Unity C# 之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
目录
Unity C# 之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
一、简单介绍
Unity中的一些知识点整理。
本节简单介绍在Unity开发中的,使用 HttpClient,获取指定网页的相关信息,然后进行数据清洗,去掉html 格式,以及标签,函数,多余的空格等信息,仅留下和网页显示差不多的文字信息,为什么这么做呢,其实这里一个使用场景是把网页数据喂给GPT,然后让 GPT 进行处理总结,如果你有新的方式也可以留言,多谢。
二、实现原理
1、HttpClient 获取指定网页的 html 数据
2、使用 HtmlAgilityPack 进行 html 的数据进行 去除所有的<script>标签及其内容,获取纯文本内容,最后再去除多余的空格和空行
三、注意事项
1、直接代码访问网页,最好添加上 User-Agent,不然,可能不能正常访问
2、注意 NuGet 安装 HtmlAgilityPack 包
四、效果预览


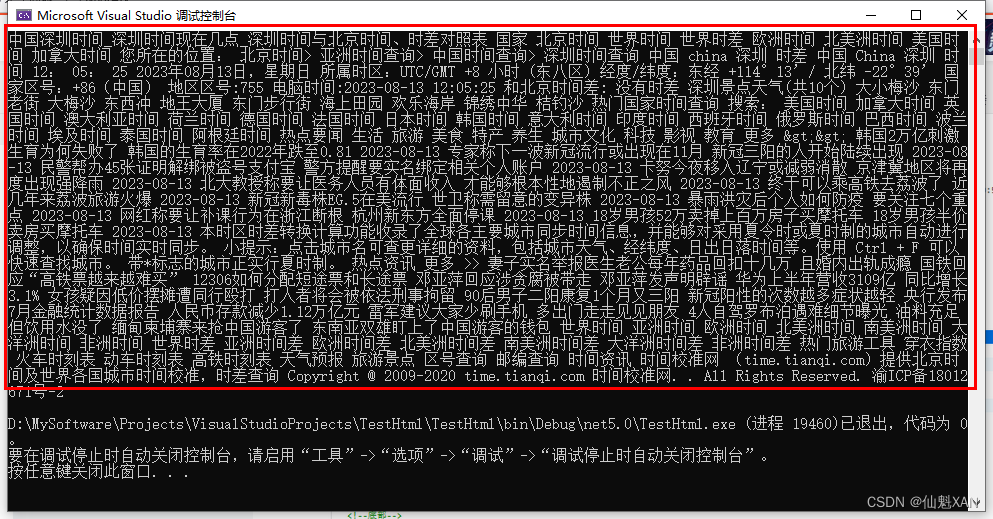
五、关键代码
using HtmlAgilityPack;
using System;
using System.Linq;
using System.Net.Http;
using System.Text.RegularExpressions;
namespace TestHtml
{
class Program
{
static async System.Threading.Tasks.Task Main(string[] args)
{
//string url = "https://movie.douban.com/chart";
//string url = "http://www.weather.com.cn/";
//string url = "https://movie.douban.com/";
//string url = "http://time.tianqi.com/";
string url = "http://time.tianqi.com/shenzhen/";
string htmlContent = @"
<html>
<head>
<title>Sample Page</title>
<script>
function myFunction() {
alert(""Hello!"");
}
</script>
</head>
<body>
<h1>Welcome to My Page</h1>
<p>This is a sample page with some content.</p>
</body>
</html>";
using (HttpClient client = new HttpClient())
{
// 设置请求头以模拟浏览器访问
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
// 访问网页并获取HTML内容
htmlContent = await client.GetStringAsync(url);
// 输出获取的HTML内容
//Console.WriteLine(htmlContent);
}
// 创建HtmlDocument对象并加载HTML内容
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(htmlContent);
// 去除所有的<script>标签及其内容
foreach (var script in doc.DocumentNode.DescendantsAndSelf("script").ToArray())
{
script.Remove();
}
// 获取纯文本内容
string text = doc.DocumentNode.InnerText;
// 去除多余的空格和空行
text = Regex.Replace(text, @"\s+", " ").Trim();
// 输出展示内容
Console.WriteLine(text);
}
}
}