Triplet注意力机制
轻量且有效的Triplet注意力机制是一种用于计算机视觉和自然语言处理任务的注意力机制。它通过比较一个查询样本与正样本和负样本之间的相似性来学习样本之间的关系。
在Triplet注意力机制中,每个样本由三个部分组成:查询样本、正样本和负样本。查询样本是我们要关注的样本,正样本是与查询样本相似的样本,而负样本是与查询样本不相似的样本。
Triplet注意力机制的目标是通过比较查询样本与正样本之间的相似性,同时与负样本之间的差异性,来学习到更好的特征表示。这种注意力机制可以用于训练深度神经网络模型,如Siamese网络或Triplet网络,以实现任务如人脸识别、图像检索和文本相似度计算等。
更多内容参考原文链接:https://arxiv.org/pdf/2010.03045.pdf
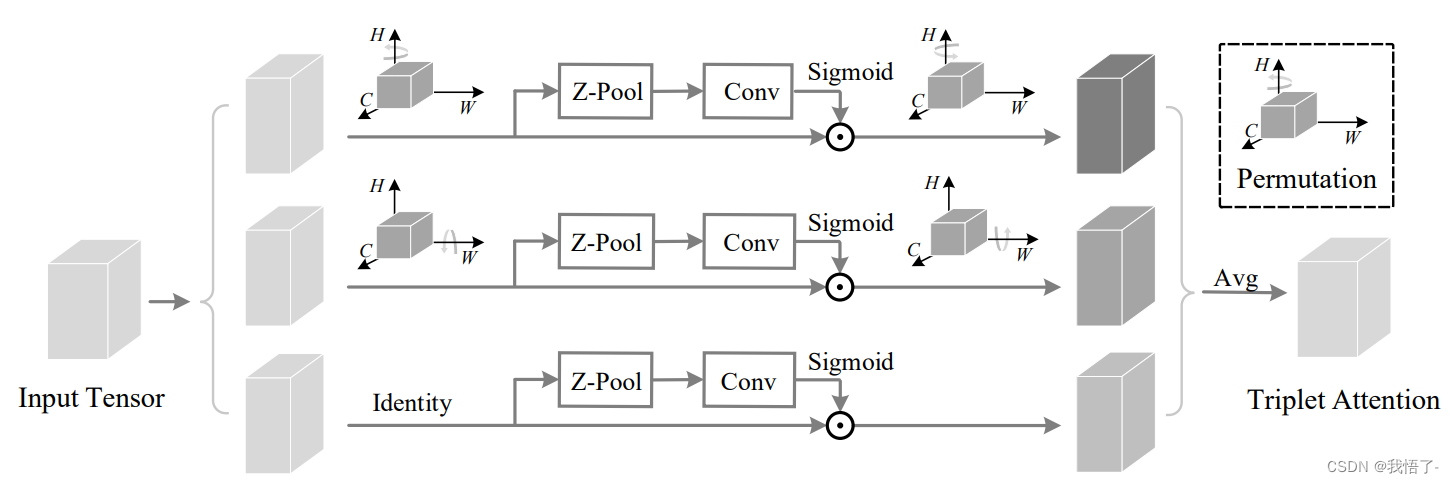
代码如下:
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True,
bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,
dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial = no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0, 2, 1, 3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0, 2, 1, 3).contiguous()
x_perm2 = x.permute(0, 3, 2, 1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0, 3, 2, 1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1 / 3 * (x_out + x_out11 + x_out21)
else:
x_out = 1 / 2 * (x_out11 + x_out21)
return x_out
if __name__ == '__main__':
input = torch.randn(50, 512, 7, 7)
triplet = TripletAttention()
output = triplet(input)
print(output.shape)