简介
论文:https://arxiv.org/abs/2103.02907
代码:https://github.com/Andrew-Qibin/CoordAttention

论文中,作者通过将位置信息嵌入到通道注意力中来为移动网络提出一种新的注意力机制,称之为“坐标注意力”。与通过 2D 全局池化将特征张量转换为单个特征向量的通道注意力不同,坐标注意力将通道注意力分解为两个一维特征编码过程,分别沿两个空间方向聚合特征。通过这种方式,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一个空间方向保留精确的位置信息。然后将得到的特征图单独编码成一对方向感知和位置敏感的注意力图,这些图可以互补地应用于输入特征图以增强感兴趣对象的表示。
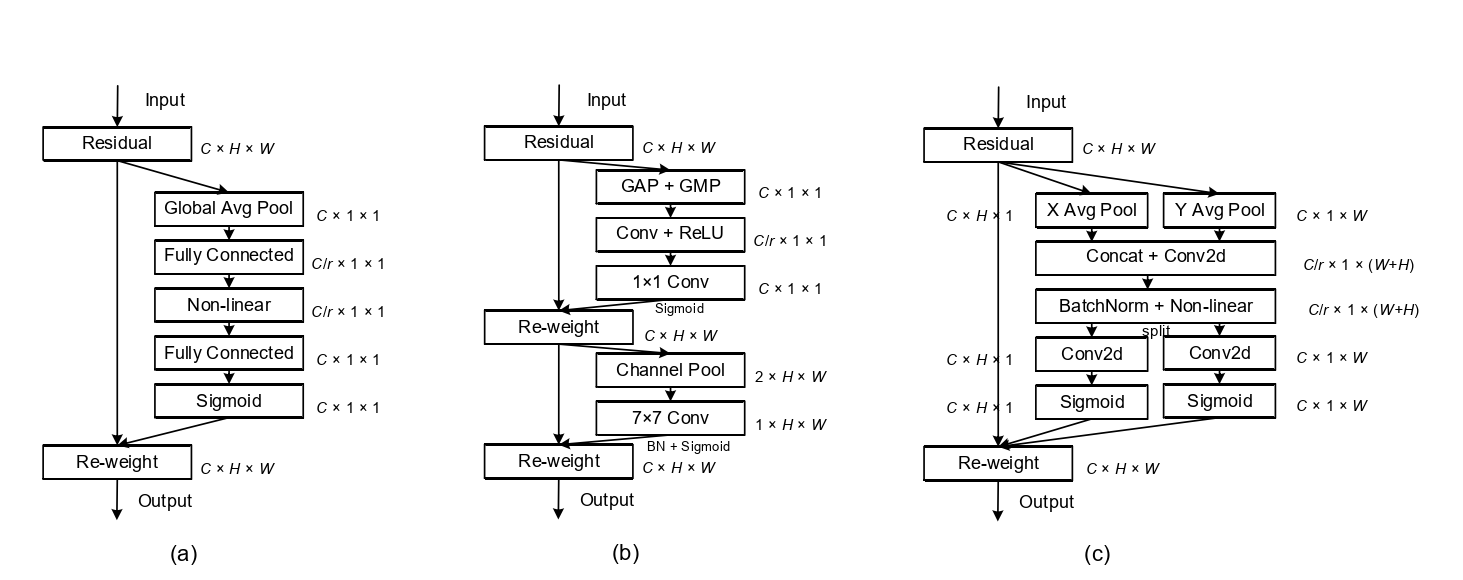
CA注意力机制的优势:
- 不仅考虑了通道信息,还考虑了方向相关的位置信息。
- 足够的灵活和轻量,能够简单的插入到轻量级网络的核心模块中。
提出不足:
- SE注意力中只关注构建通道之间的相互依赖关系,忽略了空间特征。
- CBAM中引入了大尺度的卷积核提取空间特征,但忽略了长程依赖问题。
step1: 为了避免空间信息全部压缩到通道中,这里没有使用全局平均池化。为了能够捕获具有精准位置信息的远程空间交互,对全局平均池化进行的分解。具体来说,给定输入X,我们使用两个空间范围的池化核( H , 1)或( 1 , W)分别沿水平坐标和垂直坐标对每个通道进行编码。因此,高度h处第c通道的输出可以表示为
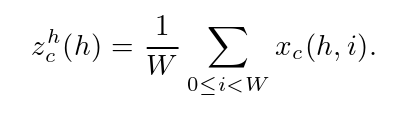
类似地,宽度为w的第c个通道的输出可以写为
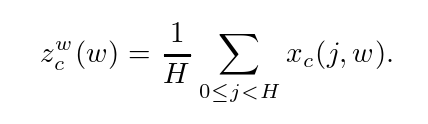
对尺寸为C ∗ H ∗ W 输入特征图Input分别按照X方向和Y方向进行池化,分别生成尺寸为C ∗ H ∗ 1 和C ∗ 1 ∗ C1W的特征图。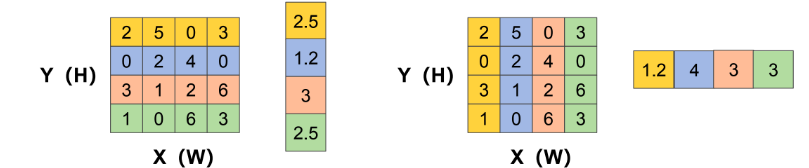
step2:具体来说,给定由式( 4 )和式( 5 )产生的聚合特征图,将zh和zw进行concat后生成如下图所示的特征图,然后进行F1操作(利用1*1卷积核进行降维,如SE注意力中操作)和激活操作,生成特征图
f ∈ RC/r×(H+W)×1。
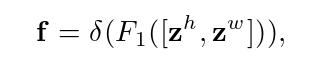


最后:Coordinate Attention 的输出公式可以写成:
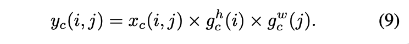
CA不仅考虑到空间和通道之间的关系,还考虑到长程依赖问题。通过实验发现,CA不仅可以实现精度提升,且参数量、计算量较少。
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
参考
https://blog.csdn.net/renxingshen2022/article/details/127919502