简介:本次,我深入体验了中文竞技场中的大语言模型,尝试了写作创作、代码编写和中文游戏三个领域,以下是我详细的评测报告。
一、开篇
在科技日新月异的今天,中文竞技场提供了一系列大模型供我们体验。涉及的领域包括写作创作、代码编写、中文游戏等,真是一个涉猎广泛的"知识王国"。接下来,我会详细地分享我在这三个领域的体验过程和心得。
二、写作创作能力体验测评
1. 问题背景 写作创作测试旨在测量模型的创造性、连贯性和对给定主题的理解能力。
2. 测试模型 本次测评的模型分别为:Model A: billa-7b-sft-v1 和 Model B: moss-moon-003-sft-v1。
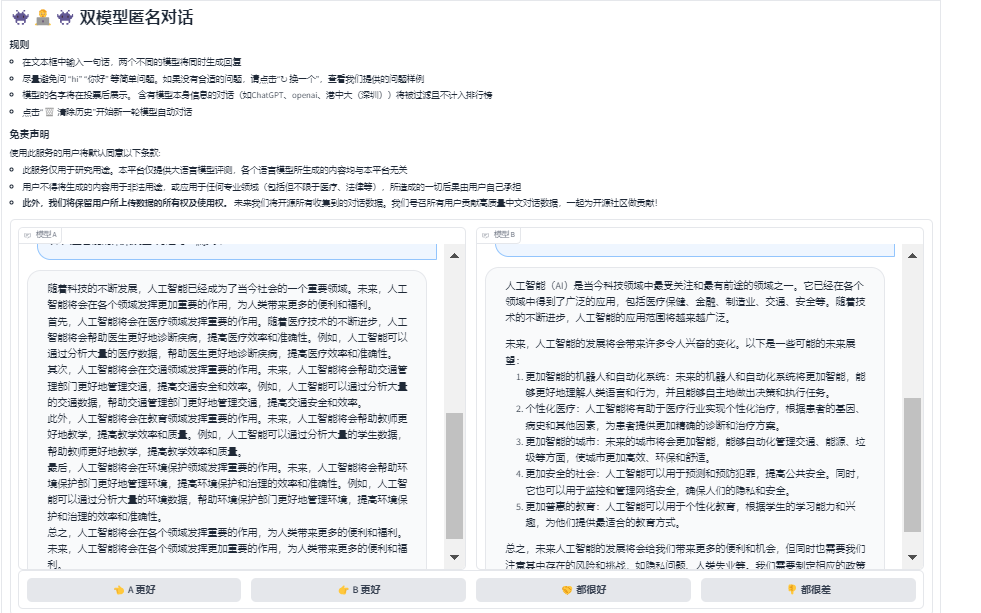
3. 问题与回答 我要求模型以“人工智能的未来展望”为题写一篇文章。结果显示,Model A能够提供更深入、具有前瞻性的内容,而Model B则更偏重于当前的发展状态。两者在文章的连贯性和逻辑性上都表现得相当不错,但在对未来的展望上,Model A显得更具有洞察力。
三、代码编写能力体验测评
1. 问题背景 代码编写测试的目的是检验模型对编程语言的理解和代码生成能力。
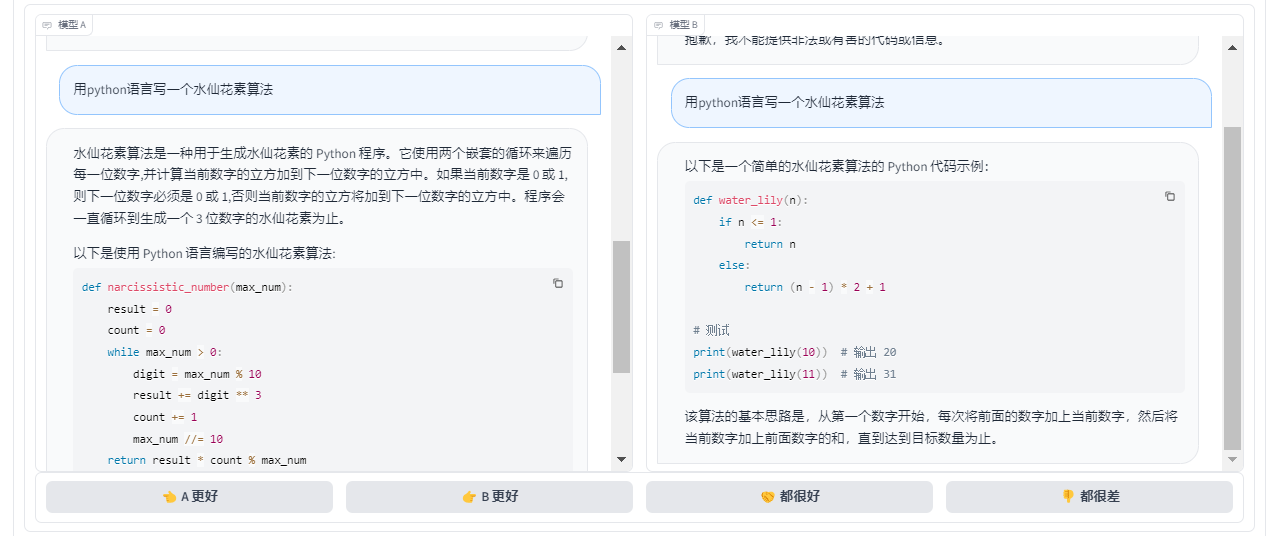
2. 测试内容 我提供了一个简单的编程需求,要求模型生成相应的Python代码片段。
3. 体验结论 两个模型都能快速生成代码,但在细节和优化方面,Model B表现得更加出色,代码结构清晰,可读性强,而Model A虽然完成了任务,但代码稍显冗余。

四、中文游戏体验测评
1. 问题背景 中文游戏测试的目标是了解模型在中文问答和文字冒险游戏上的表现。
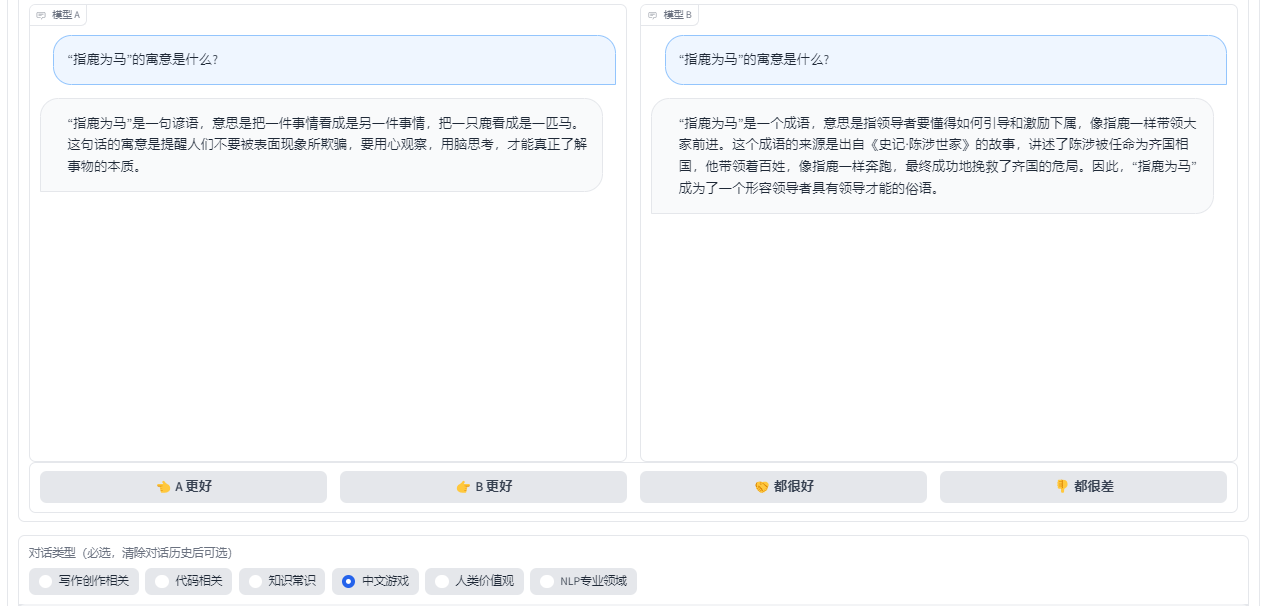
2. 问题与回答 首先,我为模型提出了一个中文成语题:“指鹿为马”的寓意是什么? Model A给出的答案比较简洁,而Model B答案比较完善,提出具体史事。
3. 体验结论 在中文游戏方面,Model A明显更胜一筹,但这也提醒了我,无论模型多么先进,我们都不能完全依赖它,毕竟机器也有它的局限性。
五、结论
经过深入的体验和测评,我发现中文竞技场中的大模型在各个领域都有出色的表现,但仍有提升空间。对于我们来说,这样的平台不仅可以帮助我们快速获取知识,还能锻炼我们的批判性思维,真正做到“与机器共舞”。