文章目录
前言
在信息时代的浪潮中,前端开发行业迅猛发展,新技术、新工具和新框架层出不穷。作为一名前端开发者,我们需要不断地学习新知识、掌握新技能,以便在激烈的市场竞争中立于不败之地。而数据结构作为计算机科学的核心知识领域,学习它能够提高我们的核心竞争力。
一、什么是数据结构
我们可以从两个方面来分析
民间定义:
数据结构是数据对象,以及存在于该对象的实例和组成实例的数据元素之间的各种联系。这些联系可以通过定义相关的函数来给出。”
—《数据结构、算法与应用》
从自己角度认识:
数据结构是一组数据的组织方式,以便更有效地进行操作和检索。
二、常见的数据结构
1.数组(Array)
数组(Array)是一种线性数据结构,用于储存具有相同类型的数据元素,几乎所有的编程语言都原生支持数组类型。数组通常情况下用于存储一系列同一种数据类型的值。 但JavaScript 里,数组中可以保存不同类型的值。
2.栈(Stack)
栈(Stack)是一种后进先出的数据结构,通常用于实现函数调用、表达式求值和其他遵循后进先出原则的操作。栈在计算机科学中有着广泛的应用,因为它们能够帮助我们解决许多实际问题。
栈的特点:
- 只允许在栈顶进行插入和删除操作。
- 数据结构的最后一个元素是栈顶(top),最先进入栈的元素位于栈底(bottom)。
- 当进行插入或删除操作时,栈顶的元素始终保持在最后被插入或删除的位置。
- 栈具有先进后出(FILO)的特性,即最后进入栈的元素最先被访问和删除。
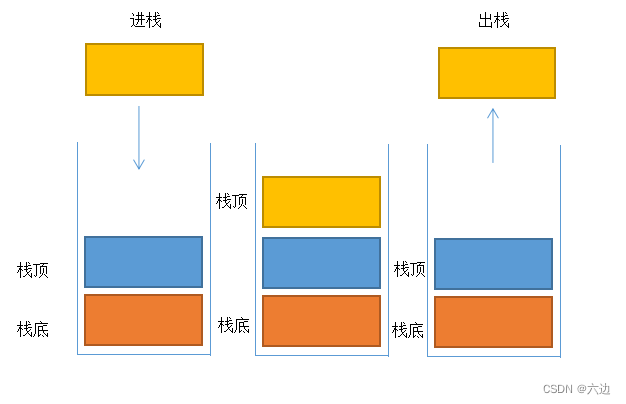
栈可以用多种数据结构实现,如数组、链表、静态数组或动态数组等。选择哪种实现取决于应用场景和性能要求。
栈的一些常见操作包括:
- 压栈(push):将元素添加到栈顶。
- 弹栈(pop):从栈顶删除元素。
- 取栈顶元素(peek):返回栈顶元素,但不删除它。
- 判断栈是否为空(isEmpty):检查栈是否为空。
- 获取栈的大小(size):返回栈中元素的数量。
3.队列(Queue)
队列(Queue)是一种先进先出的数据结构,通常用于实现任务调度、工作队列和其他遵循先进先出原则的操作。
队列的一些特点:
- 允许在队列的一端进行插入(enqueue,入队)操作,另一端进行删除(dequeue,出队)操作。
- 队列中的第一个元素位于队列的开头,最先进入队列的元素位于队列的末尾。
- 当进行插入或删除操作时,队列头部的元素始终保持在最先被插入或删除的位置。
- 队列具有先进先出(FIFO)的特性,即最先进入队列的元素最先被访问和删除。
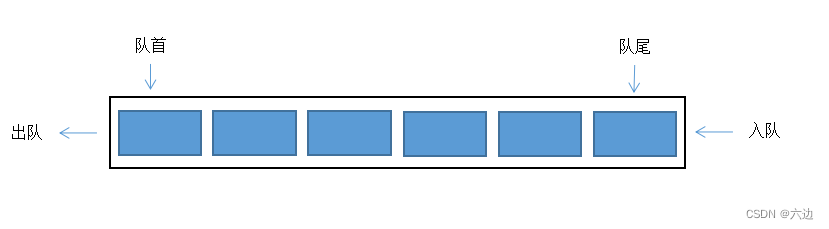
队列的一些常见操作包括:
- 入队(enqueue):将元素添加到队列的末尾。
- 出队(dequeue):从队列的开头删除元素。
- 取队头元素(front):返回队列头部的元素,但不删除它。
- 判断队列是否为空(isEmpty):检查队列是否为空。
- 获取队列的大小(size):返回队列中元素的数量。
4.优先队列(Heap)
优先队列(PriorityQueue)又称为堆,它是一种特殊的队列,其元素根据特定的优先级进行排序和访问。优先队列具有先进先出(FIFO)的特性,但是每次访问元素时,具有最高优先级的元素将被首先访问。这使得优先队列非常适用于解决具有优先级要求的任务调度问题。
生活中类似优先队列的场景:
● 优先排队的人,优先处理。 (买票、结账)。
● 排队中,有紧急情况(特殊情况)的人可优先处理。
优先队列具有以下特性:
- 先进先出(FIFO):元素按照进入队列的顺序进行访问和删除。
- 优先级:每个元素都有一个优先级,元素按照优先级进行排序。具有最高优先级的元素将首先被访问。
- 插入操作:插入元素时,需要根据元素的优先级确定元素在队列中的位置。
- 删除操作:删除元素时,需要根据元素的优先级找到并删除具有最高优先级的元素。
在编程中,优先队列通常用于实现任务调度、网络流量控制、优先级数据结构等。了解和掌握优先队列的基本操作和应用场景对于编写高效的程序非常重要。
5.链表(Linked List)
链表(Linked List)是一种动态数据结构,由节点(Node)组成,每个节点包含数据(value)和指向下一个节点的指针(next)。链表可以是有向的或无向的,可以是完全的、部分的或双向的。链表可以在需要时动态地添加或删除元素,因此它在实际编程中非常有用。
链表又分为单向链表与双向链表
5.1单向链表
单向链表(Singly LinkedList)是链表的一种简单形式,其中每个节点包含数据(value)和指向下一个节点的指针(next)。单向链表只能从一个方向遍历,即只能从链表的头部访问到链表的尾部。
以下是单向链表的一些特点:
- 链表中的节点通过指针连接,每个节点包含数据和指向下一个节点的指针。
- 链表的最后一个节点的指针为空(null),表示链表的结尾。
- 链表的第一个节点没有直接前驱指针(prev),表示链表的开头。
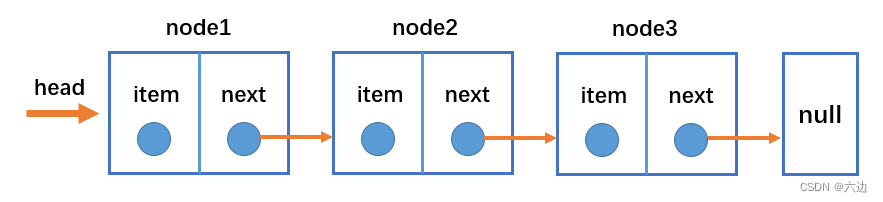
在单向链表中进行插入和删除操作时,需要修改相应节点的前驱指针和后继指针。例如,向链表的中间插入一个元素时,需要先找到要插入位置的前一个节点,然后修改其后继指针。
5.2双向链表
双向链表(Doubly LinkedList)是链表的一种,其中每个节点包含数据(value)、一个指向前驱节点的指针(prev)和一个指向后继节点的指针(next)。与单向链表不同,双向链表可以在链表的任何位置访问和操作,而不仅仅是开头或结尾。
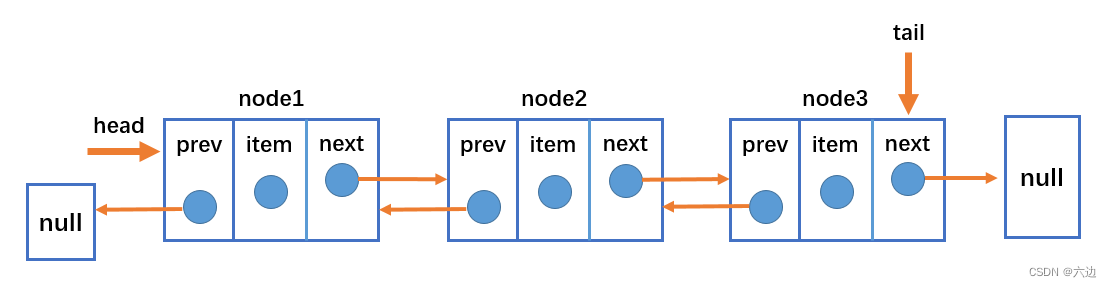
双向链表的一些特点:
- 链表中的节点通过指针连接,每个节点包含数据、指向前驱节点的指针(prev)和指向后继节点的指针(next)。
- 链表的最后一个节点的指针为空(null),表示链表的结尾。
- 链表的第一个节点没有直接前驱指针(prev),表示链表的开头。
- 由于具有两个指针,双向链表在插入和删除操作时比单向链表更高效。
在双向链表中进行插入和删除操作时,只需要修改相应节点的前驱指针和后继指针,而不需要像单向链表那样在整个链表中查找相应的前驱节点。
6.哈希表(Hash)
哈希表(HashTable)是一种基于键值(key-value)存储的数据结构,它可以快速地进行增删查改操作。哈希表的核心思想是通过哈希函数将键(key)映射到一个固定的哈希地址(hashaddress),然后根据哈希地址进行数据访问。哈希表通常在实现字典(dictionary)、关联数组(associativearray)和映射(map)等数据结构时使用。
哈希表通常是基于数组实现的,但是相对于数组,它存在更多优势:
● 哈希表可以提供非常快速的 插入-删除-查找 操作。
● 无论多少数据,插入和删除值都只需接近常量的时间,即 O(1) 的时间复杂度。实际上,只需要几个机器指令即可完成。
● 哈希表的速度比树还要快,基本可以瞬间查找到想要的元素。
● 哈希表相对于树来说编码要简单得多。
哈希表同样存在不足之处:
● 哈希表中的数据是没有顺序的,所以不能以一种固定的方式(比如从小到大 )来遍历其中的元素。
● 通常情况下,哈希表中的 key 是不允许重复的,不能放置相同的 key,用于保存不同的元素。
6.1 哈希表的一些概念
-
哈希化将大数字转化成数组范围内下标的过程,称之为哈希化。
-
哈希函数我们通常会将单词转化成大数字,把大数字进行哈希化的代码实现放在一个函数中,该函数就称为哈希函数。
-
哈希表对最终数据插入的数组进行整个结构的封装,得到的就是哈希表。
6.2 地址的冲突
链地址法(Separate Chaining)和开放地址法(Open Addressing)是两种常用的冲突解决策略,用于在哈希表中解决键值映射时产生的冲突。在哈希表中,当多个键映射到相同的哈希地址时,就会发生冲突。冲突解决策略的目标是将冲突的键值对组织起来,以便在需要时能够快速地访问和更新。
解决冲突常见的两种方案:链地址法(拉链法)和开放地址法。
1.链地址法(拉链法)
链地址法是一种基于链表的冲突解决策略。在哈希表中,每个哈希地址被看作是一个桶(bucket),每个桶包含一个链表。当多个键映射到相同的哈希地址时,这些键值对将被添加到对应的链表中。链地址法的优点是可以充分利用哈希表的空间,适用于具有较高冲突概率的场景。但是,链地址法的缺点是插入和删除操作的时间复杂度为O(n),当哈希表中的元素较多时,性能较低。
2.开放地址法
开放地址法是一种基于线性探测、二次探测或双哈希等技术的冲突解决策略。在哈希表中,当多个键映射到相同的哈希地址时,可以通过寻找下一个空的哈希地址来避免冲突。开放地址法的优点是插入和删除操作的时间复杂度为O(1),适用于具有较高冲突概率的场景。但是,开放地址法的缺点是哈希表的空间利用率较低,可能会浪费一部分空间。
7.树(Tree)
树(Tree)是一种非线性数据结构,由节点(node)和边(edge)组成。树形数据结构在计算机科学中有广泛的应用,如表示组织结构、表示文件系统、表示二叉搜索树等。
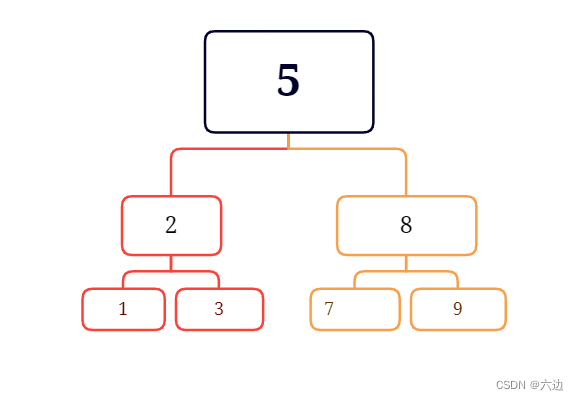
树的主要特点包括:
- 每个节点可以有零个或多个子节点,没有子节点的节点称为根节点(root)。
- 树形结构具有层次关系,从根节点到每个叶子节点的路径表示一种特定的关系。
- 树形数据结构中的边没有方向,只是用于连接相邻的节点。
根据子节点数量的不同,树可以分为以下几种基本类型:
- 无子节点的节点称为叶节点(leaf)。
- 只有一个子节点的节点称为度为1的节点(degree-1 node)。
- 有两个子节点的节点称为度为2的节点(degree-2 node)。
- 树的度是所有节点度数之和。
- 树的深度是指从根节点到叶子节点所经过的边的数量。
8.图(Graph)
图(Graph)是一种由顶点(vertex)和边(edge)组成的非线性数据结构,用于表示现实世界中的各种关系。
图的特点:
- 一组顶点:通常用 V (Vertex) 表示顶点的集合
- 一组边:通常用 E (Edge) 表示边的集合
- 边是顶点和顶点之间的连线
- 边可以是有向的,也可以是无向的。(比如 A — B,通常表示无向。 A --> B,通常表示有向)
图的应用非常广泛,包括网络分析、交通规划、社交网络、物流网络等。在编程中,图通常用于表示和处理各种复杂的关系和结构,以便于解决实际问题。图的常见实现方法有邻接表、邻接矩阵和堆等。
总结
在本文中,我们从介绍了多种数据结构,但都只是简单的介绍了一下它,后续会单独讲解各个数据结构并且使用javaSript去实现它,如果你期待后续的文章话那请关注我吧!
数据结构是计算机科学的基石,它们为我们提供了一种组织和操作数据的有效方法。通过学习不同类型的数据结构,我们能够更高效地解决实际问题,提高计算机系统的性能。希望这篇文章能够激发您对数据结构的兴趣,并引导您在学习和实践过程中不断探索和进步。