概述:
HashMap 是我们平常项目中经常使用到的集合之一,它存储的是键值对,采用的是 数组 + 链表 + 红黑树的数据结构(详细可看我之前写的一篇关于HashMap的源码的博客),存储的数据是无序的,但是如果我们项目中需要用到有序的HashMap,那么我们可以使用LinkedHashMap,使用归使用, 但是LinkedHashMap 为什么是有序的呢? 接下来就让我们通过源码来回答这问题。
注:本文使用的是JDK 1.8,主要是解析LinkedHashMap为什么有序相关的源码
源码解析:
一、LinkedHashMap的数据结构
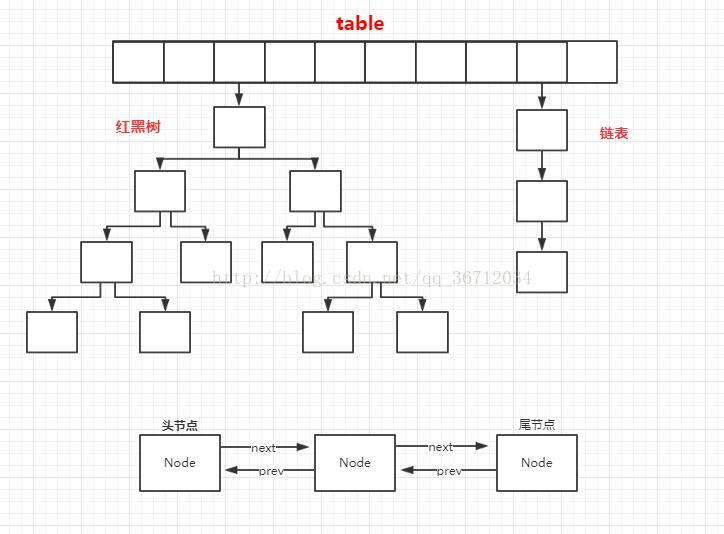
如图,上面的table部分是在父类HashMap中实现的,下面那部分是链表的数据结构,LinkedHashMap之所以能够有序,也是因为它比 HashMap 多了个链表来存储数据的原因。
二、LinkedHashMap 的属性、构造方法等
1. 属性
/**
* 链表的头节点
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 链表的尾节点
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* accessOrder为true的话,LinkHashMap中的顺序是最近一次获取的节点放在链表的尾部
* accessOrder为false的话,LinkHashMap中的顺序跟插入顺序一样
*/
final boolean accessOrder;
如上代码,LinkedHashMap 比 HashMap 多了三个属性,其中 head 和 tail 和 LinkedList 头结点和尾节点一样,存放链表的头结点和尾节点的数据,而 accessOrder 则决定LinkedHashMap的排序的方式,这个具体下面会通过源码来解析。
2. 构造方法
/**
* 带初始化容量和加载因子
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
/**
* 带初始化容量
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
/**
* 空参数构造方法
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
/**
* 传入map赋值
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
// 调用HashMap的方法存入数据
putMapEntries(m, false);
}
/**
* 带初始化容量和加载因子,还有排序的方式
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
LinkedHashMap 的构造方法基本都是调用父类 HashMap 的构造方法来进行初始化, 前面4个构造方法都是默认给accessOrder 赋值为false,也就是按照插入顺序来排序的,而最后一个方法可以通过传入 accessOrder 来决定使用哪种方式排序。
3. 存放数据的内部类
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
上面代码是 LinkedHashMap 用来存放数据的 Entry,它继承于 HashMap 中的内部类 Node,多增加了 before 属性和 after 属性,用来存当前节点的上一个节点和下一个节点。
三、LinkedHashMap 两种排序
1. 按插入顺序排序(当 accessOrder = false)
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
// 将节点放到链表的尾部
linkNodeLast(p);
return p;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
// 将节点放到链表的尾部
linkNodeLast(p); return p;
}
在上面我们说到 HashMap 中使用 数组 + 链表 + 红黑树 的数据结构,在 HashMap中如果链表的长度超过8个就会转换成红黑树,所以就存在两个创建节点的方法,分别是 创建链表节点的 newNode() 和 创建树节点的 newTreeNode 方法, 而 LinkedHashMap 重写了这两个方法,在创建节点后调用 linkNodeLast方法,将节点的数据也存到自身链表中去。下面是 linkNodeLast 方法的源码。
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
// 获取当前链表的尾部节点
LinkedHashMap.Entry<K,V> last = tail;
// 将尾部节点赋值为 p
tail = p;
// 如果之前的尾部为空,说明链表为空,所以将头部也赋值为 p
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
2. 按最近获取的数据倒序(当 accessOrder = true)
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
即使 accessOrder 为 true,LinkedHashMap 中的顺序一开始还是插入的顺序,只有获取元素的时候才会去调用 afterNodeAccess 方法将刚获取的元素放到链表的尾部,下面是 afterNodeAccess方法的源码。
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果 accessOrder 为true,并且当前获取的节点不是尾部,将将节点移到尾部
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
总结:
LinkedHashMap 的第二种排序方式是我们在开发中比较少使用,笔者也是看了源码才知道有这种排序,以前也没有发现,不过利用这种排序我们可以实现一个简单的LRU(least recently used 最近最少使用)。