章节一:引言
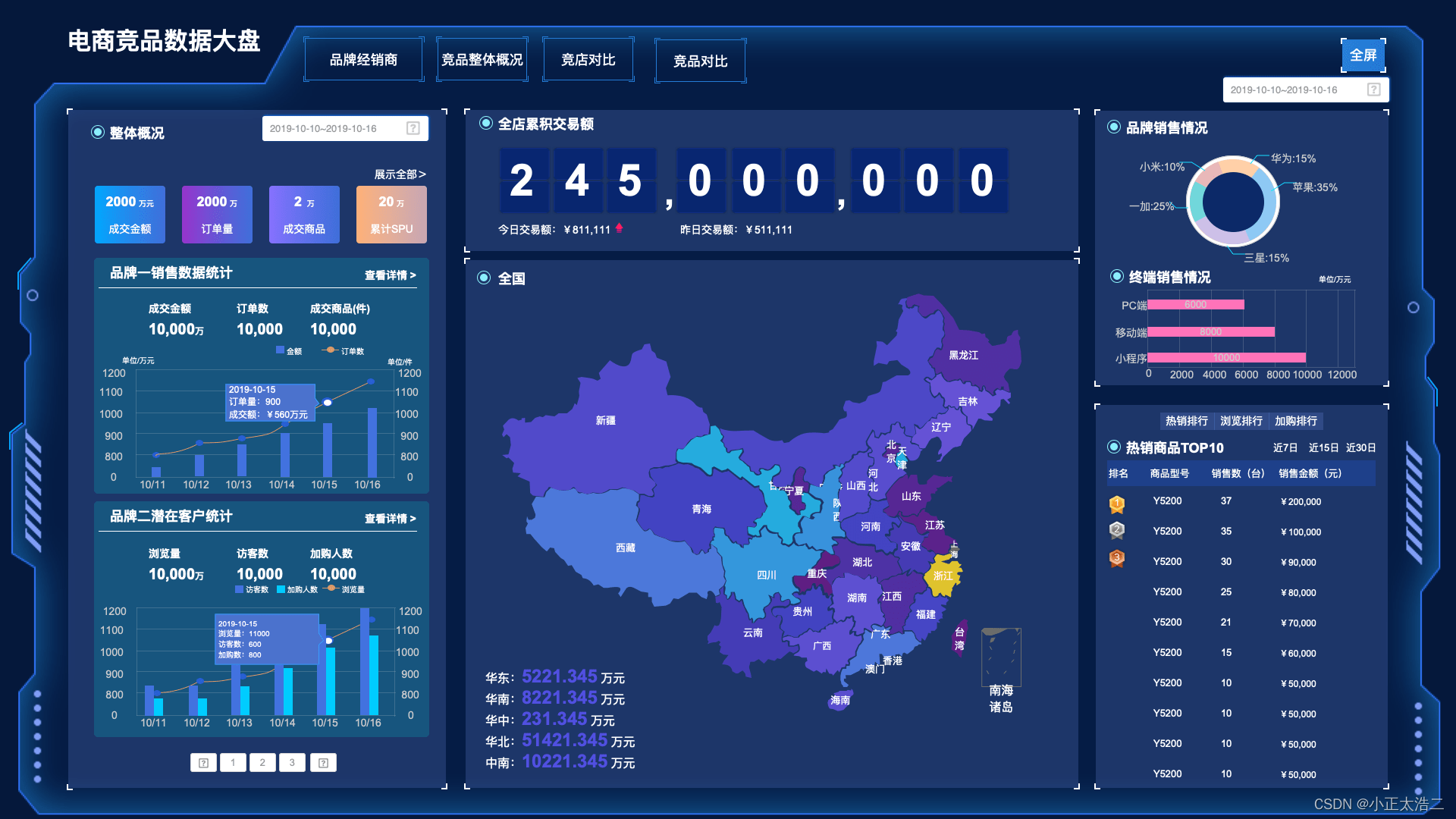
随着信息时代的不断发展,数据已经成为企业决策的重要支撑。而在大数据时代,海量的数据需要被整理、分析,以便为企业提供正确的指导。商业智能(BI)系统的兴起为企业提供了强大的数据分析能力,但要想在这个环境中获得准确、可靠的信息,数据治理变得尤为重要。
章节二:数据治理的重要性
数据治理是确保数据在整个生命周期内正确、安全、合规使用的过程。在BI环境中,数据治理不仅关乎数据的质量,还涉及到数据的可信度和可用性。一个良好的数据治理策略可以为企业带来以下益处:
准确的决策支持: 在BI环境中,决策是建立在数据分析的基础上的。如果数据不准确,决策也会受到影响。通过数据治理,可以保证数据的准确性,从而提供可靠的决策支持。
合规性与安全性: 数据治理可以确保数据在收集、存储、处理过程中符合法规和隐私要求。这对于避免法律风险以及维护客户信任至关重要。
数据可信度: 可信赖的数据可以增强用户对BI系统的信任度。通过数据治理,可以追踪数据来源、处理过程,并建立可信的数据传递链路。
章节三:数据治理的关键步骤
步骤一:数据收集和清洗
数据治理的第一步是确保数据从源头收集完整且准确。例如,考虑一个销售分析的BI系统,需要从不同的销售渠道收集数据。在这个阶段,数据清洗是不可或缺的步骤,以去除重复、不完整或错误的数据。
# 示例代码:数据清洗
import pandas as pd
# 读取原始数据
raw_data = pd.read_csv('sales_data.csv')
# 去除重复数据
deduplicated_data = raw_data.drop_duplicates()
# 填补缺失值
cleaned_data = deduplicated_data.fillna(0)
步骤二:数据标准化与分类
数据标准化是确保不同数据源之间可以进行有效比较和分析的关键步骤。例如,日期格式、单位等需要在整个系统中保持一致。
# 示例代码:数据标准化
cleaned_data['date'] = pd.to_datetime(cleaned_data['date'])
cleaned_data['revenue'] = cleaned_data['revenue'].apply(lambda x: x * 1000) # 统一单位为千元
步骤三:数据质量检测
数据质量检测涉及到验证数据的完整性、一致性和准确性。例如,检查数据是否存在异常值或逻辑错误。
# 示例代码:数据质量检测
data_quality_issues = cleaned_data[cleaned_data['revenue'] < 0]
if not data_quality_issues.empty:
raise ValueError("Negative revenue values found!")
章节四:技术案例:Apache Atlas在数据治理中的应用

Apache Atlas是一款开源的数据治理和元数据管理工具,可以帮助企业建立可信赖的BI环境。它可以跟踪数据流、数据关系,同时提供元数据管理和数据分类等功能。
例如,在一个大型零售企业的BI环境中,Apache Atlas可以帮助建立销售数据的元数据模型,标识数据表、字段以及数据关系。它还可以通过数据血缘功能追踪数据流,从销售数据的采集到最终的报表生成过程,保证数据的可信度和可溯源性。
章节五:结论
在当今竞争激烈的商业环境中,准确、可靠的数据分析是企业获得竞争优势的关键。通过建立数据治理策略,可以确保BI环境中的数据质量、可信度和合规性,为决策者提供可靠的信息支持。同时,开源工具如Apache Atlas为数据治理提供了强大的技术支持,使数据治理不再是一项难以实施的任务。让我们一起在数据的海洋中航行,打造可信赖的BI环境!