Pytorch深度学习实践–学习笔记
注:本文来源于 bilibili up 刘二大人的pytorch学习视频,为本人的学习记录笔记
视频地址 课件以及代码均在此视频链接下
一、P5使用Pytorch实现线性回归
使用pytorch的tensor数据进行运算会在计算机构建计算图,需要吃内存
1.构建线性单元模型
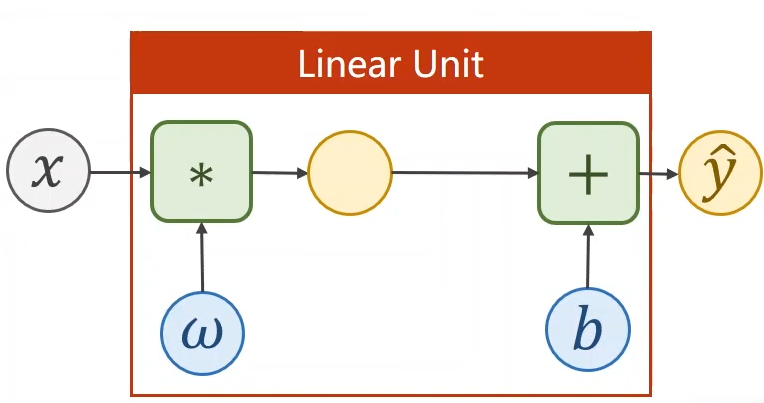
"""
net1.py
"""
from torch import nn
import torch.nn.functional as F
class LinearModel(nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = nn.Linear(1,1) # 线性层输入为1输出也为1
def forward(self,x):
y_pred = F.sigmoid(self.linear(x)) # 将输出映射到0-1之间,输出为一个分布
return y_pred
2.训练程序
import torch
from net1 import LinearModel
from torch import nn
# 准备数据集
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
model = LinearModel() # 创建模型对象
# 定义损失函数
loss_fn = nn.BCELoss(size_average=True)
# 定义优化器
learn_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),lr=learn_rate)
# 训练轮数
epochs = 1000
print(x_data.shape)
for epoch in range(epochs):
y_pred = model(x_data)
loss = loss_fn(y_pred,y_data)
print(epoch,loss.item())
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("w = ",model.linear.weight.item())
print("b = ",model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print("y_pred = ",y_test.data)
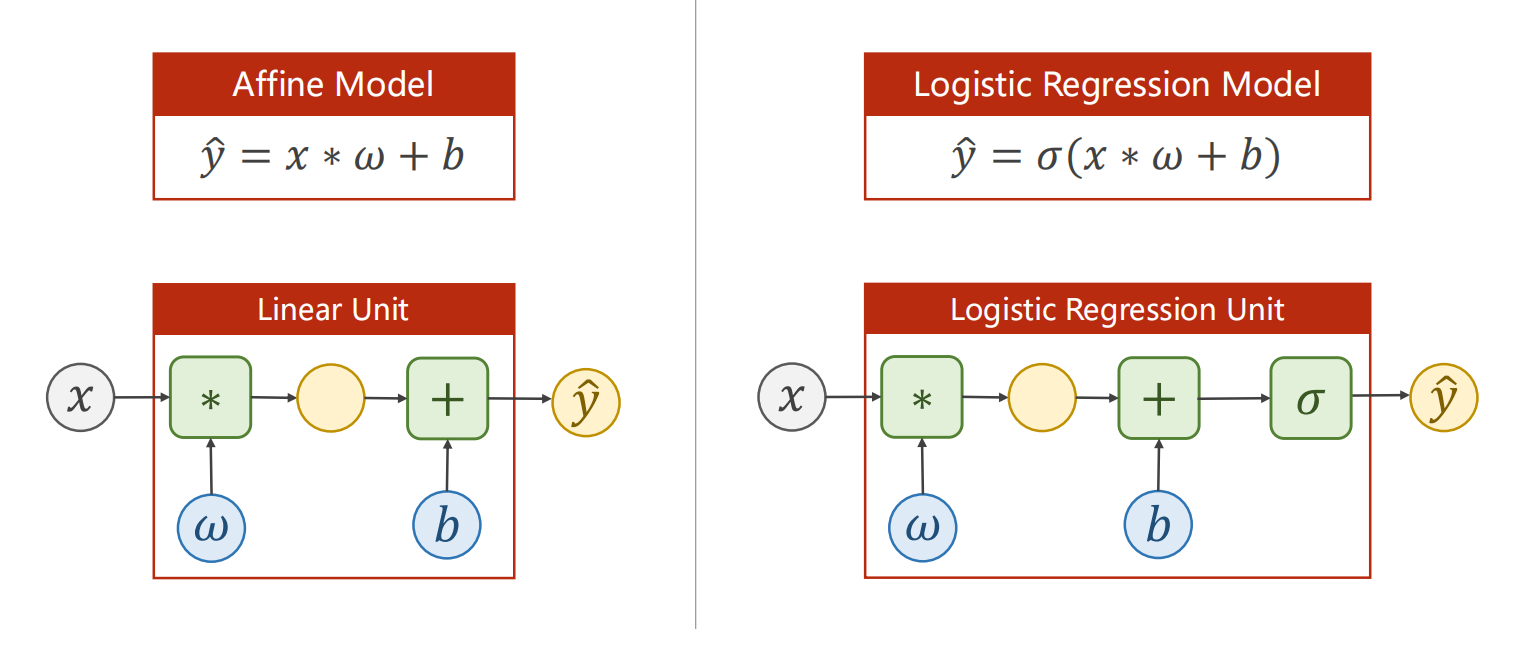
二、P6逻辑斯蒂回归
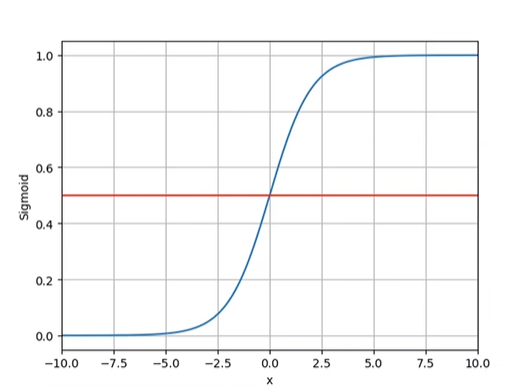
使用S型(logistic)激活函数,将线性层的输出映射至 [0,1] 之间
S型函数:
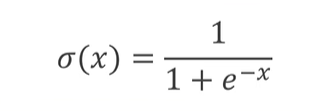
函数图像:
1.构建模型
Net2.py
from torch import nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear0 = nn.Linear(10,8)
self.linear1 = nn.Linear(8,6) # 线性层输入为1输出也为1
self.linear2 = nn.Linear(6,4)
self.linear3 = nn.Linear(4,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear0(x))
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
2.训练程序
使用了糖尿病数据集,该数据集在视频中有指导如何使用
import numpy as np
import torch
from net2 import Model
import torch.nn as nn
x = np.loadtxt('./data/diabetes_data.csv',delimiter=' ',dtype=np.float32)
y = np.loadtxt('./data/diabetes_target.csv',delimiter=' ',dtype=np.float32)
# 将 ndarray数组 类型数据变为tensor
x_data = torch.from_numpy(x[:,:])
y_data = torch.from_numpy(y[:])
y_data = torch.reshape(y_data,(442,1))
# print(x_data.shape)
# print(y_data.shape)
model = Model()
# 定义损失函数
loss_fn = nn.BCELoss(reduction='mean')
# 定义优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
epoches = 1000
for epoch in range(epoches):
# Forward
y_pred = model(x_data)
loss = loss_fn(y_pred,y_data)
print(epoch,loss.item())
# Backward
optimizer.zero_grad() # 梯度清0
loss.backward()
# update
optimizer.step()
三、P9多分类问题
涉及搭配多分类问题,可以使用softmax层将模型的输出,变为一个分布,即模型输出对于每一个target的概率均小于等于1大于等于0,所有target的概率和为1
Pytorch中的交叉熵损失函数中包含了softmax层,如下
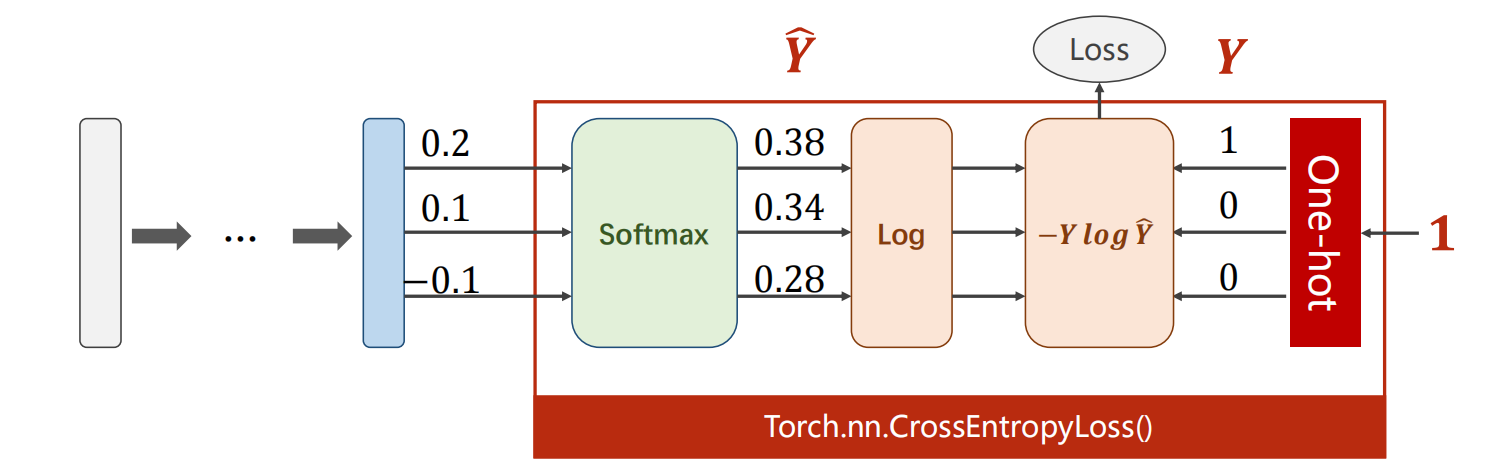
1.构建网络模型

Net3.py
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = nn.Linear(784,512)
self.l2 = nn.Linear(512,256)
self.l3 = nn.Linear(256,128)
self.l4 = nn.Linear(128,64)
self.l5 = nn.Linear(64,10)
def forward(self,x):
x = x.view(-1,784) # 使得输入的形状变为 784列,行数则需要程序自行计算得到
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不需要激活函数
使用view()对输入的Tensor数据形状进行变化,view(-1,784)使得输入的形状变为784列,行不管,程序自行计算
2.训练程序
import torch
import torch.nn.functional as F
import torch.optim as optim
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
from net3 import Net
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='./data/mnist/',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
test_dataset = datasets.MNIST(root='./data/mnist/',train=False,download=True,transform = transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
# 定义模型
model = Net()
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
epoches = 20
# 定义训练函数
def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loader,0):
inputs,targets = data
# Forward
outputs = model(inputs)
loss = loss_fn(outputs,targets)
# backward
optimizer.zero_grad() # 梯度清0
loss.backward()
optimizer.step() # 对可学习参数进行优化
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss: %.3f' %(epoch+1,batch_idx+1,running_loss/300))
running_loss = 0.0
# 定义测试函数
def test():
correct = 0
total = 0
with torch.no_grad(): # 无梯度
for data in test_loader:
images,labels = data
outputs = model(images)
_,predicated = torch.max(outputs.data,dim=1)
total += labels.size(0)
correct += (predicated == labels).sum().item()
print('Accuracy on test set: %d %%' %(100*correct / total))
def main():
for epoch in range(epoches):
model.train()
train(epoch)
model.eval()
test()
main()
重点分析:
_,predicated = torch.max(outputs.data,dim=1)
示例程序1
import torch
input = torch.Tensor([[1,2,3],[4,5,6],[7,8,9]])
print(input.shape)
_,pred = torch.max(input,dim=1)
print(pred)
运行输出1
torch.Size([3, 3])
tensor([2, 2, 2])
示例程序2
import torch
input = torch.Tensor([[1,2,3],[4,5,6],[7,8,9]])
print(input.shape)
pred = torch.max(input,dim=1)
print(pred)
运行输出2
torch.Size([3, 3])
torch.return_types.max(
values=tensor([3., 6., 9.]),
indices=tensor([2, 2, 2]))
通过比较可知torch.max(input,dim)得到的值的类型为<class 'torch.return_types.max'>,直接使用变量得到的<class 'torch.return_types.max'>数据,其中含有dim维度中最大的值,以及值所对应的索引。使用dim=0则表示在维度0中取最大值(二维则是行,即在所有列在每一行中的最大值),使用dim=1则表示在维度1中取最大值(二维则是列,即在所有行在每一列中的最大值)
使用**_,pred**(下划线)则得到对应值的索引
四、P10卷积神经网络(基础篇)
示例程序1
import torch
in_channels,out_channels = 5,10
width,height = 100,100
kernel_size = 3
batch_size = 1
# 创建卷积层输入 batch_size张数 in_channels通道数
input = torch.randn(batch_size,in_channels,width,height)
conv_layer = torch.nn.Conv2d(in_channels,out_channels,kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape) # torch.Size([1, 5, 100, 100])
print(output.shape) # torch.Size([1, 10, 98, 98])
print(conv_layer.weight.shape) # torch.Size([10, 5, 3, 3])
# 卷积核数量与 out_channels 有关
# 卷积核通道数与 input的 通道数量有关
**在卷积层中,卷积核函数通道数与 输入图像的通道数 一致 , **如下图,输入图像的通道数为n,则卷积层中的卷积核通道数也应该为n,最后得到单通道的tensor数据
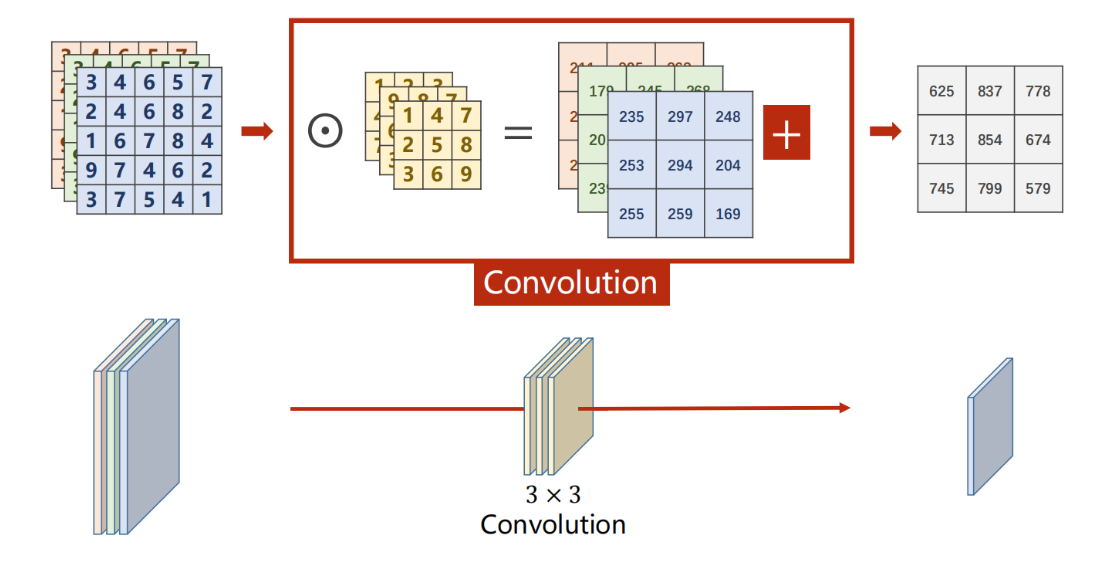
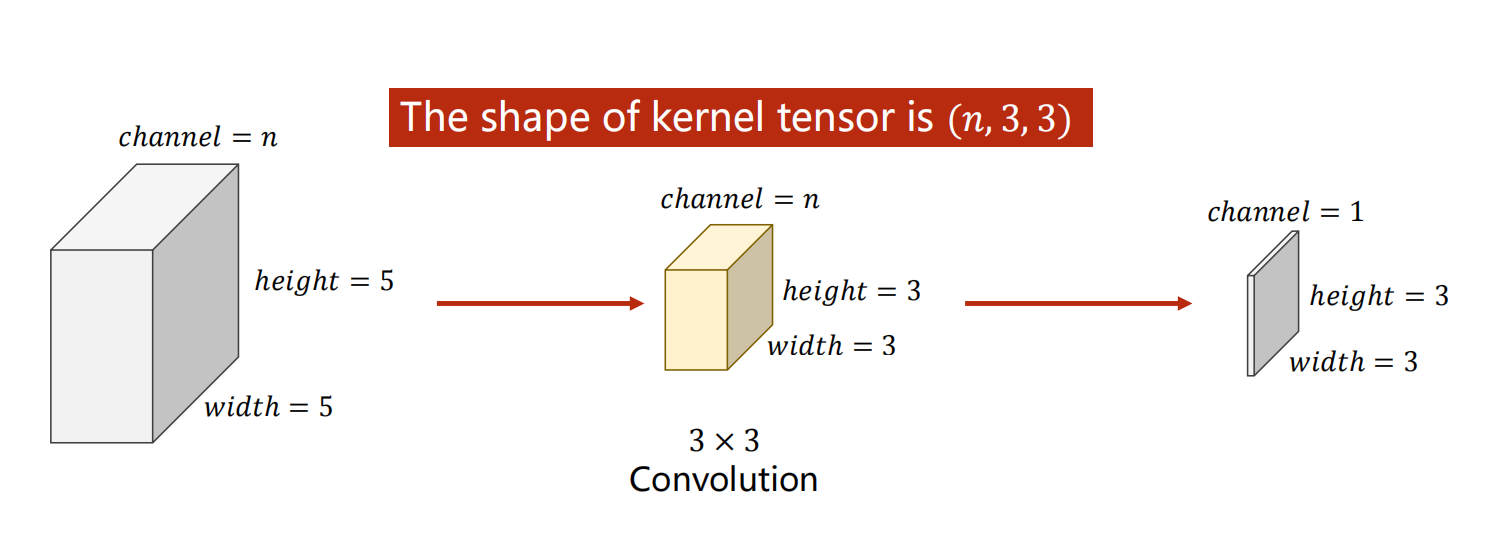
**在卷积层中,卷积核函数数量与 卷积层参数out_channels的值(经过卷积变换后,输出的tensor数据的通道数) 一致 , 即输入图像通过该卷积层会变为多少通道的tensor数据,**如下图,输入图像的通道数为n,则卷积层中的卷积核通道数也应该为n,卷积核数量为m,则输出的tensor数据的通道为m
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B1Ezkr8V-1674724262097)(https://gitee.com/zhou-xuezhi/my-pic/raw/master/img/image-20230123173704938.png)]

卷积层描述参考文章
在卷积运算时,会给定一个大小为FF的方阵,称为过滤器,又叫做卷积核,该矩阵的大小又称为感受野。过滤器的深度d和输入层的深度d维持一致,因此可以得到大小为FFd的过滤器,从数学的角度出发,其为d个FF的矩阵。在实际的操作中,不同的模型会确定不同数量的过滤器,其个数记为K,每一个K包含d个F*F的矩阵,并且计算生成一个输出矩阵。
一定大小的输入和一定大小的过滤器,再加上一些额外参数,会生成确定大小的输出矩阵。以下先介绍这些参数。
-
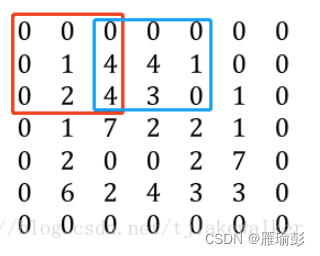
Padding: 在进行卷积运算时,输入矩阵的边缘会比矩阵内部的元素计算次数少,且输出矩阵的大小会在卷积运算中相比较于输入变小。因此,可在输入矩阵的四周补零,称为padding,其大小为P。比如当P=1时,原5*5的矩阵如下,蓝色框中为原矩阵,周围使用0作为padding

-
Stride: 进行卷积运算时,过滤器在输入矩阵上移动,进行点积运算。移动的步长stride,记为S。当S=2时,过滤器每次移动2个单元。如下图,红色框为第一步计算,蓝色框为S=2时的第二步运算
有了以上两个参数P和S,再加上参数W(输入矩阵的大小),过滤器的大小F,输出矩阵的大小为
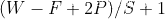
对于5x5的输入矩阵,过滤器大小F=3,P=1,S=1,其输出矩阵的大小为(5-3+2)/1+1=5。可见,在步长S为1,且进行了P=1的padding后,其输出矩阵的大小和输入一致。
公式存在一点问题详情看该文章
现在考虑当输入有多个深度时的情况。当输入为5x5x3,P=1,并且有K个过滤器时,每一个过滤器都为3x3x3。这里,我们把输入的3个7x7矩阵(5x5进行padding后得到7x7)命名为M1,M2,M3,第k个过滤器(0<k<K)的3个3x3矩阵命名为F1,F2,F3,输出的第k个矩阵(0<k<K)命名为Ok。卷积运算中,输入矩阵M1和过滤器F1,M2与F2,M3与F3进行卷积运算。卷积运算详细过程如下
-
在M1中,从最左上角,取感受野大小F*F的子矩阵,与F1进行点积运算,即对应位置元素相乘,再求和得到结果O11.
-
M2和F2进行同样的运算,得到结果O22;M3和F3得到O33.
-
O11+O22+O33相加,再加上偏移量b0,得到输出矩阵Ok左上角的第一个元素.
-
按照步长S,从M1,M2,M3中获取另外一个感受野大小的区域,对应F1,F2,F3进行步骤1~3的计算,最终得到完整的输出矩阵Ok
-
更换过滤器k+1,重复1~4的运算,得到K个输出矩阵。
总结以上过程,输出矩阵的每一个元素,是由对应过滤器不同深度的矩阵,作用于相应深度输入矩阵的不同位置,进行点积运算,再加上偏移量bias所得
在斯坦福的卷积神经网络课程有,有一个很典型的例子如下。此处分析两个步骤,完整的例子见以下链接:
Convolutional Neural Networks (CNNs / ConvNets)
在这个例子中,输入矩阵为553,即W=5,填充P为1,过滤器有K=2个,每个过滤器的大小为333,即F=3,同时设定计算步长S=2。这样可得到输出中单个矩阵的大小为(5-3+21)/2+1=3,由于K=2,所以输出的33矩阵有2个。下面为具体的计算过程
- 1). 首先从输入矩阵的最左边开始取得3*3的感受野,每一个深度的输入矩阵对应每一个深度的过滤器,进行点积运算,然后加上偏移Bias,得到第一个输出矩阵的第一个元素。详细过程为
输入矩阵1:r1 = 00+01+01+0(-1)+10+00+01+00+1*0=0
输入矩阵2:r2 = 00+00+00+01+00+01+00+20+0*0 = 0
输入矩阵3:r3 = 0*(-1)+0*(-1)+00+00+00+2(-1)+0*(-1)+00+20 = -2
输出矩阵元素(绿框中元素)O11 = r1+r2+r3+b0 = -1
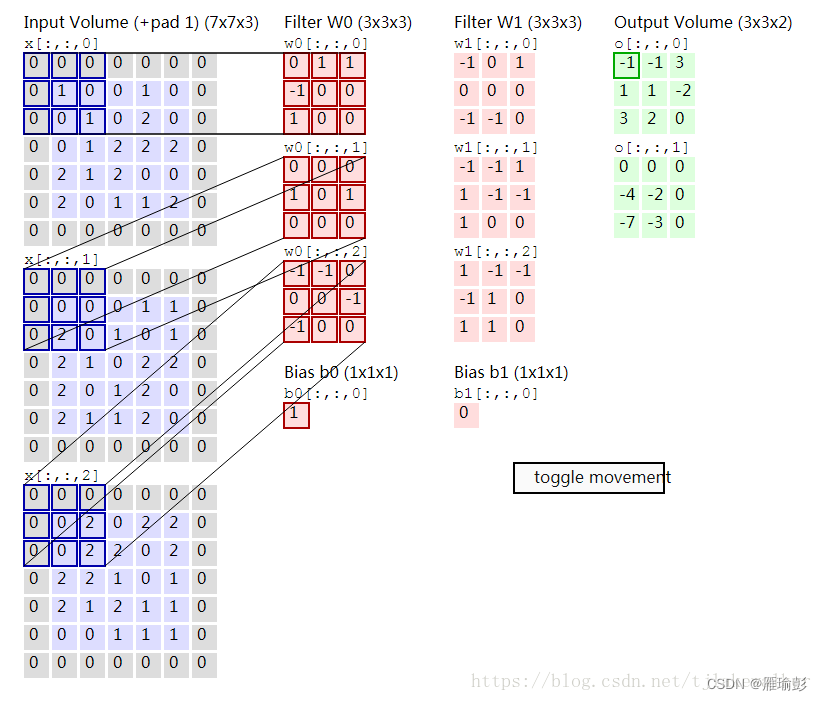
-
- 然后将感受野在3个输入矩阵上同时移动2个步长,如蓝框所示,重复1)中描述的运算,得到O12=-1,计算过程此处不再赘述
- 然后将感受野在3个输入矩阵上同时移动2个步长,如蓝框所示,重复1)中描述的运算,得到O12=-1,计算过程此处不再赘述
-
- 将感受野在输入矩阵中依次移动,当完成第一个输出矩阵的计算后,使用第二个过滤器再重复一次,得到第二个输出矩阵。卷积计算完成
在上面的计算中,每一个深度上的输入矩阵,其每一个步长的计算都是用同一个过滤器矩阵,这个现象被称为参数共享(parameter sharing)。其实这是一种简化,在未简化的情况下,同一深度矩阵上每一个步长的卷积计算,都需要使用不同的过滤器,这样会造成神经网络中参数过多,所以在实际操作中,会采取如上所述的参数共享策略,减少参数个数。
- 将感受野在输入矩阵中依次移动,当完成第一个输出矩阵的计算后,使用第二个过滤器再重复一次,得到第二个输出矩阵。卷积计算完成
到此,卷积神经网络卷积层的计算理论部分已经说完。下面一篇文章将从开发的角度,详细分析下,在实际的计算中,具体的数据结构和计算方法。
参考文献:
Convolutional Neural Networks - Basics
1.自定义卷积层数值
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1,1,5,5)
# 定义卷积层
conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,padding=1,bias=False)
# 自行定义卷积层中卷积核的数值
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
该字段代码,将卷积层中的数值进行自定义
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data
2.构建网络模型
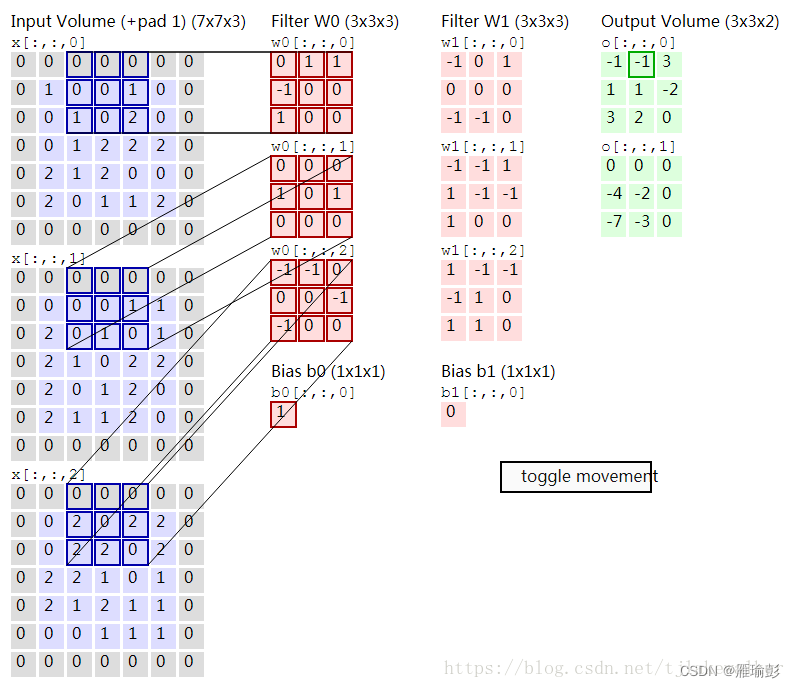
输入的图像数据为,单通道,长宽分别为28

"""
Net4.py
CNN基础篇 末尾的网络
"""
from torch import nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 特征提取 模型输入 channels = 1
self.conv1 = nn.Conv2d(1,10,kernel_size=5)
self.conv2 = nn.Conv2d(10,20,kernel_size=5)
self.pooling = nn.MaxPool2d(2)
# 全连接层
self.fc = nn.Linear(320,10)
def forward(self,x):
# Flatten data from (n,1,28,28) to (n,784)
batch_size = x.size(0) # 样本数量 n
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size,-1) # flatten
x = self.fc(x)
return x
3.测试代码
import torch
from net4 import Net
in_channels = 1
width,height = 28,28
batch_size = 2
# 创建卷积层输入 batch_size张数 in_channels通道数
input = torch.randn(batch_size,in_channels,width,height)
print(input.size(0)) # 2 为input的样本数量 input.size(1) 为input的通道数量 以此类推
print(input.shape) # torch.Size([2, 1, 28, 28])
model = Net()
output = model(input)
print(output.shape) # torch.Size([2, 10])
运行结果
2
torch.Size([2, 1, 28, 28])
torch.Size([2, 10])
五、P11卷积神经网络(高级篇)
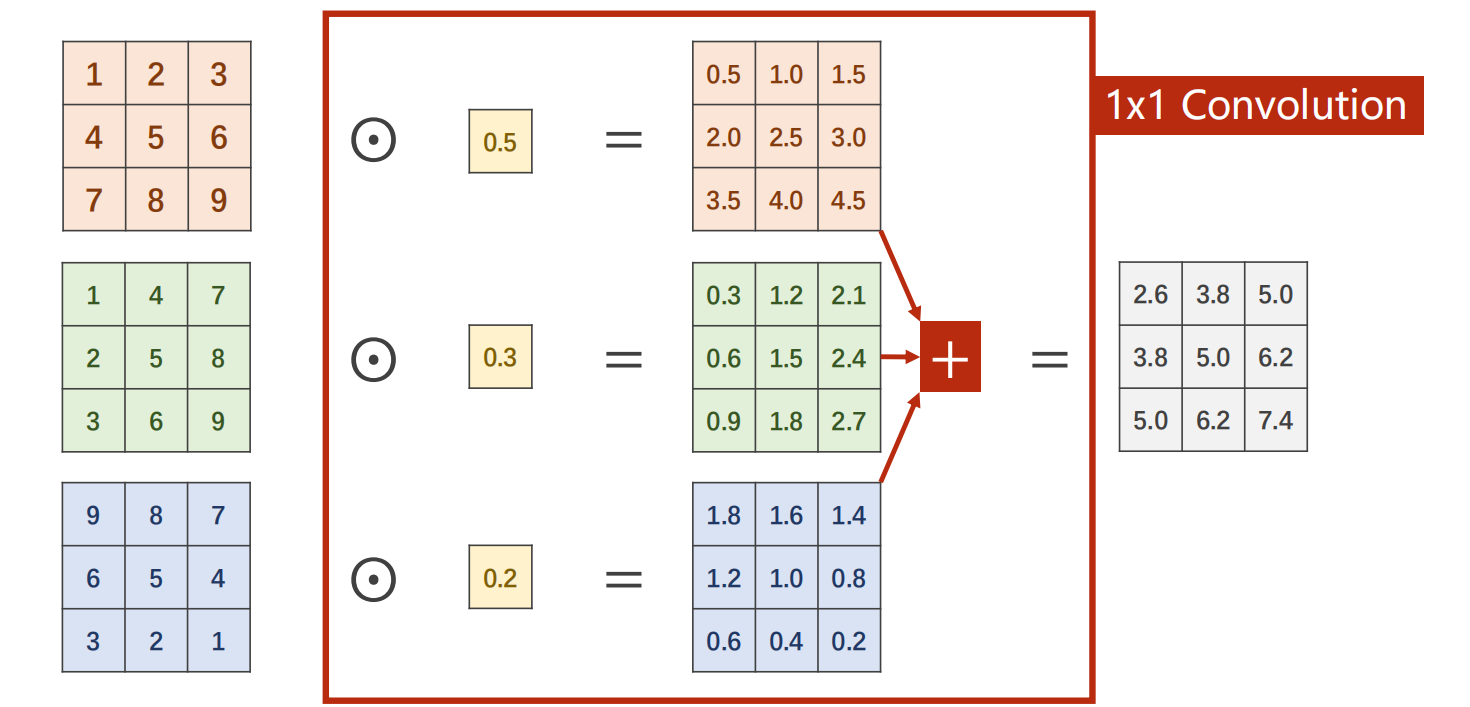
1x1卷积:其卷积核通道数与输入图像的通道数有关,可以跨越不同通道相同位置的值进行信息融合,其最主要的作用:第一、改变通道的数量,如下:一个三通道的图像,经过1X1卷积变为单通道
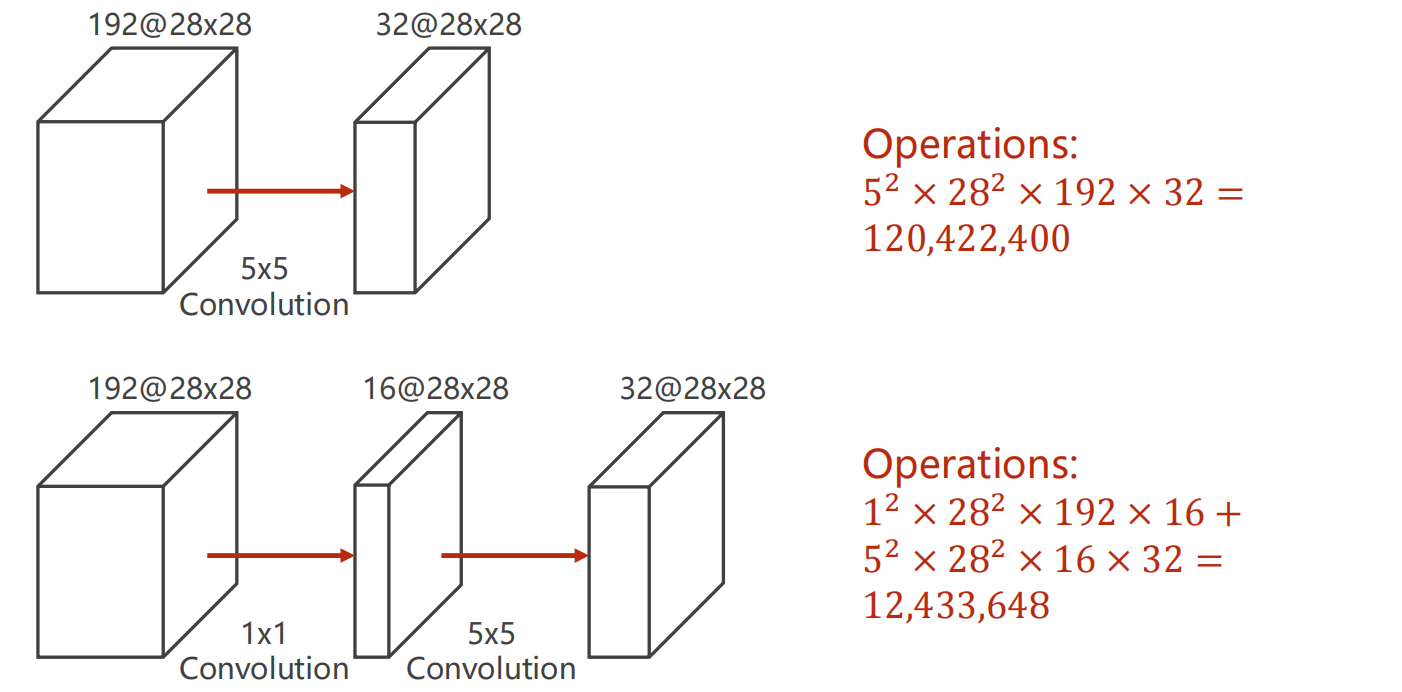
第二、降低运算量,如下,通过1x1卷积将192个通道28x28的张量变为16个通道28x28的张量,在通过一个5x5的卷积变为32通道8x8的数据,其可学习的参数为前者的1/10
1.GoogleNet中的Inception Module
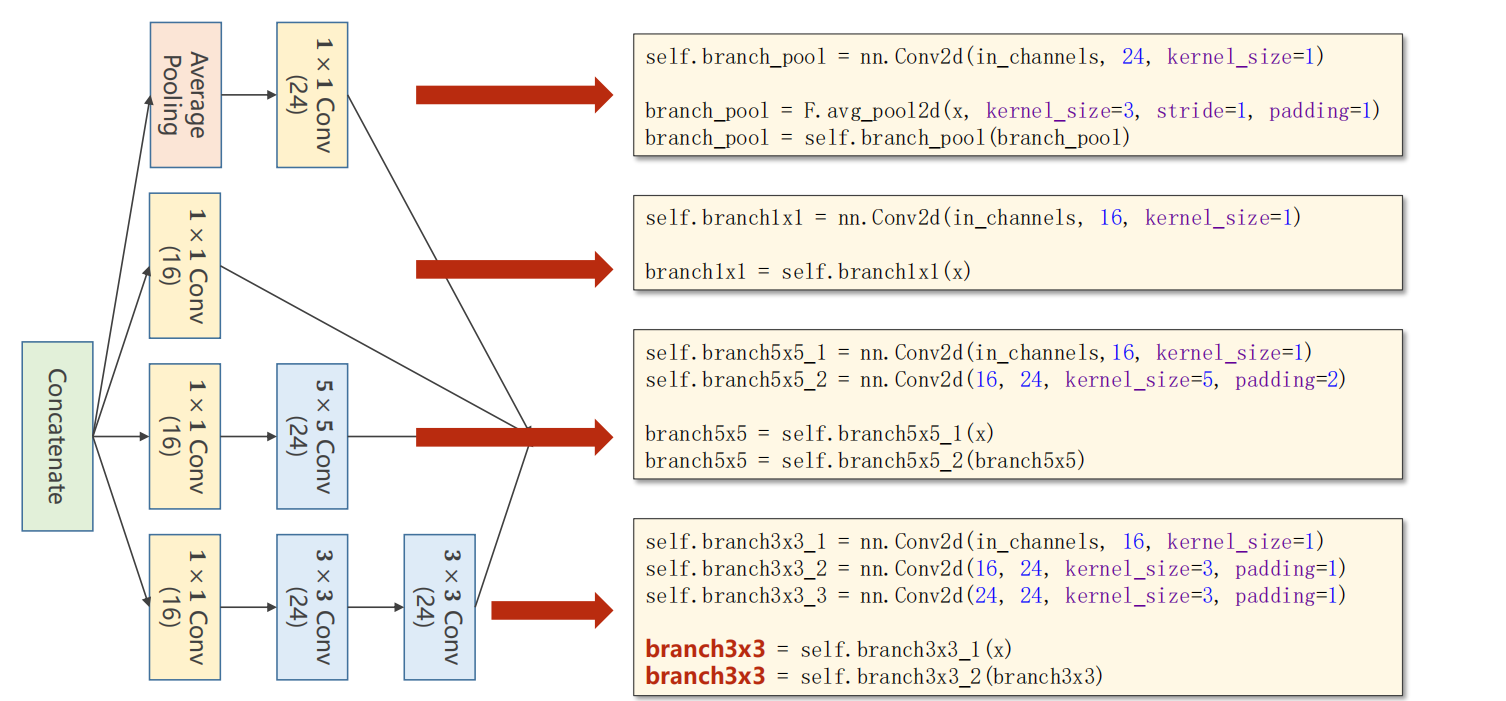
注意:这四个分支的输出,只有通道数可以不一样,其他的batch,W(宽),H(高)均一致,最后这四个分支均得到一个输出
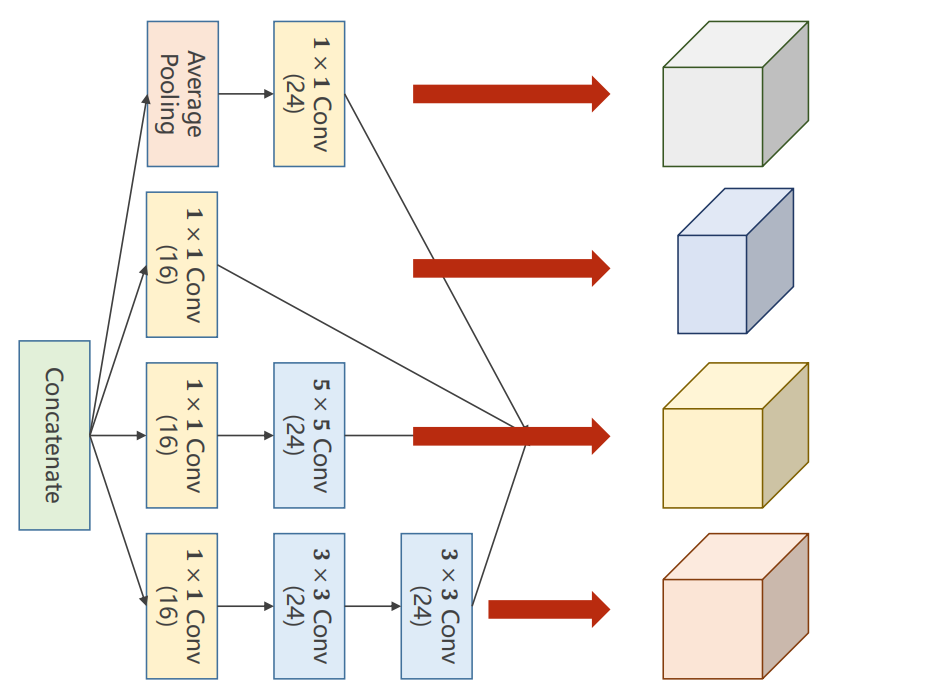
将得到的四个分支输出进行拼接:
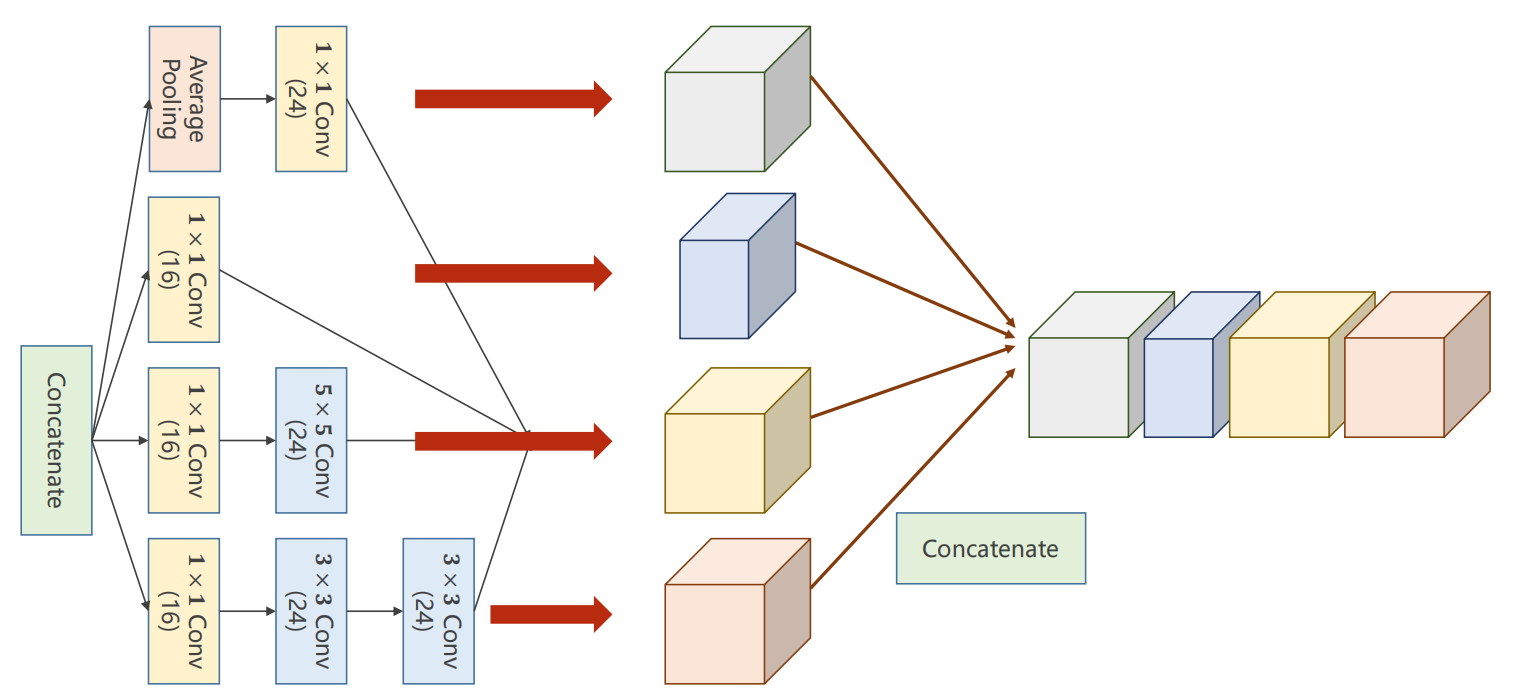
拼接如下,根据通道数进行拼接,即维度1,因为 B C W H
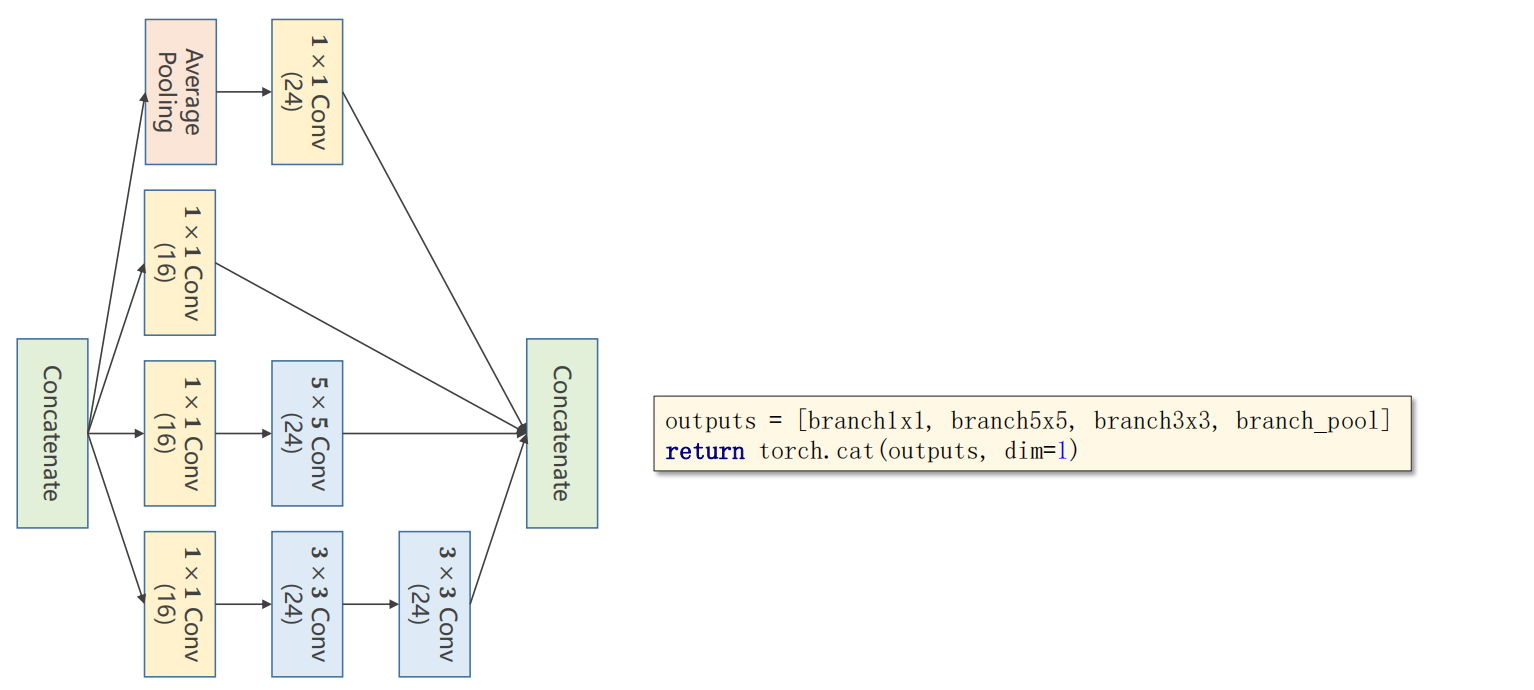
Inception Module代码:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qs1j9yZg-1674724262099)(https://gitee.com/zhou-xuezhi/my-pic/raw/master/img/image-20230123221249595.png)]
2.Residual Block
Residual Block可以在一定程度上避免梯度消失问题,残差模块的构建如下:

使用Residual Block
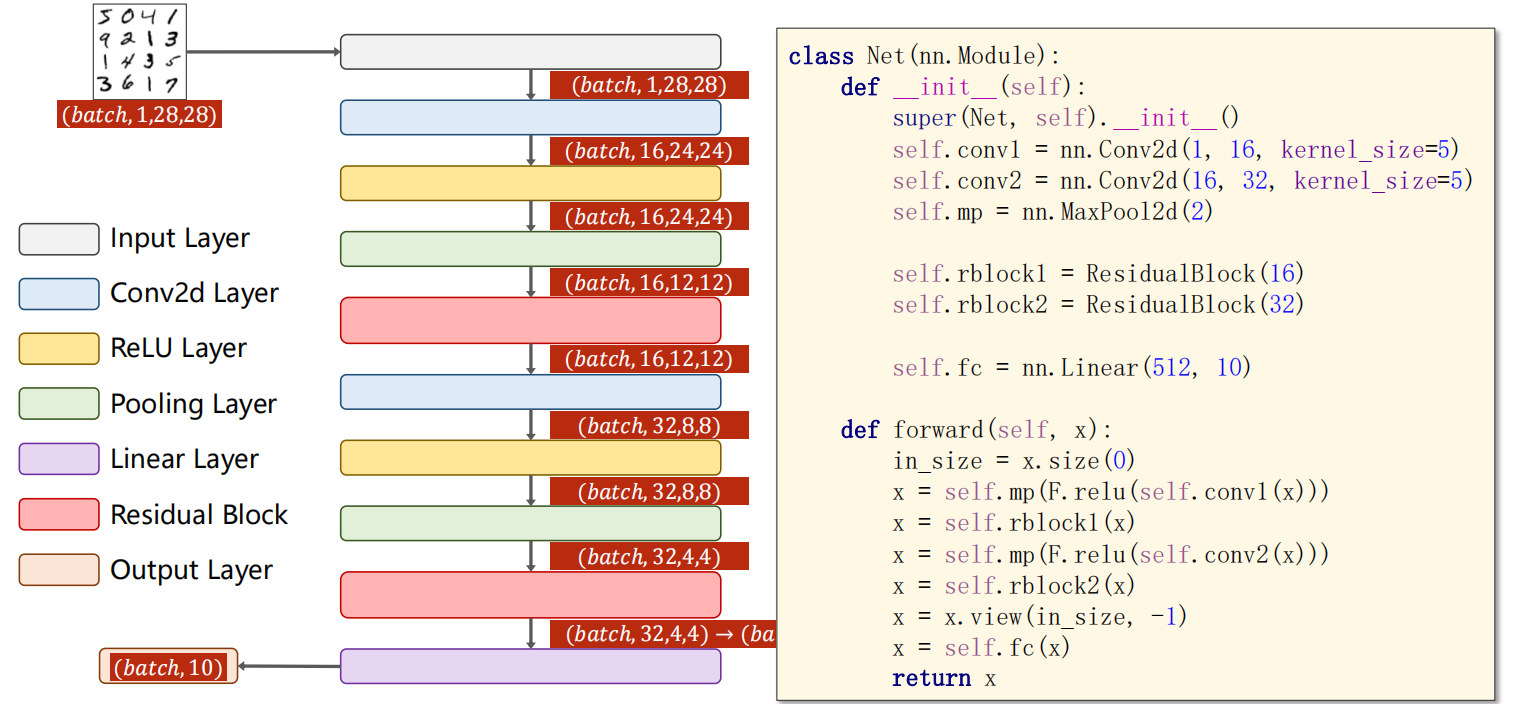
**论文: **
He K, Zhang X, Ren S, et al. Identity Mappings in Deep Residual Networks[C] 提供了很多残差网络的模型,进行学习
3.后续学习(重点):
- 理论《深度学习》
- 阅读Pytorch文档(通读一遍)
- 复现经典的工作(读代码,写代码)
- 找到一个方向,阅读大量的论文,学习构造网络的技巧
六、P12 循环神经网络(基础篇)
暂时项目不涉及,就不做笔记了
七、P13 循环神经网络(高级篇)
暂时项目不涉及,就不做笔记了