简而言之,时间序列预测是根据以前的历史数据预测未来值的过程。目前使用时间序列预测的最热门领域之一是加密货币市场,人们希望预测比特币或以太坊等流行加密货币的价格在未来几天甚至更长时间内将如何波动。另一个现实世界的案例是能源消耗预测。尤其是在能源成为主要讨论焦点之一的当今世界,能够准确预测能源消耗需求对于任何电力公司来说都是至关重要的工具。在本文中,
问题
我们将重点关注能源消耗问题,给定一个城市中不同家庭日常能源消耗的足够大的数据集,我们的任务是尽可能准确地预测未来的能源需求。出于本教程的目的,我选择了伦敦能源数据集,其中包含英国伦敦市 5,567 个随机选择的家庭在 2011 年 11 月至 2014 年 2 月期间的能源消耗。为了改进我们的预测,我们将此数据集与伦敦天气数据集结合起来,以便在此过程中添加天气相关数据。
这是这个迷你系列的第一部分。阅读完本文后,请务必检查下一部分,该部分通过合并滞后特征显着改善了结果。
预处理
在每个项目中我们要做的第一件事就是充分了解数据并在需要时对其进行预处理。要使用 pandas 查看数据,我们可以执行以下操作:
“LCLid”是标识每个家庭的唯一字符串,“Date”是不言自明的,“KWH”是该日期消耗的千瓦时总数,并且根本没有缺失值。由于我们想要以一般方式而不是每个家庭来预测消耗量,因此我们需要按日期对结果进行分组并平均千瓦时。
在这一点上,如果我们能够了解这些年来消费的变化方式,那就太好了。线图可以揭示这一点:

整个数据集的能耗图
季节性特征十分明显。在冬季,我们观察到能源需求较高,而在整个夏季,能源消耗处于最低水平。这种行为在数据集中每年都会重复,具有不同的高值和低值。为了可视化一年内的波动,我们可以这样做:
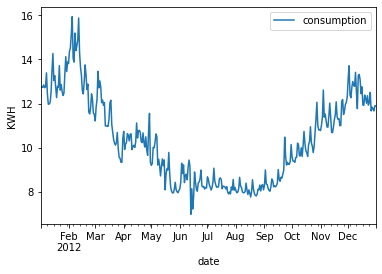
年能源消耗
为了训练像 XGBoost 和 LightGB 这样的模型,我们需要自己创建特征。目前,我们只有一项功能:完整日期。我们可以根据完整日期提取不同的特征,例如星期几、一年中的某一天、月份等。为了实现这一目标,我们可以这样做:
因此,“日期”功能目前是多余的。在删除它之前,我们将使用它将数据集拆分为训练集和测试集。与传统的训练相反,在时间序列中,我们不能只是以随机的方式分割集合,因为数据的顺序非常重要,而且我们只能合并以前的数据。否则,我们可能会被提示预测一个值,同时也考虑到未来的值!该数据集包含近 2.5 年的数据,因此对于测试集,我们将仅使用最近 6 个月的数据。如果训练集更大,我们会使用去年全年作为测试集。
为了再次可视化训练集和测试集之间的分割和区分,我们可以绘制:

可视化训练-测试分离
现在我们可以删除“日期”功能并创建训练和测试集:
训练模型
超参数优化将通过网格搜索来完成。网格搜索采用参数和一些值作为配置,并尝试每种可能的组合。达到最佳结果的参数配置将是形成最佳估计器的参数配置。网格搜索也利用交叉验证,因此提供适当的分割机制至关重要。同样,由于问题的性质,我们不能只使用简单的 k 折交叉验证。Scikit learn 提供了TimeSeriesSplit方法,该方法以尊重连续性的方式增量地分割数据。
对于 LightGB 模型,我们可以通过提供不同的参数来完成相同的操作:
评估
为了评估测试集上的最佳估计器,我们将计算一些指标。它们是平均绝对误差 (MAE)、均方误差 (MSE) 和平均绝对百分比误差 (MAPE)。其中每一个都提供了对训练模型的实际性能的不同视角。此外,我们将绘制线图以更好地可视化模型的性能。
最后,为了评估上述任何模型,我们必须运行以下命令:

XGBoost 结果

LightGBM 结果
尽管 XGBoost 可以更准确地预测冬季的能耗,但为了严格量化和比较性能,我们需要计算误差指标。通过查看下表,很明显 XGBoost 在所有情况下都优于 LightGBM。
预处理天气数据
该模型表现相对较好,但是有没有办法进一步改进呢?答案是肯定的。有许多不同的提示和技巧可以用来获得更好的结果。其中之一是使用与能耗直接或间接相关的辅助功能。例如,天气数据在预测能源需求时可以发挥决定性作用
首先我们看一下数据的结构:
需要填写的缺失数据有多种。填充缺失数据并非易事,取决于具体情况。由于我们的天气数据每天都取决于前几天和后几天,因此我们将通过插值来填充这些值。此外,我们将把“date”列转换为“datetime”,然后合并两个数据帧以获得一个增强的数据帧。
请记住,生成增强集后,我们必须重新运行拆分过程并获取新的“training_data”和“testing_data”。不要忘记也包含新功能。
无需更新训练步骤。在新数据集上训练模型后,我们得到以下结果:
XGBoost 根据天气结果进行增强

LightGBM 根据天气结果进行增强
天气数据显着提高了两个模型的性能。特别是,在 XGBoost 场景中,MAE 降低了近 44%,而 MAPE 从 19% 升至 16%。对于 LightGBM,MAE 下降了 42%,MAPE 从 19.8% 下降到 16.7%。
结论和未来的步骤
集成模型是非常强大的机器学习工具,可用于时间序列预测问题。在本文中,我们了解了在能源消耗的情况下这是如何完成的。首先,我们仅使用日期因素来训练模型。后来,我们在训练过程中考虑了与手头任务相关的其他数据,以便显着提高结果。