西风 发自 凹非寺 量子位 | 公众号 QbitAI
字节大模型,BuboGPT来了。
支持文本、图像、音频三种模态,做到细粒度的多模态联合理解。
答哪指哪,什么讲了什么没讲,一目了然:
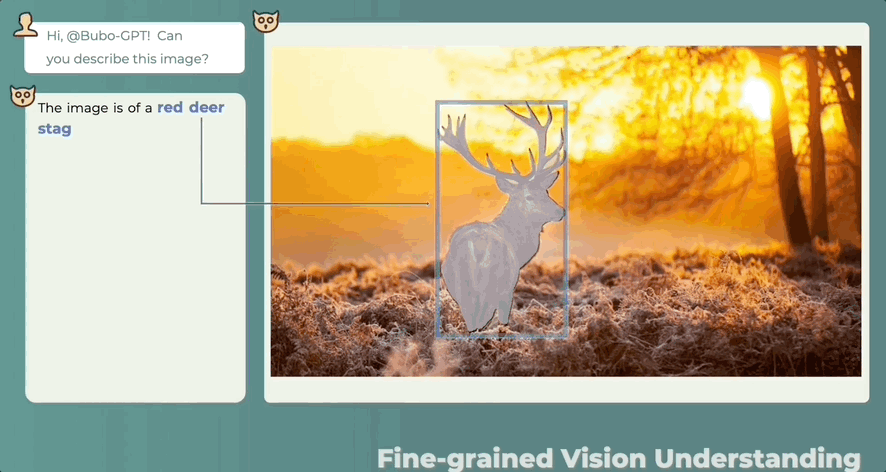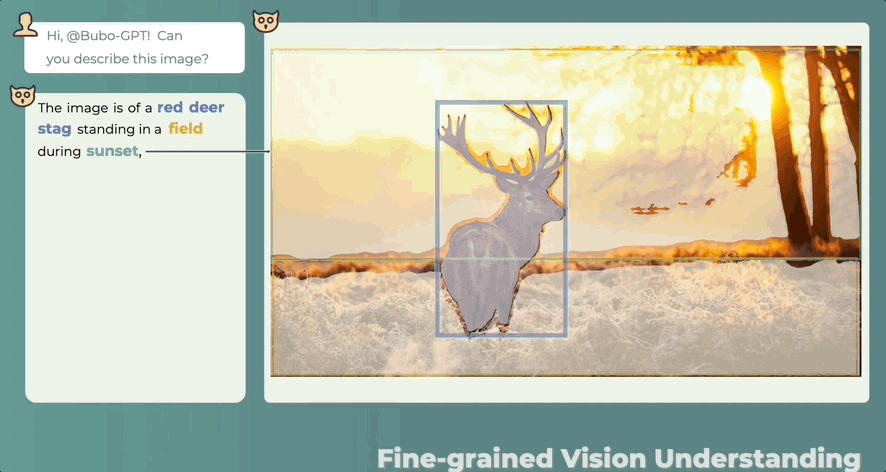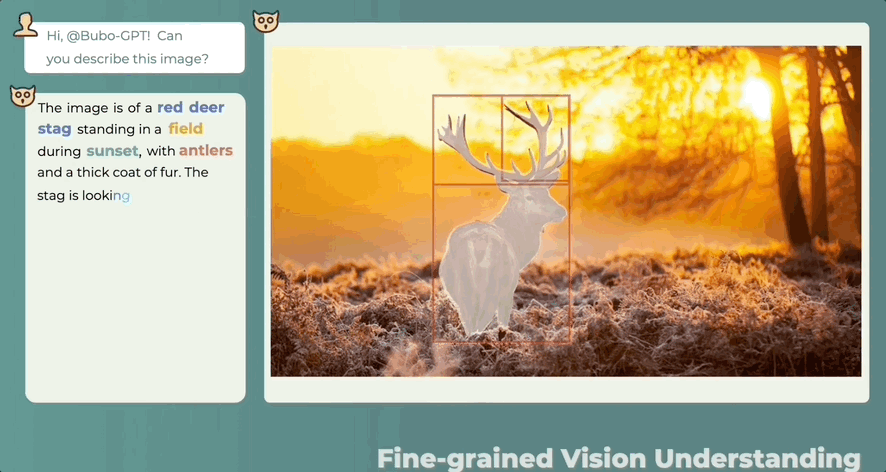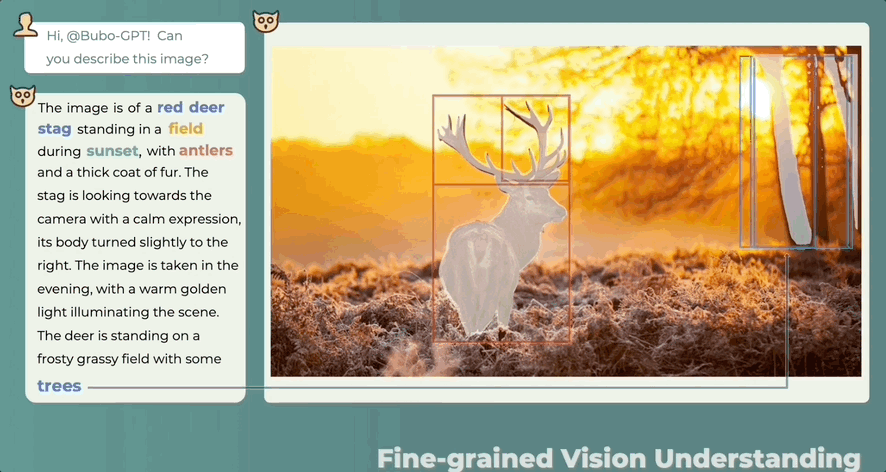
除了有“慧眼”,还有“聪耳”。人类都注意不到的细节BuboGPT能听到:

前方高能!
三模态联合理解,文字描述+图像定位+声音定位,一键搞定,准确判断声音来源:

别着急,还没完!
即使音频和图像之间没有直接关系,也可以合理描述两者之间的可能关系,看图辨音讲故事也可以:
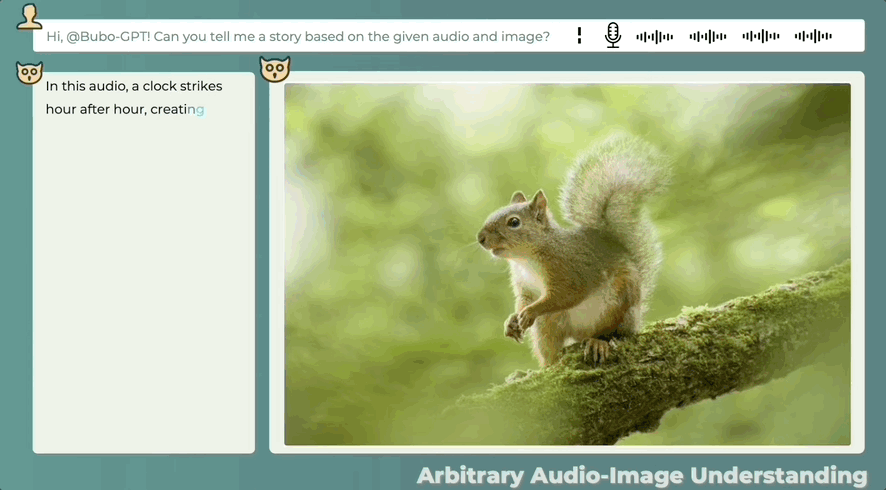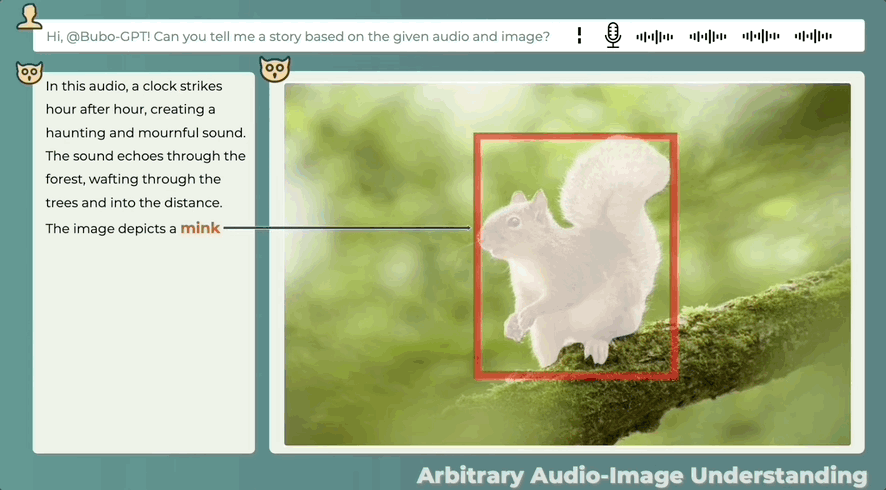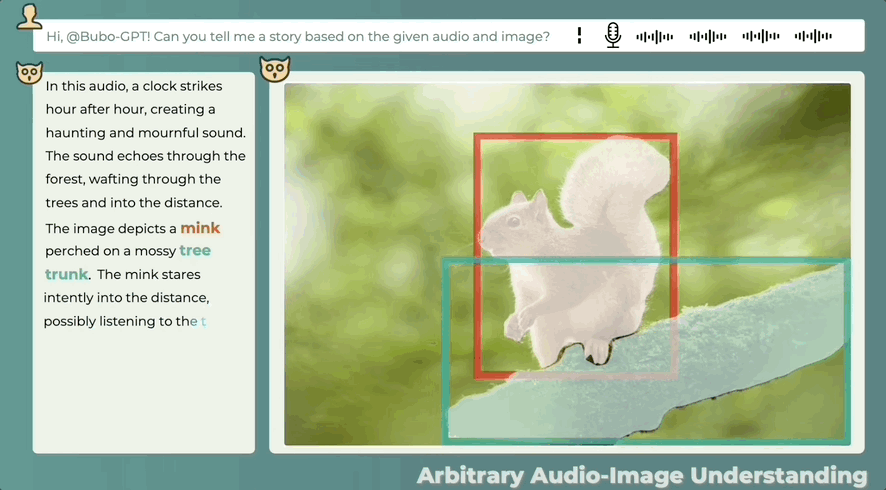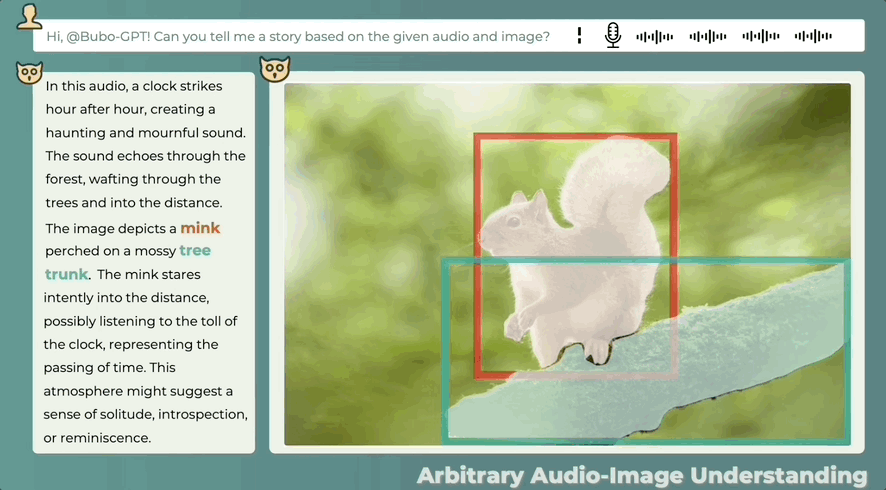
这么一看,BuboGPT干点活,够“细”的。
研究人员表示:
MiniGPT-4,LLaVA和X-LLM等最近爆火的多模态大模型未对输入的特定部分进行基础性连接,只构建了粗粒度的映射。
而BuboGPT利用文本与其它模态之间丰富的信息且明确的对应关系,可以提供对视觉对象及给定模态的细粒度理解。
因此,当BuboGPT对图像进行描述时,能够指出图中对象的具体位置。

BuboGPT:首次将视觉连接引入LLM
除了上面作者分享在YouTube的示例,研究团队在论文中也展示了BuboGPT玩出的各种花样。
活久见青蛙弹琴!这样的图BuboGPT也能准确描述吗?

一起康康回答得怎么样:

不仅能够准确描述青蛙的姿势,还知道手摸的是班卓琴?
问它图片都有哪些有趣的地方,它也能把图片背景里的东西都概括上。
BuboGPT“眼力+听力+表达力测试”,研究人员是这样玩的,大家伙儿先来听这段音频。
再来看看BuboGPT的描述怎么样:
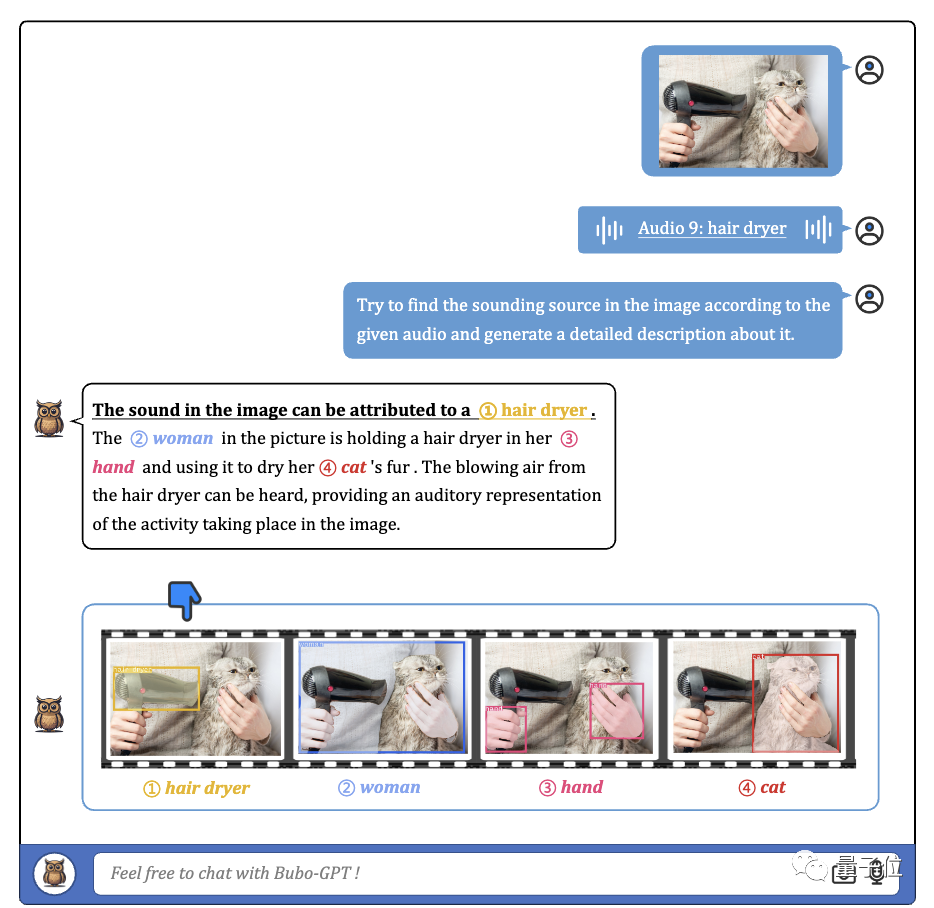
图片上的人的性别、声音来源、图片中发生的事情,BuboGPT都能准确理解。
效果这么好,是因为字节这次用了将视觉定位引入LLM的方法。
具体方法我们接着往下看。
BuboGPT的架构是通过学习一个共享的语义空间,并进一步探索不同视觉对象和不同模态之间的细粒度关系,从而实现多模态理解。
为探索不同视觉对象和多种模态之间的细粒度关系,研究人员首先基于SAM构建了一个现成的视觉定位pipeline。
这个pipeline由标记模块(Tagging Module)、定位模块(Grounding Module)和实体匹配模块(Entity-matching Module)三个模块组成。
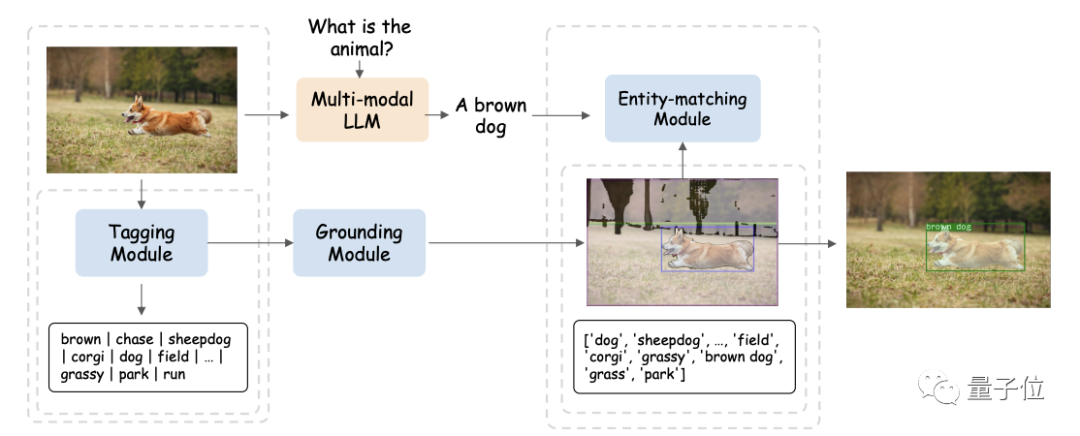
流程大概是这样婶儿的:
首先,标记模块是一个预训练模型,可以生成与输入图像相关的多个文本标签。
基于SAM的定位模块进一步定位图像上与每个文本标签相关的语义掩模或边界框。
然后,实体匹配模块利用LLM的推理能力从标签和图像描述中检索匹配的实体。
研究人员就是通过这种方式,使用语言作为桥梁将视觉对象与其它模态连接起来。
为了让三种模态任意组合输入都能有不错的效果,研究人员采用了类似于Mini-GTP4的两阶段走训练方案:
单模态预训练和多模态指令调整。
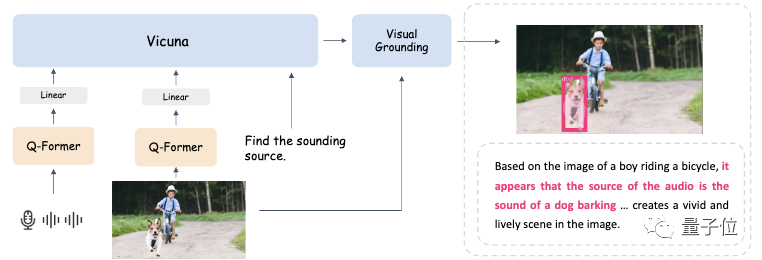
具体而言,BuboGPT使用了ImageBind作为音频编码器,BLIP-2作为视觉编码器,以及Vicuna作为预训练LLM。
在单模态预训练阶段,在大量的模态-文本配对数据上训练相应的模态Q-Former和线性投影层。
对于视觉感知,研究人员仅对图像标题生成部分进行投影层的训练,并且保持来自BLIP2的Q-Former固定。
对于音频理解,他们同时训练了Q-Former和音频标题生成部分。
在这两种设置下都不使用任何提示(prompt),模型仅接收相应的图像或音频作为输入,并预测相应的标题(caption)。

△不同输入的指令遵循示例
在多模态指令调整阶段,构建了一个高质量的多模态指令数据集对线性投影层进行微调,包括:
图像-文本:使用MiniGPT-4和LLaVa中的两个数据集进行视觉指令调优。
音频-文本:基于Clotho数据集构建了一系列表达性和描述性数据。
音频-图像-文本:基于VGGSS数据集构建了<音频,图像,文本>三模态指导调优数据对,并进一步引入负样本来增强模型。
值得注意的是,通过引入负样本“图像-音频对”进行语义匹配,BuboGPT可以更好地对齐,多模态联合理解能力更强。
目前BuboGPT代码、数据集已开源,demo也已发布啦,我们赶紧上手体验了一把。
demo浅玩体验
BuboGPT demo页面功能区一目了然,操作起来也非常简单,右侧可以上传图片或者音频,左侧是BuboGPT的回答窗口以及用户提问窗口:
上传好照片后,直接点击下方第一个按钮来上传拆分图片:

就拿一张长城照片来说,BuboGPT拆成了这个样子,识别出了山、旅游胜地以及城墙:
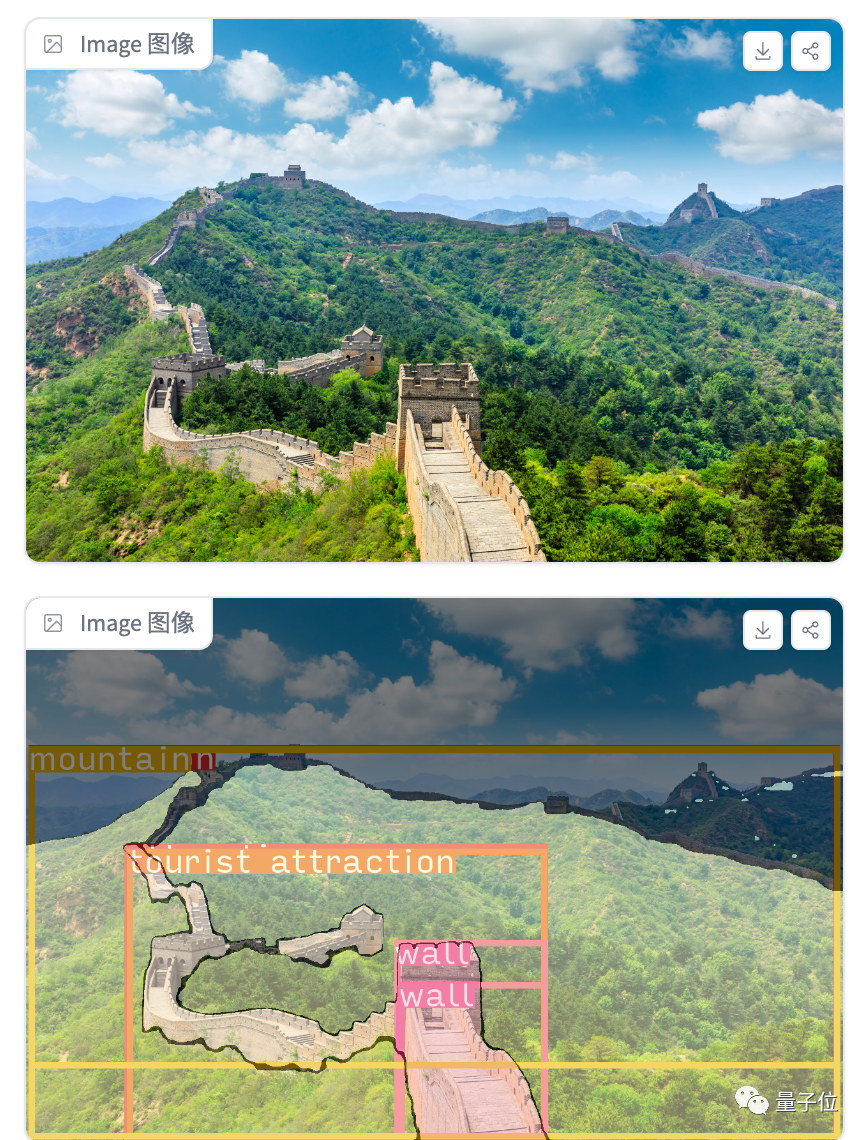
当我们让它描述一下这幅图时,它的回答也比较具体,基本准确:

可以看到拆分框上的内容也有了变化,与回答的文本内容相对应。
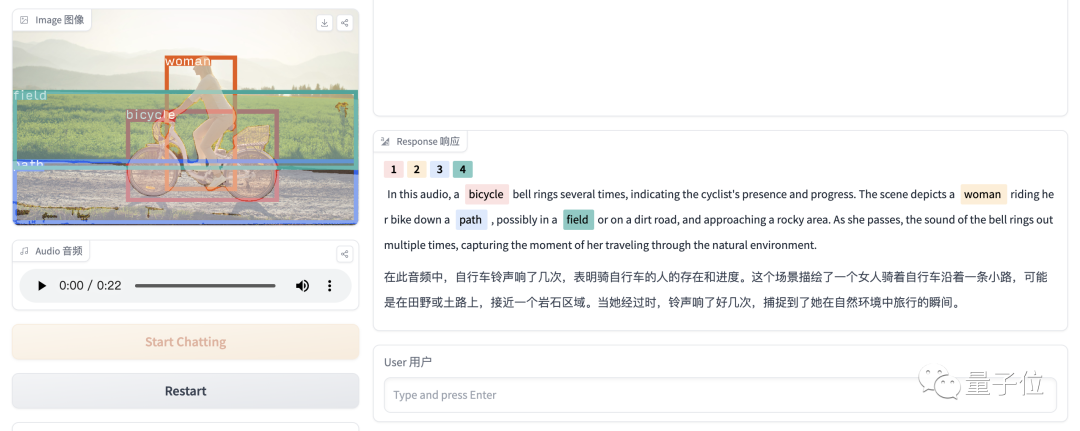
再来一张图片,并带有一段音频,BuboGPT也正确匹配了声音来源:
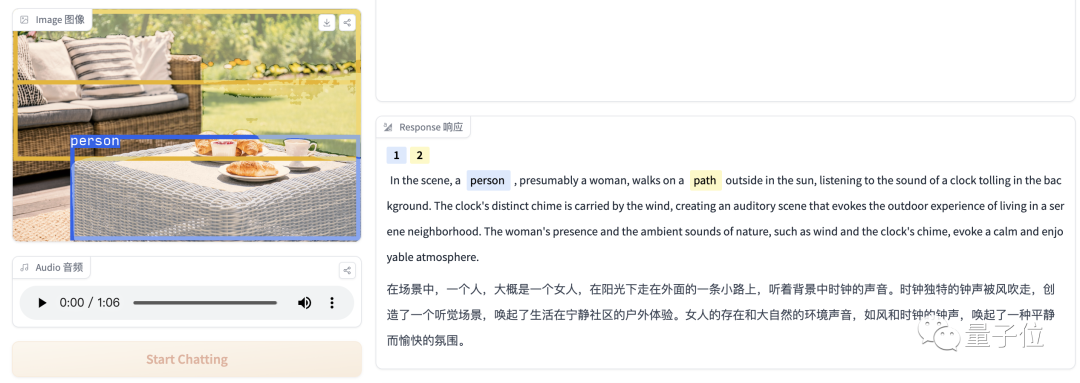
当然,它也会出现识别不成功,表述错误的情况,比如说下面这张图中并没有人,音频也只是钟声,但它的描述和图片似乎并不搭边。
感兴趣的家人赶紧亲自上手试试~~
传送门:
[1]https://bubo-gpt.github.io/
[2]https://huggingface.co/spaces/magicr/BuboGPT(demo)
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!