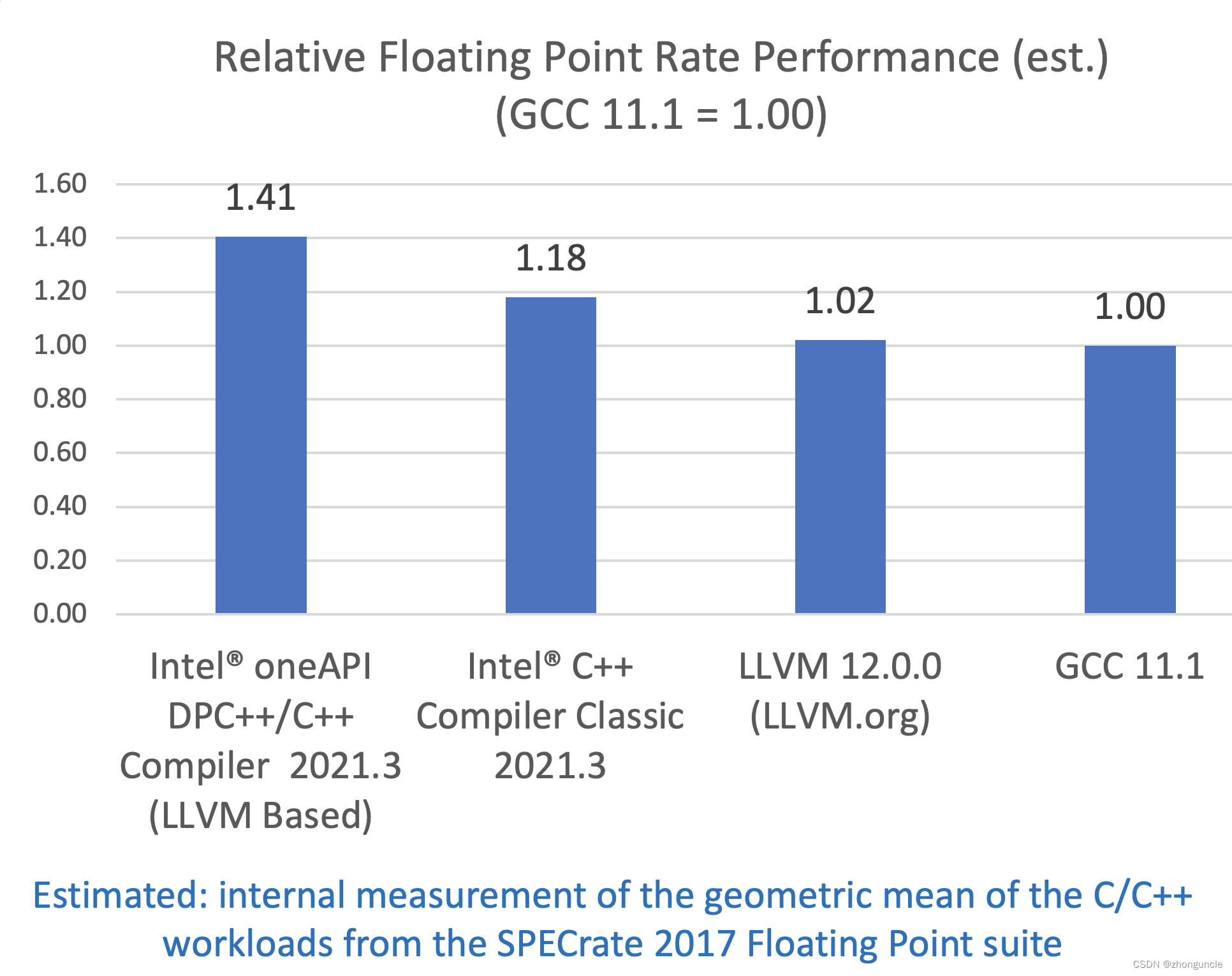
gcc和clang有什么区别?
LLVM 早期有一个名为llvm-gcc的项目,它和 GNU GCC 的最大区别就在于:llvm-gcc在编译器最后使用的是 LLVM 作为最低一级的中间表达,而不是 GNU GCC 使用的的 RTL 作为最低一级的中间表达,所以llvm-gcc编译器的最后一部分是处理 LLVM IR,而不是处理 RTL(Register Transfer Language)。
其他方面,llvm-gcc和gcc一样将会输出一个汇编文件,工作原理也一样。不过可以通过使用-emit-llvm选项来让llvm-gcc输出 LLVM 字节码。
后来 LLVM 创始人 Chris Lattner 在苹果的时候就开创了一个中间表达全部使用 LLVM 作为中间表达的 C 语言家族的编译器,也就是 Clang。
虽然clang淘汰了llvm-gcc,虽然现在还是有llvm-gcc,但是使用率和性能都不如clang。也正是因为 LLVM IR,Clang进行反汇编也很方便。
下面是 Chris Lattner 简历中提到 Clang 诞生的部分(https://www.nondot.org/sabre/Resume.html#Apple):

这里字太小了,机翻一下:

总结一下,gcc和clang的区别在于:clang的各个中间层均为 LLVM IR,而gcc的各个中间层为 TRL 或其他一些事物。
这里需要注意一点,llvm-gcc和 LLVM 创始人 Chris Lattner 在《Architecture for a Next-Generation GCC》中描述的 LLVM 编译器不是一个东西。这个 LLVM 编译器与后来的 Clang 也不是一个东西。论文中对 LLVM 编译器的示意图如下:
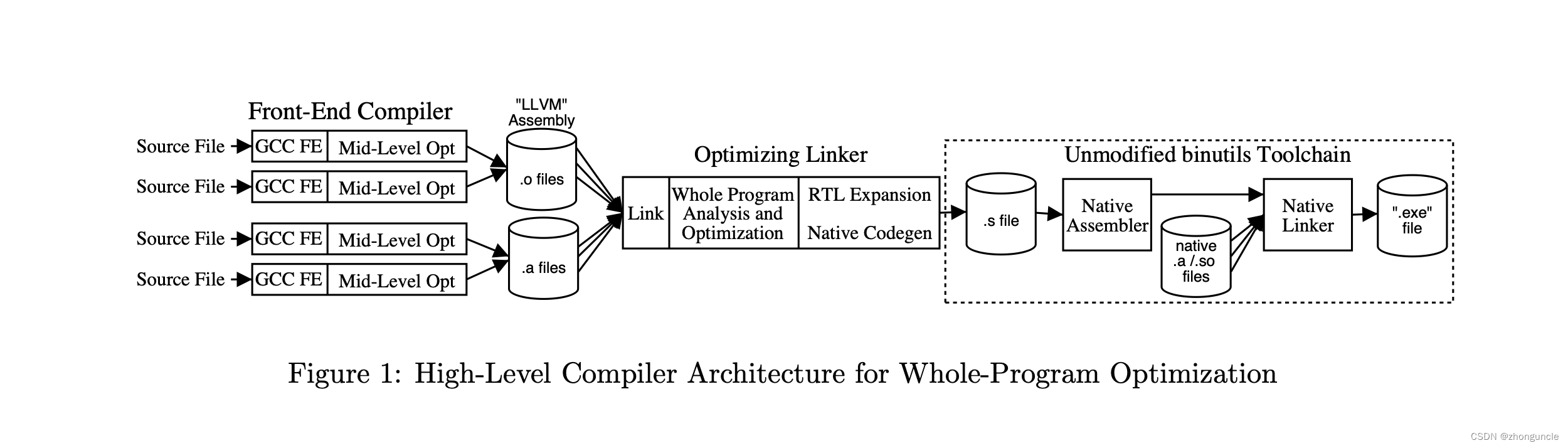
区别在于中间加了一个连接层,整个编译器中进行了两次连接。不过很明显,根据 Intel 的数据来看, LLVM 编译器的性能和效果相比 GNU GCC 差不多。不过现在你还是可以在 GitHub 上下到它,目前最新版本为 16:https://github.com/llvm/llvm-project/releases/tag/llvmorg-16.0.0
你可以选择和clang一起下载:
也可以单独下载:

写本博客的过程中,我自己对于gcc和clang编译器的使用和理解也有了更深刻的理解。不过由于本文太长了,所以难免出现披露,如果你在阅读过程中发现错误(错误、笔误、忘删掉的一些东西等等),还请评论告知我一下~
希望能帮到有需要的人~