一、n元模型
1.语言建模:根据给定的语言样本估计概率P(s)的过程
2.语言模型:根据语言样本估计出的概率分布P称为语言L的语言模型。
3.马尔科夫假设:词wi 的出现只与其前n-1个词有关
4.n元组(n-gram):只需要考虑n个词组成的片段。(n越大,模型需要的参数越多,历史信息越多,模型越准确)
5.如何建立n元模型:确定训练语料、对预料进行分词、句子边界标记,增加两个特殊词。建立n元模型的方法:(1)相对频率法(2)最大似然估计
6.数据稀疏问题:由于训练样本不足而导致所估计的分布不可靠的问题。
7.Zipf 定律: 词频和序号之间的关系: 针对给定的语料库,若某个词w的词频是f,且该词在词频表中的序号为r,则f x r = k 且 k (大致)是一个常数
8.MLE估计值不是理想的参数估计值的解决办法:平滑
二、数据平滑:
① 把在训练语料中出现过的n元组的概率适当减小
② 把减小所得到的概率质量分配给训练语料中没有出现过的n元组
1.Add-one平滑:规定n元组比真实出现次数多一次,
2.加法平滑:训练语料中未出现的n元组的概率不再为0,而是一个大于0的较小的概率值,不是加1,而是加一个小于1的正数
3.留存估计:把训练语料分作两个部分
– 训练语料(training set): 用于初始的频率估计
– 留存语料(held out data): 用于改善最初的频率估计
4.删除估计
如果有很多训练语料的话,可以使用留存估计
如果训练语料不多的话,可以…
– 把训练语料分成两个部分 part 0 和 part 1
– part 0 作为训练语料, part 1 作为留存语料建模
– part 1 作为训练语料, part 0 作为留存语料建模
– 对两个模型加权平均,求得最后的模型
5. Good Turing平滑
把出现n+1次的n元组所拥有的概率质量整体分配给出r次的n元组
① 把出现1次的n元组的概率质量分给出现0次的n元组
② 把出现2次的n元组的概率质量分给出现1次的n元组
组合使用Turing估计值和Good-Turing估计值
低频段尽量使用Turing估计值,高频段使用GoodTuring估计值
6.组合估计:高阶n元组的概率估值参考低阶n元组的概率估值。
组合模型:把不同阶别的n元组模型组合起来。
7.插值平滑:不同阶别的n元模型线形加权组合。
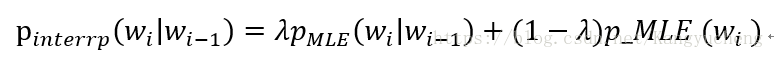
8.Jelinek-Mercer平滑:
简单线形插值平滑,权值λ固定不变,不管高阶模型估计值是否可靠,低阶模型均以同样的权重被加入模型,不合理。
– 若高阶模型可靠,λ应该大
– 若高阶模型不可靠,λ应该小
9.回退模型:在高阶模型可靠时,尽可能使用高阶模型。必要时,使用低阶模型
10.Katz平滑:是一种回退平滑模型。

三、熵
1.熵:设X是取有限个值的随机变量,若其概率分布为p(x),且x∈X,则X的熵定义为:

通常a=2.
熵描述了随机变量的不确定性,熵描述了随机变量的平均信息量。
2.相对熵:设p(x)是随机变量X的真实分布密度,q(x)是通过统计手段得
到的X近似分布,则二者间相对熵定义为:
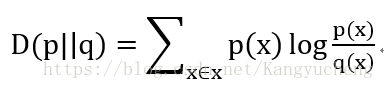
相对熵描述同一个随机变量的不同分布的差异,相对熵描述了因为错用分布密度而增加的信息量
3.交叉熵:设随机变量X的分布密度为p(x),q(x)是通过统计手段得
到的X的近似分布,则随机变量X的交叉熵定义为:
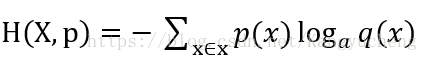
交叉熵用于比较两个近似的分布,交叉熵小的,是更好的近似分布。
4.三者关系:
