目录
拓展:程序在没有编译完成被加载到内存的时候,程序内部有地址吗?
地址空间的划分及验证
我们之前写代码时,经常会定义一些变量,包括静态变量,全局变量,普通变量,或者自己申请空间的变量等等,这些变量在内存中也会有自己相应的位置,这张图我相信大家或多或少见过.

这张图无论见过还是没有,都一定要牢牢记住各区在地址空间中的位置.
注意堆区中的变量地址上向上生长的,而栈区是向下生长.
我们写如下代码代码验证这张图.
1 #include<stdio.h>
2 #include<stdlib.h>
3 //定义未初始化全局数据
4 int g_unInitVal;
5 //定义初始化全局数据
6 int g_InitVal=0;
7 int main()
8 {
9 printf("text:%p\n",main);
10 printf("init:%p\n",&g_InitVal);
11 printf("Uninit:%p\n",&g_unInitVal);
12
13 //定义堆区数据
14 char* p1 = (char*)malloc(sizeof(char));
15 char* p2 = (char*)malloc(sizeof(char));
16 char* p3 = (char*)malloc(sizeof(char));
17
18 printf("heap1:%p\n",p1);
19 printf("heap2:%p\n",p2);
20 printf("heap3:%p\n",p3);
21
22 //定义栈区数据
23 int a = 1,b = 2,c = 3;
24
25 printf("stack:%p\n",&a);
26 printf("stack:%p\n",&b);
27 printf("stack:%p\n",&c);
28
29 return 0;
30 }
我们退出vim,make编译,然后运行:

也可以看到堆区heap和栈区stack之间相差了很大一部分地址,这部分空间叫做共享空间,这个后面部分会讲解.
同时说明一下:以上结论只在Linux下有效,但是大部分进程地址空间都是以linux为主的.
所谓的地址空间是内存吗?
那么有个问题:上面画的那段空间是内存吗?
按我们的认知是,我们每当运行程序起来,各种变量或者代码都会被暂时保存到内存这些划分的区域中,方便后面使用.
但答案是那张图不是真正意义的内存!
那它究竟是什么呢,地址空间这方面很抽象,这个本文后面会说。单独讲解一个方面会扯出很多相关的知识,所以我们先是搭好架子,然后再逐步引入讲解.
我们观察下面这种现象:
一种奇怪的现象(虚拟地址的引入)
我们知道,父进程fork()创建一个子进程,子进程会共享父进程的全局变量,所以它们的地址也是一样的.

我们make编译一下:

发现两个全局变量的地址,确实是一样的.
我们如果此时对代码稍加改动,在子进程中,将g_val值修改为20,然后再次观察父子进程的值.
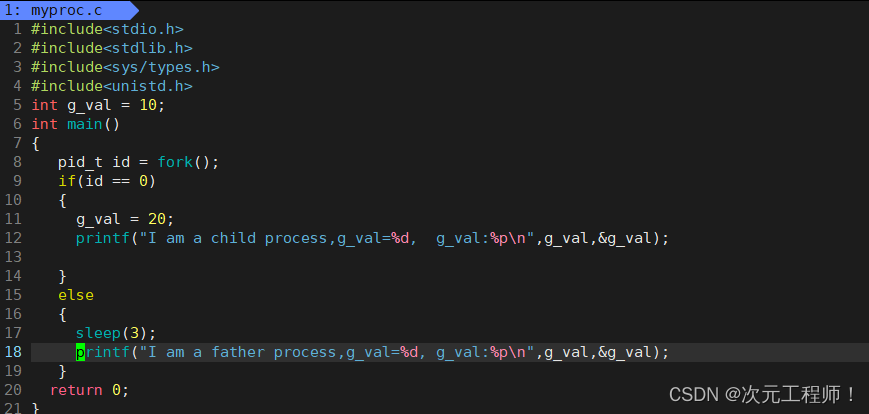
我们退出,然后make编译一下:

此时很奇怪的现象便发生了,父子进程全局变量g_val的值竟然不一样.
但很怪的是它们的地址却是相同的。同一个地址,同时读取的时候,却出现了不同的值,这怎么可能呢?
但我们可以从中得出一个重要结论:
这里这些变量的地址,绝对不是物理内存的地址.因为如果是物理地址,那么同一个时刻读取时,变量值绝对不可能不一样.一定是相同的.
这个其实是叫做虚拟地址(线性地址).
而且还需要说的是,几乎所有的语言,如果它有"地址"的概念,那么这个地址一定不是物理地址,而是虚拟地址.
那么虚拟地址是什么呢?该怎么理解呢?为什么要这么设计呢?和物理地址又有什么关系呢?等等相关的问题.我会以尽量多的例子来帮助大家理解.
什么是进程地址空间?
这个以例子辅助理解:
有一个美国大富翁,拥有10亿美金,然后它有3个私生子,分别为a,b,c.
有一天,他把a叫到自己面前说:"你好好学习,到时候如果有所成就,我这10个亿美金就会全部给你",a一听可高兴的不行,就更加努力学习,努力搞科研成果
同样地,第二天,又把b叫到自己面前,说:"你是一个商人,将来如果能把自己的事业做大,我这10亿美金以后就是你的了",b一听,这还了得,立马充满动力和干劲的去干自己的事业去了.
第三天,对c也是同样地话语.
到这里,每个儿子都认为自己会拥有这10亿美金,但是这些钱现在并没有到他们手中,而且他们也不知道彼此的存在,然后都更加的拼命努力了.相当于富翁给每个儿子都花了一张大饼.
此时呢,儿子a为了得到10亿美金,然后拼命地学习,但是需要点钱买更多的书和资源,于是某一天,就去和富翁说:"爸,能先给我100美金吗,我需要买点资源",富翁一听,可以毕竟是用在正事上。于是给了,b和c也同样如此.
但即使这样,每个人依然认为自己有10个亿
我们站在上帝视角,肯定知道三个儿子不能得到这个10个亿,三个儿子每次也只是零星的想富翁要,这些富翁是完全给的起的,而且只要富翁只要一直给,这些儿子心里也一定认为老爹有这10个亿,就算某一天某个儿子要的很多,比如一个亿,老爹说没这么多,给不了,即申请空间失败,这些儿子也会认为老爹有这么10个亿,只是现在还不愿意给我.
你理解了这个意思,这个时候便在理解地址空间:
这里的他们的富翁老爹对应操作系统. 他的这些儿子(a,b,c)便是3个进程,而老爹给这几个儿子画的这10个亿的饼,便是进程地址空间.
这个现实中的饼,即这个富翁真正拥有的钱财便是物理内存,他给每个儿子画的这些饼不只一个,很多个儿子会有很多个,所以这些饼到时候也需要管理起来,如何管理?先描述,再组织!
内核中的地址空间,本质将来也是一种数据结构,将来也要和一个特定的进程联系起来.
怎么去理解呢?后面会说.
我们平常访问到的内存是物理内存吗?
我们要知道:物理内存本身是可以随时被读写的,不存在不可读,不可写这些等等的情况.
如果直接访问物理内存,会发生什么问题呢?
比如进程1由于操作不当,产生了野指针,指向了进程2的地址,此时在进程1中对那个野指针做修改就会直接修改了进程2的数据或代码.
再或者,进程3里有一些私密的密码数据,我们在进程1中直接指针指向这块空间,然后直接访问,就得到了密码数据,这是万万不可的.
所以,直接访问物理内存存在一个致命问题:特别不安全!而且也会导致一些内存碎片问题.
所以我们的计算机不可能直接采用这种直接让用户访问物理地址的的方式的.
所以,为了解决这种问题,现代计算机提出了这种方式:
我们知道每个进程启动,都会被OS创建一个task_struct结构体用来标识这个进程的所有属性信息,然后OS也会为每个进程创建一个进程地址空间,这个地址空间被叫做虚拟地址,然后系统也会存在一种映射机制(页表),这个暂且不谈,然后把虚拟内存经过映射机制映射到物理内存.

task_struct结构体里面会有一个属性来指向这块虚拟地址空间.
可是如果虚拟地址中也是一个非法地址呢,经过映射,到了物理地址中还是非法,这不没什么用啊,还多套了一层,费这个麻烦做什么呢?
其实,当进程尝试访问一个违法的地址,例如访问未映射的内存区域或者非法的访问权限,MMU会检测到这个错误,并触发一个异常或中断,这个异常或中断称为缺页异常,后面会讲解.
就比如过年你得到了500零花钱,直接访问这500块固然很爽,但当时还小,万一被别人骗怎么办,此时我们妈妈一般会收走我们的零花钱。然后说当你需要的时候我再给你,然后你说你想买一本书看,你妈妈说嗯可以,于是便给了你,于是过了一会,你说我想买个玩具,你妈妈说买什么玩具,把钱花在正确的地方!QAQ.
这里面,这个妈妈便扮演了一个管理的角色,具有甄别是非的能力.来辨别你的需求是否是合法的,同样如果遇到了非法的虚拟地址,这个虚拟地址中的MMU就会禁止你访问.
这点就相当于变相保护了物理内存!
深入理解区域划分
那我们如何理解区域划分呢?
区域划分,本质是一在一个范围处定义start和end.用来标识起止和结束.
比如小学的时候,可能两个人闹别扭,画所谓的“三八线”.

这里需要强调的是:每个进程都要有进程地址空间!
地址空间是一种内核数据结构,它里面至少要有各个区域的划分.

我们把每一块区域都抽象成了数据结构.
每个区域大小并不是固定的.例如堆向上生长,实则是大小在变化.
所谓的范围变化,本质就是对start或者end 的标记 +/- 特定的范围即可.
在Linux下,我们把进程虚拟地址空间这个结构体抽象成 的结构叫做mm_struct.
我们直接看Linux源代码,找到task_struct,从里面找到mm_struct,因为每个进程都会有一个进程地址空间,所以它一定作为一个属性存放在task_struct里面.
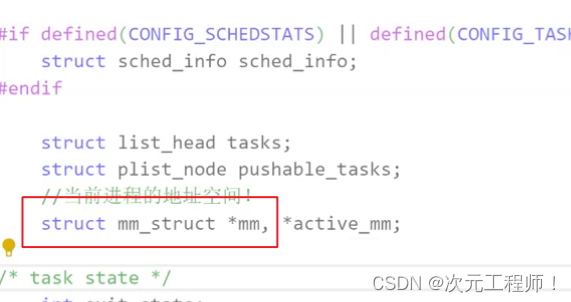
看看里面究竟有什么东西

看到了吗,这就是区域划分,用unsigned int来表示各个范围数据类型的.start 和 end来标识范围.
所以最终一个进程访问物理内存过程是如下图:
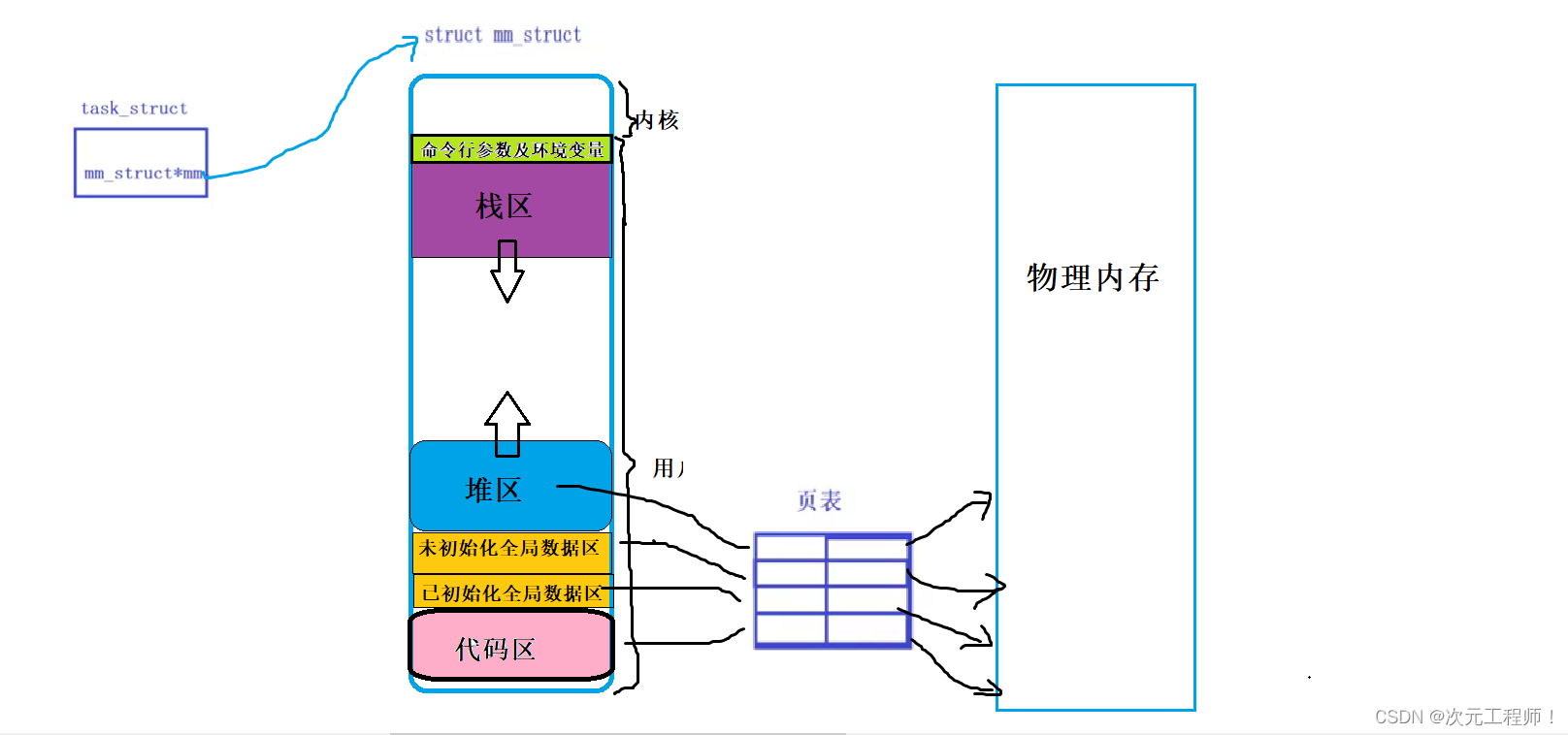
地址空间和页表(用户级)是每个进程都会有一份.
那么多个进程呢,万一映射到物理内存上位置有冲突呢?
只要保证,每一个进程的页表,映射的是物理内存的不同区域,就能做到进程之间不会相互干扰,保证进程的独立性!
再谈奇怪的现象
现在回过头来,看一开始父子进程同时访问全局变量g_val造成值不同的原因:
这里有一张图来解释.

一开始子进程没有修改g_val时,父进程和子进程都是先经过虚拟地址空间,再通过页表,同时访问到物理内存中父进程的g_val
当子进程要修改g_val时,此时子进程通过自己的进程地址空间,再经过页表映射的时候,此时会重新在物理空间开辟一份空间,然后保存子进程修改后的数据,然后后面再映射的时候,就映射到新开辟的这块空间上了.这个操作,就叫做写时拷贝.
fork()中为什么一个变量可以同时保存两个不同的值
同时也可以回答上一章遗留的问题:一个变量怎么会同时保存两个不同的值.
我们知道fork()之所以有两个返回值,是被return了两次.
而return的本质就是对id进行写入.
此时写入便发生了写时拷贝,所以父子进程其实在物理内存中,有属于自己的变量空间,只不过在用户层用同一个变量(虚拟地址)标识了!

拓展:程序在没有编译完成被加载到内存的时候,程序内部有地址吗?
先来说答案:已经有地址了,可执行程序编译的时候,内部就已经有地址了.
地址空间不要仅仅理解为是OS内部需要遵守的,编译器也要遵守!即编译器编译代码的时候,就已经给我们形成了 各个区域 , 代码区,数据区..等等,并且,采用和Linux内核中一样的方式,给每一个变量,每一行代码都进行了编址。故,在程序编译的时候,每一个字段早已经具有了一个虚拟地址!
我们画张图可以理解.
首先在磁盘中,我们编写的代码,编写的时候,就已经有了对应的虚拟地址,例如第一行代码是0x1,第二行是0x10,第三行时0x100.但是为了执行的逻辑,第一行代码中得保存第二行的虚拟地址,第二行代码中也得保存第三行的虚拟地址。如下:
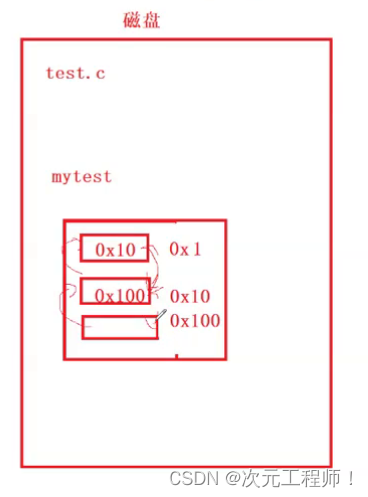
然后当程序运行起来时,会加载到物理内存中,此时每一行代码中都有下一行代码的虚拟地址,而每一行代码本身在物理地址中,也有一个地址.例如分别为0xA,0xAA,0xAAA.

那么此时,进程通过虚拟地址,再访问页表就能找到对应的物理地址然后访问了.
但问题是:地址空间和页表一开始的数据是哪里来的呢?
编译完成后,编译器会将这些代码的地址自动填充到虚拟地址空间中,而且这些代码地址都是编译器给你的.这些虚拟地址会被填充到了页表左侧,当加载到内存的时候,每个代码又有自己的物理地址,此时便把物理地址填充到页表的右侧.这样每个进程便可以通过进程地址空间中的虚拟地址,通过映射关系,在物理地址上找到对应的代码并执行了.
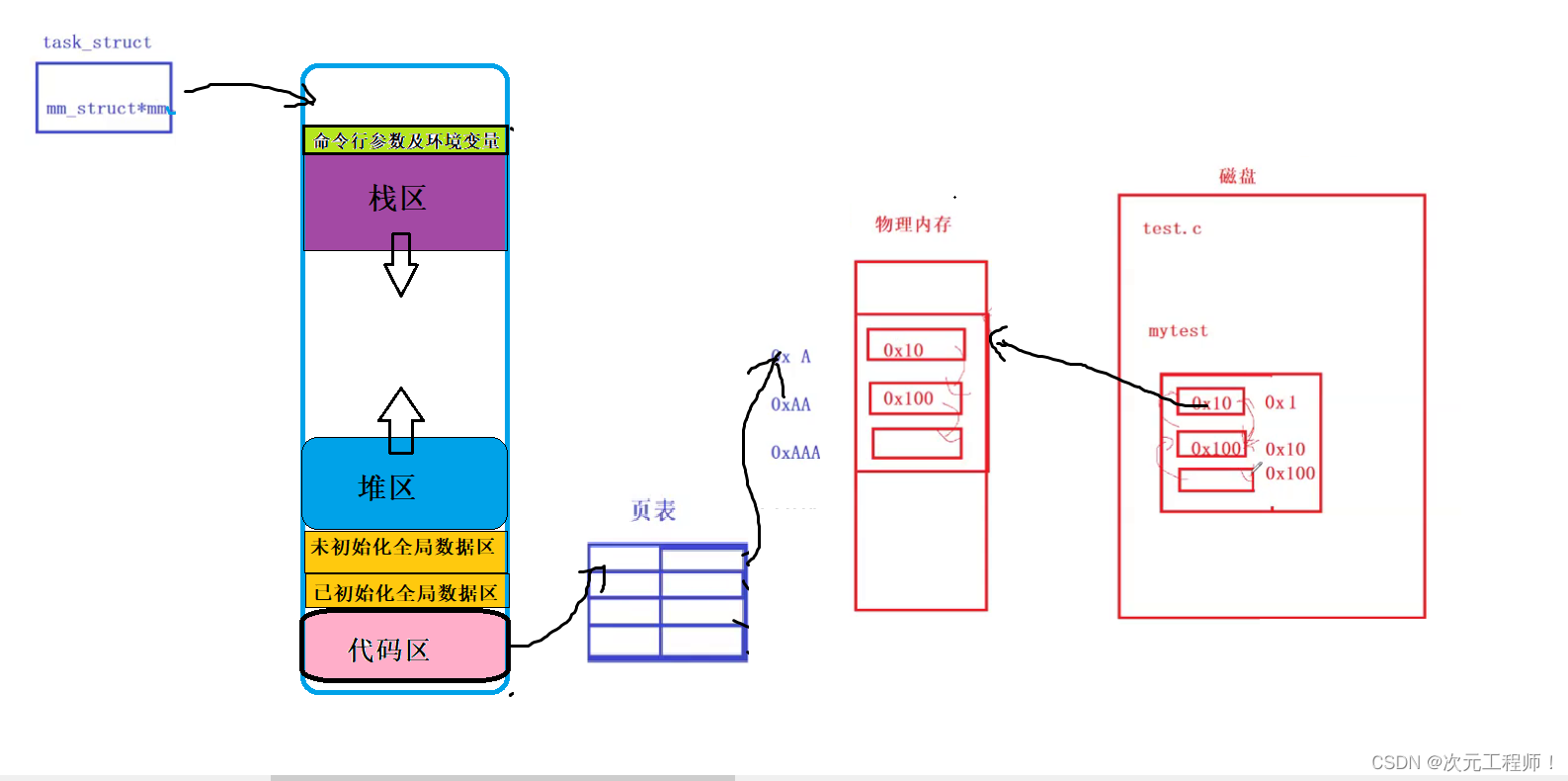
这个时候CPU开始执行了.CPU有第一条指令,拿到了0x1,所以根据地址空间中代码区,经过页表映射,在物理内存找到了0x1这条指令,然后再读到CPU,此时CPU读到的指令的内部是虚拟地址0x10!CPU执行完0x1指令后,再根据0x10经过虚拟地址空间,再经过页表又找到了0x10这条指令并且读回到CPU,重复这样,CPU便可以执行完所有指令了.、

这便是全部过程了.
关于进程地址空间讲解就到这里结束了,它的本质其实就是一段虚拟的空间!
再经过页表映射到物理地址上.
如果有任何疑问或不懂的地方,欢迎评论区或私信哦~