最近看崔庆才老哥的python爬虫视频感觉受益良多,很多知识点被他讲的很清楚有条理,基本上他一集视频够我消化个好几天
好几天没写原创了,附上代码,顺便写写我这两天的学习日志吧
短短百行代码,我学习了两天
第一天看了视频,学了下selenuim的基本用法
首先安装selenium模块:
pip3 install selenium 这里我安装的是3.14版本的
其次还需要安装Chromedriver(切记这里要安装与自己chrome对应的版本,我的chrome是66,所以安装的是2.40)
基本用法
#encoding=utf-8
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
# 打开谷歌浏览器
try:
browser.get('http://naotu.baidu.com/file/732bcef91efa1375210d15c7f38cadb7')
# 打开百度这个网站
input = browser.find_element_by_id('kw')
# 找到kw这个元素
input.send_keys('Python')
# 敲入python
input.send_keys(Keys.ENTER)
# 敲入回车
wait = WebDriverWait(browser, 10)
# 等待
wait.until(EC.presence_of_element_located((By.ID, 'content_left')))
# 等待元素被加载出来
print(browser.current_url)
print(browser.get_cookies())
print(browser.page_source)
finally:
browser.close()
这样就完成了一个简单的敲击百度搜索的事件
拖动按键
from selenium.webdriver import ActionChains
from selenium import webdriver
import time
browser = webdriver.Chrome()
action = ActionChains(browser)
browser.get('https://login.taobao.com/member/login.jhtml?spm=a21bo.2017.754894437.1.5af911d9XiIwcB&f=top&redirectURL=https%3A%2F%2Fwww.taobao.com%2F')
browser.find_element_by_xpath('//*[@id="J_Quick2Static"]').click()
browser.find_element_by_xpath('//*[@id="TPL_username_1"]').send_keys('*************')
browser.find_element_by_xpath('//*[@id="TPL_password_1"]').send_keys('*************')
source=browser.find_element_by_xpath("//*[@id='nc_1_n1t']")#需要滑动的元素
def VerificationCode(source):
action.click_and_hold(source).perform() #鼠标左键按下不放
action.move_by_offset(298,0)#需要滑动的坐标
action.release().perform() #释放鼠标
time.sleep(0.1)
VerificationCode(source)
#输入账号密码
browser.find_element_by_xpath('//*[@id="J_SubmitStatic"]').click()
python第三方模块基本没有不能实现的,只有你想不到没有他做不到的
简单的几行代码可以完成拖拽滑动验证码的事件
其实滑动验证的另一种解决方法就是用cookie登陆
selenium+phantomjs的一次实战
# coding=utf-8
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
import re
from pyquery import PyQuery as pq
import pymongo
from config import *
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
browser = webdriver.Chrome(chrome_options=chrome_options)
#这段代码定义了headless chrome,所有的配置都一样
#mongo数据库配置在config
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
#浏览器设置
# browser = webdriver.Chrome()
# browser = webdriver.PhantomJS()
browser = webdriver.PhantomJS(service_args=SERVICE_ARGS)
wait = WebDriverWait(browser, 10)
browser.set_window_size(1400,900)
# 判断该元素是否加载完成,等待的最长时间为十秒
def search():
print('正在搜索')
try:
('https://www.taobao.com/')
input = WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#q')))
submit = WebDriverWait(browser,10).until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
#找到淘宝的搜索框还有搜索键
input.send_keys('美食')
submit.click()
total = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.total')))
get_product()
return total.text
except TimeoutException:
return search()
#输入“美食”
#WebDriverWait(browser,10).until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_TSearchForm > div.search-button > button')))
#程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException
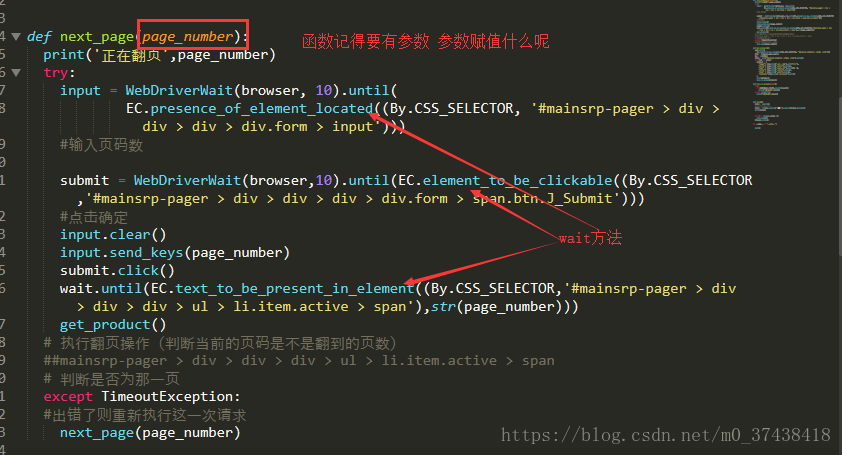
def next_page(page_number):
print('正在翻页',page_number)
try:
input = WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#mainsrp-pager > div > div > div > div.form > input')))
#输入页码数
submit = WebDriverWait(browser,10).until(EC.element_to_be_clickable((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit')))
#点击确定
input.clear()
input.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#mainsrp-pager > div > div > div > ul > li.item.active > span'),str(page_number)))
get_product()
# 执行翻页操作(判断当前的页码是不是翻到的页数)
##mainsrp-pager > div > div > div > ul > li.item.active > span
# 判断是否为那一页
except TimeoutException:
#出错了则重新执行这一次请求
next_page(page_number)
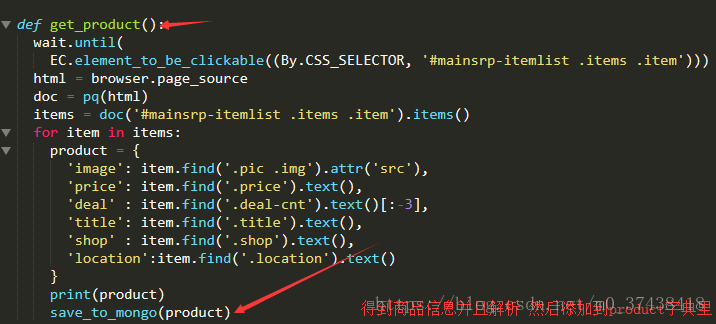
def get_product():
wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#mainsrp-itemlist .items .item')))
html = browser.page_source
doc = pq(html)
items = doc('#mainsrp-itemlist .items .item').items()
for item in items:
product = {
'image': item.find('.pic .img').attr('src'),
'price': item.find('.price').text(),
'deal' : item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop' : item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
save_to_mongo(product)
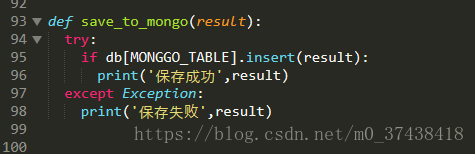
def save_to_mongo(result):
try:
if db[MONGGO_TABLE].insert(result):
print('保存成功',result)
except Exception:
print('保存失败',result)
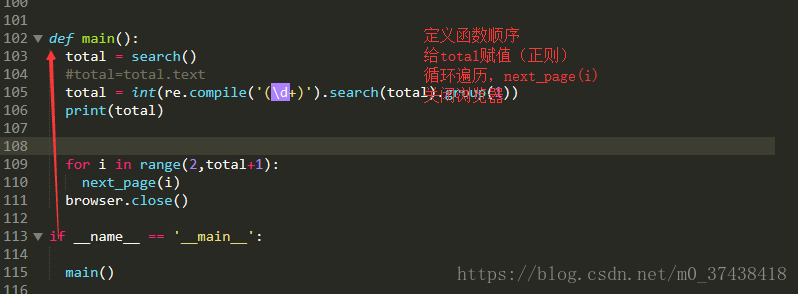
def main():
total = search()
#total=total.text
total = int(re.compile('(\d+)').search(total).group(1))
print(total)
for i in range(2,total+1):
next_page(i)
browser.close()
if __name__ == '__main__':
main()
第一天
这段代码我思考了一天
在第一天的时候我试着写selenium写一段实战秒杀天猫商品的代码,然后遇到了许多困难,这是基础不牢固导致的
遇到的困难有:
①不理解main方法的调用
②如何破解淘宝的验证码还有请求频繁限制
③def VerificationCode(source)需要传入的参数不理解
④函数前后顺序问题
我相信以后多敲代码,这些问题会解决的
第二天:
在QPython编程交流中遇到了一个好友,在他的帮忙下解决了问题
感觉他的思想都值得我学习,并且很快找到的问题的解决方法
第二天做selenium实战的时候,遇到的问题如下
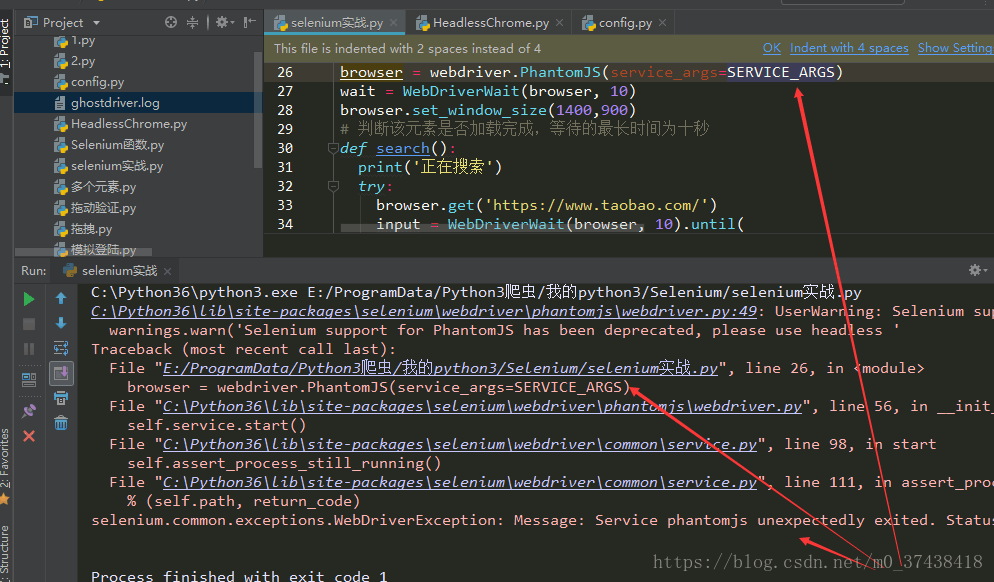
爆出warning,所以我一直以为是selenium不再支持phantomjs,然后我在网上查了许多方法
例如:
①下载selenium2.48,然后发现

这个问题是由下载的版本过低导致的(selenium3.14需要下载chromedriver,selenium2.48需要下载ghostdriver)
当时太着急解决问题,如果静下心来思考,很容易就能发现问题了,我在这里绕的圈子也有点多
②之后发现在selenium3.14版本下,整个headless chrome就可以运行了
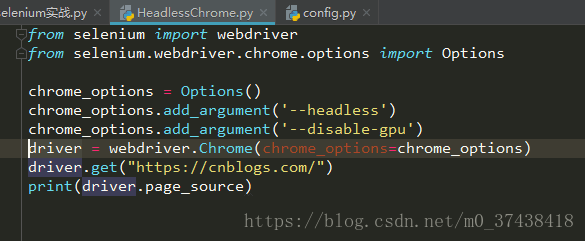
在网上找的代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://cnblogs.com/")
print(driver.page_source)
经过测试可以实现
然而放到实战代码却不行,然后我又以为是phantomjs版本被弃用的问题,又绕了很大一个圈子
好友X跟我讲
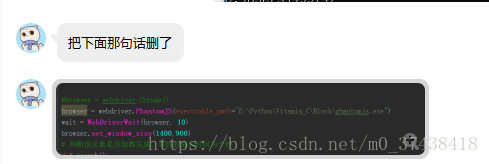

经过测试确实可以,然后我就以为是我的版本问题,后来发现使用之前的PhantomJS也可以

后面我才发现是我的传参问题
我原先的传参是这样的:

大小写完全不对
修改如下:
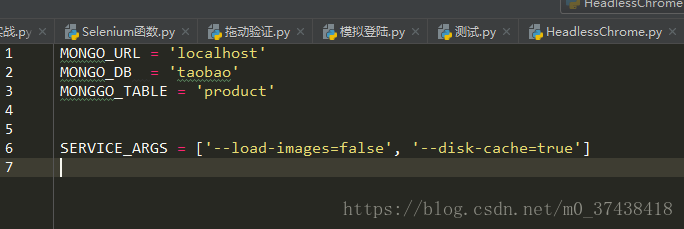
就是这个错误就导致我浪费了一晚上时间,明天好好写写代码的讲解