调度策略
传统 Unix 操作系统的调度必须实现几个冲突的目标:进程响应时间尽可能快,后台作业的吞吐量尽可能高,尽可能避免进程的饥饿现象,低优先级和高优先级的进程需要尽可能调和等等。
调度策略:决定什么时候以怎样的方式为一个新进程选择运行的规则。
Linux 的调度基于分时技术。
调度策略也根据进程的优先级对它们进行分类。Linux 中,进程的优先级是动态的。
进程分类方式一:
- I/O 受限。频繁使用 I/O 设备,并花费很多时间等待 I/O 操作的完成。
- CPU 受限。需要大量 CPU 时间的数值计算应用程序。
进程分类方式二:
- 交互式进程。如命令 shell,文本编辑程序及图形应用程序。
- 批处理进程。如程序设计语言的编译程序。
- 实时进程。如视频和音频应用程序、机器人控制程序及从物理传感器收集数据的程序。
一个批处理进程可能是 I/O 受限的(如数据库服务器),或 CPU 受限的(如图像绘制程序)。
Linux 中,调度程序可确认实时程序,通过基于进程过去行为的启发式算法(平均睡眠时间)区分交互式程序和批处理程序。
进程的抢占
如果进程进入 TASK_RUNNING 状态,内核检查到它的动态优先级大于当前正在运行进程的优先级,current 的执行被中断,调度程序选择另一个进程运行(通常为刚刚变为可运行的进程)。
进程当前的时间片到期也可以被抢占。此时,当前进程 thread_info 结构中的 TIF_NEED_RESCHED 标志被设置,以便时钟中断处理程序终止时调度程序被调用。
被抢占的进程没有被挂起,因为还处于 TASK_RUNNING 状态,只不过不再使用 CPU。

一个时间片必须持续多长?
如果平均时间片太短,进程切换引起的系统额外开销就变得非常高。
如果平均时间片太长,进程看起来就不再是并发执行,也会降低系统的响应能力。
Linux 单凭经验的方法,即选择尽可能长、同时能保持良好响应时机的一个时间片。
调度算法
Linux 2.6 的调度算法特点:
- 在固定的时间内(与可运行的进程数量无关)选中要运行的进程。
- 很好地处理了与处理器数量的比例关系,因为每隔 CPU 都拥有自己的可运行进程队列。
- 可区分交互式进程和批处理进程。
swapper 进程的 PID 为 0,只有在没有其他进程执行时运行。
每个 Linux 进程总是按照如下调度类型被调度:
- SHED_FIFO,先进先出的实时进程。
- SCHED_RR,时间片轮转的实时进程。
- SCHED_NORMAL,普通的分时进程。
普通进程和实时进程的调度算法区别很大。
普通进程的调度
每个普通进程都有静态优先级:100(最高)~ 139(最低)。
新进程继承父进程的静态优先级,但可通过将某些“nice 值”传递给 nice() 和 setpriority() 改变。
基本时间片

动态优先级和平均睡眠时间
动态优先级 = max(100, min( 静态优先级 - bonus + 5, 139))
bonus 的值与进程的平均睡眠时间相关。范围 0~10,小于 5 表示降低动态优先级以示惩罚,大于 5 表示增加动态优先级以示奖赏。
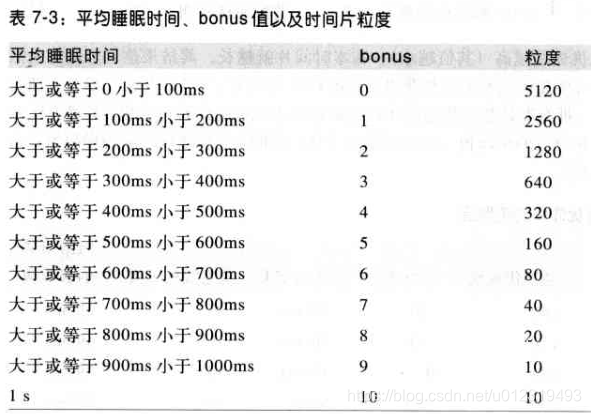
粗略地将,平均睡眠时间是进程在睡眠状态所消耗的平均纳秒数,不会大于 1s。
平均睡眠时间也被调度程序用来判断一个给定进程是交互进程还是批处理进程。如果一个进程满足下式,则被看作交互式进程:

活动和过期进程
当一个较高优先级的进程用完其时间片,应该被还没有用完时间片的低优先级进程取代,为此,调度程序维持两个不相交的可运行进程的集合。
活动进程:还没有用完时间片的进程,允许运行。
过期进程:用完了时间片,被禁止运行,直到所有活动进程过期。
总体方案要稍复杂一些:
- 用完时间片的活动批处理进程总是变成过期进程。
- 用完时间片的交互式进程仍是活动进程:调度重新重填其时间片并把它流中活动进程集合中。
- 当最老的过期进程等待了很久,或过期进程比交互式进程的静态优先级高,调度程序把用完时间片的交互式进程移到过期进程集合。
实时进程的调度
每个实时进程都有实时优先级,范围 1(最高)~ 99(最低)。用户可通过 sched_setparam() 和 sched_setscheduler() 改变进程的实时优先级。
调度程序总是让优先级高的进程运行。实时进程总是被当成活动进程。
只有如下事情发生,实时进程才会被另一个进程取代:
- 进程被另外一个具有更高优先级的实时进程抢占。
- 进程执行了阻塞操作并进入睡眠(处于 TASK_INTERRUPTIBLE 或 TASK_UNINTERRUPTIBLE 状态)。
- 进程停止(处于 TASK_STOPPED 或 TASK_TRACED 状态)或被杀死(处于 EXIT_ZOMBIE 或 EXIT_DEAD 状态)。
- 进程通过调用 sched_yield() 自愿放弃 CPU。
- 进程是基于时间片轮转的实时进程(SCHED_RR),且用完了时间片。
调度程序所使用的数据结构
进程链表链接所有的进程描述符。
运行队列链表链接所有的可运行进程(处于 TASK_RUNNING 状态的进程)的进程描述符,swapper 进程(idle 进程)除外。
数据结构 runqueue
runqueue 结构存放在 runqueues 每 CPU 变量中。宏 this_rq() 产生本地 CPU 运行队列的地址,宏 cpu_rq(n) 产生索引为 n 的 CPU 运行队列的地址。
runqueue:
- spinlock_t lock
- unsigned long nr_running
- unsigned long cpu_load
- unsigned long nr_switches
- unsigned long nr_uninterruptible
- unsigned long expired_timestamp
- unsigned long long timestamp_last_tick
- task_t * curr
- task_t * idle
- struct mm_struct * prev_mm
- prio_array_t * active 对应于包含活动进程的可运行进程的集合
- prio_array_t * expired 对应于包含过期进程的可运行进程的集合
- prio_array_t[2] arrays 每个元素表示一个可运行进程的集合
- int best_expired_prio
- atomic_t nr_iowait
- struct sd sched_domain*
- int active_balance
- int push_cpu
- task_t * migration_thread
- struct list_head migration_queue
arrays 中两个数据结构的作用会发生周期性的变化:活动进程突然变成过期进程,过期进程变为活动进程。调度程序简单地交换运行队列的 active 和 expired 字段的内容完成这种变化。
进程描述符
每个进程描述符都包含几个与调度相关的字段。
如:
- unsigned int timeslice 在进程的时间片中还剩余的时钟节拍数
- unsigend int first_time_slice 如果进程肯定不会用完其时间片,就把该标志设置为 1
- unsigned long long timestamp 进程最近插入运行队列的时间,或涉及本进程的最近一次进程切换的时间
新进程被创建时,cop_process() 调用 sched_fork() 用下述方法设置 current 父进程和 p 子进程的 time_slice 字段:
p->time_slice = (current->time_slice + 1) >> 1;
current->time_slice >> = 1;
将父进程剩余的节拍数被划分成两等份:一份给自己,另一份给子进程。避免因为创建过多子进程而占用太多时间片。
如果父进程的时间片只剩下一个时钟节拍,则 current->time_slice 置为 0。copy_process() 把 current-time_slice 重新置为 1,然后调用 scheduler_tick() 递减该字段。
copy_process() 也初始化子进程描述符中与进程调度相关的字段:
p->first_time_slice = 1; // 因为子进程没有用完它的时间片,所以设置为 1
p->timestamp = sched_clock(); // 返回被转换成纳秒的 64 位仅存去 TSC 的内容
调度程序所使用的函数
- scheduler_tick() 维持当前最新的 time_slice 计数器
- try_to_wake_up() 唤醒睡眠进程
- recalc_task_prio() 更新进程的动态优先级
- schedule() 选择要被执行的新进程
- load_balance() 维持多处理器系统中运行队列的平衡
scheduler_tick()
维持当前最新的 time_slice 计数器。
- 将转换为纳秒的 TSC 值存入本地运行队列的 timestamp_last_tick 字段。TSC 值从 sched_clock() 获得。
- 如果进程是本地 CPU 的 swapper 进程,执行下列步骤:
a. 如果本地运行队列还包括另外一个可运行的进程,就设置当前进程的 TIF_NEED_RESCHED 字段,强制重新调度。
b. 跳到第 7 步(没必要更新 swapper 进程的时间片计数器)。 - 如果 current->array 没有指向本地运行队列的活动链表,说明进程已经过期但还没有被替换,则设置 TIF_NEED_RESCHED 标志,强制重新调度,跳到第 7 步。
- 获得 this_rq()->lock 自旋锁。
- 递减当前进程的时间片计数器,如果已经用完时间片,则根据进程的调度类型进行相应操作,稍后讨论 。
- 释放 this_rq()->lock 自旋锁。
- 调用 reabalance_tick(),保证不同 CPU 的运行队列的可运行进程数量基本相同。
更新实时进程的时间片
对于先进先出的实时进程,scheduler_tick() 什么也不做,因为 current 不可能被其他低优先级或等优先级的进程抢占,维持最新时间片计数器没有意义。
对于基于时间片轮转的实时进程,scheduler_tick() 递减其时间片计数器,如果时间片被用完,执行一系列操作以达到抢占当前进程的目的:
if(current->policy == SCHED_RR && !--current->time_slice){
current->time_slice = task_timeslice(current); // task_timeslice() 根据进程的静态优先级返回相应的基本时间片
current->first_time_slice = 0; // 该标志被 fork() 中的 copy_process() 设置,并在进程的第一个时间片刚一用完立即清 0
set_tsk_need_resched(current); // 设置进程的 TIF_NEED_RESCHED 标志,强制调用 schedule() 函数,使 current 被另一个具有相同或更高优先级的实时进程取代
list_del(¤t->run_list); // 基于时间片轮转:先把进程从运行队列的活动链表中删除
list_add_tail(¤t->run_list, this_rq()->active->queue+current->prio); // 然后把进程重新插入到同一个活动链表的尾部
}
更新普通进程的时间片
scheduler_tick() 执行如下操作:
- 递减时间片计数器(current->time_slice)。
- 如果时间片用完,执行下列操作:
a. dequeue_task() 从可运行进程的 this_rq()->active 集合中删除 current。
b. set_tsk_need_resched() 设置 TIF_NEED_RESCHED 标志。
c. 更新 current 的动态优先级:
current->prio = effective_prio(current);
effective_prio() 读 current 的 static_prio 和 sleep_avg 字段,计算进程的动态优先级。
d. 重填进程的时间片:
current->time_slice = task_timeslice(current);
current->first_time_slice = 0;
e. 如果本地运行队列的数据结构的 expired_timestamp 字段等于 0(过期进程集合为空),把当前时钟节拍的值赋给 expired_timestamp:
if(!this_rq()->expired_timestamp)
this_rq()->expired_timestamp = jiffies;
f. 把当前进程插入活动进程集合或过期进程集合:
// 如果进程是一个非交互式进程,TASK_INTERACTIVE 宏产生值 0
// EXPIRED_STARVING 宏检查到运行队列中的第一个过期进程的等待时间已经超过 1000 个时钟节拍乘以运行队列中的可运行进程数加1,产生值 1
// 如果当前进程的静态优先级大于一个过期进程的静态优先级,EXPIRED_STARVING 宏也产生值 1
if(!TASK_INTERACTIVE(current) || EXPIRED_STARVING(this_rq()){
enqueue_task(current, this_rq()->expired); // 插入过期进程集合
if(current->static_prio < this_rq()->best_expired_prio)
this_rq()->best_expired_prio = current->static_prio;
}
else
enqueue_task(current, this_rq()->active); // 插入活动进程集合
- 否则,时间片没有用完(current->time_slice 不等于 0),检查当前进程的剩余时间片是否太长:
// bonus = TIMESLICE_GRANULARIT 宏产生的 CPU 的数量 * 比例常量 的乘积
// 具有高静态优先级的交互式进程,其时间片被分成大小为 TIMESLICE_GRANULARITY 的几个片段,以使这些进程不会独占 CPU
if(TASK_INTERACTIVE(p) && !((task_timeslice(p) - p->time_slice) % TIMESLICE_GRANULARIT(p)) &&
(p->time_slice >= TIMESLICE_GRANULARITY(p)) && (p->array == rq->active)) {
list_del(¤t->run_list);
list_add_tail(¤t->run_list, this_rq()->active->queue+current->prio);
set_tsk_need_resched(p);
}
try_to_wake_up()
通过将进程状态设置为 TASK_RUNNING,并把该进程插入本地 CPU 的运行队列来唤醒睡眠或停止的进程。
参数:
- 被唤醒进程的进程描述符(p)
- 可被唤醒的进程状态掩码(state)
- 标志(sync),禁止被唤醒的进程抢占本地 CPU 上正在运行的进程
执行下列操作:
- task_rq_lock() 禁用本地中断,获得最后执行进程的 CPU 所拥有的运行队列 rq 的锁。CPU 的逻辑号存储在 p->thread_info->cpu 字段。
- 如果进程的状态 p->state 不属于参数 state(状态掩码),跳到第 9 步,终止函数。
- 如果 p->array != NULL,那么进程已经属于某个运行队列,跳到第 8 步。
- 多处理器系统中,检查要被唤醒的进程是否应该迁移到另一个 CPU 的运行队列,根据以下启发式规则选择一个目标运行队列:
a. 空闲 CPU 的运行队列。
b. 先前工作量较小的 CPU 运行队列。
c. 如果进程最近被执行过,选择老的运行队列 。
d. 工作量较小的本地 CPU 运行队列。 - 如果进程处于 TASK_UNINTERRUPTIBLE 状态,递减目标运行队列的 nr_uninterruptible 字段,p->activeted = -1。
- 调用 activate_task(),执行下列步骤:
a. sched_clock() 获得以纳秒为单位的当前时间戳。如果目标 CPU 不是本地 CPU,补偿本地时钟中断的偏差:
now = (sched_clock() - this_rq()->timestamp_last_tick) + rq->timestamp_last_tick;
b. recalc_task_prio(),参数为进程描述符指针、now
c. 根据情况设置 p->activated 字段。
d. p->timestamp = now;
e. 把进程描述符插入活动进程集合:
enqueue_task(p, rq->active);
rq->nr_running++; - 如果目标 CPU 不是本地 CPU,或没有设置 sync 标志,如果 p->prio < rq->curr->prio,调用 resched_task() 抢占 rq->curr。
单处理器系统中,resched_task() 仅执行 set_tsk_need_resched() 设置 rq->curr 的 TIF_NEED_RESCHED 标志;
多处理器系统中,如果发现 TIF_NEED_RESCHED 的旧值为 0、目标 CPU 与本地 CPU 不同、rq->curr 进程的 TIF_POLLING_NRFLAG 的标志清 0,调用 smp_send_reschedule() 产生 IPI,强制目标 CPU 重新调度。 - p->state = TASK_RUNNING;
- task_rq_unlock() 打开 rq 运行队列的锁并打开本地中断。
- 成功唤醒进程返回 1,否则返回 0。
recalc_task_prio()
更新进程的平均睡眠时间 p->sleep_avg 和动态优先级 p->prio。
参数:
- 进程描述符的指针 p
- 由 sched_clock() 计算出的当前时间戳 now
执行下述操作:
- sleep_time = min(now - p->timestamp, 10^9);
p->timestamp:进程进入睡眠状态时的时间。
sleep_time:进程从最后一次执行开始,消耗在睡眠状态的纳秒数 - if(sleep_time <= 0) 不需要更新进程的平均睡眠时间,跳到第 8 步。
- 如果进程是内核线程、从 TASK_UNINTERRUPTIBLE 状态被唤醒(前一节第 5 步)、连续睡眠的时间超过睡眠极限,则 p->sleep_avg = 900 时钟节拍的值,然后跳到第 8 步。
- CURRENT_BONUS 宏计算进程原来的平均睡眠时间的 bonus 值,if(10 - bonus > 0) sleep_time *= bonus。因为第 6 步会将 sleep_time 加到进程的平均睡眠时间上,所以当前平均睡眠时间越短,它增加的就越快。
- 如果进程处于 TASK_UNINTERRUPTIBLE 状态但不是内核线程,执行下述步骤:
a. if(p->sleep_avg > 睡眠时间极限)sleep_time = 0; 不用调整平均睡眠时间,跳到第 6 步。
b. if(sleep_time + p->sleep_avg >= 睡眠时间极限) p->sleep_avg = 睡眠时间极限; sleep_time = 0;
通过对进程平均睡眠时间的轻微限制,函数不会对睡眠时间长的批处理进程给予过多奖赏。 - p->sleep_avg += sleep_time;
- if(p->sleep_avg > 1000 个以纳秒为单位的时钟节拍) p->sleep_avg = 1000 个时钟节拍。
- 更新进程的动态优先级:p->prio = effective_prio§;
schedule()
实现调度程序。从运行队列链表中找到一个进程,并随后将 CPU 分配给这个进程。schedule() 可由几个内核控制路径调用,可采取直接调用或延迟调用的方式。
直接调用
如果 current 进程未获得必需的资源而阻塞,就直接调用调度程序。要阻塞的内核路径执行下述步骤:
- 把 current 进程插入适当的等待队列。
- 把 current 进程的状态改为 TASK_INTERRUPTIBLE 或 TASK_UNINTERRUPTIBLE。
- schedule();
- 如果资源不可用,跳到第 2 步;否则,从等待队列中删除 current 进程。
延迟调用
也可以把 current 进程的 TIF_NEED_RESCHED 标志置为 1,而以延迟方式调用调度程序。每次在恢复用户进程的执行之前会检查该标志。
延迟调用调度程序的例子:
- current 进程用完时间片,由 scheduler_tick() 完成 schedule() 的延迟调用。
- 被唤醒进程的优先级高于当前进程,try_to_wake_up() 完成 schedule() 的延迟调用。
- 发出系统调用 sched_setscheduler() 时。
进程切换前 schedule() 所执行的操作
next 变量指向被选中的进程,以取代 current 进程。
如果系统中没有优先级高于 current 进程的可运行进程,那么 next 与 current 相等,不发生进程切换。
禁用内核抢占,初始化一些局部变量:
need_resched:
preempt_disable();
prev = current;
rq = this_rq(); // 把与本地 CPU 对应的运行队列赋 rq
保证 prev 不占用大内核锁:
if(prev->lock_depth >= 0)
up(&kernel_sem);
调用 sched_clock() 获取 TSC,将其值转换为纳秒,存放在 now 中。然后计算 prev 所用的 CPU 时间片长度:
now = sched_clock();
run_time = now - prev->timestamp;
if(run_time > 1000000000)
run_time = 1000000000; // 限制在 1s
优待有较长平均睡眠时间的进程:
run_time /= (CURRENT_BONUS(pre) ? : 1); // CURRENT_BONUS 返回 0~10 之间的值,它与进程的平均睡眠时间成正比
寻找可运行进程前,必须关掉本地中断,并获得所要保护的运行队列的自旋锁:
spin_lock_irq(&rq->lock);
prev 可能是一个正在被终止的进程,通过检查 PF_EDAD 标志验证:
if(prev->flags & PF_DEAD)
prev->state = EXIT_DEAD;
接下来检查 prev 的状态。
如果不是可运行状态,且没有在内核态被抢占,就从运行队列删除 prev 进程。
但是,如果它有非阻塞挂起信号,且状态为 TASK_INTERRUPTIBLE,将该进程的状态设置为 TASK_RUNNING,并插入运行队列,给 prev 一次被选中执行的机会:
if(prev->state != TASK_RUNNING && !(preempt_count() & PREEMPT_ACTIVE))
{
if(prev->state == TASK_INTERRUPTIBLE && signal_pending(prev))
prev->state = TASK_RUNNING;
else
{
if(prev->state == TASK_UNINTERRUPTIBLE)
rq->nr_uninterruptible++;
deactivate_task(prev, rq);
}
}
deactivate_task() 从运行队列中删除该进程:
rq->nr_running--;
dequeue_task(p, p->array);
p->array = NULL;
现在,检查运行队列中剩余的可运行进程数。
如果有可运行的进程,就调用 dependent_sleeper(),绝大多数情况下,该函数立即返回 0。
但是,如果内核支持超线程技术,如果被选中执行的进程优先级比已经在相同物理 CPU 的某个逻辑 CPU 上运行的兄弟进程低,则拒绝选择该进程,而执行 swapper 进程:
if(rq->nr_running)
{
if(dependent_sleeper(smp_processor_id(), rq))
{
next = rq->idle;
goto switch_tasks;
}
}
如果运行队列中没有可运行的进程,则调用 idle_balance() 从另外一个运行队列迁移一些可运行进程过来。
如果没有迁移成功,当内核支持超线程技术时,wake_sleeping_dependent() 重新调度空闲 CPU 的可运行进程。
然而,在单处理器系统中,迁移失败时,将 swapper 进程作为 next 进程。
if(!rq->nr_running)
{
idle_balance(smp_processor_id(), rq);
if(!rq->nr_running)
{
next = rq->idle;
rq->expired_timestamp = 0;
wake_sleeping_dependent(smp_processor_id(), rq);
if(!rq->nr_running)
goto switch_tasks;
}
}
假设运行队列中有可运行进程,现在检查这些可运行进程中是否至少有一个进程是活动的。如果没有,则交换运行队列结构的 active 和 expired 字段。
array = rq->active;
if(!array->nr_active)
{
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = 140;
}
现在可在活动 prio_array_t 中搜索一个可运行的进程了。
首先搜索进程集合掩码的第一个非 0 位,其下标对应包含最佳运行进程的链表。
随后,返回该链表的第一个进程描述符:
idx = sched_find_first_bit(array->bitmap); // 基于 bsfl 汇编指令,返回 32 位数组中被设置为 1 的最低位的位下标
next = list_entry(array->queue[idx].next, task_t, run_list); // 存放将取代 prev 的进程描述符指针
检查 next->activated 字段,表示进程被唤醒时的状态。
如果 next 是一个普通进程,正在从 TASK_INTERRUPTIBLE 或 TASK_STOPPED 状态被唤醒,调度程序就把自从进程插入运行队列开始所经过的纳秒数加到进程的平均睡眠时间中。
if(next->prio >= 100 && next->activated > 0)
{
unsigned long long delta = now - next->timestamp;
if(next->activated == 1)
delta = (delta * 38) / 128;
array = next->array;
dequeue_task(next, array);
recalc_task_prio(next, next->timestamp + delta);
enqueue_task(next, array);
}
next->activated = 0;
总结:禁止内核抢占,更新 prev 的运行时间,根据 prev 的状态进行相应处理,对运行队列处理以使获得 next,更新 next 的平均睡眠时间。
schedule() 进行进程切换时所执行的操作
next 进程已运行,内核将立刻访问 next 进程的 thread_info,其地址存放在 next 进程描述符接近顶部的位置。
switch_tasks:
prefetch(next); // 提示 CPU 把 next 进程的描述符第一部分字段装入硬件高速缓存
在替代 prev 前,调度程序应该完成一些管理的工作:
clear_tsk_need_resched(prev); // 清除 prev 的 TIF_NEED_RESCHED 标志
rcu_qsctr_inc(prev->thread_info->cpu); // CPU 正在经历静止状态
减少 prev 的平均睡眠时间,并把它补充给进程所使用的 CPU 时间片,随后更新进程的时间戳:
prev->sleep_avg -= run_time;
if((long)prev->sleep_avg <= 0)
prev->sleep_avg = 0;
prev->timestamp = prev->last_ran = now;
prev 和 next 可能是同一个进程,这时函数不作进程切换:
if(prev == next)
{
spin_unlock_irq(&rq->lock);
goto finish_schedule;
}
否则,进程切换:
next->timestamp = now;
rq->nr_switches++;
rq->curr = next;
prev = context_switch(rq, prev, next); // context_switch() 建立 next 的地址空间
进程描述符的 active_mm 字段指向进程所使用的内存描述符,而 mm 字段指向进程所拥有的内存描述符。
对于一般进程,这两个字段地址相同;
而内核线程没有自己的地址空间,mm 总是被置为 NULL。
context_switch() 确保,如果 next 是一个内核线程,使用 prev 所使用的地址空间:
if(!next->mm) // 内核线程
{
next->active_mm = prev->active_mm;
atomic_inc(&prev->active_mm->mm_count);
enter_lazy_tlb(prev->active_mm, next);
}
如果内核线程都有自己的地址空间,当调度程序选择一个新进程运行时,需改变页表,因为内核线程仅使用线性地址空间的第 4 个 GB,该空间的映射对系统的所有进程都是相同的。
甚至在最坏情况下,写 cr3 寄存器会使所有 TLB 表项无效,导致极大的性能损失。
现在的 Linux 中,如果 next 是内核线程,就不触及页表,进一步优化,将进程设置为懒惰 TLB 模式。
而如果 next 是一个普通进程,context_switch() 用 next 的地址空间替换 prev 的地址空间:
if(next->mm) // 普通进程
switch_mm(prev->active_mm, next->mm, next);
如果 prev 是内核线程或正在退出的进程,context_switch() 把 prev 内存描述符的指针保存到运行队列的 prev_mm 字段中:
if(!prev->mm)
{
rq->prev_mm = prev->active_mm;
prev->active_mm = NULL;
}
现在,context_switch() 可调用 switch_to() 执行 prev 和 next 之间的进程切换了:
switch_to(prev, next, prev);
return prev;
总结:更新 prev 的时间片、时间戳,根据 prev 是内核线程还是普通线程,进行相应的内存描述符替换。
进程切换后 schedule() 所执行的动作
switch_to 宏后紧接着的指令不是让 next 进程立即执行,而是如果稍后调度程序又选择 prev 时则执行 prev。
到那时,prev 不指向 schedule() 开始时所替换出的进程,而是指向被调度时被 prev 替换出的进程。
进程切换后的第一部分指令:
barrier(); // 代码优化屏障
finish_task_switch(prev);
finish_task_switch():
mm = this_rq()->prev_mm; // 如果 prev 是一个内核线程,运行队列的 prev_mm 存放 prev 的内存描述符地址
this_rq()->prev_mm = NULL;
prev_task_flags = prev->flags;
spin_unlock_irq(&this_rq()->lock); // 释放运行队列的自旋锁
if(mm) // prev 是内核线程
mmdrop(mm); // 减少内存描述符使用计数,如果等于 0,是否与页表相关的所有描述符和虚拟存储区
if(prev_task_flags & PF_DEAD) // 如果 prev 是一个正在从系统中被删除的僵死进程
put_task_struct(prev); // 释放进程描述符的引用计数,并撤销所有启用对该进程的引用
schedule() 的最后一部分指令:
finish_schedule:
prev = current;
if(prev->lock_depth >= 0)
__reacquire_kernel_lock(); // 重新获得大内核锁
preempt_enable_no_resched(); // 重新启用内核抢占
if(test_bit(TIF_NEED_RESCHED, ¤t_thread_info()->flags) // 如果设置了当前进程的 TIF_NEED_RESCHED 标志
goto need_resched; // schedule() 重新开始执行
return;
多处理器系统中运行队列的平衡
3 中不同类型的多处理机器:
- 标准的多处理器体系结构
- 超线程
- NUMA
内核应周期性地检查运行队列的工作量是否平衡,需要时,把一些进程从一个运行队列迁移到另一个运行队列。
为适应各种已有的多处理器体系结构,Linux 提出一种基于“调度域”概念的复杂的运行队列平衡算法。
调度域
调度域实际上是一个 CPU 集合,它们的工作量由内核保持平衡。
调度域采取分层组织的形式:最上层的调度域包括多个子调度域,每个子调度域包括一个 CPU 子集。
每个调度域被划分为一个或多个组,工作量的平衡在调度域的组之间完成。
每个调度域由 sched_domain 描述符表示,调度域中的每个组由 sched_group 描述符表示。
sched_domain 的 groups 字段指向组描述符链表中的第一个元素。
sched_domain 的 parent 字段指向父调度域的描述符。
物理 CPU 的 sched_domain 描述符存放在每 CPU 变量 phys_domains 中。
如果内核不支持超线程技术,这些域在域层次结构的最底层,运行队列描述符的 sd 字段指向它们。
如果内核支持超线程技术,底层调度域存放在每 CPU 变量 cpu_domains 中。
rebalance_tick()
保持系统中运行队列的平衡,每经过一次时钟节拍,被 scheduler_tick() 调用。
参数:
- 本地 CPU 的下标 this_cpu
- 本地运行队列的地址 this_rq
- 标志 idle
首先,访问运行队列描述符的 nr_running 和 cpu_load 字段,确定运行队列中的进程数,更新运行队列的平均工作量。
然后,从基本域到最上层的调度域循环,每次循环确定是否已到调用 load_balance() 的时间,从而在调度域上指向重新平衡的操作。
sched_domain 的 idle 值决定调用 load_balance() 的频率。
如果 idle 等于 SCHED_IDLE,那么运行队列为空,load_balance() 被调用频率高。
反之,如果 idle 等于 NOT_IDLE,load_balance() 被调用频率低。
load_balance()
检查调度域是否处于严重的不平衡状态,如果是,从最繁忙的的组中迁移一些进程到本地 CPU 的运行队列。
参数:
- this_cpu,本地 CPU 的下标
- this_rq,本地运行队列的描述符的地址
- sd,指向被检查的调度域的描述符
- idle,取值为 SCHED_IDLE 或 NOT_IDLE
- 获取 this_rq->lock 自旋锁。
- find_busiest_group() 分析调度域中各组的工作量。返回最繁忙的 sched_group 描述符的地址,假设该组不包括本地 CPU,在这种情况下,还返回为恢复平衡而被迁移到本地运行队列中的进程数。
如果最繁忙的组包括本地 CPU,或所有的组本来就是平衡的,返回 NULL。需过滤统计工作量中的波动。 - 如果 find_busiest_group() 在调度域中没有没有找到既不包括本地 CPU 又非常繁忙的组,就释放 this_rq->lock 自旋锁,调整调度域描述符的参数,以延迟本地 CPU 下一次对 load_balance() 的调度,然后函数终止。
- find_busiest_queue() 查找第 2 步中找到的组中最繁忙的 CPU,返回相应运行队列的描述符地址 busiest。
- 获取 busiest->lock 自旋锁。为避免死锁,首先释放 this_rq->lock,然后通过增加 CPU 下标获得这两个锁。
- move_tasks() 从最繁忙的运行队列把一些进程迁移到本地运行队列 this_rq 中。
- 如果 move_tasks() 没有迁移成功,则调度域不平衡,busiest->active_balance = 1,并唤醒 migration 线程,其描述符存放在 busiest->migration_thread 中。
migration 内核下次顺着调度域的链搜从最繁忙运行队列的基本域到最上层域搜索空闲 CPU,如果找到一个空闲 CPU,就调用 move_tasks() 把一个进程迁移到空闲运行队列。 - 释放 busiest->lock 和 this_rq->lock 自旋锁。
- 函数结束。
move_tasks()
把进程从源运行队列迁移到本地运行队列。
参数:
- this_rq,本地运行队列描述符
- this_cpu,本地 CPU 下标
- busiest,源运行队列描述符
- max_nr_move 被迁移进程的最大数
- sd,在其中执行平衡操作的调度域的描述符地址
- idle 标志,可被设置为 SCHED_IDLE、NOT_IDLE、NEWLY_IDLE
从优先级高的进程开始分析 busiest 运行队列的过期进程。
扫描完所有的过期进程后,扫描 busiest 运行队列的活动进程,对所有后续进程调用 can_migrate_task(),如果下列条件都满足,can_migrate_task() 返回 1:
- 进程当前没有在远程 CPU 上执行
- 本地 CPU 包含在进程描述符的 cpus_allowed 位掩码中
- 至少满足下列条件之一:
-
- 本地 CPU 空闲。如果内核支持超线程技术,所有本地物理芯片中的逻辑 CPU 必须空闲。
-
- 内核在平衡调度域是因反复迁移进程失败而现如困境。
-
- 被迁移的进程不是“高速缓存命中”。
如果 can_migrate_task 返回 1,调用 pull_task() 将后续进程迁移到本地运行队列。
pull_task() 先执行 dequeue_task() 从远程运行队列删除进程,然后执行 enqueue_task() 把进程插入本地运行队列,如果刚被迁移的进程比当前进程拥有更高的动态优先级,
调用 resched_task() 抢占本地 CPU 的当前进程。
与调度相关的系统调用
nice()
nice() 允许进程改变自己的基本优先级。
increment 参数用来修改进程描述符的 nice 字段。
nice() 已被 setpriority() 取代。
getpriority() 和 setpriority()
nice() 只影响调用它的进程,而 getpriority() 和 setpriority() 作用于给定组中所有进程的基本优先级。
getpriority() 返回 20 减去给定组中所有进程中最低 nice 字段的值,即最高优先级。
setpriority() 把给定组中所有进程的基本优先级设置为一个给定的值。
sched_getaffinity() 和 sched_setaffinity()
分别返回和设置 CPU 进程亲和力掩码,即允许执行进程的 CPU 的位掩码。该掩码存放在进程描述符的 cpus_allowed 字段中。
与实时进程相关的系统调用
sched_getscheduler() 和 sched_setscheduler()
sched_getscheduler() 查询参数 pid 表示的进程当前使用的调度策略。如果 pid 等于 0,检索调用进程的策略。如果成功,为进程返回策略:
SCHED_FIFO、SCHED_RR 或 SCHED_NORMAL。
sched_setscheduler() 既设置调度策略,也设置由参数 pid 表示的进程的相关参数。如果 pid 等于 0,调用进程的调度程序参数将被设置。
sched_getparam() 和 sched_setparam()
sched_getparam() 检索参数 pid 表示的进程的调度参数。如果 pid 是 0,current 进程的参数被检索。
sched_setparam() 类似于 sched_setscheduler(),不同之处在于不让调用者设置 policy 字段。
sched_yield()
允许进程在不被挂起的情况下自愿放弃 CPU,进程仍然处于 TASK_RUNNING 状态,但调度程序把它放在运行队列的过期进程集合中,或运行队列链表的末尾。
sched_get_priority_min() 和 sched_get_priority_max()
分别返回最小和最大实时静态优先级的值,该值由 policy 参数标识的调度策略使用。
sched_rr_get_interval()
把参数 pid 标识的实时进程的轮转时间片写入用户地址空间的一个结构中。如果 pid 等于 0,系统调用就写当前进程的时间片。