MobileViT注意力机制
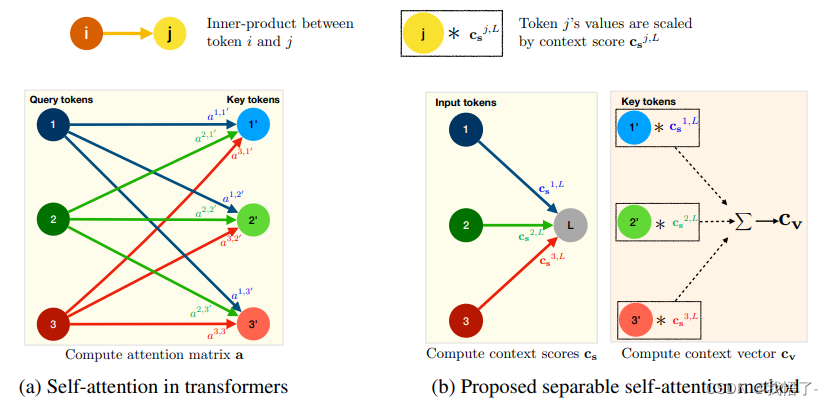
MobileViT注意力机制是MobileViTv2中提出的一种可分离自注意力机制,是一种基于ViT(Vision Transformer)模型的移动端视觉注意力模型。该注意力机制主要是基于ViT中的MHA多头自注意力机制的改进。MobileViT注意力具有 O(k) 复杂度,用于解决Transformer中 MHA 的时间复杂度和延迟瓶颈。为了进行有效推理,MobileViT注意力将 MHA 中计算量大的操作(例如,批矩阵乘法)替换为元素操作(例如,求和和乘法),从而使其成为资源受限设备的解决方法。
论文地址:https://arxiv.org/pdf/2206.02680.pdf
代码如下:
from torch import nn
import torch
from einops import rearrange
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.ln = nn.LayerNorm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.ln(x), **kwargs)
class FeedForward(nn.Module):
def __init__(self, dim, mlp_dim, dropout):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, mlp_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class Attention(nn.Module):
def __init__(self, dim, heads, head_dim, dropout):
super().__init__()
inner_dim = heads * head_dim
project_out = not (heads == 1 and head_dim == dim)
self.heads = heads
self.scale = head_dim ** -0.5
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(t, 'b p n (h d) -> b p h n d', h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b p h n d -> b p n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, head_dim, mlp_dim, dropout=0.):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim, Attention(dim, heads, head_dim, dropout)),
PreNorm(dim, FeedForward(dim, mlp_dim, dropout))
]))
def forward(self, x):
out = x
for att, ffn in self.layers:
out = out + att(out)
out = out + ffn(out)
return out
class MobileViTAttention(nn.Module):
def __init__(self, in_channel=3, dim=512, kernel_size=3, patch_size=7):
super().__init__()
self.ph, self.pw = patch_size, patch_size
self.conv1 = nn.Conv2d(in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2)
self.conv2 = nn.Conv2d(in_channel, dim, kernel_size=1)
self.trans = Transformer(dim=dim, depth=3, heads=8, head_dim=64, mlp_dim=1024)
self.conv3 = nn.Conv2d(dim, in_channel, kernel_size=1)
self.conv4 = nn.Conv2d(2 * in_channel, in_channel, kernel_size=kernel_size, padding=kernel_size // 2)
def forward(self, x):
y = x.clone() # bs,c,h,w
## Local Representation
y = self.conv2(self.conv1(x)) # bs,dim,h,w
## Global Representation
_, _, h, w = y.shape
y = rearrange(y, 'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim', ph=self.ph, pw=self.pw) # bs,h,w,dim
y = self.trans(y)
y = rearrange(y, 'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)', ph=self.ph, pw=self.pw, nh=h // self.ph,
nw=w // self.pw) # bs,dim,h,w
## Fusion
y = self.conv3(y) # bs,dim,h,w
y = torch.cat([x, y], 1) # bs,2*dim,h,w
y = self.conv4(y) # bs,c,h,w
return y
if __name__ == '__main__':
m = MobileViTAttention(in_channel=512)
input = torch.randn(1, 512, 49, 49)
output = m(input)
print(output.shape)