此次的数据集来自kaggle的关于在线零售业务的交易数据,该公司主要销售礼品,大部分出售对象是面向批发商。
数据链接
数据集字段介绍
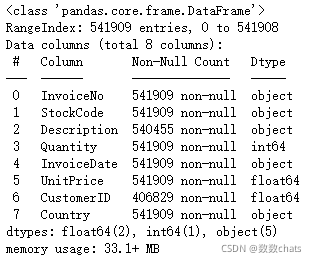
数据包含541910行,8个字段,字段内容为:
InvoiceNo: 订单编号,每笔交易有6个整数,退货订单编号开头有字母’C’。
StockCode: 产品编号,由5个整数组成。
Description: 产品描述。
Quantity: 产品数量,有负号的表示退货
InvoiceDate: 订单日期和时间。
UnitPrice: 单价(英镑),单位产品的价格。
CustomerID:客户编号,每个客户编号由5位数字组成。
Country: 国家的名称,每个客户所在国家/地区的名称。
数据处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
import datetime
plt.rcParams['font.sans-serif']=['Simhei']
data=pd.read_csv('data.csv')
data.info()
缺失值处理
#缺失值占比
data.isnull().mean()

CustomerID 约25%的数据记录是空的,这意味着有约25%的数据记录没有分配给任何客户。而我们不可能把这些记录的值映射到任何客户。所以这些对于目前是没有用的,因此我们可以将其删除。
data.dropna(axis = 0, subset = ['CustomerID'],inplace = True)
删除重复值
print('重复的数据条目: {}'.format(data.duplicated().sum()))
data.drop_duplicates(inplace = True)
异常值处理
data.describe()
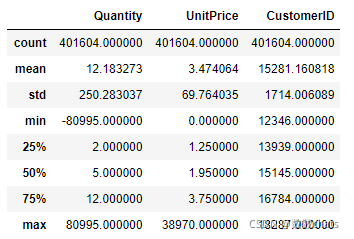
quantity指的是购买的数量,不可能存在负数;UnitPrice是单价,不可能存在负值。将异常值直接删除。
data=data.loc[(data['Quantity']>0) & (data['UnitPrice']>0)]
RFM划分用户群
data['total_sales'] = data['UnitPrice'] * data['Quantity']
rfm=data.groupby(['CustomerID']).agg({
'InvoiceDate':'max',
'InvoiceNo':'nunique',
'total_sales':'sum'
}).sort_index()
rfm.InvoiceDate=rfm.InvoiceDate.dt.date
#创建一个新的变量,计算R(recency)的时候用
Nowdate=max(rfm.InvoiceDate)+datetime.timedelta(days=1)
#求R, R值定义为 最近一次购买日期 距离Nowdate的时间间隔
rfm.InvoiceDate=(Nowdate-rfm.InvoiceDate).astype('str').apply(lambda x:x[:-5]).astype('int32')
rfm.rename(columns={
'InvoiceDate':'R','InvoiceNo':'F','total_sales':'M'},inplace=True)
rfm.head()
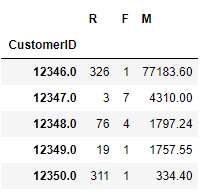
分别计算三个指标的中位数,每个指标与中位数进行比较,划分高低,一共会得到8组分类
为每一个用户的R,F,M值进行高低维度的划分;低用‘1’表示,高用‘2’表示。高与低是针对用户值的高低而言的。
R值若小于中位数,则为高,否则为低
F值若大于中位数,则为高,否则为低
M值若大于中位数,则为高,否则为低
R_median = rfm['R'].median()
rfm['R_label']=rfm['R'].apply(lambda x:'2' if x>R_median else '1')
F_median = rfm['F'].median()
rfm['F_label']=rfm['F'].apply(lambda x:'2' if x>F_median else '1')
M_median = rfm['M'].median()
rfm['M_label']=rfm['M'].apply(lambda x:'2' if x>M_median else '1')
rfm['RFM_label'] =rfm['R_label']+rfm['F_label']+rfm['M_label']
#查看各个分类的数量
print(rfm['RFM_label'].value_counts())
#可视化各个分类
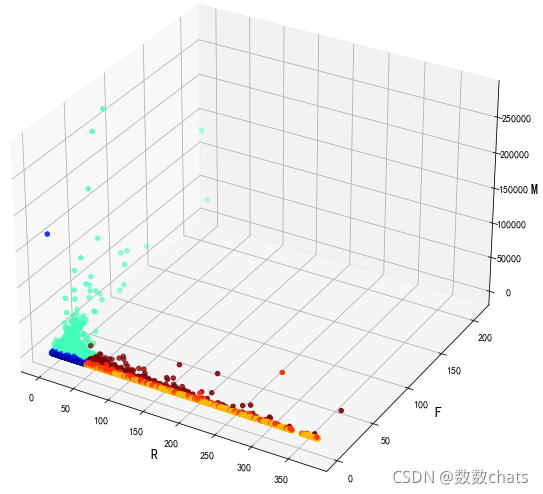
tag={
'111':1,'112':2,'':3,'122':4,'121':5,'211':6,'212':7,'222':8}
fig = plt.figure(figsize=(20,10))
ax = fig.add_subplot(111, projection='3d') # 创建三维坐标
ax.set_xlabel('R', fontsize=14)
ax.set_ylabel('F', fontsize=14)
ax.set_zlabel('M', fontsize=14)
plt.tick_params(labelsize=10)
ax.scatter(rfm.R, rfm.F, rfm.M, s=20, c=rfm.RFM_label.map(tag), cmap="jet", marker="o")
plt.show()
KMeans与RFM结合划分
#查看R、F、M数据分布情况
plt.scatter(range(len(rfm.R)),rfm.R)
plt.ylabel('R')
plt.show()
plt.scatter(range(len(rfm.F)),rfm.F)
plt.ylabel('F')
plt.show()
plt.scatter(range(len(rfm.M)),rfm.M)
plt.ylabel('M')
plt.show()
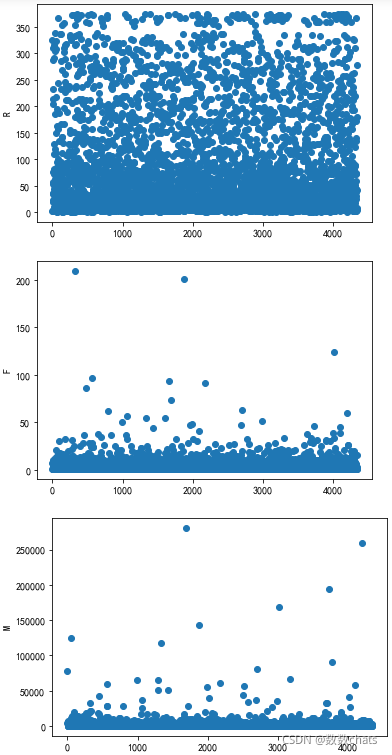
我们会发现实际上的数据大部分都聚集在了一起,并且有一些非常离散的极端值数据,这对我们后续进行数据聚类会产生不利影响,所以我们使用log函数对数据进行处理,让其分布的更加均匀:
# 即使针对于某一个属性,它的值差别很大,所以我们先使用log transform把值做个转换,+1是为了避免log(0)
rfm_log=np.log(rfm[['R','F','M']]+1)
#归一化
scaler=StandardScaler().fit_transform(rfm_log)
#模型训练
L = []
for k in range(2,11):
kmeans=KMeans(n_clusters=k).fit(scaler)
L.append([k, silhouette_score(scaler, kmeans.labels_)])
print(L)
sse={
}
for k in range(2,11):
kmeans=KMeans(n_clusters=k).fit(scaler)
sse[k]=kmeans.inertia_
print(sse)
#可视化训练结果
fig,axes = plt.subplots(1, 2, figsize=(20, 8), dpi=100)
ax1=axes[0]
ax2=axes[1]
a = pd.DataFrame(L)
a.columns = ['k', '轮廓系数']
ax1.plot(a.k, a.轮廓系数,'gp-')
ax1.set_title('轮廓系数确定最佳的K值',fontdict={
'fontsize':15})
ax1.set_ylabel('轮廓系数')
ax2.plot(list(sse.keys()),list(sse.values()),'bp-')
ax2.set_title('误差平方和确定最佳的K值',fontdict={
'fontsize':15})
ax2.set_ylabel('误差平方和')
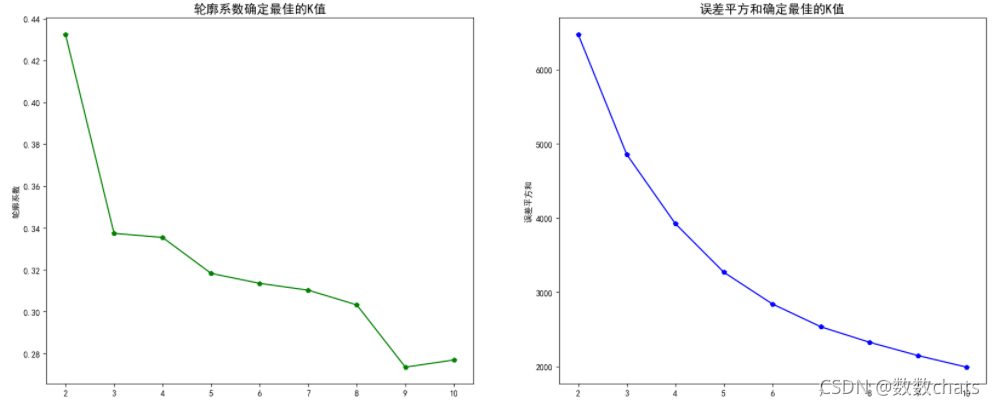
k=2时,轮廓系数是最大的,其次是k=3或4。结合业务而言,如果将用户分成两类,精确度不够高,又k=4的误差平方和比k=3小,因此接下来选择k=4。
下面分别展示k=3和k=4时的模型分类情况
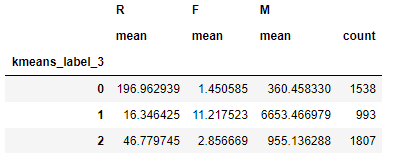
#k=3
kmeans=KMeans(n_clusters=3).fit(rfm_log)
cluster_labels=kmeans.labels_
rfm['kmeans_label_3']=cluster_labels
rfm.groupby(['kmeans_label_3']).agg({
'R':'mean','F':'mean','M':['mean','count']})
#k=4
kmeans=KMeans(n_clusters=4).fit(rfm_log)
cluster_labels=kmeans.labels_
rfm['kmeans_label_4']=cluster_labels
rfm.groupby(['kmeans_label_4']).agg({
'R':'mean','F':'mean','M':['mean','count']})
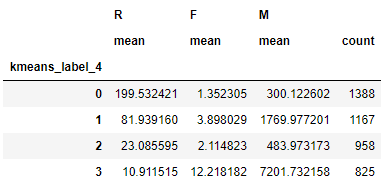
fig = plt.figure(figsize=(20,10))
ax = fig.add_subplot(121, projection='3d')
ax.set_title('K=4', fontsize=18)
ax.set_xlabel('R', fontsize=14)
ax.set_ylabel('F', fontsize=14)
ax.set_zlabel('M', fontsize=14)
plt.tick_params(labelsize=10)
ax.scatter(rfm.R, rfm.F, rfm.M, s=20, c=rfm.kmeans_label_4, cmap="jet", marker="o")
ax = fig.add_subplot(122, projection='3d')
ax.set_title('K=3', fontsize=18)
ax.set_xlabel('R', fontsize=14)
ax.set_ylabel('F', fontsize=14)
ax.set_zlabel('M', fontsize=14)
plt.tick_params(labelsize=10)
ax.scatter(rfm.R, rfm.F, rfm.M, s=20, c=rfm.kmeans_label_3, cmap="jet", marker="o")
plt.show()
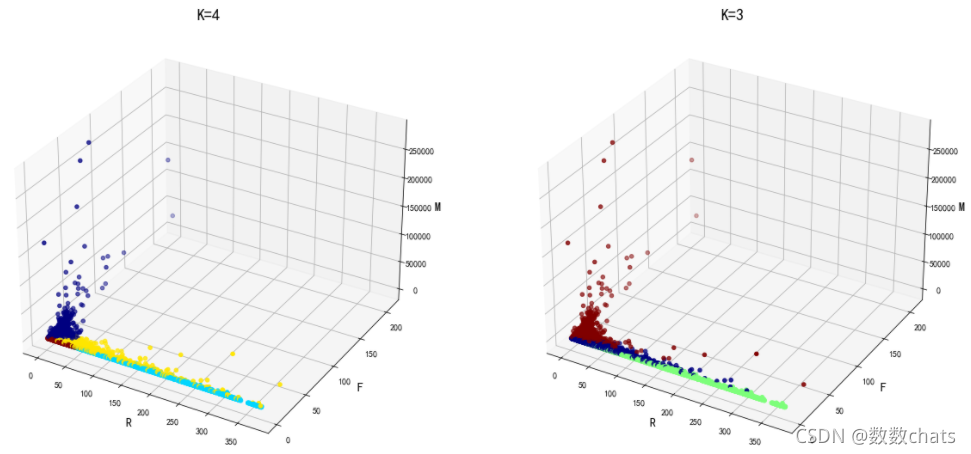
在使用这种方式做实际的数据处理时,可能因为数据分布的原因导致区分度并不是特别好,因为根据数据进行用户区分,并不是总能发现比较明显的区分“界限”,也就是不同群体间的边界其实是非常模糊和混杂的(从上面的最终分析图也可以看出这样的情况),所以从这个角度讲,单纯通过RFM模型和聚类进行用户群体划分也是有它的局限性的。