访问基于磁盘的文件是一种复杂的活动,既涉及 VFS 抽象层、块设备的处理,也涉及磁盘高速缓存的使用。
将磁盘文件系统的普通文件和块设备文件都简单地统称为“文件”。
访问文件的模式有多种:
- 规范模式:规范模式下文件打开后,标志 O_SYNC 和 O_DIRECT 清 0,且它的内容由 read() 和 write() 存取。
read() 阻塞调用进程,直到数据被拷贝进用户态地址空间。
但 write() 在数据被拷贝到页高速缓存(延迟写)后马上结束。 - 同步模式:同步模式下文件打开后,标志 O_SYNC 置 1 或稍后由系统调用 fcntl() 对其置 1。
该标志只影响写操作(读操作总是会阻塞),它将阻塞系统调用,直到数据写入磁盘。 - 内存映射模式:内存映射模式下文件打开后,应用程序发出系统调用 mmap() 将文件映射到内存中。
因此,文件就成为 RAM 中的一个字节数组,应用程序就可直接访问数组元素,而不需要调用 read()、write() 或 lseek()。 - 直接 I/O 模式:直接 I/O 模式下文件打开后,标志 O_DIRECT 置 1。
任何读写操作都将数据在用户态地址空间与磁盘间直接传送而不通过页高速缓存。 - 异步模式:异步模式下,文件的访问可以有两种方法,即通过一组 POSIX API 或 Linux 特有的系统调用实现。
所谓异步模式就是数据传输请求并不阻塞调用进程,而是在后台执行,同时应用程序继续它的正常执行。
读写文件
read() 和 write() 的服务例程最终会调用文件对象的 read 和 write 方法,这两个方法可能依赖文件系统。
对于磁盘文件系统,这些方法能确定被访问的数据所在物理块的位置,并激活块设备驱动程序开始数据传送。
读文件文件是基于页的,内核总是一次传送几个完整的数据页。
如果进程发出 read() 后,数据不在 RAM 中,内核就分配一个新页框,并使用文件的适当部分填充该页,把该页加入页高速缓存,最后把请求的字节拷贝到进程地址空间中。
对于大部分文件系统,从文件中读取一个数据页等同于在磁盘上查找所请求的数据存放在哪些块上。
该过程完成后,内核通过向通用块成提交适当的 I/O 操作来填充这些页。
大多数磁盘文件系统 read 方法由 generic_file_read() 通用函数实现。
对基于磁盘的文件,写操作比较复杂,因文件大小可改变,因此内核可能会分配磁盘上的一些物理块。
很多磁盘文件系统通过 generic_file_write() 实现 write 方法。
从文件中读取数据
generic_file_read() 参数:
- filp,文件对象的地址
- buf,用户态线性区的线性地址,从文件中读出的数据必须存在这里
- count,要读取的字符个数
- ppos,指向一个变量的指针,该变量存放读操作开始处的文件偏移量
第一步,初始化两个描述符。
第一个描述符存放在类型为 iovec 局部变量 local_iov 中,它包含用户态缓冲区的地址(buf)和长度(count),缓冲区存放待读文件中的数据。
第二个描述符存放在类型为 kiocb 的局部变量 kiocb 中,它用来跟踪正在运行的同步和异步 I/O 操作的完成状态。
generic_file_read() 通过执行宏 init_sync_kiocb 来初始化描述符 kiocb,并设置 ki_key 字段为 KIOCB_SYNC_KEY、ki_flip 字段为 filp、ki_obj 字段为 current。
然后,调用 __generic_file_aio_read() 并将刚填完 iovec 和 kiocb 描述符地址传给它。
最后该函数返回一个值,该值通常就是从文件有效读入的字节数。
__generic_file_aio_read() 是所有文件系统实现同步和异步操作所使用的通用例程。
参数:kiocb 描述符的地址 iocb、iovec 描述符数组的地址 iov、数组的长度和存放文件当前指针的一个变量的地址 ppos。
iovec 描述符数组被函数 generic_file_read() 调用时只有一个元素,描述待接收数据的用户态缓冲区。
__generic_file_aio_read() 执行步骤:
- 调用 access_ok() 检查 iovec 描述符所描述的用户态缓冲区是否有效。
因为起始地址和长度已经从 sys_read() 服务例程得到,因此在使用前需要对它们进行检查,无效时返回错误代码 -EFAULT。 - 建立一个读操作描述符,即一个 read_descriptor_t 类型的数据结构。
该结构存放于单个用户态缓冲相关的文件读操作的当前状态。 - 调用 do_generic_file_read(),传送给它文件对象指针 filp、文件偏移量指针 ppos、刚分配的读操作描述符的地址和函数 file_read_actor() 的地址。
- 返回拷贝到用户态缓冲区的字节数,即 read_descriptor_t 中 written 字段值。
do_generic_file_read() 从磁盘读入所请求的页并把它们拷贝到用户态缓冲区。步骤如下:
- 获得要读取的文件对应的 address_space 对象,它的地址存放在 filp->f_mapping。
- 获得地址空间对象的所有者,即索引节点对象,它将拥有填充了文件数据的页面。
它的地址存放在 address_space 对象的 host 字段。
如果所读文件是块设备文件,那么所有者就不是由 filp->f_dentry->d_inode 所指向的索引节点对象,而是 bdev 特殊文件系统中的索引节点对象。 - 把文件看作细分的数据页(每页 4096 字节),并从文件指针 *ppos 导出一个请求字节所在页的逻辑号,即地址空间中的页索引,并存放在 index 局部变量中。
把第一个请求字节在页内的偏移量存放在 offset 局部变量中。 - 开始一个循环来读入包含请求字节的所有页,要读数据的字节数存放在 read_descriptor_t 描述符的 count 字段中。
每次循环中,通过下述步骤传送一个数据页:
a. 如果 index * 4096 + offset 超过索引节点对象的 i_size 字段中的文件大小,则从循环退出,并跳到第 5 步。
b. 调用 cond_resched() 检查当前进程的标志 TIF_NEED_RESCHED。如果标志置位,则调用 schedule()。
c. 如果必须预读页,则调用 page_cache_readahead() 读入这些页。
d. 调用 find_get_page(),参数为指向 address_space 对象的指针及索引值;
它将查找页高速缓存已找到包含所请求数据的页描述符。
e. 如果 find_get_page() 返回 NULL 指针,则所请求的页不在页高速缓存中,则执行如下步骤:
(1)调用 handle_ra_miss() 来调用预读系统的参数。
(2)分配一个新页。
(3)调用 add_to_page_cache() 将该新页描述符插入到页高速缓存,该函数将新页的 PG_locked 标志置位。
(4)调用 lru_cache_add() 将新页描述符插入到 LRU 链表。
(5)跳到第 4j 步,开始读文件数据。
f. 如果函数已运行至此,说明页已经位于页高速缓存中。
检查标志 PG_uptodate,如果置位,则页中的数据是最新的,因此无需从磁盘读数据,跳到第 4m 步。
g. 页中的数据是无效的,因此必须从磁盘读取。
函数通过调用 lock_page() 获取对页的互斥访问。
如果 PG_locked 已经置位,则 lock_page() 阻塞当前进程直到标志被清 0。
h. 现在页已由当前进程锁定。
但另一个进程也许会在上一步之前已从页高速缓存中删除该页,那么,它就要检查页描述符的 mapping 字段是否为 NULL。
如果是,调用 unlock_page() 解锁页,并减少它的引用计数(find_get_page() 增加计数,并跳到第 4a 步重读同一页。
i. 至此,页已经被锁定且在高速缓存中。
再次检查标志 PG_uptodate,因为另一个内核控制路径可能已经完成第 4f 步和第 4g 步的必要读操作。
如果标志置位,则调用 unlock_page() 并跳到第 4m 来跳过读操作。
j. 现在真正的 I/O 操作可以开始了,调用文件的 address_space 对象的 readpage 方法。
相应的函数会负责激活磁盘到页之间的 I/O 数据传输。
k. 如果 PG_uptodate 还没有置位,则它会等待直到调用 lock_page() 后页被有效读入。
该页在第 4g 步中锁定,一旦读操作完成就被解锁,因此当前进程在 I/O 数据传输完成时停止睡眠。
l. 如果 index 超出文件包含的页数(通过将 inode 对象的 i_size 字段的值除以 4096 得到),那么它将减少页的引用计数器,并跳出循环到第 5 步。
这种情况发生在这个正被本进程读的文件同时有其他进程正在删减它时。
m. 将应该拷入用户态缓冲区的页中的字节数存放在局部变量 nr 中。
该值的大小等于页的大小(4096 字节),除非 offset 非 0 或请求数据不全在该文件中。
n. 调用 mark_page_accessed() 将标志 PG_referenced 或 PG_active 置位,从而表示该页正被访问且不应该被换出。
如果同一文件在 do_generic_file_read() 的后续执行中要读几次,则该步骤只在第一次读时执行。
o. 把页中的数据拷贝到用户态缓冲区。调用 file_read_actor() 执行下列步骤:
(1)调用 kmap(),该函数为处于高端内存中的页建立永久的内核映射。
(2)调用 __copy_to_user() 把页中的数据拷贝到用户态地址空间。该操作在访问用户态地址空间时如果有缺页异常将会阻塞进程。
(3)调用 kunmap() 释放页的任一永久内核映射。
(4)更新 read_descriptor_t 描述符的 count、written 和 buf 字段。
p. 根据传入用户态缓冲区的有效字节数更新局部变量 index 和 count。
一般,如果页的最后一个字节已拷贝到用户态缓冲区,则 index 的值加 1 而 offset 的值清 0;
否则,index 的值不变而 offset 的值被设为已拷贝到用户态缓冲区的字节数。
q. 减少页描述符的引用计数器。
r. 如果 read_descriptor_t 描述符的 count 字段不为 0,则文件中还有其他数据要读,跳到第 4a 步继续循环读文件的下一页数据。 - 所请求的或可以读到的数据已读完。函数更新预读数据结构 filp->f_ra 来标记数据已被顺序从文件读入。
- 把 index * 4096 + offset 值赋给 *ppos,从而保存以后调用 read() 和 write() 进行顺序访问的位置。
- 调用 update_atime() 把当前时间存放在文件的索引节点对象 i_atime 字段,并把它标记为脏后返回。
总结:创建读操作请求;检查是否已读完、重新调度、预读页、在页高速缓存中、页被锁定、页中的数据是否为最新,并进行相应处理;把页中的数据拷贝到用户态缓冲区;更新读操作相关
普通文件的 readpage 方法
do_generic_file_read() 反复使用 readpage 方法把一个个页从磁盘读到内存。
address_space 对象的 readpage 方法存放的是函数地址,有效激活从物理磁盘到页高速缓存的 I/O 数据传送。
对于普通文件,该字段通常指向 mpage_readpage() 的封装函数。如 Ext3 文件系统的 readpage 方法
int exit3_readpage(struct file *file, struct page *page)
{
return mpage_readpage(page, ext3_get_block);
}
mpage_readpage() 参数为待填充页的页描述符 page 及有助于 mpage_readpage() 找到正确块的函数的地址 get_block。
该函数把相对于文件开始位置的块号转换为相对于磁盘分区中块位置的逻辑块号。
所传递的 get_block 函数总是用缓冲区首部来存放有关重要信息,如块设备(b_dev 字段)、设备上请求数据的位置(b_blocknr 字段)和块状态(b_state 字段)。
mpage_readpage() 在从磁盘读入一页时可选择两种不同的策略:
如果包含请求数据的块在磁盘上是连续的,就用单个 bio 描述符向通用块城发出读 I/O 操作。
如果不连续,就对页上的每一块用不同的 bio 描述符来读。
get_block 依赖文件系统,它的一个重要作用是:确定文件中的下一块在磁盘上是否也是下一块。
mpage_readpage() 执行下列步骤:
- 检查页描述符的 PG_private 字段:如果置位,则该页是缓冲区页,即该页与描述组成该页的块的缓冲区首部链表相关。
这意味着该页已从磁盘读入过,且页中的块在磁盘上不是相邻的。跳到第 11 步,用一次读一块的方式读该页 。 - 得到块的大小(存放在 page->mapping->host->i_blkbits 索引节点字段),然后计算出访问该页的所有块所需要的两个值,即页中的块数和页中第一块的文件块号(相对于文件起始位置页中第一块的索引)。
- 对于页中的每一块,调用依赖于文件系统的 get_block 函数,得到逻辑块号,即相对于磁盘或分区开始位置的块索引。
页中所有块的逻辑块号存放在一个本地数组中。 - 在执行上一步的同时,检查可能发生的异常条件。
当一些块在磁盘上不相邻时,或某块落入“文件洞”内时,或一个块缓冲区已经由 get_block 函数写入时,跳到第 11 步,用一次读一块的方式读该页。 - 至此,说明页中的所有块在磁盘上是相邻的。
但它可能是文件中的最后一页,因此,页中的一些块可能在磁盘上没有映像。
如果这样,它将页中相应块缓冲区填上 0;如果不是,将页描述符的标志 PG_mappedtodisk 置位。 - 调用 bio_alloc() 分配包含单一段的一个新 bio 描述符,并分别用块设备描述符地址和页中第一个块的逻辑块号来初始化 bi_bdev 字段和 bi_sector 字段。这两个信息已在第 3 步中得到。
- 用页的起始地址、所读数据的首字节偏移量(0)和所读字节总数设置 bio 段的 bio_vec 描述符。
- bio->bi_end_io = mpage_end_io_read() 的地址.
- 调用 submit_bio() 将数据传输的方向设定 bi_rw 标志,更新每 CPU 变量 page_states 来跟踪所读扇区数,并在 bio 描述符上调用 generic_make_request()。
- 返回 0(成功)。
- 如果函数跳到这里,则页中含有的块在磁盘上不连续。
如果页是最新的(PG_uptodate 置位),函数就调用 unlock_page() 对该页解锁;
否则调用 block_read_full_page() 用一次读一块的方式读该页。 - 返回 0(成功)。
mapge_end_io_read() 是 bio 的完成方法,一旦 I/O 数据传输结束它就开始执行。
假定没有 I/O 错误,将页描述符的标志 PG_uptodate 置位,调用 unlock_page() 解锁该页并唤醒相应睡眠的进程,然后调用 bio_put() 清除 bio 描述符。
块设备文件的 readpage 方法
在 bdev 特殊文件系统中,块设备使用 address_space 对象,该对象存放在对应块设备索引节点的 i_data 字段。
块设备文件的 readpage 方法总是相同的,由 blkdev_readpage() 实现,该函数调用 block_read_full_page():
int blkdev_readpage(struct file *file, struct *page page)
{
return block_read_full_page(page, blkdev_get_block);
}
block_read_full_page() 的第二个参数也指向一个函数,该函数把相对于文件开始出的文件块号转换为相对于块设备开始处的逻辑块号。
但对于块设备文件来说,这两个数是一致的。blkdev_get_block() 执行下列步骤:
- 检查页中第一个块的块号是否超过块设备的最后一块的索引值(bdev->bd_inode->i_size / bdev->bd_block_size,bdev 指向块设备描述符)。
如果超过,则对于写操作它将返回 -EIO,而对于读操作它将返回 0。 - 设置缓冲区首部的 bdev 字段为 b_dev。
- 设置缓冲区首部的 b_blocknr 字段为文件块号,它将作为参数传递给本函数。
- 把缓冲区首部的 BH_Mapped 标志置位,以表明缓冲区首部的 b_dev 和 b_blocknr 字段是有效的。
block_read_full_page() 以一次读一块的方式读一页数据。
- 检查页描述符的标志 PG_private,如果置位,则该页与描述组成该页的块的缓冲区首部链表相关;
否则,调用 create_empty_buffers() 为该页所含的所有块缓冲区分配缓冲区首部。
页中第一个缓冲区的缓冲区首部地址存放在 page->private 字段中。
每个缓冲区首部的 b_this_page 字段指向该页中下一个缓冲区的缓冲区首部。 - 从相对于页的文件偏移量(page->index 字段)计算出页中第一块的文件块号。
- 对该页中的每个缓冲区的缓冲区首部,执行如下步骤:
a. 如果标志 BH_Uptodate 置位,则跳过该缓冲区继续处理该页的下一个缓冲区。
b. 如果标志 BH_Mapped 未置位,且该块未超过文件尾,则调用 get_block。
对于普通文件,该函数在文件系统的磁盘数据结构中查找,得到相对于磁盘或分区开始处的缓冲区逻辑块号。
对于块设备文件,该函数把文件块号当作逻辑块号。
对这两种情形,函数都将逻辑块号存放在相应缓冲区首部的 b_blocknr 字段中,并将标志 BH_Mapped 置位。
c. 再检查标志 BH_Uptodate,因为依赖于文件系统的 get_block 可能已触发块 I/O 操作而更新了缓冲区。
如果 BH_Uptodate 置位,则继续处理该页的下一个缓冲区。
d. 将缓冲区首部的地址存放在局部数组 arr 中,继续该页的下一个缓冲区。 - 假如上一步中没有遇到“文件洞”,则将该页的标志 PG_mappedtodisk 置位。
- 现在局部变量 arr 中存放了一些缓冲区首部的地址,与其对应的缓冲区的内容不是最新的。
如果数组为空,那么页中的所有缓冲区都是有效的,因此,该函数设置页描述符的 PG_uptodate 标志,调用 unlock_page() 对该页解锁并返回。 - 局部数组 arr 非空。对数组中的每个缓冲区首部,执行下述步骤:
a. 将 BH_Lock 标志置位。该标志一旦置位,就一直等待该缓冲区释放。
b. 将缓冲区首部的 b_end_io 字段设置为 end_buffer_async_read() 的地址,并将缓冲区首部的 BH_Async_Read 标志置位。 - 对局部数组 arr 中的每个缓冲区首部调用 submit_bh(),将操作类型设为 READ,该函数触发了相应块的 I/O 数据传输。
- 返回 0。
end_buffer_async_read() 在对缓冲区的 I/O 数据传输结束后就执行。
假定没有 I/O 错误,将缓冲区首部的 BH_Uptodate 标志置位而将 BH_Async_Read 标志置 0。
那么,函数就得到包含块缓冲区的缓冲区页描述符,同时检测页中所有块是否是最新的,如果是,将该页的 PG_uptodate 标志置位并调用 unlock_page()。
文件的预读
预读在实际请求前读普通文件或块设备文件的几个相邻的数据页。
文件的预读需要复杂的算法,原因如下:
- 由于数据是逐页读取的,因此预读算法不必考虑页内偏移量,只要考虑所访问的页在文件内部的位置就可以了。
- 只要进程持续地顺序访问一个文件,预读就会逐渐增加。
- 当前的访问与上一次访问不是顺序时,预读就会逐渐减少乃至禁止。
- 当一个进程重复地访问同一页,或当几乎所有的页都已在页高速缓存时,预读必须停止。
- 低级 I/O 设备驱动程序必须在合适的时候激活,这样当将来进程需要时,页已传送完毕。
当访问给定文件时,预读算法使用两个页面集,当前窗和预读窗,各自对应文件的一个连续区域。
当前窗内的页是进程请求的页和内核预读的页,且位于页高速缓存内(当前窗内的页不必是最新的,因为 I/O 数据传输仍可能在运行)。
当前窗包含进程顺序访问的最后一页,且可能由内核预读但进程未请求的页。
预读窗内的页紧接着当前窗内的页,它们是内核正在预读的页。
预读窗内的页都不是进程请求的,但内核假定进程迟早会请求。
当内核认为是顺序访问且第一页在当前窗内时,它就检测是否建立了预读窗。
如果没有,内核就创建一个预读窗并触发相应页的读操作。
理想情况下,进程继续从当前窗请求页,同时预读窗的页则正在传送。
当进程请求的页在预读窗,则预读窗就成为当前窗。
预读算法使用的主要数据结构是 file_ra_state 描述符,存放于每个文件对象的 f_ra 字段。
当一个文件被打开时,在它的 file_ra_state 描述符中,除了 prev_page 和 ra_pages 这两个字段,其他的所有字段都置为 0。
prev_page 存放进程上一次读操作中所请求页的最后一页的索引。初值为 -1。
ra_pages 表示当前窗的最大页数,即对该文件允许的最大预读量。初值在该文件所在块设备的 backing_dev_info 描述符。
flags 字段内有两个重要的字段 RA_FLAG_MISS 和 RA_FLAG_INCACHE。
如果已被预读的页不在页高速缓存内,则第一个标志置位,这时下一个要创建的预读窗大小将被缩小。
当内核确定进程请求的最后 256 页都在页高速缓存内时(连续高速缓存名字数存放在 ra->cache_hit 字段中),第二个标志置位,这时内核认为所有的页都已在高速缓存内,关闭预读。
执行预读算法的时机:
- 当内核用用户态请求读文件数据页时。触发 page_cache_readahead()。
- 当内核为文件内存映射分配一页时。
- 当用户态应用执行 readahead() 系统调用时,对某个文件描述符显式触发某预读活动。
- 当用户态应用使用 POSIX_FADV_NOREUSE 或 POSIX_FADV_WILLNEED 命令执行 posix_fadvise() 系统调用时,它会通知内核,某个范围的文件页不久将要被访问。
- 当用户态应用使用 MADV_WILLNEED 命令执行 madvise() 系统调用时,它会通知内核,某个文件内存映射区域中的给定范围的文件页不久将要被访问。
page_cache_readahead()
处理没有被特殊系统调用显式触发的所有预读操作。
它填写当前窗和预读窗,根据预读命中数更新当前窗和预读窗的大小,即根据过去对文件访问预读策略的成功程度调整。
当内核必须满足对某个文件一页或多页的读请求时,函数就被调用,参数如下:
- mapping,描述页所有者的 address_space 对象指针
- ra,包含该页的文件 file_ra_state 描述符指针
- filp,文件对象地址
- offset,文件内页的偏移量
- req_size,完成当前读操作还需读的页数
当进程第一次访问一个文件,且其第一个请求页是文件中偏移量为 0 的页时,函数假定进程要进行顺序访问。
那么,从第一页创建一个新的当前窗。初始当前窗的长度与进程第一个读操作所请求的页数有关。
请求的页数越大,当前窗就越大,一直到最大值,即 ra->ra_pages。
反之,当进程第一次访问文件,但第第一个请求页在文件中的偏移量不为 0 时,函数假定进程不是执行顺序读。
那么,禁止预读(ra->size = -1)。但当预读暂时被禁止而函数又认为需要顺序读时,将建立一个新的当前窗。
预读窗总是从当前窗的最后一页开始。但它的长度与当前窗的长度相关:
如果 PA_FLAG_MISS 标志置位,则预读窗长度为当前窗长度减 2,小于 4 时设为 4;
否则,预读窗长度为当前窗长度的 4 倍或 2 倍。
如果进程继续顺序访问文件,最终预读窗会成为新的当前窗,新的预读窗被创建。
一旦函数认识到对文件的访问相对于上一次不是顺序的,当前窗与预读窗就被清空,预读被暂时禁止。
当进程的读操作相对于上一次文件访问为顺序时,预读将重新开始。
每次 page_cache_readahead() 创建一个新窗,它就开始对所包含页的读操作。
为了读一大组页,page_cache_readahead() 调用 blockable_page_cache_readahead()。
为了减少内核开销,blockable_page_cache_readahead() 采用下面灵活的方法:
- 如果服务于块设备的请求队列是读拥塞的,就不进行读操作。
- 将要读的页与页高速缓存进行比较,如果该页已在页高速缓存内,跳过即可。
- 在从磁盘读前,读请求所需的全部页框是一次性分配的。
如果不能一次性得到全部页框,预读操作就只在可以得到的页上进行。 - 只要可能,通过使用多段 bio 描述符向通用块层发出读操作。
这通过 address_space 对象专用的 readpages 方法实现;如果没有定义,就通过反复调用 readpage 方法实现。
handle_ra_miss()
当预读策略不是十分有效,内核就必须修正预读参数。
如果进程do_generic_file_read() 在第 4c 步调用 page_cache_readahead() 有两种情形:
请求页在当前窗或预读窗表明它已经被预先读入了;
或者还没有,则调用 blockable_page_cache_readahead() 来读入。
在这两种情形下,do_generic_file_read() 在第 4d 步中就在页高速缓存中找到了该页,如果没有,就表示该页框已经被收回算法从高速缓存中删除。
这种情形下,do_generic_file_read() 调用 handle_ra_miss(),通过将 RA_FLAG_MISS 标志置位与 RA_FLAG_INCACHE 标志清 0 来调整预读算法。
写入文件
write() 涉及把数据从进程的用户态地址空间中移动到内核数据结构中,然后再移动到磁盘上。
文件对象的 write 方法允许每种文件类型都定义一个专用的操作。
Linux 2.6 中,每个磁盘文件系统的 write 方法都是一个过程,主要表示写操作所涉及的磁盘块,把数据从用户态地址空间拷贝到页高速缓存的某些页中,然后把这些页中的缓冲区标记成脏。
许多文件系统通过 generic_file_write() 来实现文件对象的 write 方法,参数:
- file,文件对象指针
- buf,用户态地址空间中的地址,必须从该地址获取要写入文件的字符
- count,要写入的字符个数
- ppos,存放文件偏移量的变量地址,必须从这个偏移量处开始写入
执行以下操作:
- 初始化 iovec 类型的一个局部变量,它包含用户态缓冲区的地址与长度。
- 确定所写文件索引节点对象的地址 inode(file->f_mapping->host),获得信号量(inode->i_sem).
有了该信号量,一次只能有一个进程对某个文件发出 write() 系统调用。 - 调用 init_sync_kiocb 初始化 kiocb 类型的局部变量。
将 ki_key 字段设置为 KIOCB_SYNC_KEY、ki_filp 字段设置为 filp、ki_obj 字段设置为 current。 - 调用 __generic_file_aio_write_nolock() 将涉及的页标记为脏,并传递相应的参数:iovec 和 kiocb 类型的局部变量地址、用户态缓冲区的段数和 ppos。
- 释放 inode->i_sem 信号量。
- 检查文件的 O_SYNC 标志、索引节点的 S_SYNC 标志及超级块的 MS_SYNCHRONOUS 标志。
如果至少一个标志置位,则调用 sync_page_range() 强制内核将页高速缓存中第 4 步涉及的所有页刷新,阻塞当前进程直到 I/O 数据传输结束。
sync_page_range() 先执行 address_space 对象的 writepage 方法或 mpage_writepages() 开始这些脏页的 I/O 传输,然后调用 generic_osync_inode() 将索引节点和相关缓冲区刷新到磁盘,最后调用 wait_on_page_bit() 挂起当前进程直到全部所刷新页的 PG_writeback 标志清 0。 - 将 __generic_file_aio_write_nolock() 的返回值返回,通常是写入的有效字节数。
__generic_file_aio_write_nolock() 参数:kiocb 描述符的地址 iocb、iovec 描述符数组的地址 iov、该数组的长度及存放文件当前指针的变量的地址 ppos。
当被 generic_file_write() 调用时,iovec 描述符数组只有一个元素,该元素描述待写数据的用户态缓冲区。
仅讨论最常见的情形,对有页高速缓存的文件进行 write() 调用的一般情况。
__generic_file_aio_write_nolock() 执行如下步骤:
- 调用 access_ok() 确定 iovec 描述符所描述的用户态缓冲区是否有效。无效时返回错误码 -EFAULT。
- 确定待写文件(file->f_mapping->host)索引节点对象的地址 inode。
如果文件是一个块设备文件,这就是一个 bdev 特殊文件系统的索引节点。 - 将文件(file->f_mapping->backing_dev_info)的 backing_dev_info 描述符的地址设为 current->backing_dev_info。
实际上,即使相应请求队列是拥塞的,该设置也会允许当前进程写回 file->f_mapping 拥有的脏页。 - 如果 file->flags 的 O_APPEND 标志置位且文件是普通文件(非块设备文件),它将 *ppos 设为文件尾,从而新数据都将追加到文件的后面。
- 对文件大小进行几次检查。如,写操作不能把一个普通文件增大到超过每用户的上限或文件系统的上限,每用户上限存放在 current->signal->rlim[RLIMIT_FSIZE],文件系统上限存放在 inode->i_sb->s_maxbytes。
另外,如果文件不是“大型文件”(当 file->f_flags 的 O_LARGEFILE 标志清 0 时),则其大小不能超过 2GB。
如果没有设定上述限制,它就减少待写字节数。 - 如果设定,则将文件的 suid 标志清 0,如果是可执行文件的话就将 sgid 标志也清 0。
- 将当前时间存放在 inode->mtime 字段(文件写操作的最新时间)中,也存放在 inode->ctime 字段(修改索引节点的最新时间)中,且将索引节点对象标记为脏。
- 开始循环以更新写操作中涉及的所有文件页。每次循环期间,执行下列子步骤:
a. 调用 find_lock_page() 在页高速缓存中搜索该页。如果找到,则增加引用计数并将 PG_locked 标志置位。
b. 如果该页不在页高速缓存中,则分配一个新页框并调用 add_to_page_cache() 在页高速缓存内插入此页。
增加引用计数并将 PG_locked 标志置位。在内存管理区的非活动链表中插入一页。
c. 调用索引节点(file->f_mapping)中 address_space 对象的 prepare_write 方法。为该页分配和初始化缓冲区首部。
d. 如果缓冲区在高端内存中,则建立用户态缓冲区的内核映射,然后调用 __copy_from_user() 把用户态缓冲区中的字符拷贝到页中,并释放内核映射。
e. 调用索引节点(file->f_mapping)中 address_space 对象的 commit_write 方法,把基础缓冲区标记为脏。
f. 调用 unlock_page() 清 PG_locked 标志,并唤醒等待该页的任何进程。
g. 调用 mark_page_accessed() 为内存回收算法更新页状态。
h. 减少页引用计数来撤销第 8a 或 8b 步中的增加值。
i. 在这一步,还有一页被标记为脏,检查页高速缓存中脏页比例是否超过一个固定的阈值(通常为系统中页的 40%)。
如果是,调用 writeback_inodes() 刷新几十页到磁盘。
j. 调用 cond_resched() 检查当前进程的 TIF_NEED_RESCHED 标志。如果该标志置位,则调用 schedule()。 - 现在,写操作中所涉及的文件的所有页都已处理。更新 *ppos 的值,让它正好指向最后一个被写入的字符之后的位置。
- 设置 current->backing_dev_info 为 NULL。
- 返回写入文件的有效字符数后结束。
总结:检查;判断是写入还是追加;如果页不在缓存中则添加到缓存中,并标记为脏;如果脏页过多则刷新到磁盘;返回写入字符数。
普通文件的 prepare_write 和 commit_write 方法
address_space 对象的 prepare_write 和 commit_write 方法专门用于由 generic_file_write() 实现的通用写操作,适用于普通文件和块设备文件。
每个磁盘文件系统都定义了自己的 prepare_write 方法。Ext2 文件系统:
int ext2_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page, from, to, ext2_get_block);
}
ext2_get_block() 把相对于文件的块号转换为逻辑块号。
block_prepare_write() 为文件页的缓冲区和缓冲区首部做准备:
- 检查某页是否是一个缓冲区页(如果是则 PG_Private 标志置位);如果该标志清 0,则调用 create_empty_buffers() 为页中所有的缓冲区分配缓冲区首部。
- 对于页中包含的缓冲区对应的每个缓冲区首部,及受写操作影响下每个缓冲区首部,执行下列操作:
a. 如果 BH_New 标志置位,则将它清 0。
b. 如果 BH_New 标志已清 0,则执行下列子步骤:
(1)调用依赖于文件系统的函数,该函数的地址 get_block 以参数形式传递过来。
查看这个文件系统磁盘数据结构并查找缓冲区的逻辑块号(相对于磁盘分区的起始位置)。
与文件系统相关的函数把这个数存放在对应缓冲区首部的 b_blocknr 字段,并设置它的 BH_Mapped 标志。
与文件系统相关的函数可能为文件分配一个新的物理块,这种情况下,设置 BH_New 标志。
(2)检查 BH_New 标志的值;如果被置位,则调用 unmap_underlying_metadata() 检查页高速缓存内的某个块设备缓冲区是否包含指向磁盘同一块的一个缓冲区。
实际上调用 __find_get_block() 在页高速缓存内查找一个旧块。
如果找到一块,将 BH_Dirty 标志清 0 并等待直到该缓冲区的 I/O 数据传输完毕。
此外,如果写操作不对整个缓冲区进行重写,则用 0 填充未写区域,然后考虑页中的下一个缓冲区。
c. 如果写操作不对整个缓冲区进行重写且它的 BH_Delay 和 BH_Uptodate 标志未置位(已在磁盘文件系统数据结构中分配了块,但 RAM 中的缓冲区没有有效的数据映射),函数对该块调用 ll_rw_block() 从磁盘读取它的内容。 - 阻塞当前进程,直到在第 2c 步触发的所有读操作全部完成。
- 返回 0。
一旦 prepare_write 方法返回,generic_file_write() 就用存放在用户态地址空间中的数据更新页。
接下来,调用 address_space 对象的 commit_write 方法。
该方法由 generic_commit_write() 实现,几乎适用于所有非日志型磁盘文件系统。
generic_commit_write() 执行下列步骤:
- 调用 __block_commit_write(),然后依次执行如下步骤:
a. 考虑页中受写操作影响的所有缓冲区;对于其中的每个缓冲区,将对应缓冲区首部的 BH_Uptodate 和 BH_Dirty 标志置位。
b. 标记相应索引节点为脏,这需要将索引节点加入超级块脏的索引节点链表。
c. 如果缓冲区页中的所有缓冲区是最新的,则将 PG_uptodate 标志置位。
d. 将页的 PG_dirty 标志置位,并在基树中将页标记成脏。 - 检查写操作是否将文件增大。如果增大,则更新文件索引节点对象的 i_size 字段。
- 返回 0。
块设备文件的 prepare_write 和 commit_write 方法
写入块设备文件的操作类似于对普通文件的相应操作。
块设备文件的 address_space 对象的 prepare_write 方法通常由下列函数实现:
int blkdev_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_prepare_write(page, from, to, blkdev_get_block);
}
与之前的 block_prepare_write() 唯一的差异在第二个参数,它是一个指向函数的指针,该函数必须把相对于文件开始处的文件块号转换为相对与块设备开始处的逻辑块号。对于块设备文件,这两个数是一致的。
块设备文件的 commit_write 方法:
int blkdev_commit_write(struct file *file, struct page *page, unsigned from, unsigned to)
{
return block_commit_write(page, from, to);
}
用于块设备的 commit_write 方法与用于普通文件的 commit_write 方法本质上做同样的事情。
唯一的差异是这个方法不检查写操作是否扩大了文件,因为不可能在块设备文件的末尾追加字符。
把脏页写到磁盘
通常 I/O 数据传输是延迟进行的。
当内核要启动有效 I/O 数据传输时,就调用文件 address_space 对象的 writepages 方法,它在基树中寻找脏页,并把它们刷新到磁盘。
如 Ext2 文件系统:
int ext2_writepages(struct address_space *mapping, struct writeback_control *wbc)
{
return mpage_writepages(mapping, wbc, ext2_get_block);
}
对于 mpage_writepages(),如果没有定义 writepages 方法,内核直接调用 mpage_writepages() 并把 NULL 传给第三个参数。
ext2_get_block() 将文件块号转换成逻辑块号。
writeback_control 数据结构是一个描述符,它控制 writeback 写操作如何执行。
mpage_writepages() 指向下列步骤:
- 如果请求队列写拥塞,但进程不希望阻塞,则不向磁盘写任何页就返回。
- 确定文件的首页,如果 writeback_control 描述符给定一个文件内的初始位置,将它转换成索引。
否则,如果 writeback_control 描述符指定进程无需等待 I/O 数据传输结束,它将 mapping->writeback_index 的值设为初始页索引。
最后,如果进程必须等待数据传输完毕,则从文件的第一页开始扫描。 - 调用 find_get_pages_tag() 在页高速缓存中查找脏页描述符。
- 对上一步得到的每个页描述符,执行下述步骤:
a. 调用 lock_page() 锁定该页。
b. 确认页是有效的并在页高速缓存内。
c. 检查页的 PG_writeback 标志。如果置位,表明页已被刷新到磁盘。
如果进程必须等待 I/O 数据传输完毕,则调用 wait_on_page_bit() 在 PG_writeback 清 0 前一直阻塞当前进程;
函数结束时,以前运行的任何 writeback 操作都被终止。
否则,如果进程无需等待,它将检查 PG_dirty 标志,如果清 0,则正在运行的写回操作将处理该页,将它解锁并跳回第 4a 步继续下一页。
d. 如果 get_block 参数是 NULL,它将调用文件 address_space 对象的 mapping->writepage 方法将页刷新到磁盘。
否则,如果 get_block 参数不是 NULL,就调用 mpage_writepage()。详见第 8 步。 - 调用 cond_resched() 检查当前进程的 TIF_NEED_RESCHED 标志,如果置位就调用 schedule()。
- 如果函数没有扫描完给定范围内的所有页,或写到磁盘的有效页数小于 writeback_control 描述符中原先的给定值,则跳回第 3 步。
- 如果 writeback_control 描述符没有给定文件内的初始位置,它将最后一个扫描页的索引值赋给 mapping->writeback_index 字段。
- 如果在第 4d 步中调用了 mpage_writepage(),且返回了 bio 描述符地址,则调用 mpage_bio_submit()。
像 Ext2 这样的典型文件系统的 writepage 方法是一个通用的 block_write_full_page() 的封装函数。
block_write_full_page() 分配页缓冲区首部(如果还不在缓冲区页中),对每页调用 submit_bh() 指定 WRITE 操作。
对于块设备文件,block_write_full_page() 的封装函数为 blkdev_writepage()。
许多非日志文件系统依赖于 mpage_writepage() 而不是自定义的 writepage 方法。
这样能改善性能,因为 mpage_writepage() 在 I/O 传输中可将尽可能多的页聚集在一个 bio 描述符。
有利于块设备驱动程序利用硬盘控制器的 DMA 分散-聚集能力。
mpage_writepage() 将检查:待写页包含的块在磁盘上是否不相邻,该页是否包含文件洞,页上的某块是否没有脏或不是最新的。
如果以上至少一条成立,就仍然用依赖于文件系统的 writepage 方法;否则,将页追加为 bio 描述符的一段。
bio 描述符的地址将作为参数被传给函数;如果为 NULL,mpage_writepage() 将初始化一个新的 bio 描述符并将地址返回给调用函数,
调用函数未来调用 mpage_writepage() 时再将该地址传回。这样,同一个 bio 可加载几个页。
如果 bio 中某页与上一个加载页不相邻,mpage_writepage() 就调用 mpage_bio_submit() 开始该 bio 的 I/O 数据传输,并为该页分配一个新的 bio。
mpage_bio_submit() 将 bio 的 bi_end_io 方法设为 mpage_end_io_write() 的地址,然后调用 submit_bio() 开始传输。
一旦数据传输成功结束,mpage_end_io_write() 就唤醒那些等待传输结束的进程,并消除 bio 描述符。
内存映射
内核把对线性区中页内某个字节的访问转换成对文件中相应字节的操作的技术为内存映射。
两种类型的内存映射:
- 共享型,在线性区页上的任何写操作都会修改磁盘上的文件;而且,如果进程读共享映射中的一个页进行写,那么这种修改对于其他映射了这同一文件的所有进程来说都是可见的。
- 私有型,当进程创建的映射只是为读文件,而不是写文件时才会使用此种映射。私有映射的效率比共享映射高。
但对私有映射页的任何写操作都会使内核停止映射该文件中的页。因此,写操作既不会改变磁盘上的文件,对访问相同文件的其他进程也不可见。
但私有内存映射中还没有被进程改变的页会因为其他进程对文件的更新而更新。
mmap() 创建一个新的内存映射,必须指定要给 MAP_SHARED 标志或 MAP_PRIVATE 标志作为参数。
一旦创建映射,进程就可以从这个新线性区的内存单元读取数据,等价于读取了文件中存放的数据。
munmap() 撤销或缩小一个内存映射。
如果一个内存映射是共享的,相应的线性区就设置了 VM_SHARED 标志;
如果一个内存映射是私有的,相应的线性区就清除了 VM_SHARED 标志。
内存映射的数据结构
- 所映射的文件相关的索引节点对象
- 所映射文件的 address_space 对象
- 不同进程对一个文件进行不同映射所使用的文件对象
- 对文件进行每一不同映射所使用的 vm_area_struct 描述符
- 对文件进行映射的线性区所分配的每个页框所对应的页描述符
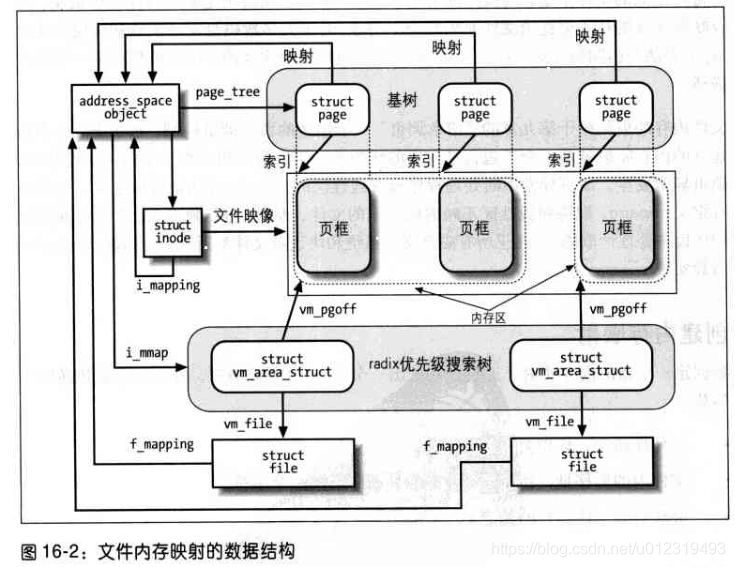
图的左边给出了标识文件的索引节点。
每个索引节点对象的 i_mapping 字段指向文件的 address_space 对象。
每个 address_space 对象的 page_tree 字段又指向该地址空间的页的基树,而 i_mmap 字段指向第二棵树,叫做 radix 优先级搜索树(PST),这种树由地址空间的线性区组成。PST 的主要作用是为了执行“反向映射”,这是为了快速标识共享一页的所有进程。
每个线性区描述符都有一个 vm_file 字段,与所映射文件的文件对象链接(如果为 NULL,则线性区没有用于内存映射)。
第一个映射的位置存放线性区描述符的 vm_pgoff 字段,它表示以页大小为单位的偏移量。
所映射的文件那部分的长度就是线性区的大小,可以从 vm_start 和 vm_end 字段计算出来。
共享内存映射的页通常都包含在页高速缓存中;私有内存映射的页只要还没有被修改,也包含在页高速缓存。
当进程试图修改一个私有内存映射的页时,内核就把该页进行复制,并在进程页表中用复制的页替换原来的页框。
虽然原来的页框还在页高速缓存,但不再属于这个内存映射。
该复制的页框不会被插入页高速缓存,因为其中包含的数据不再是磁盘上表示那个文件的有效数据。
对每个不同的文件系统,内核提供了几个钩子函数来定制其内存映射机制。内存映射实现的核心委托给文件对象的 mmap 方法。
对于大多数磁盘文件系统和块设备文件,该方法由 generic_file_mmap() 通用函数实现。
文件内存映射依赖于请求调用机制。
创建内存映射
mmap() 参数:
- 文件描述符,标识要映射的文件
- 文件内的偏移量,指定要映射的文件部分的第一个字符
- 要映射的文件部分的长度
- 一组标志,进程必须显式地设置 MAP_SHARED 标志或 MAP_PRIVATE 标志来指定所请求的内存映射的种类。
- 一组权限,指定对线性区进行访问的一种或多种权限:读访问(PROT_READ)、写访问(PROT_WRITE)或执行访问(PROT_EXEC)。
- 一个可选的的线性地址,内核把该地址作为新线性区应该从哪里开始的一个线索。如果指定了 MAP_FIXED 标志,且内核不能从指定的线性地址开始分配新线性区,那么这个系统调用失败。
mmap() 系统调用返回新线性区中第一个单元位置的线性地址。主要调用 do_mmap_pgoff() 函数。
do_mmap_pgoff():
- 检查要映射的文件是否定义了 mmap 文件操作。如果没有,就返回一个错误码。文件操作表中的 mmap 值为 NULL 说明相应的文件不能被映射。
- get_unmapped_area() 调用文件对象的 get_unmapped_area 方法,如果已定义,就为文件的内存映射分配一个合适的线性地址区间。
磁盘文件系统不定义这个方法,需调用内存描述符的 get_unmapped_area 方法。 - 除了进行正常的一致性检查外,还要对所请求的内存映射的种类(存放在 mmap() 的参数 flags 中)与在打开文件时所指定的标志(存放在 file->f_mode 字段中)进行比较。
根据这两个消息源,执行以下的检查:
- 如果请求一个共享可写的内存映射,文件应该是为写入而打开的,而不是以追加模式打开的(open() 的 O_APPEND 标志)。
- 如果请求一个共享内存映射,文件上应该没有强制锁。
- 对于任何种类的内存映射,文件都应该是为读操作而打开的。
- 用文件对象的地址初始化线性区描述符的 vm_file 字段,并增加文件的引用计数器。
对映射的文件调用 mmap 方法,将文件对象地址和线性区描述符地址作为参数传给它。
a. 将当前时间赋给文件索引节点对象的 i_atime 字段,并将该索引节点标记为脏。
b. 用 generic_file_vm_ops 表的地址初始化线性区描述符的 vm_ops 字段。
在这个表中的方法,除了 nopage 和 populate 方法外,其他都为空。nopage 方法由 filemap_nopage() 实现,而 populate 方法由 filemap_poplate() 实现。 - 增加文件索引节点对象 i_writecount 字段的值,该字段就是写进程的引用计数器。
撤销内存映射
munmap() 还可用于减少每种内存区的大小。参数:
- 要删除的线性地址区间中第一个单元的地址
- 要删除的线性地址区间的长度
sys_munmap() 服务例程实际上调用 do_munmap()。
不需要将待撤销可写共享内存映射中的页刷新到磁盘。
实际上,这些页仍然在页高速缓存内,因此继续起磁盘高速缓存的作用。
内存映射的请求调页
内存映射创建后,页框的分配尽可能推迟。
内核先验证缺页所在地址是否包含在某个进程的线性区内,如果是,内核就检查该地址所对应的页表项,如果表项为空,就调用 do_no_page()。
do_no_page() 执行对请求调页的所有类型都通用的操作,如分配页框和更新页表。
它还检查所涉及的线性区是否定义了 nopage 方法,当定义时,do_no_page() 执行的主要操作:
- 调用 nopage 方法,返回包含所请求页的页框的地址。
- 如果进程试图对页进行写入,而该内存映射是私有的,则通过把刚读取的页拷贝一份并插入页的非活动链表中来避免进一步的“写时复制”异常。
如果私有内存映射区域还没有一个包含新页的被动匿名线性区,它要么追加一个新的被动匿名线性区,要么增大现有的。
在下面步骤中,该函数使用新页而不是 nopage 方法返回的页,所以后者不会被用户态进程修改。 - 如果某个其他进程删改或作废了该页(address_space 描述符的 truncate_count 字段就是用于这种检查的),函数将跳回第 1 步,尝试再次获得该页。
- 增加进程内存描述符的 rss 字段,表示一个新页框已分配给进程。
- 用新页框的地址及线性区的 vm_page_prot 字段中所包含的页访问权来设置缺页所在的地址对应的页表项。
- 如果进程试图对该页进行写入,则把页表项的 Read/Write 和 Dirty 位强制置为 1。
这种情况下,或者把该页框互斥地分配给进程,或者让页成为共享;这两种情况下,都应该允许对该页进行写入。
请求调页算法的核心在于线性区的 nopage 方法。
一般,该方法必须返回进程所访问页所在的页框地址。其实现依赖于页所在线性区的种类。
在处理对磁盘文件进行映射的线性区时,nopage 方法必须首先在页高速缓存中查找所请求的页。
如果没有找到相应的页,就必须从磁盘读入。大部分文件系统都是由 filemap_nopage 实现 nopage 方法。参数:
- area,所请求页所在线性区的描述符地址。
- address,所请求页的线性地址。
- type,存放函数侦测到的缺页类型(VM_FAULT_MAJOR 或 VM_FAULT_MINOR)的变量的指针。
filemap_nopage() 执行以下步骤:
- 从 area->vm_file 字段得到文件对象地址 file;
从 file->f_mapping 得到 address_space 对象地址;
从 address_space 对象的 host 字段得到索引节点对象地址。 - 用 area 的 vm_start 和 vm_pgoff 字段来确定从 address 开始的页对应的数据在文件中的偏移量。
- 检查文件偏移量是否大于文件大小。如果是,就返回 NULL,这意味着分配新页失败,除非缺页是由调试程序通过 ptrace() 跟踪另一个进程引起的。
- 如果线性区的 VM_RAND_READ 标志置位,假定进程以随机方式读内存映射中的页,那么它忽略预读,跳到第 10 步。
- 如果线性区的 VM_SEQ_READ 标志置位,假定进程以严格顺序读内存映射中的页,则调用 page_cache_readahead() 从缺页处开始预读。
- 调用 find_get_page(),在页高速缓存内寻找由 address_space 对象和文件偏移量标识的页。如果找到,跳到第 11 步。
- 此时,说明没有在页高速缓存中找到页,检查内存区的 VM_SEQ_READ 标志:
a. 如果标志置位,内核将强行预读线性区中的页,预读算法失败,就调用 handle_ra_miss() 来调整预读参数,并跳到第 10 步。
b. 否则,如果标志未置位,将文件 file_ra_state 描述符中的 mmap_miss 计数器加 1。
如果失败数远大于命中数(存放在 mmap_hit 计数器内),将忽略预读,跳到第 10 步。 - 如果预读没有永久禁止(file_ra_state 描述符的 ra_pages 字段大于 0),将调用 do_page_cache_readahead() 读入包含请求页的一组页。
- 调用 find_get_page() 检查请求页是否在页高速缓存中,如果在,跳到第 11 步。
- 调用 page_cache_read() 检查请求页是否在页高速缓存中,如果不在,则分配一个新页框,把它追加到页高速缓存,执行 mapping->a_ops->readpage 方法,安排一个 I/O 操作从磁盘读入该页内容。
- 调用 grab_swap_token(),尽可能为当前进程分配一个交换标记。
- 请求页已在页高速缓存中,将文件 file_ra_state 描述符的 mmap_hit 计数器加 1。
- 如果页不是最新的(标志 PG_uptodate 未置位),就调用 lock_page() 锁定该页,执行 mapping->a_ops->readpage 方法触发 I/O 数据传输,调用 wait_on_page_bit() 后睡眠,一直等到该页被解锁,即等待数据传输完成。
- 调用 mark_page_accessed() 来标记请求页为访问过。
- 如果在页高速缓存内找到该页的最新版,将 *type 设为 VM_FAULT_MINOR,否则设为 VM_FAULT_MAJOR。
- 返回请求页地址。
用户态进程可通过 madvise() 来调整 filemap_nopage() 的预读行为。
MADV_RANDOM 命令将线性区的 VM_RAND_READ 标志置位,从而指定以随机方式访问线性区的页。
MADV_SEQUNTIAL 命令将线性区的 VM_SEQ_READ 标志置位,从而指定以严格顺序方式访问页。
MADV_NORMAL 命令将复位 VM_RAND_READ 和 VM_SEQ_READ 标志,从而指定以不确定的顺序访问页。
把内存映射的脏页刷新到磁盘
进程可是由 msync() 把属于共享内存映射的脏页刷新到磁盘。
参数:一个线性地址区间的起始地址、区间的长度即具有下列含义的一组标志。
- MS_SYNC,挂起进程,直到 I/O 操作完成。调用进程可假设当系统调用完成时,该内存映射中的所有页都已经被刷新到磁盘。
- MS_ASYNC(对 MS_SYNC 的补充),要求系统调用立即返回,而不用挂起调用进程。
- MS_INVALIDATE,使同一文件的其他内存映射无效(没有真正实现,因为在 Linux 中无用)。
对线性地址区间中所包含的每个线性区,sys_msync() 服务例程都调用 msync_interval() 执行以下操作:
- 如果线性区描述符的 vm_file 字段为 NULL,或者如果 VM_SHARED 标志清 0,就返回 0(该线性区不是文件的可写共享内存映射)。
- 调用 filemap_sync() 扫描包含在线性区地址区间所对应的页表项。
对于找到的每个页,重设对应页表项的 Dirty 标志,调用 flush_tlb_page() 刷新相应的快表(TLB)。
然后设置页描述符的 PG_dirty 标志,把页标记为脏。 - 如果 MS_ASYNC 标志置位,返回。MS_ASYNC 标志的实际作用就是将线性区的页标志 PG_dirty 置位。
该系统调用没有实际开始 I/O 数据传输。 - 至此,MS_SYNC 标志置位,必须将内存区的页刷新到磁盘,且当前进程必须睡眠直到所有 I/O 数据传输结束。
为此,要得到文件索引节点的信号量 i_sem。 - 调用 filemap_fdatawrite(),参数为文件的 address_space 对象的地址。
必须用 WB_SYNC_ALL 同步模式建立一个 writeback_control 描述符,且要检查地址空间是否有内置的 writepage 方法。
如果有,则返回;没有,则执行 mapge_writepages() 将脏页写到磁盘。 - 检查文件对象的 fsync 方式是否定义,如果是,则执行。
对于普通文件,该方法仅把文件的索引节点对象刷新到磁盘。
然后,对于块设备文件,该方法调用 sync_blockdev() 激活该设备所有脏缓冲区的 I/O 数据传输。 - 执行 filemap_fdatawait()。页高速缓存中的基树标识了所有通过 PAGECACHE_TAG_SRITEBACK 标记正在往磁盘写的页。
函数快速扫描覆盖给定线性地址区间的这一部分基树来寻找 PG_writeback 标志置位的页。
调用 wait_on_page_bit() 使其中每一页睡眠,直到 PG_writeback 标志清 0,即等到正在进行的该页的 I/O 数据传输结束。 - 释放文件的信号量 i_sem 并返回。
非线性内存映射
非线性映射中,每一内存页都映射文件数据中的随机页。
为实现非线性映射,内核使用了另外一些数据结构。
首先,线性区描述符的 VM_NONLINERAR 标志用于表示线性区存在一个非线性映射。
给定文件的所有非线性映射线性区描述符都存放在一个双向循环链表,该链表位于 address_space 对象的 i_mmap_nonlinear 字段。
为创建一个非线性内存映射,用户态进程首先以 mmap() 系统调用创建一个常规的共享内存映射。
然后调用 remap_file_pages() 来重写映射内存映射中的一些页。
sys_remap_file_pages() 服务例程参数:
- start,调用进程共享文件内存映射区域内的线性地址。
- size,文件重写映射部分的字节数。
- prot,未用(必须为 0)。
- pgoff,待映射文件初始页的页索引。
- flags,控制非线性映射的标志。
sys_remap_file_pages() 用线性地址 start、页索引 pgoff 和映射尺寸 size 所确定的文件数据部分进行重写映射。
如果线性区非共享或不能容纳要映射的所有页,则失败并返回错误码。
实际上,该服务例程把线性区插入文件的 i_mmap_nonlinear 链表,并调用该线性区的 populate 方法。
对于所有普通文件,populate 方法是由 filemap_populate() 实现的:
- 检查 remap_file_pages() 的 flags 参数中 MAP_NONBOCK 标志是否清 0。
如果是,则调用 do_page_cache_readahead() 预读待映射文件的页。 - 对重写映射的每一页:
a. 检查页描述符是否已在页高速缓存内,如果不在且 MAP_NONBLOCK 未置位,则从磁盘读入该页。
b. 如果页描述符在页高速缓存内,它将更新对应线性地址的页表项来指向该页框,并更新线性区描述符的页引用计数器。
c. 否则,如果没有在页高速缓存内找到该页描述符,它将文件页的偏移量存放在该线性地址对应的页表项的最高 32 位,并将页表项的 Present 位清 0、Dirty 位置位。
当处理请求调页错误时,handle_pte_fault() 检查页表项的 Present 和 Dirty 位。
如果它们的值对应一个非线性内存映射,则 handle_pte_falut() 调用 do_file_page() 从页表项的高位中取出所请求文件页的索引,然后,do_file_page() 调用线性区的 populate 方法从磁盘读入页并更新页表项本身。
因为非线性内存映射的内存页是按照相对于文件开始处的页索引存放在页高速缓存中,而不是按照相对于线性区开始处的索引存放的,所以非线性内存映射刷新到磁盘的方式与线性内存映射一样。
直接 I/O 传送
绕过了页高速缓存,在每次 I/O 直接传送中,内核对磁盘控制器进行编程,以便在应用程序的用户态地址空间中自缓存的页与磁盘之间直接传送数据。
当应用程序直接访问文件时,它以 O_DIRECT 标志置位的方式打开文件。
调用 open() 时,dentry_open() 检查打开文件的 address_space 对象是否已实现 direct_IO 方法,没有则返回错误码。
对一个已打开的文件也可由 fcntl() 的 F_SETFL 命令把 O_DIRECT 置位。
第一种情况中,应用程序对一个以 O_DIRECT 标志置位打开的文件调用 read()。
文件的 read 方法通常由 generic_file_read() 实现,它初始化 iovec 和 kiocb 描述符并调用 __genenric_file_aio_read()。
__genenric_file_aio_read() 检查 iovec 描述符描述的用户态缓冲区是否有效,文件的 O_DIRECT 标志是否置位。
当调用 read() 时,等效于:
if(filp->f_flags & O_DIRECT)
{
// 检查请求的字符数、文件指针的当前值是否大于文件大小
if(count == 0 || *ppos > file->f_mapping->host->i_size)
return 0;
// 1:io_vec 描述符中指定的用户态缓冲区号
// __generic_file_aio_read() 更新文件指针,设置对文件索引节点的访问时间戳,然后返回
retval = generic_file__direct_IO(READ, iocb, iov, **ppos, 1);
if(retval > 0)
*ppos += retval;
file_accessed(filp);
return retval;
}
对一个以 O_DIRECT 标志位打开的文件调用 write() 时,情况类似。
文件的 write 方法就是调用 generic_file_aio_write_nolock()。
函数检查 O_DIRECT 标志是否置位,如果置位,则调用 generic_file_direct_IO(),这次限定的是 WRITE 操作类型。
generic_file_direct_IO() 参数:
- rw,操作类型:READ 或 WRITE
- iocb,kiocb 描述符指针
- iov,iove 描述符数组指针
- offset,文件偏移量
- nr_segs,iov 数组中 iovec 描述符数
generic_file_direct_IO() :
- 从 kiocb 描述符的 ki_filp 字段得到文件对象的地址 file,从 file->f_mapping 字段得到 address_space 对象的地址 mapping。
- 如果操作类型为 WRITE,且一个或多个进程已创建了与文件的某个部分关联的内存映射,则调用 unmap_mapping_range() 取消文件所有页的内存映射。
如果任何取消映射的页所对应的页表项,其 Dirty 位置位,则确保它在页高速缓存内的相应页被标记为脏。 - 如果存于 mapping 的基树不为空(mapping->nrpages 大于 0),则调用 filemap_fdatawrite() 和 filemap_fdatawait() 刷新所有脏页到磁盘,并等待 I/O 操作结束。
- 调用 mapping 地址空间的 direct_IO 方法。
- 如果操作类型为 WRITE,则调用 invalidate_inode_pages2() 扫描 mapping 基树中的所有页并释放它们。
该函数同时也清空指向这些页的用户态表项。
大多数情况下,direct_IO 方法都是 __blockdev_direct_IO() 的封装函数:
对存放在相应块中要读或写的数据进行拆分,确定数据在磁盘上的位置,并添加一个或多个用于描述要进行的 I/O 操作的 bio 描述符。
数据将被 iov 数组中 iovec 描述符确定的用户态缓冲区读写。
调用 submit_bio() 将 bio 描述符提交给通用层。
通常,__blockdev_direct_IO() 不立即返回,而是等待所有的直接 I/O 传送都已完成才返回。
因此,一旦 read() 或 write() 返回,应用程序就可以访问含有文件数据的缓冲区。
异步 I/O
当用户态进程调用库函数读写文件时,一旦读写操作进入队列函数就结束。
甚至有可能真正的 I/O 数据传输还没开始。这样调用进程可在数据正在传输时继续自己的运行。
应用程序通过 open() 打开文件,然后用描述请求操作的信息填充 struct aiocb 类型的控制块。
struct aiocb 最常用的字段:
- aio_fildes,文件的文件描述符
- aio_buf,文件数据的用户态缓冲区
- aio_nbytes,待传输的字节数
- aio_offset,读写操作在文件中的起始位置
最后,应用程序将控制块地址传给 aio_read() 或 aio_write()。
一旦请求的 I/O 数据传输已由系统库或内核送进队列,这两个函数就结束。
应用程序可调用 aio_error() 检查正在运行的 I/O 操作的状态:
如果数据传输仍在进行,则返回 EINPROGRESS;完成则返回 0;失败则返回一个错误码。
aio_return() 返回已完成异步 I/O 操作的有效读写字节数;失败则返回 -1。
Linux 2.6 中的异步 I/O
异步 I/O 可由系统库实现而不完全需要内核支持。
Linux 2.6 内核版运用一组系统调用实现异步 I/O 。
异步 I/O 环境
如果一个用户态进程调用 io_submit() 开始异步 I/O 操作,它必须预先创建一个异步 I/O 环境。
基本上,一个异步 I/O 环境(简称 AIO 环境)就是一组数据结构,该数据结构用于跟踪进程请求的异步 I/O 操作的运行情况。
每个 AIO 环境与一个 kioctx 对象关联,kioctx 对象存放了与该环境有关的所有信息。
一个应用可创建多个 AIO 环境。
一个给定进程的所有 kioctx 描述符存放在一个单向链表中,该链表位于内存描述符的 ioctx_list 字段。
AIO 环是被 kioctx 对象使用的重要的数据结构。
AIO 环是用户态进程中地址空间的内存缓冲区,它可以由内核态的所有进程访问。
kioctx 对象的 ring_info.mmap_base 和 ring_info.mmap_size 字段分别存放 AIO 环的用户态起始地址和长度。
ring_info.ring_pages 字段存放一个数组指针,该数组存放含有 AIO 环的页框的描述符。
AIO 环实际上一个环形缓冲区,内核用它来写正运行的异步 I/O 操作的完成报告。
AIO 环的第一个字节有一个首部(struct aio_ring 数据结构),后面的所有字节是 io_event 数据结构,每个表示一个已完成的异步 I/O 操作。
因为 AIO 环的页映射到进程的用户态地址空间,应用可以直接检查正运行的异步 I/O 操作的情况,从而避免使用相对较慢的系统调用。
io_setup() 为调用进程创建一个新的 AIO 环境。
参数:正在运行的异步 I/O 操作是最大数目(确定 AIO 环的大小)和一个存放环境局部的变量指针(AIO 环的基地址)。
sys_io_setup() 服务例程实际上调用 do_mmap() 为进程分配一个存放 AIO 环的新匿名线性区,然后创建和初始化该 AIO 环境的 kioctx 对象。
io_destroy() 删除 AIO 环境和含有对应 AIO 环的匿名线性区。
该系统调用阻塞当前进程直到所有正在运行的异步 I/O 操作结束。
提交异步 I/O 操作
io_submit() 参数:
- ctx_id,由 io_setup()(标识 AIO 环境)返回的句柄
- iocbpp,iocb 类型描述符的指针数组的地址,每项元素描述一个异步 I/O 操作。
- nr,iocbpp 指向的数组的长度
iocb 数据结构与 POSIX aiocb 描述符有同样的字段 aio_fildes、aio_buf、aio_nbytes、aio_offset。
aio_lio_opcode 字段存放请求操作的类型(如 read、write 或 sync)。
sys_io_submit() 服务例程执行下列步骤:
- 验证 iocb 描述符数组的有效性。
- 在内存描述符的 ioctx_list 字段所对应的链表中查找 ctx_id 句柄对应的 kioctx 对象。
- 对数组中的每个 iocb 描述符,执行下列步骤:
a. 获得 aio_fildes 字段中的文件描述符对应的文件对象地址。
b. 为该 I/O 操作分配和初始化一个新的 kiocb 描述符。
c. 检查 AIO 环中是否有空闲位置来存放操作的完成情况。
d. 根据操作类型设置 kiocb 描述符的 ki_retry 方法。
e. 执行 aio_run_iocb(),实际上调用 ki_retry 方法为相应的异步 I/O 操作启动数据传输。
如果 ki_retry 方法返回 -EIOCBRETRY,则表示异步 I/O 操作已提交但还没有完全成功:
稍后在这个 kiocb 上,aio_run_iocb() 会被再次调用;
否则,调用 aio_complete() 为异步 I/O 操作在 AIO 环中追加完成事件。
如果异步 I/O 操作是一个读请求,那么对应 kiocb 描述符的 ki_retry 方法由 aio_pread() 实现。
该函数实际上执行文件对象的 aio_read 方法,然后按照 aio_read 方法的返回值更新 kiocb 描述符的 ki_buf 和 ki_left 字段。
最后,aio_pread() 返回从文件读入的有效字节数,或者,如果函数确定请求的字节没有传输完,则返回 -EIOCBRETRY。
对于大部分文件系统,文件对象的 aio_read 方法就是调用 __generic_file_aio_read()。
如果文件的 O_DIRECT 标志置位,函数就调用 generic_file_aio_read()。
但这种情况下,__blockdev_direct_IO() 不阻塞当前进程使之等待 I/O 数据传输完毕,而是立即返回。
因为异步 I/O 操作仍在运行,aio_run_iocb() 会被再次调用,调用者是 aio_wq 工作队列的 aio 内核线程。
kiocb 描述符跟踪 I/O 数据传输的运行。
所有数据传输完毕后,将完成结果追加到 AIO 环。
如果异步 I/O 操作是一个写请求,则对应 kiocb 描述符的 ki_retry 方法由 aio_pwrite() 实现。
该函数实际上执行文件对象的 aio_write 方法,然后按照 aio_write 方法的返回值更新 kiocb 描述符的 ki_buf 和 ki_left 字段。
最后 aio_pwrite() 返回写入文件的有效字节数,或者,如果函数确定请求的字节没有传输完,则返回 -EIOCBRETRY。
对于大部分文件系统,文件对象的 aio_write 方法就是调用 generic_file_aio_write_nolock()。
如果文件的 O_DIRECT 标志置位,就调用 generic_file_direct_IO()。